文献17.DL、PHY、自编码器、RTN、CNN调制分类
文献原文:https://arxiv.org/pdf/1702.00832.pdf
文献详解参考,请看这位大神的:【文献笔记】【精读】An Introduction to Deep Learning for the Physical Layer_ndwuhuangwei的博客-CSDN博客
目录
An Introduction to Deep Learning for the Physical Layer
一、读文献
1.INTRODUCTION
1-A.讨论了DL对物理层的潜在优势
1-B.介绍了ML in WC工作
2.深度学习基础
3.作者提出的几个DL在通信的应用
3-A端到端自动编码通信系统
3-B多对收发机的自动编码器
3-C RTNs 增强信号处理算法的无线电转换网络
3-D CNNs分类任务
4.概述并挖坑
4-A 数据集和挑战
4-B 数据表示,损失函数,和训练信噪比
4-C 复数域神经网络
4-D DL大量的数据处理
4-E 端到端学习的系统识别
4-F从CSI中学习并超越
5.总结
二、复现
1.搭环境
2.自编码器
2.1源码运行结果
2.2源码分析
三、写作手法笔记
An Introduction to Deep Learning for the Physical Layer
Tim O’Shea, Senior Member, IEEE, and Jakob Hoydis, Member, IEEE
期刊:IEEE Transactions on Cognitive Communications & Networking
一、读文献
这篇文章主要介绍了DL在通信物理层的几个应用。
1.首先是将通信系统用一个自动编码器的形式,将发射机和接收机看做为一个整体,实现端到端的传输。
2.在自动编码器的基础上,扩展到多个收发器的网络,并提出了RTNs(radio transformer networks)无线电转换网络的概念,让通信领域的专家知识纳入到机器学习中。
3.讨论了CNNs在原始IQ样本中对于调制分类的应用。与传统方案相比,没有过于依赖专家特征,并具有较高的准确性。
1.INTRODUCTION
DL or ML 在通信领域中有较高门槛。
(1)通信是一个很成熟的领域,且在很多传统研究上已经将性能提升得很高了,出现了性能提升的瓶颈。因此,机器学习应用于通信领域在性能上要通过很高的门槛,才能提供切实的新的好处。
(2)通信与CV和NLP(自然语音处理)领域的区别:这两个领域很难用严格的数学模型、传统算法实现,如图像检测手写数字。但是通信中的信道、系统模型、信号检测等都有很好的数学模型和算法可以实现。
第三段说,在难以用简单的数学模型描述的复杂通信场景中,希望可以用DL的方式去提高性能。谈到本篇文章的主要贡献。
(3)①对于一个给定信道模型,发射机和接收机的实现,通过学习他,使损失函数最优化。(eg.最小化误码率模块)其中的关键是,将发射机,信道,接收机表示为一个深度神经网络,作为一个自动编码器进行训练。甚至可以应用于最优解未知的通道模型和损失函数。
②将这种概念扩展到多对收发机竞争容量的对抗网络。这会导致干扰的产生,进而寻找一个最佳的信号方案。作者演示了一个具有多入多出的网络,所有收发机的实现都可以对于一个普遍的或者个人的性能指标进行联合优化。
③介绍了RTNs,将专家知识集成到DL 模型中。RTNs允许你在接收端执行预定义的修正算法,这些算法可以用另一个NN中学习到的参数进行反馈(复数乘法、向量卷积)。
④使用CNNs解决调制分类问题。超越了传统的方法,举了两个例子:sacle-invariant feature transform (SIFT)尺度不变特征和Bag-of-words。
1-A.讨论了DL对物理层的潜在优势
