ubuntu下100%成功安装torch,同时配置cuda和cudnn
原文:http://blog.csdn.net/hungryof/article/details/51557666
总说
这些更新不影响主体。所有更新附加在文章最后。
第一次更新: 内容:添加一些Torch7常用库的安装,时间:2017.3.20
第二次更新:内容:某些torch库无法在线安装,转成离线安装的方法,时间:2017.3.31
第三次更新:内容:针对安装”cutorch”时出错的问题修复。时间:2017.5.11
第四次更新:内容:加入cudnn6.0的安装。 时间:2017.5.19
第五次更新:内容:解决Missing dependencies for nn:moses >= 1. 问题。 时间:2017.6.4
第六次更新: 内容:解决g++依赖包问题。时间:2017.6.25
第七次更新:内容:为什么有时候luarocks明明安装了包,但是还是出现类似Missing dependencies for nn:moses >= 1的错误??。时间:2017.6.26
第八次更新:内容:如果你的显卡是Jetson Tegra 或是Jeston TK1之类的,或是用到linux是32位的(超级不推荐)跑程序时出现Segmentation fault (core dumped)问题,一种可能可以解决的办法。。。时间:2017.8.10
第九次更新:纪念逝去的Torch7.。。时间:2017.9.8
三个前提:
1. ubuntu别太老,最好14.04或以上吧,本人采用14.04
2. cuda别太老,本人试过cuda7.5和cuda8.0。都完美运行。值得注意的是compute6.1之类的显卡必须是cuda8.0或者更高。反正往高的装没问题。
3. cudnn一定要和cuda版本对应。这是最关键的。比如我以前是普通的泰坦X,就是计算能力5.1的,随便装7.5还是8.0。但是如果是新泰坦X或是1080之类的,计算能力是6.1的, cuda最低是8.0。 版本对应指,如果cuda是7.5的,即cuda-repo-ubuntu1404-7-5-local_7.5-18_amd64,采用的cudnn就要cudnn-7.5-linux-x64-v5.0-ga.tgz,是为cuda7.5准备的cudnn5.0版本。 现在装的是cuda8.0,即cuda-repo-ubuntu1404-8-0-local_8.0.44-1_amd64.deb。采用的是
cudnn-8.0-linux-x64-v5.1.tgz。
安装与测试
用一个例子来跑,从而验证torch以及cuda和cudnn是否安装成功。
我推荐这个。
参考:链接:https://github.com/jcjohnson/neural-style/blob/master/INSTALL.md
neural-style
安装torch7
直接用torch自带脚本
git clone https://github.com/torch/distro.git ~/torch --recursive
cd ~/torch; bash install-deps;
./install.sh- 1
- 2
- 3
这里可能会出现的问题,在 坑一中。
如果出现Missing dependencies for nn:moses >= 1. ,请参照博客的附加部分
接下来,它会提示是否吧torch加入bashrc中,有”….(yes|no)”提示,输入yes,即可。
为了保险,可以看看bashrc文件
vim ~/.bashrc- 1
查看文档末尾是不是有类似
./home/xxx/torch/install/bin/torch-activate- 1
上面是你torch安装的路径。
然后跟新一下环境变量。
source ~/.bashrc- 1
然后
th- 1
会出现 
现在来说,基本的torch就安装好了!!!就是这么简单。但是你可能还想装cuda,其实也很简单。
下载配置neural style(仅仅用于测试cpu和GPU的对比程序,真心可以省略。。)
安装其他依赖库
sudo apt-get install libprotobuf-dev protobuf-compiler
luarocks install loadcaffe- 1
- 2
下载neural style代码
cd ~/
git clone https://github.com/jcjohnson/neural-style.git
cd neural-style- 1
- 2
- 3
安装VGG模型
sh models/download_models.sh
CPU版本的测试
th neural_style.lua -gpu -1 -print_iter 1- 1
- 2
- 3
- 4
若出现
[libprotobuf WARNING google/protobuf/io/coded_stream.cc:505] Reading dangerously large protocol message. If the message turns out to be larger than 1073741824 bytes, parsing will be halted for security reasons. To increase the limit (or to disable these warnings), see CodedInputStream::SetTotalBytesLimit() in google/protobuf/io/coded_stream.h.
