SVM算法详解
Support Vector Machine
终于,我们来到了SVM。SVM是我个人感觉机器学习中最优美的算法,这次我们要来非常细致地介绍。SVM是一类有监督的分类算法,它的大致思想是:假设样本空间上有两类点,我们希望找到一个划分超平面,将这两类样本分开,而划分超平面应该选择泛化能力最好的,也就是能使得两类样本中距离它最近的样本点距离最大。
Hard Margin&Dual Problem
Hard Margin
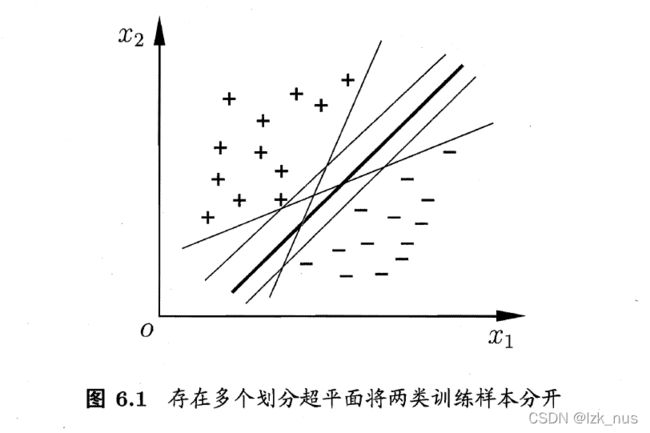
如图所示,中间那条加粗的超平面就是我们所求的最优划分超平面。我们知道平面的方程可以用线性方程: w T x + b = 0 w^Tx+b=0 wTx+b=0来表示, w = ( w 1 , w 2 , … , w n ) w=(w_1,w_2,\dots,w_n) w=(w1,w2,…,wn)表示的是平面的法矢量。现在,我们假设样本空间 D = { ( x i , y i ) ∣ i ∈ Z + } D=\{(x_i,y_i)|i\in Z^{+}\} D={(xi,yi)∣i∈Z+}中只有两个类别的样本,类别标记分别为 y i = 1 y_i=1 yi=1或 y i = − 1 y_i=-1 yi=−1。那么对于 ( x i , y i ) , y i = 1 (x_i,y_i),y_i=1 (xi,yi),yi=1,超平面得到的结果 w T x i + b ≥ 1 w^Tx_i+b\ge1 wTxi+b≥1;反之, w T x i + b ≤ − 1 w^Tx_i+b\le-1 wTxi+b≤−1。因此我们有:
{ w T x i + b ≥ 1 , y i = 1 w T x i + b ≤ − 1 , y i = − 1 \begin{cases} w^Tx_i \ + \ b \ \ge \ 1, \ \ \ \ \ y_i=1 \\ w^Tx_i \ + \ b \ \le \ -1, \ \ \ \ \ y_i=-1\end{cases} {wTxi + b ≥ 1, yi=1wTxi + b ≤ −1, yi=−1
某一个样本点 ( x i , y i ) (x_i,\ y_i) (xi, yi)到划分超平面的距离公式为:
γ = ∣ w T x i + b ∣ ∣ ∣ w ∣ ∣ \gamma \ = \ \frac{|w^Tx_i+b|}{||w||} γ = ∣∣w∣∣∣wTxi+b∣
考虑两类样本点中距离划分超平面最近的样本,这类样本恰好能够使得上式中的等号成立,如图:
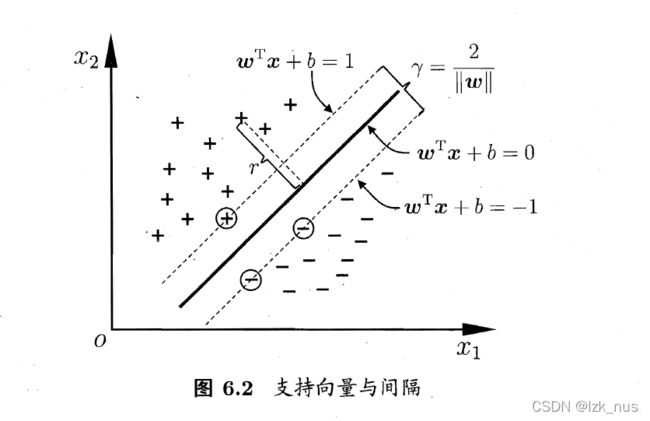
我们称这类距离划分超平面最近的样本点为“支持向量”,称 γ = 2 ∣ ∣ w ∣ ∣ \gamma \ = \ \frac{2}{||w||} γ = ∣∣w∣∣2为“间隔”。
之前我们说到了,我们希望这个间隔能够最大化来使得模型泛化能力最强,因此我们的任务就是:
m a x i m i z e w 2 ∣ ∣ w ∣ ∣ s . t . y i ( w T x i + b ) ≥ 1 maximize_{w} \ \ \ \ \ \ \ \ \ \frac{2}{||w||} \\ s.t. \ \ \ \ y_i(w^Tx_i+b) \ \ge \ 1 maximizew ∣∣w∣∣2s.t. yi(wTxi+b) ≥ 1
这个任务等价于:
m i n i m i z e w 1 2 ∣ ∣ w ∣ ∣ 2 s . t 1 − y i ( w T x i + b ) ≤ 0 minimize_{w} \ \ \ \ \ \ \ \ \ \frac{1}{2}{||w||^2} \\ s.t \ \ \ \ \ 1 - y_i(w^Tx_i+b) \le 0 minimizew 21∣∣w∣∣2s.t 1−yi(wTxi+b)≤0
这就变成了一个非常典型的凸优化问题。
Dual Problem
对于求条件极值,我们自然要先写出他的Lagrange乘子式:
L ( α , w , b ) = 1 2 ∣ ∣ w ∣ ∣ 2 − ∑ i = 1 n α i ( 1 − y i ( w T x i + b ) ) L(\alpha,w,b) \ = \ \frac{1}{2}||w||^2 \ - \ \sum_{i=1}^{n}{\alpha_i}{(1-y_i(w^Tx_i+b))} L(α,w,b) = 21∣∣w∣∣2 − i=1∑nαi(1−yi(wTxi+b))