1.DL非线性
现有的通信中的信号处理算法通常是线性的、平稳的、具有高斯统计的。然而实际的系统有很多缺陷和非线性,(如非线性功率放大器PAs,有限分辨率量化)。基于DL,不需要数学可处理的模型,并可针对特定硬件配置和信道优化。
2.DL提供了End-to-End的整体方案,能够对整体性能进行优化
将通信系统分模块先进行优化,再合并,未必能够使通信系统整体性能达到最优。例如:
A. Goldsmith, “Joint source/channel coding for wireless channels,1995中介绍将信源和信道编码分离;
E. Zehavi, “8-PSK trellis codes for a Rayleigh channel,1992中,分离编码和调制;
这些对于实际信道不是最优的。
H. Wymeersch, Iterative receiver design. 2007中的基于因子图的方法,虽然计算复杂,但提供了增益。
3.DL计算效率高,能耗低
4.GPU和用于NN处理的专业化芯片Y .-H. Chen, “Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural net-works,”2017日益发展,NN能够实现高的硬件资源利用率。
1-B.介绍了ML in WC工作
1.谈到,以往ML在通信中应用的文献中,基本都只关注单个接收机处理任务,对于发射机的考虑,或者整个端到端系统的考虑完全缺失。
2.有两类不同方法将DL应用通信中,①利用DL改进现有算法,比如让其中迭代的部分换成NN;②用DL完全取代现有算法,如盲检测,功率控制,调制识别,信号压缩,信道解码等。
2.深度学习基础
CNN、ML工具、网络规划和训练
3.作者提出的几个DL在通信的应用
自动编码器、推广至多个收发机、RTNs、CNNs
3-A端到端自动编码通信系统
发送信号映射成  ,发送端对信号进行约束(eg.能量
,发送端对信号进行约束(eg.能量![]() ,幅度
,幅度![]() ,平均功率
,平均功率![]() ),n:n discrete uses of the channel??
),n:n discrete uses of the channel??
??解决:默认信道用一次发送1个bit,因此n的英文意思是信道的使用次数,发送一组码元用了几次信道,即有多少个码元。
分组码(n,k),编码,n个码元为一组,其中信息位数为k,码率![]() (bit/channel use),
(bit/channel use),![]() 。
。
信道用条件概率密度函数 ,其中接收信号
,其中接收信号![]() 。接收端接收到之后用反映射变换回发送信号的估计值。
。接收端接收到之后用反映射变换回发送信号的估计值。
自动编码器的目标:让输入在中间层用低维去表示,重构出最小误码的输出。
用这种方式,学习 非线性压缩 和 重构输入。
自编码器示意图:输入端为被编码的one-hot向量,输出是所有可能消息的概率分布,其中最有可能的为估计值输出。
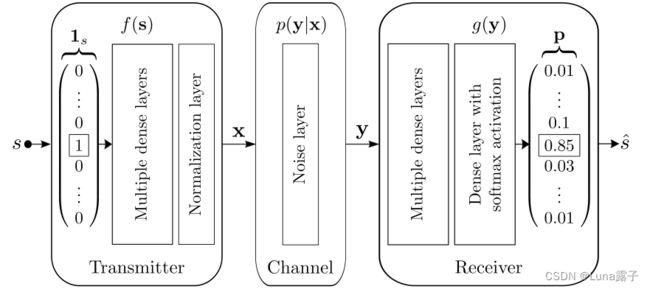 发射机由前馈神经网络组成,有多个全连接层,一个标准化层,用于对x的约束。
发射机由前馈神经网络组成,有多个全连接层,一个标准化层,用于对x的约束。
信道方差![]()
接收机也前馈NN,最后一层激活函数,输出是对最高概率的索引。
使用SGD梯度下降对所有可能信息使用合适的分类交叉熵损失函数
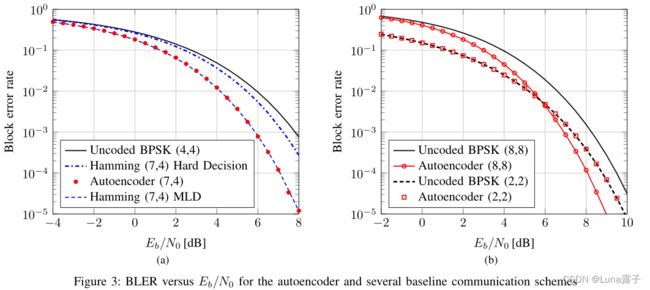
论文及源码中提炼的训练信息???
(1) optimizer: SGD 4-B中使用Adam 信噪比7dB,学习率0.001
(2) loss_function: BLER????