[libprotobuf WARNING google/protobuf/io/coded_stream.cc:78] The total number of bytes read was 574671192
Successfully loaded models/VGG_ILSVRC_19_layers.caffemodel
conv1_1: 64 3 3 3
conv1_2: 64 64 3 3
conv2_1: 128 64 3 3
conv2_2: 128 128 3 3
conv3_1: 256 128 3 3
conv3_2: 256 256 3 3
conv3_3: 256 256 3 3
conv3_4: 256 256 3 3
conv4_1: 512 256 3 3
conv4_2: 512 512 3 3
conv4_3: 512 512 3 3
conv4_4: 512 512 3 3
conv5_1: 512 512 3 3
conv5_2: 512 512 3 3
conv5_3: 512 512 3 3
conv5_4: 512 512 3 3
fc6: 1 1 25088 4096
fc7: 1 1 4096 4096
fc8: 1 1 4096 1000
WARNING: Skipping content loss
Iteration 1 / 1000
Content 1 loss: 2091178.593750
Style 1 loss: 30021.292114
Style 2 loss: 700349.560547
Style 3 loss: 153033.203125 - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
表示如果这一步都到不了的话,难度挺大。
安装cuda
这个如果你以前装过就不用再装了,其实就是个环境嘛,默认是安装在类似/usr/local/cuda-8.0的。安装的时候它会创建一个软链接,类似windows的快捷方式。
直接从官网上下载对应版本的cuda 。然后deb文件直接双击安装。你别以为这个deb安装完了,cuda就安装好了,其实还有附加的库,也是要安装的。这些要通过命令行来进行。
sudo apt-get update
sudo apt-get install cuda- 1
- 2
上面的apt-get安装的cuda会根据你的deb的cuda的版本的不同,而安装相应的库。比如你如果是采用cuda8.0的deb,那么此时上面会出现一堆cuda8.0-之类的文件名的库。
最后再试试是否安装好了cuda
nvidia-smi- 1
出现你的显卡配置信息的话,就ok。 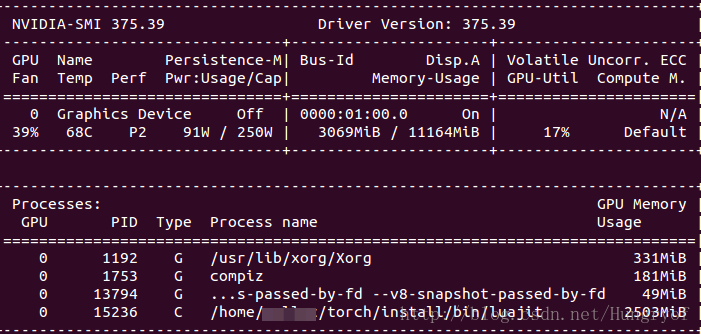
安装torch的cuda支持
刚才装的cuda是通用的,是所有的程序框架都可以用的啊。但是你让torch用cuda的话,还要安装2个库cutorch和cunn。cutorch是让torch能用GPU,而cunn是专门针对神经网络,让神经网络运行于GPU之上。其实torch安装相应的其他库还是很简单的,直接一条命令搞定。
luarocks install cutorch
luarocks install cunn- 1
- 2
注意:安装cutorch可能会出错。方法见博文最后面
测试一下
th -e "require 'cutorch'; require 'cunn'; print(cutorch)"- 1
此时到这里应该还是妥妥的.
