win下使用TensorFlow object detection训练自己模型
win下使用TensorFlow object detection训练自己模型
- 1. 环境
- 2.xml生成csv文件,再生成record文件
-
- 2.1 对训练文件和测试文件都使用以下两个文件分别生成自己的csv文件
- 2.1 对生成的两个csv文件分别生成自己的record文件
- 3. 修改配置文件
- 4.训练保存模型
- 5.进行模型验证
- 6.使用zed相机实时检测
- 7.Android端使用实时检测
-
- 7.1 将pb文件转换成tflite文件
- 7.2安装android studio
- 8.对训练的图像进行数据增强
- 9.模型应用于网络摄像头
- 工程文件
- 参考
1. 环境
1.1 创建虚拟环境python3.7,安装tensorflow-gpu==1.13.1,安装PIL(pip install pillow)。
1.2 下载labelimg,使用labelimg对自己的图片进行标注,保存,生成xml文件(使用这三个快捷键:ctrl+s保存,d下一张,w画笔工具,标注最好是字符串形式的标签)。
1.3 建立4个文件夹(train训练图片,train_xml训练图片经过labelimg标注的xml文件,test测试文件同上)。
1.4 克隆tensorflow的models文件,就是用这里的模型和配置文件来训练自己的数据。
1.5.1 下载自己对应版本的protoc,解压后将bin文件夹中的【protoc.exe】放到C:\Windows,
1.5.2 在models\research\目录下打开命令行窗口,输入
protoc object_detection/protos/*.proto --python_out=.
1.5.3 在 ‘此电脑’-‘属性’- ‘高级系统设置’ -‘环境变量’-‘系统变量’ 中新建名为‘PYTHONPATH’的变量,将
models/research/ 及 models/research/slim 两个文件夹的完整目录添加,分号隔开。
1.5.4 将slim文件夹下的nets文件夹复制,粘贴到research/object_detection文件夹下.
1.5.5 在slim位置打开终端,输入
python setup.py build
python setup.py install
如果有问题,将slim文件夹下的bulid文件改名。
1.5.6 测试API,输入
python object_detection/builders/model_builder_test.py
不报错说明运行成功。
2.xml生成csv文件,再生成record文件
2.1 对训练文件和测试文件都使用以下两个文件分别生成自己的csv文件
'''
xml文件生成csv文件,生成到了各自的xml文件夹里
更改三个地方
'''
import os
import glob
import pandas as pd
import xml.etree.ElementTree as ET
os.chdir(r'F:\bomb\test_xml') ## 1、更改路径到训练(或者测试)的xml文件夹
path = r'F:\bomb\test_xml' ## 2、同上
def xml_to_csv(path):
xml_list = []
for xml_file in glob.glob(path + '\\*.xml'):
tree = ET.parse(xml_file)
#print(tree)
root = tree.getroot()
#hh=root.findall('object')
#print(hh[0][0].text)
#print(root.find('size')[0])
for member in root.findall('object'):
#print(member,member[0].text)
try:
value = (#root.find('filename').text,
xml_file.split('\\')[-1].split('.')[0]+'.jpg',
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text)
)
except:
pass
#print(value)
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
def main():
image_path = path
xml_df = xml_to_csv(image_path)
xml_df.to_csv('test.csv', index=None) #3、输出文件名称,生成train.csv或者test.csv
print('Successfully converted xml to csv.')
main()
2.1 对生成的两个csv文件分别生成自己的record文件
新建一个generate_tfrecord.py文件,修改里面的自己的路径
# -*- coding: utf-8 -*-
"""
csv文件生成record文件,生成到了各自的xml文件夹里
"""
"""
Usage:
# From tensorflow/models/
# Create train data:
python C:\\Users\\YFZX\\Desktop\\image_augment\\image_augment\\generate_tfrecord.py --csv_input=train.csv --output_path=train.record
python generate_tfrecord.py --csv_input=F:\\bomb\\test.csv --output_path=F:\\bomb\\test.record
"""
#改3处
import sys
sys.path.append(r'C:\\models-r1.13.0\research\object_detection\utils')#1.改成自己下载的tensorflow的model文件夹里面的research\object_detection\utils文件夹路径
import dataset_util
import os
import io
import pandas as pd
import tensorflow as tf
from PIL import Image
#from object_detection.utils import dataset_util
from collections import namedtuple, OrderedDict
# os.chdir(r'C:\Users\YFZX\Desktop\dz')
# print(sys.argv[0])
flags = tf.app.flags
flags.DEFINE_string('csv_input', '', 'Path to the CSV input')#这里是运行py文件的输入文件名叫csv_input
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')## 第一个是参数名称,第二个参数是默认值,第三个是参数描述
FLAGS = flags.FLAGS
# TO-DO replace this with label map
#2.注意将对应的label改成自己的类别!!!!!!!!!!
