机器学习模型自我代码复现:GBDT
根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述,仅罗列自己将要使用到的部分公式。
如文中或代码有错误或是不足之处,还望能不吝指正。
集成学习,通过构建并结合多个学习器来完成学习任务。集成学习大抵可以分为2类,1类是将各个弱学习器串联训练,使得前一个学习器中的错类在后一个学习器中被更加“重视”以提升总体的训练效果,被称为Boosting;另一类是并联训练多个弱学习器,将他们的结果结合起来(平均法或投票法)组成一个强学习器,被称为Bagging。
GBDT是一类Boosting学习器,改造自AdaBoost,是AdaBoost的推广(一般形式)。
AdaBoost的策略是:将前一个学习器中的错类,在放入下一个学习器时提升权重,如此重复进行,使用加法模型获得结果。

其中,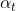 表示学习器的学习率,
表示学习器的学习率,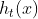 代表第t个学习器的预测结果。AdaBoost的损失函数为指数损失函数。
代表第t个学习器的预测结果。AdaBoost的损失函数为指数损失函数。
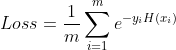
GBDT与AdaBoost的逻辑大抵相同,但是不同的是:
AdaBoost拟合的是根据上一个学习器的权重以及误差进行拟合,而GBDT拟合的是负梯度。
GBDT不再限制损失函数为指数损失函数。
下文中的GBDT的基学习器为CART树,因此在每棵树拟合负梯度时,任然按照CART回归树的最佳选择节点的方法。
from scipy.optimize import minimize
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import train_test_split
import random
class GBDT_CART:
def __init__(self,data,labels,n_estimators,max_feature_ratio = 1.0,max_sample_ratio=1.0,max_depth = None,learning_rate=0.1):
"""
初始化
data:自变量
labels:因变量
n_estimators:弱学习器个数
max_feature_ratio:每个弱学习期最多使用的特征个数
max_sample_ratio:每个弱学习期最多使用的样本个数
max_depth:每个弱学习器(CART树)的最大深度
feature_idxs:保存每棵树所用到的特征下标
trees:保存每棵树
learning_rate:学习率
"""
self.trees = []
self.n_estimators = n_estimators
self.origin_data = data
self.origin_labels = labels
self.sample_num = int(max_sample_ratio*data.shape[0])
self.feature_sample_num = max(1,int(max_feature_ratio*data.shape[1]))
self.max_depth = max_depth
self.data_num = data.shape[0]
self.feature_num = data.shape[1]
self.feature_idxs = []
self.learning_rate = learning_rate
def init_value(self,y):
"""
初始化将因变量的均值作为初始值
"""
return np.array([sum(y)/len(y) for _ in range(len(y))])
def get_residual(self,y_pred,y_real):
"""
计算残差,此处就是CART回归树的损失函数1/2(y-y_hat)^2的梯度的负方向
y_pred:预测值
y_real:真实值
"""
return np.array([y_real[i]-y_pred[i] for i in range(len(y_pred))])
def train(self):
"""
根据样本训练模型
"""
#初始化为所有值的均值
self.y_first = self.init_value(self.origin_labels)
residual_res = [self.get_residual(self.y_first,self.origin_labels)]
for i in range(self.n_estimators):
tree = DecisionTreeRegressor(max_depth=self.max_depth)
idxs = random.sample(range(self.data_num),self.sample_num)
feature_idx = random.sample(range(self.feature_num),self.feature_sample_num)
feature_idx.sort() #这一步是需要加的,否则特征index乱序,会导致每个树的特征对应不上
self.feature_idxs.append(feature_idx)
data = self.origin_data[idxs,:]
data = data[:,feature_idx]
tmp_label = residual_res[-1][idxs]
self.trees.append(tree)
tree.fit(data,tmp_label)
#将训练集中的所有值都计算一遍残差,到了下一棵树时进行采样完毕后,取出所需要的部分训练
y_hat = self.y_first + np.sum([self.learning_rate*one_tree.predict(self.origin_data[:,feature_idx]) for one_tree in self.trees],axis=0)
resid = self.get_residual(y_hat,self.origin_labels)
residual_res.append(resid)
def predict(self,data):
"""
根据传入特征预测值
data:特征矩阵
"""
res = self.y_first[0]*np.ones(data.shape[0])
for i in range(self.n_estimators):
tree=self.trees[i]
data_tmp = data[:,self.feature_idxs[i]]
res += tree.predict(data_tmp)*self.learning_rate
return res
def score(self,data,label):
"""
根据传入特征计算预测值的均方误差
data:特征矩阵
label:真值
"""
return sum(np.square(gbdt.predict(data)-label))/len(label)使用mpg(汽车排放量)测试一下。
df = pd.read_excel('mpg.xlsx')
df = df.iloc[:,range(6)]
df.replace("?",pd.NA,inplace=True)
df.dropna(axis=0,inplace=True)
y = df.iloc[:,0]
x = df.iloc[:,range(1,5)]
x_train,x_test,y_train,y_test = train_test_split(x,y)
gbdt = GBDT_CART(x_train.values,y_train.values,n_estimators=100)
gbdt.train()
gbdt.score(x_test.values,y_test.values)
"""
自己实现的gbdt的均方误差为
24.5970620946798
"""
res1 = gbdt.predict(x_test.values)
from sklearn.ensemble import GradientBoostingRegressor
skGBDT = GradientBoostingRegressor()
skGBDT.fit(x_train,y_train)
res2 = skGBDT.predict(x_test.values)
sum(np.square(res2-y_test.values))/len(res2)
"""
sklearn的GBDT的均方误差为16.591827373079223
"""import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rcParams["font.family"]="SimHei"
plt.figure(figsize=(10,10))
plt.subplot(2,2,1)
plt.plot(res1,c="orange")
plt.title("GBDT预测值")
plt.subplot(2,2,2)
plt.title("sklearn-GBDT预测值")
plt.plot(res2,c="green")
plt.subplot(2,2,3)
plt.title("真实值")
plt.plot(y_test.values,c="red")
plt.show()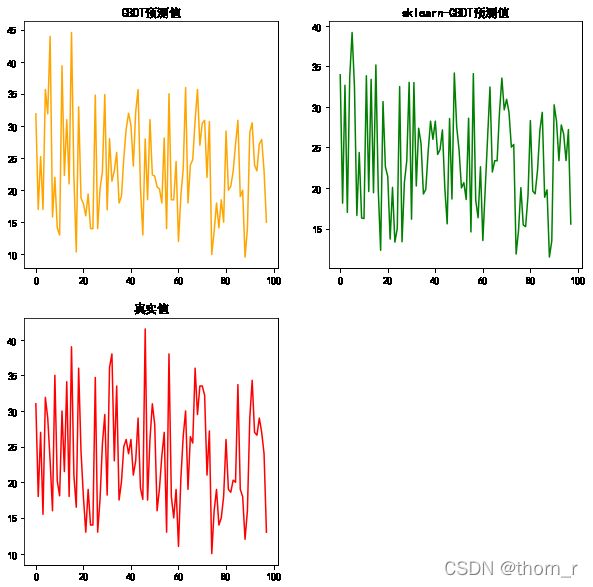
自己的简单实现和sklearn的GBDT有着一定的差距,但是在特征量与数据量较小时,具备基础的训练预测功能。