AI中文语音克隆、语音合成——GitHub上babysor/MockingBird 项目源码部分功能实现
AI中文语音克隆、语音合成——GitHub上babysor/MockingBird 项目源码部分功能实现
第一次独立地从认识一项技术,然后到github上搜索相关代码,跟着ReadMe.md教学文档将项目的功能实现部分复现。目前并没有涉及训练数据集的部分功能,是接受了作者建议,使用别人训练好的模型,最终的效果虽然差强人意,但还是为能够独立复现部分功能而高兴,从最终的结果也能稍稍感受到这项技术的强大。在实现的过程中也积累了部分经验,所以在此记录历程。
文章结尾附有调试好的项目源码,项目环境准备好后下载解压运行即可,亲测有效。
项目地址:https://github.com/babysor/MockingBird
先找到项目中的项目准备部分:

先在anaconda上新建一个环境,在这个环境里安装相应的包。
打开Anaconda Prompt ,输入conda create -n voice_clone python=3.9 -n是说明环境的名字,后面的voice_clone可以换成你想要的名字,在后面的python=3.9指定python的版本是3.9的,安装文档里说要3.7版本以上,而且3.9在安装pytorch时没有问题,所以就安个3.9版本的python。
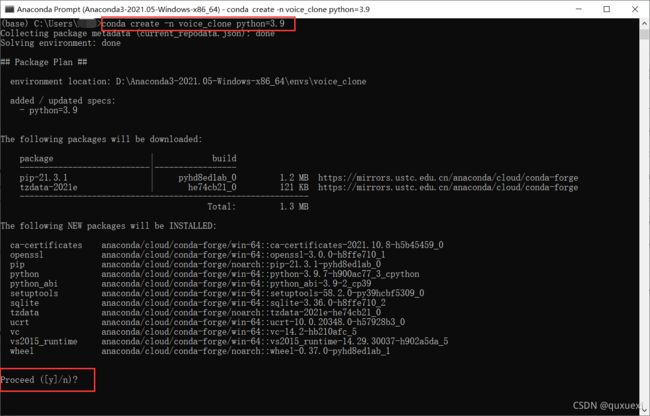
输入y,然后回车。(y是指yes,表示同意安装)
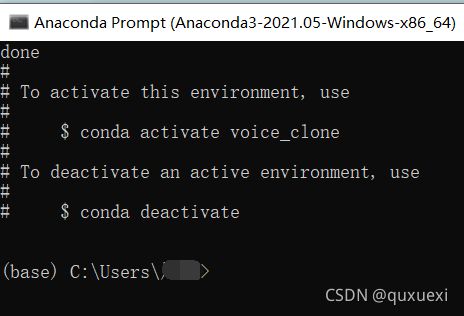
这样环境就创建成功了。可以用conda env list查看已经安装的环境。
安装PyTorch
激活刚刚创建的环境。输入activate voice_clone进入刚建的环境。接下来安装PyTorch

我直接复制了推荐版本的安装代码到voice_clone环境下安装
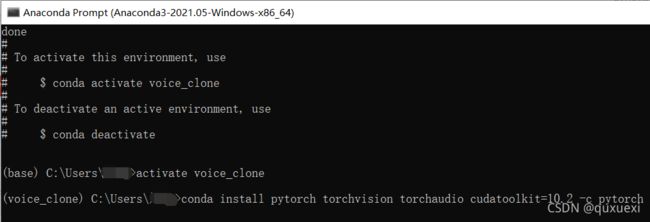
展示需要安装的东西后,我们输入y进行安装
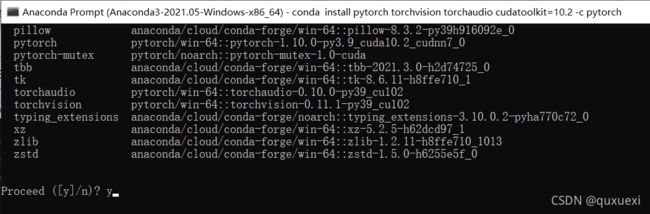
安装成功后输入pip list查看是否有pytorch相关的包
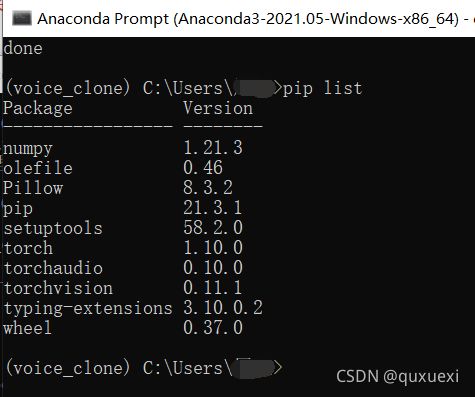
安装ffmpeg
下一步的安装ffmpeg的步骤,因为之前电脑上安装过了,就不演示了,有需要的可以查看相关教程进行安装。
下载项目源码
上述操作完成之后就可以到GitHub上下载源码了
源码链接:https://github.com/babysor/MockingBird
进入后下载源码压缩包到本地,解压后用pycharm打开