def class_text_to_int(row_label):
if row_label == 'class3':
return 1
elif row_label == 'class4':
return 2
elif row_label == 'class5':
return 3
elif row_label == 'class6':
return 4
elif row_label == 'class7':
return 5
else:
return 0
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
def create_tf_example(group, path):
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class']))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def main(_):
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
path = os.path.join(os.getcwd(), r'F:\bomb\train') #3.改为自己的train(或者test)图片的存放路径
examples = pd.read_csv(FLAGS.csv_input)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString())
writer.close()
output_path = os.path.join(os.getcwd(), FLAGS.output_path)
print('Successfully created the TFRecords: {}'.format(output_path))
if __name__ == '__main__':
tf.app.run()
保存此py文件,然后在终端的虚拟环境(activate tf1.13)中运行这个py文件(在这位置安装shift再鼠标右键,选择在此处打开命令窗口),如下
csv_input=自己的csv文件地址。output_path=生成的record文件的地址和名称。(如果出错,可以试着吧地址写成绝对路径)
python bomb819\torecord.py --csv_input=bomb831\train831.csv --output_path=bomb831\train.record
3. 修改配置文件
1.建立一个自己的pbtxt文件(bomb.pbtxt),我自己是手写的,就按照research\object_detection\data文件夹里面已有的文件改成自己的分类类别。
2.在object_detection文件夹下新建一个自己的工程目录文件夹(bomb),在object_detection/samples/config文件夹里面,找到你自己想要的模型的config文件,复制粘贴到自己刚才建立的工程目录里,并按自己的模型分类进行修改
3.主要的修改是num_classes分类的类别数,batch_size按自己数据的大小选择适合的,学习率与batchsize应该按比例增加或减少。num_steps看自己的训练时间,fine_tune_checkpoint是迁移学习的,如果没有model.ckpt文件就要注释掉,input_path是自己的record文件的位置,label_map_path是自己的pbtxt文件的位置)。

4.训练保存模型
首先需在models/research/目录下执行:python setup.py install,在在models/research/slim目录下执行:python setup.py install
1.训练模型:在object detection 文件夹打开虚拟环境
train_dir是自己的工程文件夹,pipeline_config_path是工程文件夹下刚才修改的配置文件
python ./legacy/train.py --logtostderr --train_dir=bomb/ --pipeline_config_path=bomb/ssdlite_mobilenet_v1_coco.config
这里我遇到了显存不足的问题,该config里的batchsize还是不行,于是在legacy下的train.py文件开头添加了
#放在代码顶部的导入包的位置
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
或者
from tensorflow.compat.v1 import InteractiveSession
import tensorflow as tf
config = tf.compat.v1.ConfigProto(gpu_options=tf.compat.v1.GPUOptions(allow_growth=True))
sess = tf.compat.v1.Session(config=config)
查看tensorboard,
tensorboard --logdir=bomb831\
2.保存模型
训练完成后,在object detection 文件夹打开虚拟环境,bomb2/ssdlite_mobilenet_v1_coco.config是自己工程项目下生成的config文件,bomb2/model.ckpt-100是上一步训练的结果文件,bomb2_model是模型的保存文件夹。
python export_inference_graph.py \ --input_type image_tensor \ --pipeline_config_path bomb2/ssdlite_mobilenet_v1_coco.config \ --trained_checkpoint_prefix bomb2/model.ckpt-100 \ --output_directory bomb2_model
5.进行模型验证
将自己的验证图片放在文件夹下,我放在了object_detection/test_images下。
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
config = tf.compat.v1.ConfigProto(gpu_options=tf.compat.v1.GPUOptions(allow_growth=True))
sess = tf.compat.v1.Session(config=config)
import zipfile
from distutils.version import StrictVersion
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
import cv2
#主要改五处,剩下的自行查看修改。
# This is needed since the notebook is stored in the object_detection folder.
sys.path.append("..")
from object_detection.utils import ops as utils_ops
from utils import label_map_util
from utils import visualization_utils as vis_util
# # Model preparation
# ## Variables
#
# Any model exported using the `export_inference_graph.py` tool can be loaded here simply by changing `PATH_TO_FROZEN_GRAPH` to point to a new .pb file.
#
# By default we use an "SSD with Mobilenet" model here. See the [detection model zoo](https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/detection_model_zoo.md) for a list of other models that can be run out-of-the-box with varying speeds and accuracies.
# In[ ]:
# What model to download.
MODEL_NAME = 'bomb2_model'#1.改为自己生成模型的文件夹
# Path to frozen detection graph. This is the actual model that is used for the object detection.
PATH_TO_FROZEN_GRAPH = MODEL_NAME + '/frozen_inference_graph.pb'
# List of the strings that is used to add correct label for each box.
PATH_TO_LABELS = os.path.join('data', 'bomb2.pbtxt')#2.bptxt文件,我把他放在了object—_detection\data\下的bomb2.pbtxt
