智能推荐系统 - 协同过滤算法
相似度计算三种常见方法
1.欧式距离
import pandas as pd
df = pd.DataFrame([[5, 1, 5], [4, 2, 2], [4, 2, 1]], columns=['用户1', '用户2', '用户3'], index=['物品A', '物品B', '物品C'])
df
import numpy as np
dist = np.linalg.norm(df.iloc[0] - df.iloc[1])
dist ![]()
2. 余弦内置函数
import pandas as pd
df = pd.DataFrame([[5, 1, 5], [4, 2, 2], [4, 2, 1]], columns=['用户1', '用户2', '用户3'], index=['物品A', '物品B', '物品C'])
df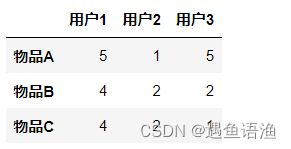
from sklearn.metrics.pairwise import cosine_similarity
user_similarity = cosine_similarity(df)
pd.DataFrame(user_similarity, columns=['物品A', '物品B', '物品C'], index=['物品A', '物品B', '物品C']) 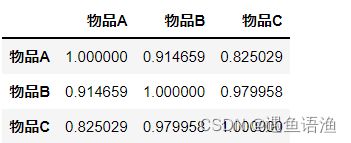
3 皮尔逊相关系数
from scipy.stats import pearsonr
X = [1, 3, 5, 7, 9]
Y = [9, 8, 6, 4, 2]
corr = pearsonr(X, Y)
print('相关系数r值为' + str(corr[0]) + ',显著性水平P值为' + str(corr[1]))![]()
import pandas as pd
df = pd.DataFrame([[5, 4, 4], [1, 2, 2], [5, 2, 1]], columns=['物品A', '物品B', '物品C'], index=['用户1', '用户2', '用户3'])
df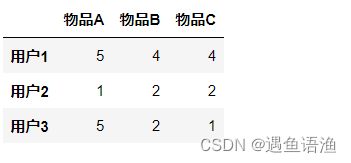
# 物品A与其他物品的皮尔逊相关系数
A = df['物品A']
corr_A = df.corrwith(A)
corr_A 
# 皮尔逊系数表,获取各物品相关性
df.corr() 
案例实战 - 电影智能推荐系统
1.读取数据
import pandas as pd
movies = pd.read_excel('电影.xlsx')
movies.head()
score = pd.read_excel('评分.xlsx')
score.head() 
df = pd.merge(movies, score, on='电影编号')
df.head() 
df.to_excel('电影推荐系统.xlsx')df['评分'].value_counts() # 查看各个评分的出现的次数
import matplotlib.pyplot as plt
df['评分'].hist(bins=20) # hist()函数绘制直方图,竖轴为各评分出现的次数 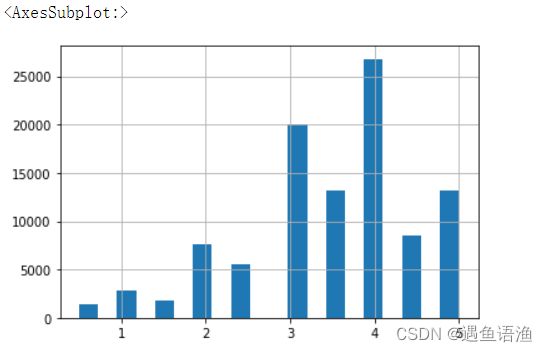
2.数据分析
ratings = pd.DataFrame(df.groupby('名称')['评分'].mean())
ratings.sort_values('评分', ascending=False).head()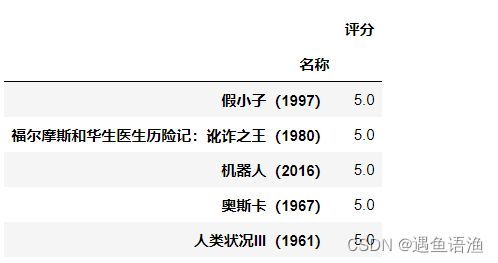