安装cudnn
其实cudnn就是一些链接库,怎么安装呢。把cudnn的头文件放入和相应的链接库放入cuda路径的相应位置就行了。显然头文件是放入include文件夹中,而链接库是放入lib64文件夹中。因此有
下面先安装cudnn5.1的,然后直接luarocks install cudnn,现在默认的是cudnn5.x。如果想要安装cudnn6.0的,请看文章附加。
tar -xzvf cudnn-8.0-linux-x64-v5.1.tgz
sudo cp cuda/lib64/libcudnn* /usr/local/cuda-8.0/lib64/
sudo cp cuda/include/cudnn.h /usr/local/cuda-8.0/include/- 1
- 2
- 3
最后在安装torch的cudnn支持
luarocks install cudnn- 1
测试一下:
th neural_style.lua -gpu 0 -backend cudnn- 1
几乎是百分百成功的,妥妥的,可能会出现坑二。
测试一下
(注意:没通过可能是由于特定误差阈值设置的问题,如今他们也不更新了,所以你就当没问题用就行,否则建议能转则转啊,顺带说一句,,用了快2年了,貌似还没发现哪个函数有问题。)
cd ~/torch
./test.sh- 1
- 2
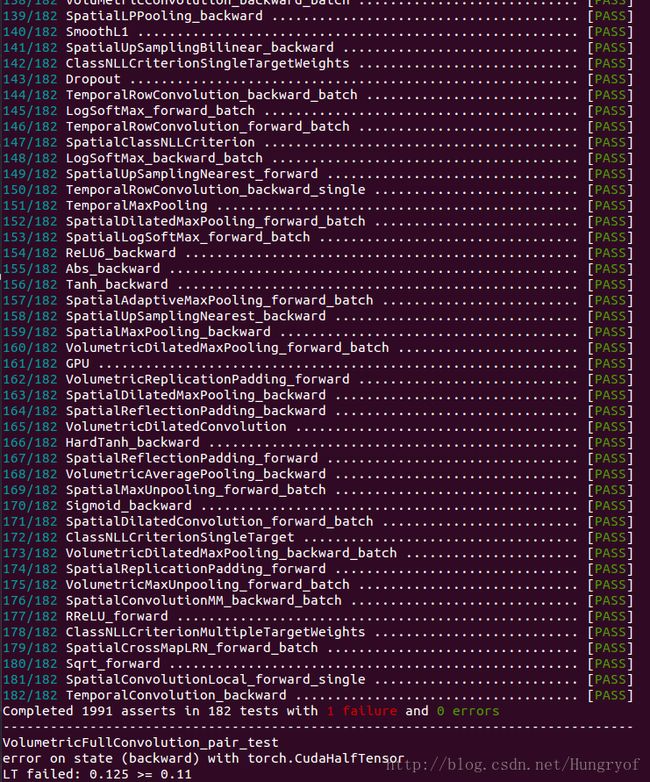
只有一个错误,在VolumetricFullConvolution_pair_test中,但是我应该用不到这个卷积,所以问题不大。
吓人的是,半天后再测试一下时,又诡异的没错误了。。这么不稳定,退torch,保平安。 
坑1:torch的依赖库很多!!
curl -s https://raw.githubusercontent.com/torch/ezinstall/master/install-deps | bash- 1
运行这个时,一定会经过较长时间的安装!!!!由于我这里的网很差,所以如果你的也有类似的情况,那么可能会出现:“xxx 校验和不符”。这时说明完全没有安装依赖库好吧!!我以前以为已经装好了,直接下完neural-style,然后./install.sh。我擦,结果出现什么cmake not found之类的。然后我还傻乎乎的去 sudo apt-get install cmake。结果又出现其他乱七八糟的,现在就是一句话:bash install-dep是把所有的依赖库都会安装好!!并且安装完之后会有类似提示:“torch dependencies have already installed.”。 如果一致出现什么校验和不符这类问题,那么就更换源,最靠谱的方法不是根据网上所说的从“网易源”或是“搜狐源”加入到sudo vim /etc/apt/source.list之类的,这都不靠谱!最有效的方法是,右上角–>系统设置–>软件和更新—>Ubuntu软件—>下拉选择框–>其他站点—>选择最佳服务器,过段时间,测试结束后,就会显示最好的服务器,然后选择确定。关闭时会让你重新载入源,点击确定即可。
坑2 可能出现’libcudnn not found in library path’的情况
截取其中一段错误信息:
Please install CuDNN from https://developer.nvidia.com/cuDNN
Then make sure files named as libcudnn.so.5 or libcudnn.5.dylib are placed in your library load path (for example /usr/local/lib , or manually add a path to LD_LIBRARY_PATH)- 1
- 2
LD_LIBRARY_PATH是该环境变量,主要用于指定查找共享库(动态链接库)时除了默认路径之外的其他路径。由于刚才已经将
“libcudnn*”复制到了/usr/local/cuda-8.0/lib64/下面,因此需要
方法一:
1. sudo gedit /etc/ld.so.conf.d/cudnn.conf 就是新建一个conf文件。名字随便
2. 加入刚才的路径/usr/local/cuda-8.0/lib64/
3. 反正我还添加了/usr/local/cuda-8.0/include/,这个估计不要也行。
4. 保存后,再sudo ldconfig来更新缓存。(可能会出现libcudnn.so.5不是符号连接的问题,不过无所谓了!!若要解决这个问题,可以看哈哈)
方法二(这个简单):
直接
vim ./.bashrc- 1
然后在最后添加
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBARARY_PATH- 1
此时运行
th neural_style.lua -gpu 0 -backend cudnn- 1
成功了!!!! 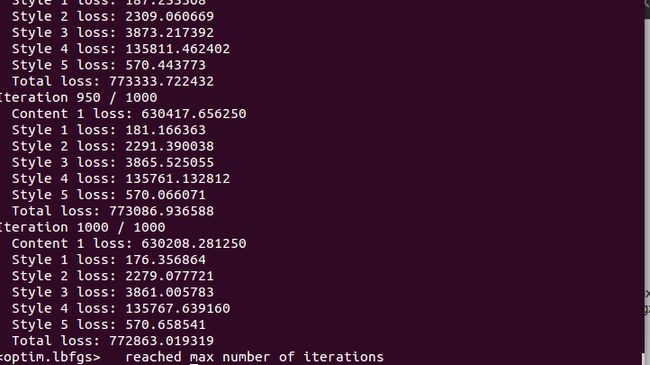
发现用cudnn时,变成50个50个一显示了,速度快了些。刚才但存用cuda只是1个1个显示的。不说了,歇会儿。
总结
一定要版本对应!!cuda和cudnn的版本一定要对应,对应!!!!
HDF5安装
torch中如果直接
luarocks install hdf5- 1
是会出错的。要这样:
sudo apt-get install libhdf5-serial-dev hdf5-tools
git clone https://github.com/deepmind/torch-hdf5
cd torch-hdf5
luarocks make hdf5-0-0.rockspec LIBHDF5_LIBDIR="/usr/lib/x86_64-linux-gnu/"- 1
- 2
- 3
- 4
具体的一些用法参照
DeepMind
各种问题汇总方案
记录一下装了n遍torch,总结出来的各种问题解决方案。
其他一些可能会用到的库
下面三个分别是加载caffe的model要用到的库, 自动求导的库,以及自定义初始化参数的库。
luarocks install loadcaffe
luarocks install autograd
luarocks install nninit- 1
- 2
- 3
安装loadcaffe前要先安装
sudo apt-get install libprotobuf-dev protobuf-compiler- 1
其中loadcaffe可能会因为人品不好,直接这样安装不成功!此时查看下文的离线安装torch库。
还有就是可能希望将loss或是图片在浏览器中显示出来的库display
luarocks install https://raw.githubusercontent.com/szym/display/master/display-scm-0.rockspec- 1
你可能还需要将torch的tensor转换成numpy的数组,以便利用Python的库进行操作。这时候你需要
luarocks install npy4th- 1
值得注意的是,由于Torch的table是从1开始的,而python是从0开始的。它是会自动转换的,所以无需担心。
最后抱怨一下,都多少年没更新了啊。。 
看看别人TF。。 
最后的最后,再次强调!退Torch,保平安。。
离线安装torch库
我们知道torch安装库还是很简单的。直接luarocks install xxx。但是有时候怎么都安装不了某些库。比如luarocks install loadcaffe
这时候直接找github的源码,下载离线安装
git clone https://github.com/szagoruyko/loadcaffe.git
cd loadcaffe
luarocks make loadcaffe-xxx- 1
- 2
- 3
搞定了。
cutorch安装出错解决方法
以前是不会错的,但是如今他们更新了THCTensor后,就会出错了。 The problem is the latest commit these guys have pushed into master in THCTensor file.