# ## Load a (frozen) Tensorflow model into memory.
# In[ ]:
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_FROZEN_GRAPH, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
# ## Loading label map
# Label maps map indices to category names, so that when our convolution network predicts `5`, we know that this corresponds to `airplane`. Here we use internal utility functions, but anything that returns a dictionary mapping integers to appropriate string labels would be fine
# In[ ]:
category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS, use_display_name=True)
# ## Helper code
# In[ ]:
def load_image_into_numpy_array(image):
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
# # Detection
# In[ ]:
PATH_TO_TEST_IMAGES_DIR = 'test_images'#3.测试图片的文件夹目录,在object_detection\test_images里放测试图片
TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, '{}.jpg'.format(i)) for i in range(1, 3)]#4.图片的名称,这里是1.jpg和2.jpg
# TEST_IMAGE_PATHS = [os.path.join(PATH_TO_TEST_IMAGES_DIR, '1.png')]
# Size, in inches, of the output images.
IMAGE_SIZE = (20, 14)#
# In[ ]:
def run_inference_for_single_image(image, graph):
with graph.as_default():
with tf.Session() as sess:
# Get handles to input and output tensors
ops = tf.get_default_graph().get_operations()
all_tensor_names = {output.name for op in ops for output in op.outputs}
tensor_dict = {}
for key in [
'num_detections', 'detection_boxes', 'detection_scores',
'detection_classes', 'detection_masks'
]:
tensor_name = key + ':0'
if tensor_name in all_tensor_names:
tensor_dict[key] = tf.get_default_graph().get_tensor_by_name(
tensor_name)
if 'detection_masks' in tensor_dict:
# The following processing is only for single image
detection_boxes = tf.squeeze(tensor_dict['detection_boxes'], [0])
detection_masks = tf.squeeze(tensor_dict['detection_masks'], [0])
# Reframe is required to translate mask from box coordinates to image coordinates and fit the image size.
real_num_detection = tf.cast(tensor_dict['num_detections'][0], tf.int32)
detection_boxes = tf.slice(detection_boxes, [0, 0], [real_num_detection, -1])
detection_masks = tf.slice(detection_masks, [0, 0, 0], [real_num_detection, -1, -1])
detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(
detection_masks, detection_boxes, image.shape[1], image.shape[2])
detection_masks_reframed = tf.cast(
tf.greater(detection_masks_reframed, 0.5), tf.uint8)
# Follow the convention by adding back the batch dimension
tensor_dict['detection_masks'] = tf.expand_dims(
detection_masks_reframed, 0)
image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0')
# Run inference
output_dict = sess.run(tensor_dict,
feed_dict={image_tensor: image})
# print(output_dict)
# all outputs are float32 numpy arrays, so convert types as appropriate
output_dict['num_detections'] = int(output_dict['num_detections'][0])
output_dict['detection_classes'] = output_dict[
'detection_classes'][0].astype(np.int64)
output_dict['detection_boxes'] = output_dict['detection_boxes'][0]
output_dict['detection_scores'] = output_dict['detection_scores'][0]
if 'detection_masks' in output_dict:
output_dict['detection_masks'] = output_dict['detection_masks'][0]
return output_dict
# In[ ]:
i = 40
for image_path in TEST_IMAGE_PATHS:
image = Image.open(image_path)
# the array based representation of the image will be used later in order to prepare the
# result image with boxes and labels on it.
image_np = load_image_into_numpy_array(image)
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
# Actual detection.
output_dict = run_inference_for_single_image(image_np_expanded, detection_graph)
# print(output_dict)
# Visualization of the results of a detection.
image = vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
output_dict['detection_boxes'],
output_dict['detection_classes'],
output_dict['detection_scores'],
category_index,
# instance_masks=output_dict.get('detection_masks'),
use_normalized_coordinates=True,
min_score_thresh=0.1,#5.可信度阈值
line_thickness=4)
# print(coordinate,score)
cv2.imwrite(f'test_images\\{i}.jpg', image)
# i += 1
cv2.namedWindow('1',0)
cv2.imshow('1',image_np)
cv2.waitKey(0)
# plt.figure(figsize=IMAGE_SIZE)
# plt.imshow(image_np)
# plt.show()
6.使用zed相机实时检测
zed相机可以参考我之前的博客,传送门,在下载的zed_sdk文件夹下打开自己的虚拟环境,运行python的api文件:
python get_python_api.py
这时会让你接着下载whl文件,如图所示
按照他的提示,进行输入下载,然后就可以调用zed的python接口了。
下面用自己训练的文件使用zed实现实时的目标检测功能
import datetime
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tensorflow as tf
import collections
import statistics
import math
import tarfile
import os.path
from threading import Lock, Thread
from time import sleep
import cv2