(3) data_set:随机生成的待传输的blocks,也就是有效信息编码串
(4) input:二维张量 [input_dimension, input_dimension],表示input_dimension个bit(一个bit被编码为input_dimension长度的one hot),也就表示一个block
(5) output:input编码再加噪解码后的输出,shape一模一样
3-B多对收发机的自动编码器
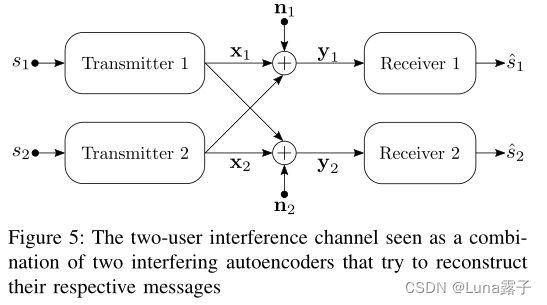 主要是如何消除第二方带来的干扰。利用权重
主要是如何消除第二方带来的干扰。利用权重
3-C RTNs 增强信号处理算法的无线电转换网络
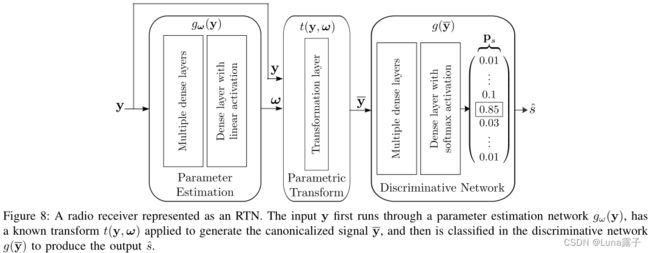
RTNs不寻求直接提高参数本身,而是一种优化参数估计方式的网络,是学习前馈注意的形式。inspired by Spatial Transformer Networks 。
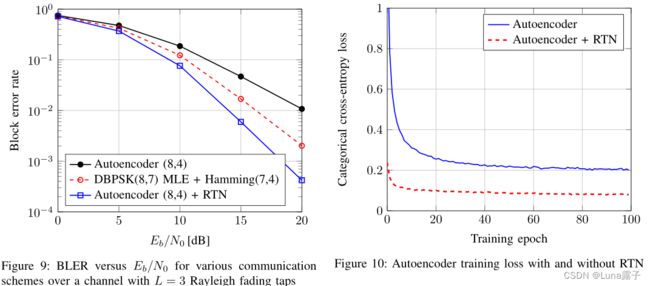
1.RTN可以提高差分BPSK的最大似然序列估计(MLE)和汉明(7,4)编码的性能。
2.RTN能够更快的训练收敛
3-D CNNs分类任务
传统的调制分类任务:expert feature engineering,analytic decision trees (single trees are widely used in practice)决策树;在特征空间上训练的方法:support vector machines支持向量机,random forests随机森林?,samll feedforward NNs小规模前馈神经网络;最近使用了模式识别:the spectral coherence function 谱想干函数,α-profileα-剖面,结合了神经网络的分类。
以上方法没有寻求在无线电领域中对原始时间序列数据上使用特征学习的方法。在图像领域的激发下,使用了下面这个网络(类似VGG)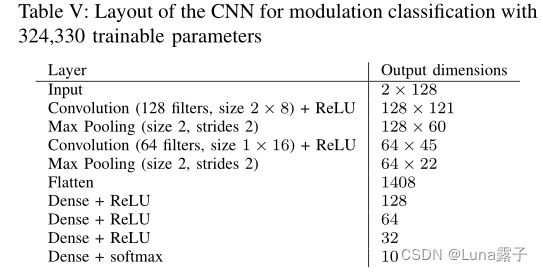
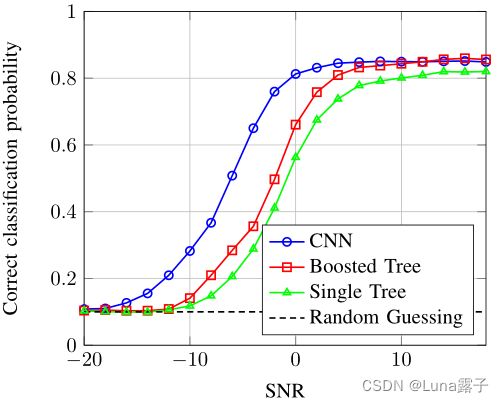
数据集:2016-10的https://www.deepsig.ai/datasets
4.概述并挖坑
4-A 数据集和挑战
没有通用的基准测试和开放的数据集
4-B 数据表示,损失函数,和训练信噪比
对最优数据表示、损失函数和训练策略缺少。
eg.二进制信号可以表示为:二进制或one-hot vectors,调制符号(复数),或者整数。但最佳表示可能取决于网络结构,学习目标和损失函数等。再比如在解码问题中,可以在直接在信道观测,或者取对数用似然比。此外,不知在哪个SNR下训练。
信噪比对训练的影响:从高信噪比开始训练,随着每个周期逐渐降低,会使性能提高[58]。
[58] D. George and E. Huerta, “Deep neural networks to enable real-time multimessenger astrophysics,” arXiv preprint arXiv:1701.00008, 2016.