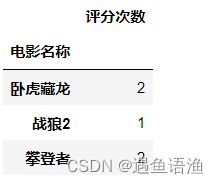
ratings['评分次数'] = df.groupby('名称')['评分'].count()
ratings.sort_values('评分次数', ascending=False).head() 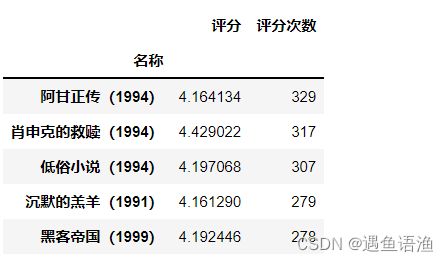
3.数据处理
user_movie = df.pivot_table(index='用户编号', columns='名称', values='评分')
user_movie.tail()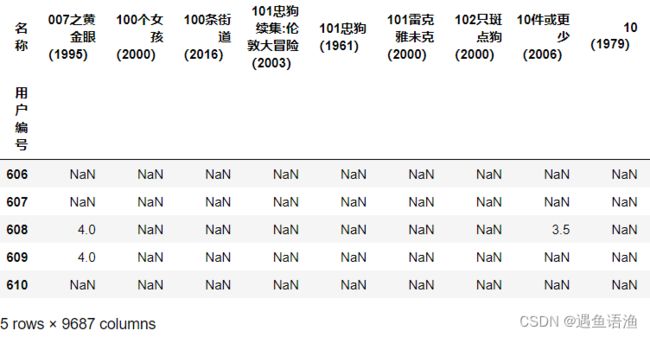
user_movie.describe() # 因为数据量较大,这个耗时可能会有1分钟左右 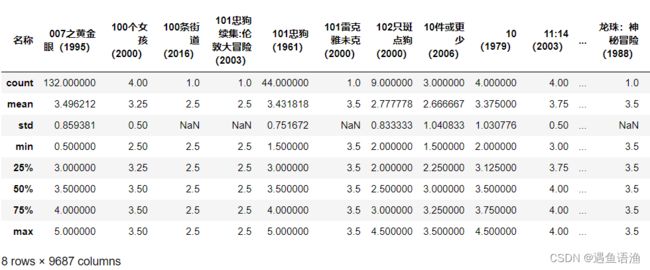
4.智能推荐
FG = user_movie['阿甘正传(1994)'] # FG是Forrest Gump(),阿甘英文名称的缩写
pd.DataFrame(FG).head()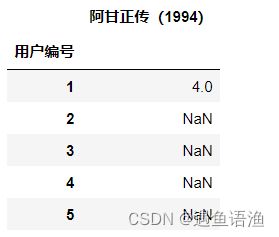
# axis默认为0,计算user_movie各列与FG的相关系数
corr_FG = user_movie.corrwith(FG)
similarity = pd.DataFrame(corr_FG, columns=['相关系数'])
similarity.head() 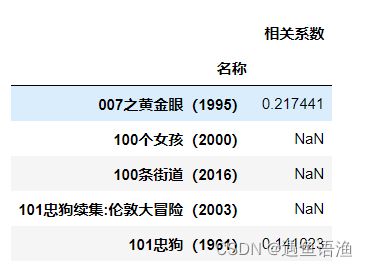
similarity.dropna(inplace=True) # 或写成similarity=similarity.dropna()
similarity.head() 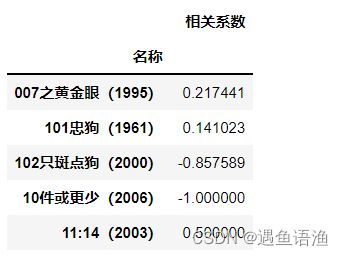
similarity_new = pd.merge(similarity, ratings['评分次数'], left_index=True, right_index=True)
similarity_new.head() 
# 第二种合并方式
similarity_new = similarity.join(ratings['评分次数'])
similarity_new.head() 
similarity_new[similarity_new['评分次数'] > 20].sort_values(by='相关系数', ascending=False).head() # 选取阈值 
补充知识点:groupby()函数的使用
import pandas as pd
data = pd.DataFrame([['战狼2', '丁一', 6, 8], ['攀登者', '王二', 8, 6], ['攀登者', '张三', 10, 8], ['卧虎藏龙', '李四', 8, 8], ['卧虎藏龙', '赵五', 8, 10]], columns=['电影名称', '影评师', '观前评分', '观后评分'])data
means = data.groupby('电影名称')[['观后评分']].mean()
means
means = data.groupby('电影名称')[['观前评分', '观后评分']].mean()
means 
means = data.groupby(['电影名称', '影评师'])[['观后评分']].mean()
means 
count = data.groupby('电影名称')[['观后评分']].count()
count
count = count.rename(columns={'观后评分':'评分次数'})
count