Pycharm中设置项目的解释器
在pycharm中项目的解释器使用我们新建的环境voice_clone中安装的python解释器
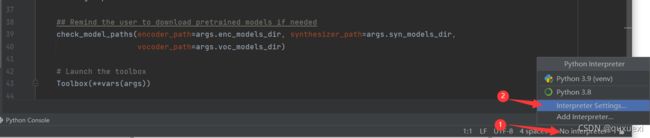
进入seting界面后,我们给当前项目添加一个新的解释器,按下图操作

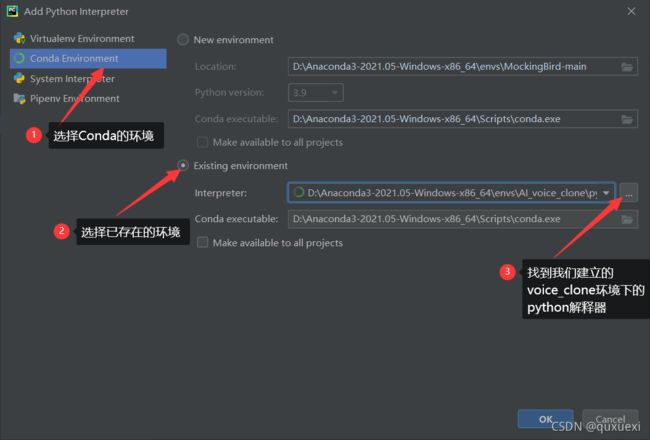
如下图,点击OK,这样项目的解释器就设置好了。
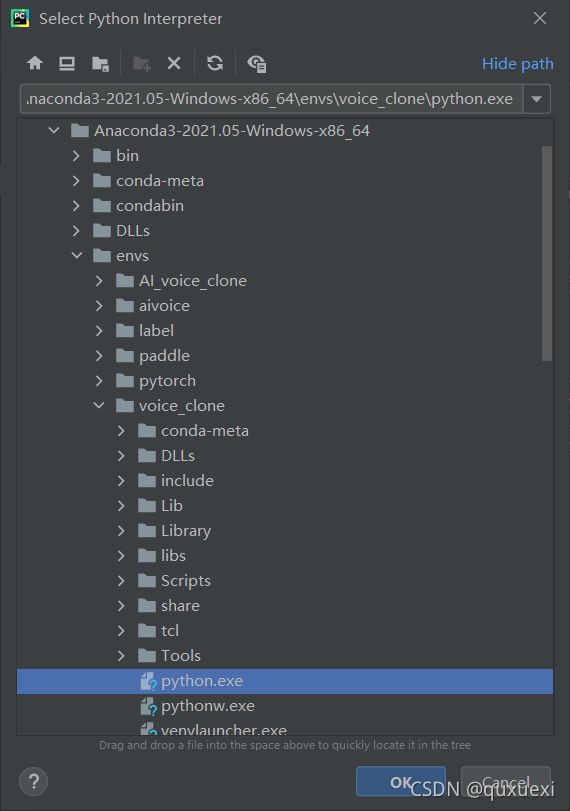
设置好后在这个界面里也能查看当前解释器环境中已经安装好的包,之后再添加requirement.txt中的包时可以在这里查看是否安装成功,
还有一种查看的方法就是进入pycharm最下面的Terminal终端里输入pip list也可以查看的。
进入终端安装requirements.txt中所需的包
在Terminal中输入pip install -r requirements.txt 进行安装