提出了一些调参方法(batch size, learning rate…)
Examples include architecture search guided by hyper-gradients and differential hyper-parameters [59] as well as genetic algorithm or particle swarm style optimization [60].
[59] D. Maclaurin, D. Duvenaud, and R. P . Adams, “Gradient-based hyper-parameter optimization through reversible learning,” in Proc. 32nd Int.Conf. Mach. Learn. (ICML), 2015.
[60] J. Bergstra and Y . Bengio, “Random search for hyper-parameter optimization,” J. Mach. Learn. Res., vol. 13, pp. 281–305, Feb. 2012.
4-C 复数域神经网络
通信中通常运用复数计算,但是目前没有DL框架支持复数运算,一方面因为复数运算可以转换为两倍的实数运算;另一方面目前也没有针对复数的损失函数以及激活函数。
4-D DL大量的数据处理
用深度学习训练端到端通信系统的一大阻力就是数据的纬度太大,如果发送的信息有k=100bit,那就有M=2^100个数据要被训练。
一些解决方案:
25. deep unfolding现有的迭代算法。这个方法利用来自训练数据的附加信息来改进现有信号处理算法。22.23.24.将上面算法应用于信道解码和MIMO检测中。在22.中,将编码结构通过Tanner图嵌入到网络中,因此训练单个码字就足够。另一种方法,RTNs将现有模型的边缘信息以及来自丰富数据集的信息合并到DL算法中,提高性能同时降低模型和训练复杂性。
[22] E. Nachmani, Y . Be’ery, and D. Burshtein, “Learning to decode linear codes using deep learning,” in Proc. IEEE Annu. Allerton Conf. Commun., Control, and Computing (Allerton), 2016, pp. 341–346.
[23] E. Nachmani, E. Marciano, D. Burshtein, and Y . Be’ery, “RNN decoding of linear block codes,” arXiv preprint arXiv:1702.07560, 2017.
[24] N. Samuel, T. Diskin, and A. Wiesel, “Deep MIMO detection,” arXiv preprint arXiv:1706.01151, 2017.
[25] J. R. Hershey, J. L. Roux, and F. Weninger, “Deep unfolding:Model-based inspiration of novel deep architectures,” arXiv preprint arXiv:1409.2574, 2014.
4-E 端到端学习的系统识别
3-A和3-C中,默认信道传递函数已知,以便反向传播算法可计算梯度。eg.瑞利衰落信道,自动编码器需要在训练阶段知道信道系数,以计算传输信号x的微小变化如何影响接收信号y。模拟信道容易,但对真实信道的黑盒是挑战。解决:迁移学习maybe。
4-F从CSI中学习并超越
CSI是多用户MIMO通信的基本要求。目前蜂窝网投入大量资源获取CSI,但除了预编码,检测,或其他直接处理当前数据帧的相关任务外,通常不使用CSI。CSI中包含了丰富的位置信息,可使用ML实现通信之外的应用。如穿墙跟踪人65以及手势情感识别66。
[65] F. Adib, C.-Y . Hsu, H. Mao, D. Katabi, and F. Durand, “Capturing the human figure through a wall,” ACM Trans. Graphics (TOG), vol. 34,no. 6, p. 219, 2015.