I made a local copy of the repo. Took out the problem some code and installed
it using luarocks. Worked for me
这个问题是因为:distro安装的各种包的稳定版本,会滞后于各个包几个月时间。如果要单独更新某个包可以用下面的
解决方法:先要用luarocks安装一下torch,这会更新distro的torch7的包。
luarocks install torch
luarocks install cutorch- 1
- 2
cudnn6.0
首先当然安装类似cudnn-8.0-linux-x64-v6.0.tgz,然后
git clone https://github.com/soumith/cudnn.torch -b R6
cd cudnn.torch
luarocks make- 1
- 2
- 3
另外,现在貌似是torch.cudnn没优化好??毕竟还不是master分支,关键是你装上之后,跑我那个程序速度好像没提升啊。说好的2x速度提升呢。。。
执行./install.sh时出现Moses>=1.错误
Missing dependencies for nn:moses >= 1.,有时候执行./install.sh时,会出现这个问题。
一句话:网速差啊网速差!你可能会说自己网速不差,这个问题当且仅当网速出问题时才会出现
解决办法
luarocks install moses- 1
是没有用的!你得单独下载
Moses,然后参照博客前面提到的离线安装torch库的办法,安装完Moses后,就可以正确安装torch了。
g++依赖包问题
这个问题很可能是因为改了源造成的。直接用Ubuntu14.04的官方源就行,其他版本的也用对应的源即可。 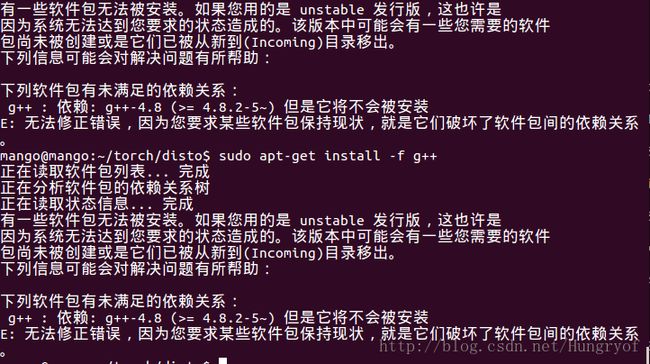
更改/etc/apt/source.list,再末尾加上下面的源,然后update
deb http://archive.ubuntu.com/ubuntu/ trusty main restricted universe multiverse
deb http://archive.ubuntu.com/ubuntu/ trusty-security main restricted universe multiverse
deb http://archive.ubuntu.com/ubuntu/ trusty-updates main restricted universe multiverse
deb http://archive.ubuntu.com/ubuntu/ trusty-proposed main restricted universe multiverse
deb http://archive.ubuntu.com/ubuntu/ trusty-backports main restricted universe multiverse
deb-src http://archive.ubuntu.com/ubuntu/ trusty main restricted universe multiverse
deb-src http://archive.ubuntu.com/ubuntu/ trusty-security main restricted universe multiverse
deb-src http://archive.ubuntu.com/ubuntu/ trusty-updates main restricted universe multiverse
deb-src http://archive.ubuntu.com/ubuntu/ trusty-proposed main restricted universe multiverse
deb-src http://archive.ubuntu.com/ubuntu/ trusty-backports main restricted universe multiverse- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
为什么有时候luarocks明明安装了包,但是还是出现类似Missing dependencies for nn:moses >= 1的错误??
以前我直接是讲distro包放在主目录下的torch文件夹内的,然后进行安装。一般这样安装就是luarocks安装的所有的包,默认在/home/xxx/torch/install内的。然而诡异的是,有时候离线安装mose包,会出现 
这说明luarocks竟然安装在/usr/lib下面了。所以我们需要指定mose的安装路径!否则./install是从/home/xxx/torch/install找已经安装的包的。
解决方案:
luarocks make --tree /home/xxx/torch/install rockspec/moses-1.6.1-1.rockspec- 1
其中–tree是指定moses的安装路径。
Segamentation Fault错误的可能解决办法
如果你的显卡是**Jetson Tegra 或是Jeston TK1之类的,或是用到linux是32位的(超级不推荐)跑程序时出现Segmentation fault (core dumped)。
办法:使用Lua5.2而不是默认的LuaJIT, 然而令人头大是是如果模型超过2GB,就会出错~~
使用Lua5.2的方法见官网 http://torch.ch/docs/getting-started.html
逝去的Torch7
前几天,传来噩耗!突然出现Torch的distro的Readme更新,一看: 
这标志着Torch正式进入维护模式。额,其实也无所谓了,自从pytorch出来后,就几乎没有更新。。所以,你还看torch博客干嘛啊,赶紧转啊!!!!