# ZED imports
import pyzed.sl as sl
#重点改3处
sys.path.append('utils')
# ## Object detection imports
from utils import ops as utils_ops
from utils import label_map_util
from utils import visualization_utils as vis_util
def load_image_into_numpy_array(image):
ar = image.get_data()
ar = ar[:, :, 0:3]
(im_height, im_width, channels) = image.get_data().shape
return np.array(ar).reshape((im_height, im_width, 3)).astype(np.uint8)
# return np.array(image)
def load_depth_into_numpy_array(depth):
ar = depth.get_data()
ar = ar[:, :, 0:4]
(im_height, im_width, channels) = depth.get_data().shape
return np.array(ar).reshape((im_height, im_width, channels)).astype(np.float32)
lock = Lock()
width = 1056
height = 624
confidence = 0.495#置信度阈值设置
image_np_global = np.zeros([width, height, 3], dtype=np.uint8)
depth_np_global = np.zeros([width, height, 4], dtype=np.float)
exit_signal = False
new_data = False
# ZED image capture thread function
def capture_thread_func(svo_filepath=None):
global image_np_global, depth_np_global, exit_signal, new_data
zed = sl.Camera()
# Create a InitParameters object and set configuration parameters
input_type = sl.InputType()
if svo_filepath is not None:
input_type.set_from_svo_file(svo_filepath)
init_params = sl.InitParameters(input_t=input_type)
init_params.camera_resolution = sl.RESOLUTION.HD720
init_params.camera_fps = 30
init_params.depth_mode = sl.DEPTH_MODE.PERFORMANCE
init_params.coordinate_units = sl.UNIT.METER
init_params.svo_real_time_mode = False
# Open the camera
err = zed.open(init_params)
print(err)
while err != sl.ERROR_CODE.SUCCESS:
err = zed.open(init_params)
print(err)
sleep(1)
image_mat = sl.Mat()
depth_mat = sl.Mat()
runtime_parameters = sl.RuntimeParameters()
image_size = sl.Resolution(width, height)
while not exit_signal:
if zed.grab(runtime_parameters) == sl.ERROR_CODE.SUCCESS:
zed.retrieve_image(image_mat, sl.VIEW.LEFT, resolution=image_size)
zed.retrieve_measure(depth_mat, sl.MEASURE.XYZRGBA, resolution=image_size)
# print(image_mat.get_data().shape,depth_mat.get_data().shape)
lock.acquire()
image_np_global = load_image_into_numpy_array(image_mat)
depth_np_global = load_depth_into_numpy_array(depth_mat)
# print(image_np_global.shape,depth_np_global.shape)
new_data = True
lock.release()
sleep(0.01)
zed.close()
def display_objects_distances(image_np, depth_np, num_detections, boxes_, classes_, scores_, category_index):
box_to_display_str_map = collections.defaultdict(list)
box_to_color_map = collections.defaultdict(str)
research_distance_box = 30
for i in range(num_detections):
if scores_[i] > confidence:
box = tuple(boxes_[i].tolist())
if classes_[i] in category_index.keys():
class_name = category_index[classes_[i]]['name']
display_str = str(class_name)
if not display_str:
display_str = '{}%'.format(int(100 * scores_[i]))
else:
display_str = '{}: {}%'.format(display_str, int(100 * scores_[i]))
# Find object distance
ymin, xmin, ymax, xmax = box
x_center = int(xmin * width + (xmax - xmin) * width * 0.5)
y_center = int(ymin * height + (ymax - ymin) * height * 0.5)
x_vect = []
y_vect = []
z_vect = []
min_y_r = max(int(ymin * height), int(y_center - research_distance_box))
min_x_r = max(int(xmin * width), int(x_center - research_distance_box))
max_y_r = min(int(ymax * height), int(y_center + research_distance_box))
max_x_r = min(int(xmax * width), int(x_center + research_distance_box))
if min_y_r < 0: min_y_r = 0
if min_x_r < 0: min_x_r = 0
if max_y_r > height: max_y_r = height
if max_x_r > width: max_x_r = width
for j_ in range(min_y_r, max_y_r):
for i_ in range(min_x_r, max_x_r):
z = depth_np[j_, i_, 2]
if not np.isnan(z) and not np.isinf(z):
x_vect.append(depth_np[j_, i_, 0])
y_vect.append(depth_np[j_, i_, 1])
z_vect.append(z)
if len(x_vect) > 0:
x = statistics.median(x_vect)
y = statistics.median(y_vect)
z = statistics.median(z_vect)
distance = math.sqrt(x * x + y * y + z * z)
print("{:.2f} {:.2f} {:.2f}".format(x, y, z))
# display_str = display_str + " " + str('% 6.2f' % distance) + " m "
display_str = display_str + str('% .2f' % x) + "x" + str('% .2f' % y) + "y" + str('% .2f' % z) + "z"
box_to_display_str_map[box].append(display_str)
box_to_color_map[box] = vis_util.STANDARD_COLORS[classes_[i] % len(vis_util.STANDARD_COLORS)]
for box, color in box_to_color_map.items():
ymin, xmin, ymax, xmax = box
vis_util.draw_bounding_box_on_image_array(
image_np,
ymin,
xmin,
ymax,
xmax,
color=color,
thickness=4,
display_str_list=box_to_display_str_map[box],
use_normalized_coordinates=True)
return image_np
def main(args):
svo_filepath = None
if len(args) > 1:
svo_filepath = args[1]