[66] M. Zhao, F. Adib, and D. Katabi, “Emotion recognition using wireless signals,” in Proc. ACM Annu. Int. Conf. Mobile Computing and Net-working, 2016, pp. 95–108.
5.总结
实现了不用任何先验知识,用自动编码器联合学习收发机和信号编码,实现了端到端的传输。
二、复现
在github上找到了其他人写的关于自动编码器部分的代码:这里面的snr应该是Eb/N0。https://github.com/vidits-kth/py-radio-autoencoder/tree/0aeb2ca41c9987b040bce536cffe31be8db7e791
准备环境:tensorflow-gpu1.15.0 + python3.6 (使用 anaconda 配置)+itpp(作者自己写的库)
1.搭环境
创建并激活虚拟环境
conda create -n tf1.15_itpp python=3.6查看所有环境
conda info -econda activate tf1.15itpppip指令安装gpu版本的tensorflow
pip install tensorflow-gpu==1.15.0有可能会出现这种情况:
![]()
先更新一下pip指令试试:
python -m pip install --upgrade pip
pip install tensorflow-gpu==1.15.0查看安装后的:
conda list接下来安装itpp,这是一个信号处理的库,从makefile中可以看出,基于已经apt-get install libitpp-dev的前提下,是linux中使用。https://github.com/vidits-kth/py-itpp
在本文中itpp被hamming.py调用,用于编解汉明码,算误码率等。
在安装itpp过程中,在是否用sudo上费了好大劲。。。
pip3 install pybind11git clone https://github.com/vidits-kth/py-itpp.git
cd py-itpp
./install_prerequisites_python3.sh 注意远程多人使用的服务器 指令前可能需要加sudo超级管理指令
sudo make install
pip3 install -e . 一个例子试一下是否成功:
python
import itpp
a = itpp.vec('0:10:100')
print(a) 至此,环境终于成功安装好!!!!!!
2.自编码器
2.1源码运行结果
先直接运行代码
python radio_autoencoder.py
可以正常运行,得到下图:
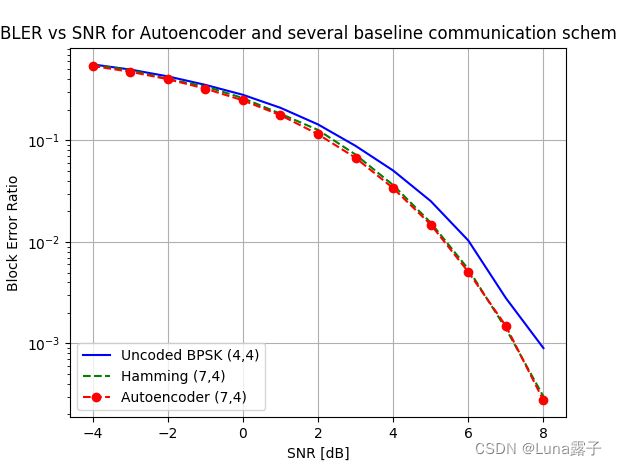
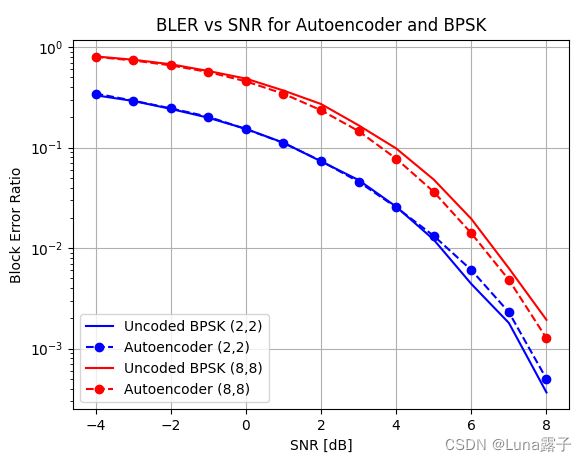
2.2源码分析
主要关注自动编码器部分的代码:
1.高斯噪声下的自动编码器性能
这一部分关键是随机生成one-hot形式的数据集
def block_error_ratio_autoencoder_awgn(snrs_db, block_size, channel_use, batch_size, nrof_steps):
print('block_size %d'%(block_size))
print('channel_use %d'%(channel_use))
rate = float(block_size)/float(channel_use)
print('rate %0.2f'%(rate))
'''The input is one-hot encoded vector for each codeword'''
alphabet_size = pow(2, block_size)
# np.eye生成一个对角矩阵,以二维数组的形式,转换为one-hot
alphabet = np.eye(alphabet_size, dtype = 'float32') # One-hot encoded values
'''Repeat the alphabet to create training and test datasets'''
# np.transpose转置
# np.tile将数组沿各个方向复制,默认向右拓展
# 先向右拓展再转置,相当于扩充列向量。每一个alphabet矩阵都是一串编码。
# train_dataset拥有batch_size串编码,扔可看作为一维的数据集。
train_dataset = np.transpose(np.tile(alphabet, int(batch_size)))
test_dataset = np.transpose(np.tile(alphabet, int(batch_size * 1000)))
print('--Setting up autoencoder graph--')
