点云配准ICP算法推导,SVD分解
文章目录
- 前言
- 一、点云配准问题的数学描述
- 二、基于SVD的ICP算法实现步骤
- 三、ICP算法原理推导
- 总结
前言
最近在看点云配准相关算法,关于点云配准:迭代最近点(Iterative Closest Point, ICP)算法可谓是配准算法的先驱和鼻祖了,该算法于上世纪90年代提出。虽然现在看ICP算法比较老旧,算法精准度也不是很好,但是通过学习ICP的设计原理可以深刻的了解点云配准这个数学问题及纯数学形式的解决思路。
在学习的过程中我发现网上很少有从零基础讲解ICP算法的(可能默认看这类算法的都有很好的数学功底吧),所以我想写一篇关于ICP算法的详细推导博客,希望通过一篇文章帮大家彻底搞懂ICP的原理。后续有可能的话会针对这篇公式推导博客写一篇对应的代码实现博客。
这篇博客适用于点云配准的入门小白,或不多说,上正文!
一、点云配准问题的数学描述
现有两朵点云
P = { p i ∈ R 3 ∣ i = 1 , … , N } \mathrm{P}=\left\{\boldsymbol{p}_i \in \mathbb{R}^3 \mid i=1, \ldots, N\right\} P={pi∈R3∣i=1,…,N}
Q = { q i ∈ R 3 ∣ i = 1 , … , M } \mathrm{Q}=\left\{\boldsymbol{q}_i \in \mathbb{R}^3 \mid i=1, \ldots, M\right\} Q={qi∈R3∣i=1,…,M}
需要求解一个刚性变换 T = R , t \mathrm{T}={R,t} T=R,t,使得点云 P P P和 Q Q Q对齐,( P P P向 Q Q Q对齐),其中 R R R是旋转矩阵, t t t是平移向量。找寻刚性变换的过程可以被视做一个最优化的过程(让匹配误差最小,即:该匹配的两个点经过变换后的欧氏距离最小):
min R , t ∑ i = 1 N ∥ R p i + t − q i ∥ 2 \min _{R, t} \sum_{i=1}^N\left\|R p_i+t-q_i\right\|^2 R,tmini=1∑N∥Rpi+t−qi∥2
说明:在真实的点云配准过程中,两朵点云中的数据的数量不一定一致(就是上述定义的M和N),在实际的ICP算法中,算法要先对两朵点云进行关键点匹配,即找到 P P P点云中 p i p_i pi点在 Q Q Q点云中的对应点,然后将他们放到对应集合中,找到了上面介绍的一一对应的具有N个点的待配准点云。对应关系寻找的好坏直接决定了算法最后配准的精准度。
二、基于SVD的ICP算法实现步骤
-
分别求两点云各自的质心:
p ˉ = 1 N ∑ i = 1 N p i , ⋯ ⋅ q ˉ = 1 N ∑ i = 1 N q i \bar{p}=\frac{1}{N} \sum_{i=1}^N p_i, \cdots \cdot \bar{q}=\frac{1}{N} \sum_{i=1}^N q_i pˉ=N1i=1∑Npi,⋯⋅qˉ=N1i=1∑Nqi -
对点云坐标去中心化,即:求两点云相对与各自质心的坐标:
x i = p i − p ˉ , ⋯ ⋯ y i = q i − q ˉ x_i=p_i-\bar{p}, \cdots \cdots y_i=q_i-\bar{q} xi=pi−pˉ,⋯⋯yi=qi−qˉ -
利用去中心化后的点云坐标计算 H H H矩阵,维数为3*N:
H = ∑ i = 0 N x i y i T H=\sum_{i=0}^N x_i y_i^T H=i=0∑NxiyiT -
对 H H H矩阵进行SVD分解:
R = U V T R=UV^T R=UVT -
验证结果:如果: d e t ( R ) = 1 det(R)=1 det(R)=1,算法有效;如果: d e t ( R ) = − 1 det(R)=-1 det(R)=−1,算法失效
det表示求矩阵的行列式值
- 计算平移矩阵:
t = Y − X t=Y-X t=Y−X
三、ICP算法原理推导
在第一节中介绍:点云配准可以转化为如下数学问题:
F ( R , t ) = min R , t ∑ i = 1 N ∥ R p i + t − q i ∥ 2 F(R,t)=\min _{R, t} \sum_{i=1}^N\left\|R p_i+t-q_i\right\|^2 F(R,t)=R,tmini=1∑N∥Rpi+t−qi∥2
这是一个二元函数,对于二元函数的求解问题,可以用导数等于0解决。先固定 R R R求 t t t:
∂ F ∂ t = 2 ∑ i = 0 N t + 2 R ∑ i = 0 N p i − 2 ∑ i = 0 N q i = 0 \frac{\partial F}{\partial t}=2 \sum_{i=0}^N t+2 R \sum_{i=0}^N p_i-2 \sum_{i=0}^N q_i=0 ∂t∂F=2i=0∑Nt+2Ri=0∑Npi−2i=0∑Nqi=0
推出:
t = ∑ i = 0 N q i ∑ i = 0 N 1 − R ∑ i = 0 N p i ∑ i = 0 N 1 = 1 N ∑ i = 0 N q i − R 1 N ∑ i = 0 N p i t=\frac{\sum_{i=0}^N q_i}{\sum_{i=0}^N 1}-\frac{R \sum_{i=0}^N p_i}{\sum_{i=0}^N 1}=\frac{1}{N} \sum_{i=0}^N q_i-R \frac{1}{N} \sum_{i=0}^N p_i t=∑i=0N1∑i=0Nqi−∑i=0N1R∑i=0Npi=N1i=0∑Nqi−RN1i=0∑Npi
此时发现公式中出现了去中心化的表达,因此用去中心化的方式表达 t t t(算法中的去中心化操作也就是这么来的):
t = q ˉ − R p ˉ t=\bar{q}-R\bar{p} t=qˉ−Rpˉ
将 t t t带回原始公式 F F F中:
F ( R , t ) = min R ∑ i = 1 N ∥ R p i + q ˉ − R p ˉ − q i ∥ 2 = min R ∑ i = 1 N ∥ R ( p i − p ˉ ) − ( q i − q ˉ ) ∥ 2 = min R ∑ i = 1 N ∥ R x i − y i ∥ 2 F(R, t)=\min _R \sum_{i=1}^N\left\|R p_i+\bar{q}-R \bar{p}-q_i\right\|^2\\=\min _R \sum_{i=1}^N\left\|R\left(p_i-\bar{p}\right)-\left(q_i-\bar{q}\right)\right\|^2\\=\min _R \sum_{i=1}^N\left\|R x_i-y_i\right\|^2 F(R,t)=Rmini=1∑N∥Rpi+qˉ−Rpˉ−qi∥2=Rmini=1∑N∥R(pi−pˉ)−(qi−qˉ)∥2=Rmini=1∑N∥Rxi−yi∥2
其中:
∥ R x i − y i ∥ 2 = ( R x i − y i ) T ( R x i − y i ) = ( x i T R T − y i T ) ( R x i − y i ) = x i T x i − y i T R x i − x i T R T y i + y i T y i \begin{aligned}\left\|R x_i-y_i\right\|^2=&\left(R x_i-y_i\right)^T\left(R x_i-y_i\right)=\left(x_i^T R^T-y_i^T\right)\left(R x_i-y_i\right) \\ &=x_i^T x_i-y_i^T R x_i-x_i^T R^T y_i+y_i^T y_i \end{aligned} ∥Rxi−yi∥2=(Rxi−yi)T(Rxi−yi)=(xiTRT−yiT)(Rxi−yi)=xiTxi−yiTRxi−xiTRTyi+yiTyi
因为 x i x_i xi和 y i y_i yi的维度是1×3, R R R的维度是3×3,因此 y i T R x i y_i^T R x_i yiTRxi 和 x i T R T y i x_i^T R^T y_i xiTRTyi是一个常数,对于一个常数来说,它的转置等于它本身:
x i T R T y i = ( x i T R T y i ) T = y i T R x i x_i^T R^T y_i=\left(x_i^T R^T y_i\right)^T=y_i^T R x_i xiTRTyi=(xiTRTyi)T=yiTRxi
因此,上面的展开式子可以写成:
( R x i − y i ) T ( R x i − y i ) = x i T x i − 2 y i T R x i + y i T y i \left(R x_i-y_i\right)^T\left(R x_i-y_i\right)=x_i^T x_i-2 y_i^T R x_i+y_i^T y_i (Rxi−yi)T(Rxi−yi)=xiTxi−2yiTRxi+yiTyi
将展开式代入到F函数中便可得:
F ( R , t ) = min R ∑ i = 1 N ( x i T x i − 2 y i T R x i + y i T y i ) F(R, t)=\min _R \sum_{i=1}^N\left(x_i^T x_i-2 y_i^T R x_i+y_i^T y_i\right) F(R,t)=Rmini=1∑N(xiTxi−2yiTRxi+yiTyi)
观察此时的 F F F函数发现,函数中的第一项和第三项没有 R R R的作用,都是常数项,对于一个最优化问题来说没有贡献,因此该最优化问题的结果仅由第二项决定:
F ( R , t ) = min R ∑ i = 1 N − 2 y i T R x i F(R, t)=\min _R \sum_{i=1}^N-2 y_i^T R x_i F(R,t)=Rmini=1∑N−2yiTRxi
去掉负号和前面的常系数便可以将最小化问题转化成最大化问题:
max R ∑ i = 1 N y i T R x i \max _R \sum_{i=1}^N y_i^T R x_i Rmaxi=1∑NyiTRxi
观察 y i T R x i y_i^T Rx_i yiTRxi这个式子的特点:
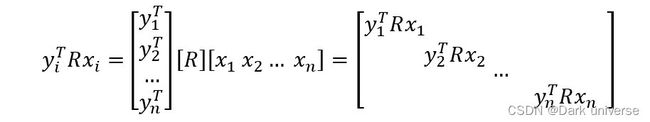
可以发现式子上的数都在这个矩阵的对角线上,这样便可以用矩阵的迹来进行进一步的表示,最大化式子可以表示成:
max R ∑ i = 1 N y i T R x i = max ( ∑ i = 1 N trace ( y i T R x i ) ) \max _R \sum_{i=1}^N y_i^T R x_i=\max \left(\sum_{i=1}^N \operatorname{trace}\left(y_i^T R x_i\right)\right) Rmaxi=1∑NyiTRxi=max(i=1∑Ntrace(yiTRxi))
根据矩阵迹的性质 t r a c e ( A B ) = t r a c e ( B A ) trace(AB)=trace(BA) trace(AB)=trace(BA)对上面的式子进项变换可得:
t r a c e ( y i T R x i ) = t r a c e ( R x i y i T ) trace(y_i^T Rx_i)=trace(Rx_i y_i^T) trace(yiTRxi)=trace(RxiyiT)
记: ∑ i = 1 N y i T x i \sum_{i=1}^N y_i^T x_i ∑i=1NyiTxi为矩阵 H H H(算法中要设置H的原因),上述的式子便可进一步化简:
max R ∑ i = 1 N y i T R x i = max R trace ( R ∑ i = 1 N ( x i y i T ) ) = max R trace ( R H ) \begin{aligned} \max _R \sum_{i=1}^N y_i^T R x_i=& \max_R \operatorname{trace}\left(R \sum_{i=1}^N \left(x_i y_i^T\right)\right) \\ & =\max _R \operatorname{trace}(R H) \end{aligned} Rmaxi=1∑NyiTRxi=Rmaxtrace(Ri=1∑N(xiyiT))=Rmaxtrace(RH)
对 H H H进行SVD分解:
SVD分解的原理介绍: https://zhuanlan.zhihu.com/p/448767610
H = U Λ V T H=U \Lambda V^T H=UΛVT
记:
L = V U T L=V U^T L=VUT
则:
L H = V U T U Λ V T = V Λ V T L H=V U^T U \Lambda V^T=V \Lambda V^T LH=VUTUΛVT=VΛVT
L H LH LH为正定矩阵,所以:
trace ( R H ) ≤ trace ( L H ) \operatorname{trace}(R H) \leq \operatorname{trace}(L H) trace(RH)≤trace(LH)
当 R = L R=L R=L时, R H RH RH的值最大.所以 R R R的解为:
R = L = V U T R=L=V U^T R=L=VUT
总结
ICP是非常经典的点云配准算法,其解决配准的方法在数学上也是非常经典的求解最优化问题。通过对ICP算法的推导,我们可以总结:点云配准的过程实际上就是在求解一个3 * 3大小的旋转矩阵R和一个3 * 1大小的平移矩阵t。