# This main thread will run the object detection, the capture thread is loaded later
# What model to download and load
MODEL_NAME = 'bomb2_model'#1.改为自己的模型文件夹目录
# MODEL_NAME = 'faster_rcnn_nas_coco_2018_01_28' # Accurate but heavy
# Path to frozen detection graph. This is the actual model that is used for the object detection.
PATH_TO_FROZEN_GRAPH = MODEL_NAME + '/frozen_inference_graph.pb'
# Check if the model is already present
if not os.path.isfile(PATH_TO_FROZEN_GRAPH):
print('Failing to initialize model')
# print("Downloading model " + MODEL_NAME + "...")
# List of the strings that is used to add correct label for each box.
# PATH_TO_LABELS = os.path.join('data', 'mscoco_label_map.pbtxt')
PATH_TO_LABELS = os.path.join('data', 'bomb2.pbtxt')#2.改为自己的bptxt文件夹目录
NUM_CLASSES = 5#3.自己模型的类别数
# Start the capture thread with the ZED input
print("Starting the ZED")
capture_thread = Thread(target=capture_thread_func, kwargs={'svo_filepath': svo_filepath})
capture_thread.start()
# Shared resources
global image_np_global, depth_np_global, new_data, exit_signal
# Load a (frozen) Tensorflow model into memory.
print("Loading model " + MODEL_NAME)
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_FROZEN_GRAPH, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
# Limit to a maximum of 80% the GPU memory usage taken by TF https://www.tensorflow.org/guide/using_gpu
config = tf.ConfigProto()
config.gpu_options.per_process_gpu_memory_fraction = 0.8
# Loading label map
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES,
use_display_name=True)
category_index = label_map_util.create_category_index(categories)
# Detection
with detection_graph.as_default():
with tf.Session(config=config, graph=detection_graph) as sess:
while not exit_signal:
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
if new_data:
lock.acquire()
image_np = np.copy(image_np_global)
depth_np = np.copy(depth_np_global)
# print(image_np,depth_np)
new_data = False
lock.release()
image_np_expanded = np.expand_dims(image_np, axis=0)
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Each box represents a part of the image where a particular object was detected.
boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represent how level of confidence for each of the objects.
# Score is shown on the result image, together with the class label.
scores = detection_graph.get_tensor_by_name('detection_scores:0')
classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
# Actual detection.
(boxes, scores, classes, num_detections) = sess.run(
[boxes, scores, classes, num_detections],
feed_dict={image_tensor: image_np_expanded})
num_detections_ = num_detections.astype(int)[0]
# Visualization of the results of a detection.
image_np = display_objects_distances(
image_np,
depth_np,
num_detections_,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index)
print(datetime.datetime.now())
cv2.imshow('object detection', cv2.resize(image_np, (width, height)))
if cv2.waitKey(10) & 0xFF == ord('q'):
cv2.destroyAllWindows()
exit_signal = True
else:
sleep(0.01)
sess.close()
exit_signal = True
capture_thread.join()
if __name__ == '__main__':
main(sys.argv)
7.Android端使用实时检测
7.1 将pb文件转换成tflite文件
- 将生成的模型文件保存,这里用到了tensorflow自己的ssd,因此可以用object_detection目录下的export_tflite_ssd_graph.py文件,如下图所示,最终生成了这两个文件。
python export_tflite_ssd_graph.py --input_type image_tensor --pipeline_config_path ./bomb819/ssd_mobilenet_v2_quantized_300x300_coco.config --trained_checkpoint_prefix ./bomb819/model.ckpt-10000 --output_directory bombtf819

2.下载Bazel的win版本
![]()
3.将下载的exe文件改名为bazel.exe,然后将它放在一个文件夹下,并将位置添加到系统的环境变量path中,就可以成功运行bazel了。
然后用bazel对文件build,获取.pb模型输入输出节点array名称和相关矩阵参数。这里我没有跑成功,具体可以参考我师父的博客,不过如果用tensorflow自己的模型的话也可以不用build,因为名称和相关矩阵可以找到。
4.运行以下py文件就可以生成tflite文件。
# -*- coding:utf-8 -*-
import tensorflow as tf
in_path = r"bombtf\tflite_graph.pb"#1、刚才生成的pb文件地址
#out_path = "tflite_graph.tflite"