input, output, noise_std_dev, h_norm = _implement_autoencoder(alphabet_size, channel_use)
print( '--Setting up training scheme--')
train_step = _implement_training(output, input)
print('--Setting up accuracy--')
accuracy = _implement_accuracy(output, input)
print('--Starting the tensorflow session--')
sess = _setup_interactive_tf_session()
_init_and_start_tf_session(sess)
print('--Training the autoencoder over awgn channel--')
_train(train_step, input, noise_std_dev, nrof_steps, train_dataset, snrs_db, rate, accuracy)
print('--Evaluating autoencoder performance--')
bler = _evaluate(input, noise_std_dev, test_dataset, snrs_db, rate, accuracy)
print('--Closing the session--')
_close_tf_session(sess)
return bler部分函数解析:
1)np.eye(N,M=None,k=0,dtype=
返回的是一个二维2的数组(N,M),对角线的地方为1,其余的地方为0.
N:输出的行数
M:可选项,输出的列数,如果没有默认为N
k:可选项,对角线的下标,默认0表示主对角线,负数是低对角,正数高对角(对应线为1)
dtype:可选项,返回的数据的数据类型
order:可选项,输出的数组形式,按照C语言的行优先’C',还是按照Fortran形式的列优先‘F'存储在内存中
1.1自动编码器网络搭建
# 编码器网络结构搭建函数的输入(one-hot编码种类,使用信道次数:一个码元所含bit数目)
def _implement_autoencoder(input_dimension, encoder_dimension):
# 为即将输入的张量插入placeholder占位符,[None, input_dimension]为输入张量的shape几行几列,这里是二维的,None表示batch_size数量未知
input = tf.compat.v1.placeholder(tf.float32, [None, input_dimension])
'''Densely connected encoder layer'''
W_enc1 = _weight_variable([input_dimension, input_dimension])
b_enc1 = _bias_variable([input_dimension])
# tf.matmul矩阵相乘,h_enc1的shape为[input_dimension, input_dimension]??
h_enc1 = tf.nn.relu(tf.matmul(input, W_enc1) + b_enc1)
'''Densely connected encoder layer'''
# 这一层类比编码器
W_enc2 = _weight_variable([input_dimension, encoder_dimension])
b_enc2 = _bias_variable([encoder_dimension])
# h_enc2的shape为[input_dimension, encoder_dimension]
h_enc2 = tf.matmul(h_enc1, W_enc2) + b_enc2
'''Normalization layer'''
# tf.math.reciprocal用于计算倒数; tf.reduce_sum压缩求和,用于降维,按行求和; tf.square各元素求平方
# tf.expand_dims令张量在指定轴上扩充维度
# 一缩一扩,shape保持在[input_dimension, encoder_dimension]
normalization_factor = tf.math.reciprocal(tf.sqrt(tf.reduce_sum(tf.square(h_enc2), 1))) * np.sqrt(encoder_dimension)
h_norm = tf.multiply(tf.tile(tf.expand_dims(normalization_factor, 1), [1, encoder_dimension]), h_enc2)
'''AWGN noise layer'''