同样的方法安装pip install webrtcvad-wheels
至此,项目所需的环境基本安装完成了,接下来就是研究源码,修改参数,运行代码,测试功能的故事了。
进入快速上手实现阶段
项目中作者给出了两种方案,一种是训练自己的合成器模型,另一种是使用别人训练好的合成器模型,这里因为时间有限,就选择别人训练好的合成器模型进行功能复现。
下载合成器模型文件
作者给出三个模型供大家下载使用,我下载了第一个和第三个,
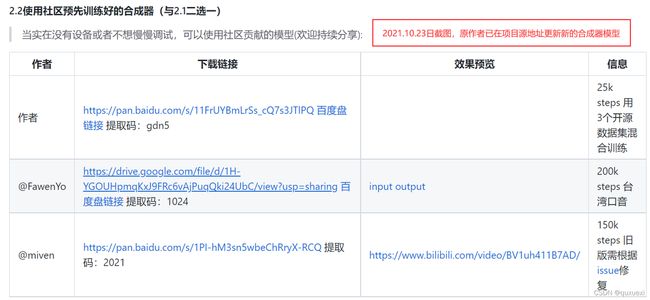
下载的第一个是一个my_run.pt文件,第三个是三个合成器的模型文件,先下载下来,留着接下来放到项目中。
旧合成器网盘链接:
链接:https://pan.baidu.com/s/12fSaYv5qEn59IkKGEbIU1A
提取码:kxzz
最新的合成器模型可以到GitHub项目下方的说明中下载(已经更新了新的模型)。
修改项目文件
检擦encoder、synthesizer、vocoder这三个目录下有没有saved_models目录,saved_models里就是存放合成器模型的地方,如果没有saved_models目录就自己创建一个,否则缺少的话运行demo_toolbox.py时会报错。报错如下:
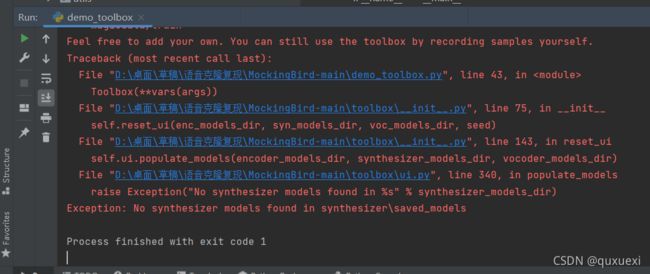
我下载的源码中synthesizer目录下没有saved_models目录,于是我自己创建了一个.
然后将下载的第一个合成器模型my_run.pt复制到synthesizer目录下的saved_models目录中

这时候再运行demo_toolbox.py文件,运行成功,并弹出操作的小界面。

至此,项目文件的修改就完成了。(直接使用别人训练好的合成器模型不需要修改源码中的任何参数)
准备wav音频文件,试着进行语音合成与克隆
项目似乎不支持MP3文件,但支持wav形式的音频文件,从本地导入MP3文件会报错:

所以需要先将我们的MP3文件转换成wav文件,在百度上搜 在线 MP3转wav 转换。
使用网站:https://www.aconvert.com/cn/audio/wav-to-mp3/
点击 Rrowse(打开本地) ,从本地导入wav格式音频文件
模型可以选择如下图的组合

接着进行语音合成
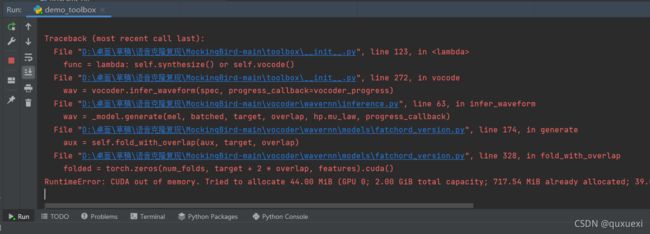
Error展示
点击合成后可能会出现报错,说超出内存了
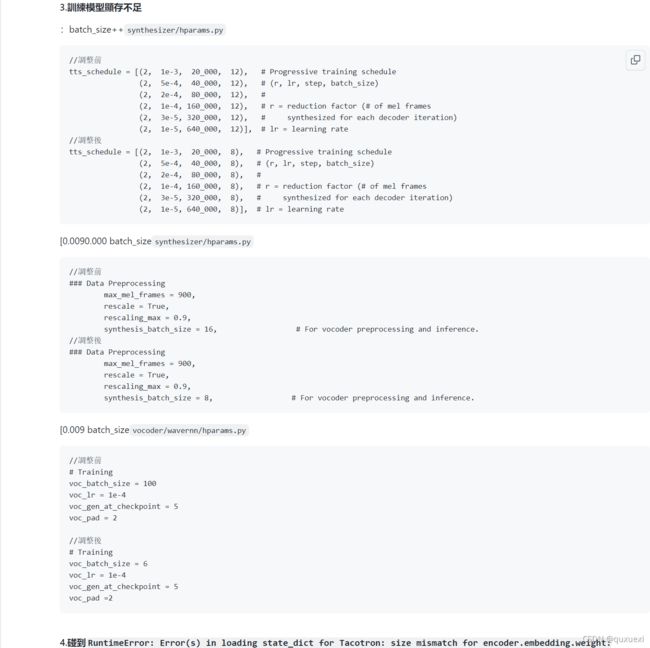
我们可以参考作者给出的解决办法进行修改,调整batch_size.(所谓Batch就是每次送入网络中训练的一部分数据,而Batch Size就是每个batch中训练样本的数量)
终止程序后,重新运行demo_toolbox.py,然后重新从本地导入文件,重新合成。
结果又出现了可能的报错:

先结束进程,然后可以参考
https://github.com/babysor/MockingBird/issues/37
大概就是修改synthesizer/utils/symbols.py中的一行代码:
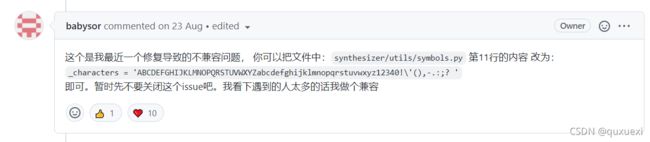
改完之后运行,重新运行demo_toolbox.py,然后重新从本地导入文件,重新合成。
如果试过还方法后还是出现类似的报错,可以讲style的值调大一点(原理还不清楚)

之后运行应该就不会报错了。
手动分割线--------------------------------------------------------------------------------------------------------------------------
上面的内容是10月24日编写的,当时想着再次复现一下这个项目,结果发现搞不明白了,因为合成的效果一直很不好。现在下载的源码和之前在10月20日下载项目源码有些变化,从界面也可以看出来发现
这是在10月20日下载的版本调试的界面。所以为了弥补这次的翻车,我把之前调试好的源码分享在这里供大家下载玩玩。
链接:https://pan.baidu.com/s/14lafr_3aa7AiLKnjyEjv5Q
提取码: kxzz
下载并解压之后。(环境啥的要先配置好哈)直接运行demo_toolbox.py文件,点击 Browse(打开本地) 上传本地wav格式音频文件
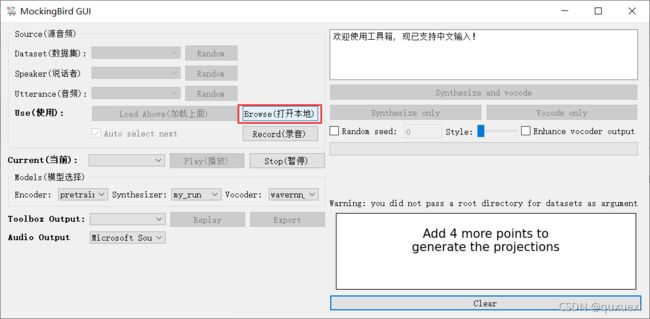
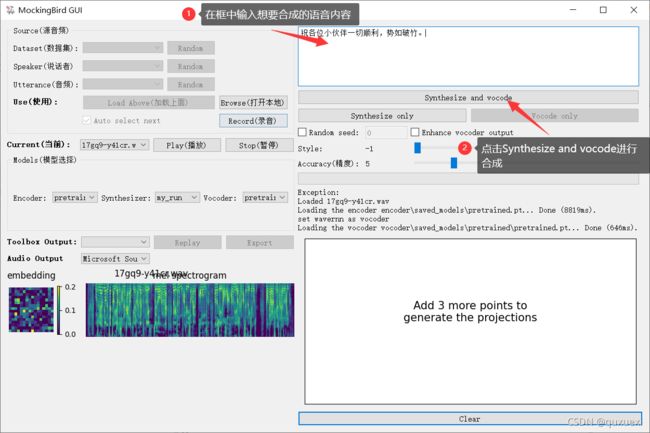
在合成语音之前最好把 Enhance vocoder output 勾选上(这样会清晰一些),然后点击 Synthersize and vocoder 进行合成

合成小技巧
在每次合成语音时,可以先点击 Synthersize only ,观看输出的波形,如果输出的波形看起来都连在一起,大概率合成的效果不好,这时可以增大 Style 的值试试。
当观察到输出的波形像下面的这个一样,两个字中间有明显的间隔,然后就可以点击 Vocode only 对当前的波形进行语音合成。

好了,分享就到这,thank you。