# out_path = "./model/quantize_frozen_graph.tflite"
# 模型输入节点
input_tensor_name = ["normalized_input_image_tensor"]
input_tensor_shape = {"normalized_input_image_tensor":[1,300,300,3]}#2.这里是build的结果,也可以在项目的congfig文件中查看,如下图
# 模型输出节点
classes_tensor_name = ['TFLite_Detection_PostProcess','TFLite_Detection_PostProcess:1','TFLite_Detection_PostProcess:2','TFLite_Detection_PostProcess:3']#3、这里也是build的结果,不过tensorflow自己的程序都是这几个名称,可以不用改。
converter = tf.lite.TFLiteConverter.from_frozen_graph(in_path,
input_tensor_name, classes_tensor_name,
input_tensor_shape)
converter.allow_custom_ops=True
converter.post_training_quantize = True#进行量化缩小
tflite_model = converter.convert()
open(r"bombtf\output_detect.tflite", "wb").write(tflite_model)#4.输出tflite文件的地址。


7.2安装android studio
安装java,安装android studio,并运行之后,发现报错,没有sdk,于是在Android Studio的安装目录下,找到\bin\idea.properties,在尾行添加disable.android.first.run=true,表示初次启动不检测SDK。
然后运行,并下载sdk,下载jdk,最后打开官方给的工程文件。
7.2.1将自己生成的tflite文件放在android/app/src/main/assets中,并在这个目录下新建一个txt文件存放自己的识别标签,如下图

7.2.2去掉gradle文件里的一行注释,如图所示

7.2.3修改三处内容(复制关键字,右键app>>find infiles>>输入关键字并打开就可以找到文件)
private static final boolean TF_OD_API_IS_QUANTIZED = true;
private static final String TF_OD_API_MODEL_FILE = "output_detect.tflite";
private static final String TF_OD_API_LABELS_FILE = "file:///android_asset/bombtf.txt";

private static final float MINIMUM_CONFIDENCE_TF_OD_API = 0.30f;#修改阈值
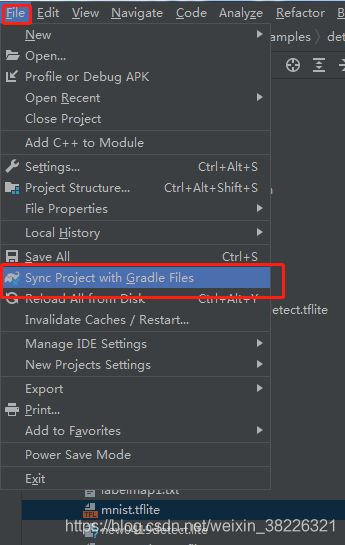
在运行程序时,出现了sdk不兼容问题,于是app那个小绿图标有叉号,而且运行报错No variants found for ‘app’. Check build files to ensure at least one variant exists.。具体的解决方法是:SDK Manager中选中Android 10进行下载,然后 File -> Sync Project with Gradle Files


然后就可以运行到手机,打开设置中的开发人员操作。
8.对训练的图像进行数据增强
首先pip install imgaug,然后运行程序,增强训练数据集,我途中遇到了编码问题,解决方法是在open方式里增加encoding=‘utf-8’,我改的好像是elementtree.py文件。这个py文件新开一个工程在main中粘贴运行,他在这一个工程下运行会出问题。
import xml.etree.ElementTree as ET
import pickle
import os
from os import getcwd
import numpy as np
from PIL import Image
import imgaug as ia
from imgaug import augmenters as iaa
ia.seed(1)
def read_xml_annotation(root, image_id):
in_file = open(os.path.join(root, image_id),encoding='UTF-8')
tree = ET.parse(in_file)
root = tree.getroot()
bndboxlist = []
for object in root.findall('object'): # 找到root节点下的所有country节点
bndbox = object.find('bndbox') # 子节点下节点rank的值
xmin = int(bndbox.find('xmin').text)
xmax = int(bndbox.find('xmax').text)
ymin = int(bndbox.find('ymin').text)
ymax = int(bndbox.find('ymax').text)
# print(xmin,ymin,xmax,ymax)
bndboxlist.append([xmin,ymin,xmax,ymax])
# print(bndboxlist)
bndbox = root.find('object').find('bndbox')
return bndboxlist
def change_xml_list_annotation(root, image_id, new_target,saveroot,id,h,w):
in_file = open(os.path.join(root, str(image_id) + '.xml'),encoding='UTF-8') # 这里root分别由两个意思
tree = ET.parse(in_file)
xmlroot = tree.getroot()
index = 0
aaa = xmlroot.find('path')
#print(aaa)
#aaa.text = 'C:\\Users\\YFZX\\Desktop\\6#\\img_aug\\' + str(image_id) + "_aug_" + str(id) + '.jpg'
for object in xmlroot.findall('object'): # 找到root节点下的所有object节点
bndbox = object.find('bndbox') # 子节点下节点rank的值
# xmin = int(bndbox.find('xmin').text)
# xmax = int(bndbox.find('xmax').text)
# ymin = int(bndbox.find('ymin').text)
# ymax = int(bndbox.find('ymax').text)
new_xmin = new_target[index][0]
new_ymin = new_target[index][1]
new_xmax = new_target[index][2]
new_ymax = new_target[index][3]
xmin = bndbox.find('xmin')
xmin.text = str(new_xmin)
ymin = bndbox.find('ymin')
ymin.text = str(new_ymin)
xmax = bndbox.find('xmax')
xmax.text = str(new_xmax)
ymax = bndbox.find('ymax')
ymax.text = str(new_ymax)
index = index + 1
if new_xmin>0 and new_ymin >0 and new_xmax<w and new_ymax<h:
tree.write(os.path.join(saveroot, str(image_id) + "_aug_" + str(id) + '.xml'))
def mkdir(path):
# 去除首位空格
path = path.strip()
# 去除尾部 \ 符号
path = path.rstrip("\\")
# 判断路径是否存在
# 存在 True
# 不存在 False
isExists = os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(path)
print(path + ' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print(path + ' 目录已存在')