noise_std_dev = tf.compat.v1.placeholder(tf.float32)
# noise_std_dev是一个浮点数,表示噪声标准差
channel = tf.random.normal(tf.shape(h_norm), stddev=noise_std_dev)
h_noisy = tf.add(h_norm, channel)
'''Densely connected decoder layer'''
# 类比解码器
# shape变回[input_dimension,input_dimension]
W_dec1 = _weight_variable([encoder_dimension, input_dimension])
b_dec1 = _bias_variable([input_dimension])
h_dec1 = tf.nn.relu(tf.matmul(h_noisy, W_dec1) + b_dec1)
'''Output layer'''
W_out = _weight_variable([input_dimension, input_dimension])
b_out = _bias_variable([input_dimension])
output = tf.nn.softmax(tf.matmul(h_dec1, W_out) + b_out)
return (input, output, noise_std_dev, h_norm)1)placeholder是占位符,相当于定义了一个变量,提前分配了需要的内存。但只有启动一个session,程序才会真正的运行。建立session后,通过feed_dict()函数向变量赋值。
2)tf.reduce_sum压缩求和,用于降维。
tf.reduce_sum(x) =>所有数值相加;tf.reduce_sum(x, 0) =>按列求和;
tf.reduce_sum(x, 1)=>按行求和;tf.reduce_sum(x, 1, keep_dims=True)=>按照行的维度求和
3)tf.square各元素求平方
4)tf.expand_dims( input, axis=None, name=None, dim=None )用于增加维度
axis:指定扩大输入张量形状的维度索引值
dim:等同于轴,一般不推荐使用
在给定一个input时,在axis轴处给input增加一个维度。索引值从0开始,如果是负数,则从最后向后进行计数。
5)tf.tile(input, multiples, name=None)
multiples参数维度必须与input一致,表示在第几维上复制几次。如multiples=[2,3]表示在第一维上复制2次,第二维上复制3次。
6)tf.multiply(x,y,name=None)乘法,相同位置的元素相乘
1.2训练函数选择代码
def _implement_training(output, input):
# 计算交叉熵
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits = output, labels = input))
# 使用Adam优化算法,1e-3学习率lr,又叫步长,定义每次参加参数更新的幅度
train_step = tf.compat.v1.train.AdamOptimizer(1e-3).minimize(cross_entropy)
return train_step 1)tf.nn.softmax_cross_entropy_with_logits_v2(_sentinel=None,labels=None,logits=None,
dim=-1,name=None)结果是真实标签和预测标签之差,使用softmax交叉熵进行计算。
_sentinel:一个内部参数,具体作用还未可知
labels:真实标签,注意是一个onehot向量,且长度跟logits一样长,长度为类别数
logits:模型最后一层的输出,注意不要过softmax函数,维度为[batch_size,numclass]
dim: 按照哪一个维度去求的,默认-1也就是最后一维,也就是按照类别数来求的,如果你的类别数在第一维的话,这里必须要改成0。
1.3训练代码
def _train(train_step, input, noise_std_dev, nrof_steps, training_dataset, snrs_db, rate, accuracy):
print('--Training--')
print('number of steps %d'%(nrof_steps))
snr = max(snrs_db)
# 步长-1,从右向左取
snrs_rev = snrs_db[::-1]
for snr in snrs_rev[0:1]: # Train with higher SNRs first
print('training snr %0.2f db'%(snr))