return False
if __name__ == "__main__":
IMG_DIR = r"D:\models-r1.13.0\models-r1.13.0\research\object_detection\bomb819\test" ## 原始图片
XML_DIR = r"D:\models-r1.13.0\models-r1.13.0\research\object_detection\bomb819\test_xml" ## 原始xml
AUG_XML_DIR = r"D:\models-r1.13.0\models-r1.13.0\research\object_detection\bomb819\test_xml_aug" # 存储增强后的XML文件夹路径
mkdir(AUG_XML_DIR)
AUG_IMG_DIR = r"D:\models-r1.13.0\models-r1.13.0\research\object_detection\bomb819\test_aug" # 存储增强后的影像文件夹路径
mkdir(AUG_IMG_DIR)
AUGLOOP = 60 # 每张影像增强的数量
boxes_img_aug_list = []
new_bndbox = []
new_bndbox_list = []
# 影像增强
seq = iaa.Sequential([
iaa.Flipud(0.5), # vertically flip 20% of all images
iaa.Fliplr(0.5), # 镜像
#iaa.Multiply((1.2, 1.5),per_channel=0.2), # change brightness, doesn't affect BBs
#iaa.GaussianBlur(sigma=(0, 3.0)),
#iaa.AdditiveGaussianNoise(loc=0, scale=(0.0, 0.3*255), per_channel=0.5), #### loc 噪声均值,scale噪声方差,50%的概率,对图片进行添加白噪声并应用于每个通道
iaa.Multiply((0.75, 1.5), per_channel=1), ####20%的图片像素值乘以0.5-2中间的数值,用以增加图片明亮度或改变颜色
#iaa.Affine(
# translate_px={"x": 15, "y": 15},
# scale=(0.8, 0.95),
# rotate=(-30, 30)
#), # translate by 40/60px on x/y axis, and scale to 50-70%, affects BBs
iaa.Crop(percent=(0, 0.1),keep_size=True),# 0-0.1的数值,分别乘以图片的宽和高为剪裁的像素个数,保持原尺寸
iaa.Affine(scale=(0.8, 1.5),
translate_percent=None,
translate_px=None,
rotate=(-180, 180),
shear=0.0,
order=1,
cval=0,
mode='constant',)
],random_order= True)
for root, sub_folders, files in os.walk(XML_DIR):
for name in files:
bndbox = read_xml_annotation(XML_DIR, name)
for epoch in range(AUGLOOP):
seq_det = seq.to_deterministic() # 保持坐标和图像同步改变,而不是随机
# 读取图片
img = Image.open(os.path.join(IMG_DIR, name[:-4] + '.jpg'))
img = np.array(img)
#print(img.shape)(h,w,c)
h=img.shape[0]
w=img.shape[1]
# bndbox 坐标增强
for i in range(len(bndbox)):
bbs = ia.BoundingBoxesOnImage([
ia.BoundingBox(x1=bndbox[i][0], y1=bndbox[i][1], x2=bndbox[i][2], y2=bndbox[i][3]),
], shape=img.shape)
bbs_aug = seq_det.augment_bounding_boxes([bbs])[0]
boxes_img_aug_list.append(bbs_aug)
# new_bndbox_list:[[x1,y1,x2,y2],...[],[]]
new_bndbox_list.append([int(bbs_aug.bounding_boxes[0].x1),
int(bbs_aug.bounding_boxes[0].y1),
int(bbs_aug.bounding_boxes[0].x2),
int(bbs_aug.bounding_boxes[0].y2)])
# 存储变化后的图片
image_aug = seq_det.augment_images([img])[0]
path = os.path.join(AUG_IMG_DIR, str(name[:-4]) + "_aug_" + str(epoch) + '.jpg')
# image_auged = bbs.draw_on_image(image_aug, thickness=0)
Image.fromarray(image_aug).save(path)
# 存储变化后的XML
change_xml_list_annotation(XML_DIR, name[:-4], new_bndbox_list, AUG_XML_DIR, epoch,h,w)
print(str(name[:-4]) + "_aug_" + str(epoch) + '.jpg')
new_bndbox_list = []
画出增强后的图像的画框图像
import os
import cv2 as cv
import xml.etree.ElementTree as ET
def xml_to_jpg(imgs_path, xmls_path, out_path):
imgs_list = os.listdir(imgs_path) #读取图片列表
xmls_list = os.listdir(xmls_path) # 读取xml列表
if len(imgs_list) <= len(xmls_list): #若图片个数小于或等于xml个数,从图片里面找与xml匹配的
for imgName in imgs_list:
temp1 = imgName.split('.')[0] #图片名 例如123.jpg 分割之后 temp1 = 123
temp1_ = imgName.split('.')[1] #图片后缀
if temp1_!='jpg':
continue
for xmlName in xmls_list: #遍历xml列表,
temp2 = xmlName.split('.')[0] #xml名
temp2_ = xmlName.split('.')[1]
if temp2_ != 'xml':
continue
if temp2!=temp1: #判断图片名与xml名是否相同,不同的话跳过下面的步骤 继续找
continue
else: #相同的话 开始读取xml坐标信息,并在对应的图片上画框
img_path = os.path.join(imgs_path, imgName)
xml_path = os.path.join(xmls_path, xmlName)
img = cv.imread(img_path)
labelled = img
root = ET.parse(xml_path).getroot()
for obj in root.iter('object'):
bbox = obj.find('bndbox')
xmin = int(bbox.find('xmin').text.strip())
ymin = int(bbox.find('ymin').text.strip())
xmax = int(bbox.find('xmax').text.strip())
ymax = int(bbox.find('ymax').text.strip())
labelled = cv.rectangle(labelled, (xmin, ymin), (xmax, ymax), (0, 0, 255), 2)
cv.imwrite(out_path + '\\' +imgName, labelled)
break
else: # 若xml个数小于图片个数,从xml里面找与图片匹配的。下面操作与上面差不多
for xmlName in xmls_list:
temp1 = xmlName.split('.')[0]
temp1_ = xmlName.split('.')[1]
if temp1_ != 'xml':
continue
for imgName in imgs_list:
temp2 = imgName.split('.')[0]
temp2_ = imgName.split('.')[1] # 图片后缀
if temp2_ != 'jpg':
continue
if temp2 != temp1:
continue
else:
img_path = os.path.join(imgs_path, imgName)
xml_path = os.path.join(xmls_path, xmlName)
img = cv.imread(img_path)
labelled = img
root = ET.parse(xml_path).getroot()
for obj in root.iter('object'):
bbox = obj.find('bndbox')
xmin = int(bbox.find('xmin').text.strip())
ymin = int(bbox.find('ymin').text.strip())
xmax = int(bbox.find('xmax').text.strip())
ymax = int(bbox.find('ymax').text.strip())
labelled = cv.rectangle(labelled, (xmin, ymin), (xmax, ymax), (0, 0, 255), 1)
cv.imwrite(out_path + '\\' +imgName, labelled)
break
if __name__ == '__main__':
# 使用英文路径,中文路径读不进来
imgs_path =r'C:\Users\YFZX\Desktop\models-r1.13.0\models-r1.13.0\research\object_detection\bomb819\train' #图片路径
xmls_path = r'C:\Users\YFZX\Desktop\models-r1.13.0\models-r1.13.0\research\object_detection\bomb819\train_xml' #xml路径
retangele_img_path =r'C:\Users\YFZX\Desktop\models-r1.13.0\models-r1.13.0\research\object_detection\bomb819\train_xml_tojpg' #保存画框后图片的路径
xml_to_jpg(imgs_path, xmls_path, retangele_img_path)
9.模型应用于网络摄像头
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from time import sleep
import numpy as np
import os
import sys
import tensorflow as tf
config = tf.compat.v1.ConfigProto(gpu_options=tf.compat.v1.GPUOptions(allow_growth=True))
sess = tf.compat.v1.Session(config=config)
import cv2
os.chdir(r'E:\models-r1.13.0\models-r1.13.0\research\object_detection')
sys.path.append("..")
# Object detection imports
from utils import label_map_util
from utils import visualization_utils as vis_util
# Model preparation
MODEL_NAME = 'bomb819_model'
PATH_TO_CKPT = MODEL_NAME + '/1_frozen_inference_graph.pb'
PATH_TO_LABELS = os.path.join('data', '1_bomb.pbtxt')
NUM_CLASSES = 5
# Load a (frozen) Tensorflow model into memory.
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
# Loading label map
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES,
use_display_name=True)
category_index = label_map_util.create_category_index(categories)
# Helper code
def load_image_into_numpy_array(image):
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
with detection_graph.as_default():
with tf.Session(graph=detection_graph) as sess:
# Definite input and output Tensors for detection_graph
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Each box represents a part of the image where a particular object was detected.
detection_boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represent how level of confidence for each of the objects.
# Score is shown on the result image, together with the class label.
detection_scores = detection_graph.get_tensor_by_name('detection_scores:0')
detection_classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
# the video to be detected, eg, "test.mp4" here
# url = "rtsp://admin:[email protected]/12"
url = "rtsp://admin:[email protected]/11"
vidcap = cv2.VideoCapture(url)
# Default resolutions of the frame are obtained.The default resolutions are system dependent.
# We convert the resolutions from float to integer.
while (1):
sleep(0.001)
ret, image = vidcap.read()
if ret == True:
image_np = image
#x, y = image_np.shape[0:2]
#image_np= cv2.resize(image_np, (int(y * 2), int(x * 2)))
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
# Actual detection.
(boxes, scores, classes, num) = sess.run(
[detection_boxes, detection_scores, detection_classes, num_detections],
feed_dict={image_tensor: image_np_expanded})
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=2)
#print(scores)
cv2.imshow("capture",image_np)
if cv2.waitKey(1) == ord('q'):
break
vidcap.release()
cv2.destroyAllWindows()
声明下,本人初入职场,菜鸟小白,这个项目是工作接触的第二个任务,全程在小杨师傅的指导下完成,哈哈哈哈,要向优秀的的小杨师傅努力学习呀!加油啦!
工程文件
文件太大,可以留言或私信找我要。
参考
【1】https://blog.csdn.net/weixin_42232538/article/details/111141445
【2】https://my.oschina.net/u/3732258/blog/4698658