# noise如何得到??
noise = np.sqrt(1.0 / (2 * rate * pow(10, 0.1 * snr)))
for i in range(int(nrof_steps)):
batch = training_dataset
# np.random.shuffle洗牌
np.random.shuffle(batch)
if (i + 1) % (nrof_steps/10) == 0: # i = 0 is the first step
print('training step %d'%(i + 1))
train_step.run(feed_dict={input: batch, noise_std_dev: noise})
print('training accuracy %0.4f'%(accuracy.eval(feed_dict={input: batch, noise_std_dev: noise})))1)[start : end : step]
start:开始下标,从0开始
end:结束下标,(输出不包含该位置数)
step:步长,步长为正时,从左向右取值。步长为负时,从右向左取值 注意:步长不可以为0
??这个代码中关于噪声功率的计算有一点问题,在这里第1章(2):QPSK调制解调器仿真 - 知乎有关于Eb/N0与信号与噪声功率比值的详细描述。
其中rate=br/sr,代码中的snr,即横坐标应该为Eb/N0
spow = sum(Fsignal.^2)/length(Fsignal);%信号功率 attn = 0.5*spow*sr/br*10.^(-EbN0indB/10); %这个0.5是必须的,实信号 attn = sqrt(attn);
令:补充两个仿真加白噪声的方法:
%%%%%方式一:用awgn函数 x = cos(0:pi/1000000:6*pi); figure (1); plot(x); snr = 10; %单位是dB y1 = awgn(x,snr,'measured'); figure (2); plot(y1); %%%%%方式二:加随机序列 % x = cos(0:pi/1000000:6*pi); sigPower = sum(abs(x).^2)/length(x); noisePower = sigPower /10^(snr/10); a = sqrt(noisePower); y2 = x + a*randn(1,length(x)); figure (3); plot(y2); %%%%%%%%%%%结论 %%%%两种加噪声方式都可以,按照个人习惯选择即可 %%%%当存在I路、Q路信号时,噪声功率在I路和Q路上是各占一半功率
2.3RTNs代码复现
这一部分是我自己在上面的代码基础上改进的,在论文中给出的接收机部分的网络结构,根据此来进行改写。由于Transformation Layer部分没有展开描述,因此本环节只加入了参数估计的部分,主要是残差结构和参数传递。改写后的代码如下:
(传输层的代码可能是用了这篇文章Spatial Transformer Networks | Papers With Code)
'''AWGN noise layer'''
noise_std_dev = tf.compat.v1.placeholder(tf.float32)
# noise_std_dev是一个浮点数,表示噪声标准差
channel = tf.random.normal(tf.shape(h_norm), stddev=noise_std_dev)
# [input_dimension, encoder_dimension]
h_noisy = tf.add(h_norm, channel)
'''Parameter Estimation'''
W_est1 = _weight_variable([input_dimension, input_dimension])
b_est1 = _bias_variable([input_dimension])
# [input_dimension, input_dimension]
h_est1 = tf.nn.relu(tf.matmul(h_noisy, W_est1) + b_est1)
W_est2 = _weight_variable([input_dimension, encoder_dimension])
b_est2 = _bias_variable([encoder_dimension])
# h_est2的shape为[input_dimension, encoder_dimension]
h_est2 = tf.matmul(h_est1, W_est2) + b_est2
# [input_dimension, encoder_dimension]
h_est3 = tf.add(h_noisy,h_est2)
'''Parametric Transform'''
'''Densely connected decoder layer'''
# 类比解码器
# shape变回[input_dimension,input_dimension]
W_dec1 = _weight_variable([encoder_dimension, input_dimension])
b_dec1 = _bias_variable([input_dimension])
h_dec1 = tf.nn.relu(tf.matmul(h_est3, W_dec1) + b_dec1)
'''Output layer'''
W_out = _weight_variable([input_dimension, input_dimension])
b_out = _bias_variable([input_dimension])
output = tf.nn.softmax(tf.matmul(h_dec1, W_out) + b_out)经过编译后,该网络结构搭建部分的代码顺利通过,但是报错在了训练的时候,.run的位置
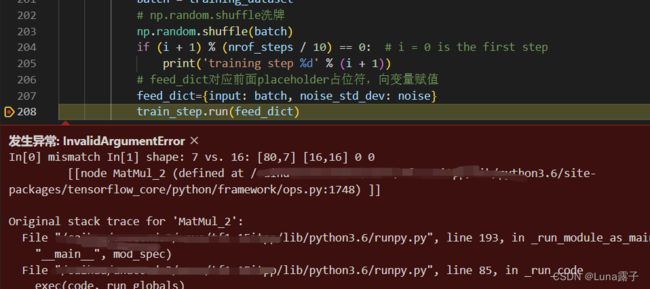
报错显示的是维度不匹配,但实在是找不到原因,十分困惑,卡在这儿了!!!!!
改写后的网络结构的输入输出的shape都没变,为啥训练输入维度出错呢??????不明白啊!!!!
三、写作手法笔记
1.The beauty of this approach is that it can…………...用于描述方法的亮点。
2.This result mirrors a..................................................反映,“mirror”
3.However, to the best of our knowledge ,....................用在前面介绍别人方法的不足。