我们的任务是 m i n i m i z e L ( α , w , b ) minimize \ \ L(\alpha,w,b) minimize L(α,w,b)。
下面考虑它的dual problem:
m i n w , b m a x α L ( α , w , b ) min_{w,b}max_{\alpha}L(\alpha,w,b) \\ minw,bmaxαL(α,w,b)
接下来求出 L L L对 w , b w,b w,b的偏导:
∇ w L = w − ∑ i = 1 n α i y i x i = 0 w = ∑ i = 1 n α i y i x i ∇ b L = − ∑ i = 1 n α i y i = 0 ∑ i = 1 n α i y i = 0 \nabla_{w}L = w-\sum_{i=1}^n{\alpha_iy_ix_i}=0 \ \ \ \ \ \ \ \ \ w = \sum_{i=1}^n{\alpha_iy_ix_i} \\ \nabla_{b}L = -\sum_{i=1}^n{\alpha_iy_i} = 0 \ \ \ \ \ \ \ \ \ \ \ \sum_{i=1}^n{\alpha_iy_i}=0 ∇wL=w−i=1∑nαiyixi=0 w=i=1∑nαiyixi∇bL=−i=1∑nαiyi=0 i=1∑nαiyi=0
代入 g ( α ) g(\alpha) g(α)得到对偶函数我们得到:
g ( α ) = ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j x i T x j g(\alpha) = \sum_{i=1}^n{\alpha_i} - \frac{1}{2}\sum_{i=1}^n\sum_{j=1}^{n}{\alpha_i\alpha_jy_iy_jx_i^Tx_j} g(α)=i=1∑nαi−21i=1∑nj=1∑nαiαjyiyjxiTxj
因此我们可以把问题转化为:
m a x α ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j x i T x j s . t . α i ≥ 0 ∑ i = 1 n α i y i = 0 max_{\alpha} \ \ \ \ \ \ \ \ \ \ \ \ \ \sum_{i=1}^n{\alpha_i} - \frac{1}{2}\sum_{i=1}^n\sum_{j=1}^{n}{\alpha_i\alpha_jy_iy_jx_i^Tx_j} \\ s.t. \ \ \ \ \ \ \ \ \ \ \alpha_i\ge0 \\ \ \ \ \ \ \ \ \ \ \ \ \ \sum_{i=1}^n{\alpha_iy_i}=0 maxα i=1∑nαi−21i=1∑nj=1∑nαiαjyiyjxiTxjs.t. αi≥0 i=1∑nαiyi=0
如果满足的是strong dual,那么应该满足的KKT条件是:
{ 1 − y i ( w T x i + b ) ≤ 0 p r i m a l c o n s t r a i n t α i ≥ 0 d u a l c o n s t r a i n t α i ( 1 − y i ( w T x i + b ) ) = 0 c o m p l e m e n t a r y s l a c k n e s s \begin{cases} 1-y_i(w^Tx_i+b)\le0 \ \ \ \ \ \ \ \ \ \ \ \ primal \ \ constraint \\ \alpha_i\ge0 \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ dual \ \ constraint \\ \alpha_i(1-y_i(w^Tx_i+b))=0 \ \ \ complementary \ \ slackness \end{cases} ⎩ ⎨ ⎧1−yi(wTxi+b)≤0 primal constraintαi≥0 dual constraintαi(1−yi(wTxi+b))=0 complementary slackness
(突然发现学过凸优化理论就是好……)
Soft Margin
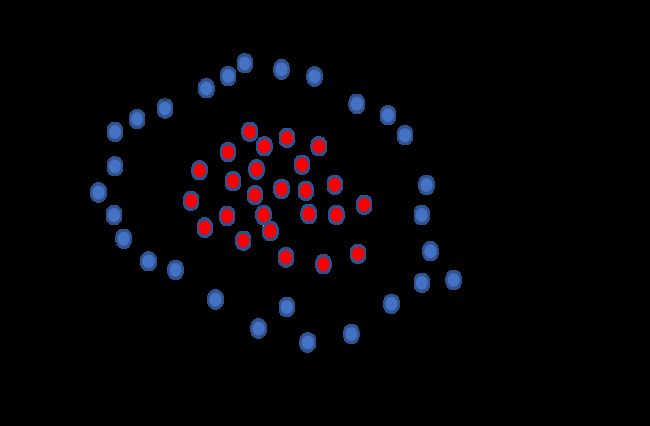
前面我们谈到的都是理想状况,也就是能够找到一个划分平面把两类样本点完全分开。但是很多时候,我们会遇到一些特殊的数据导致无法用一个平面实现完全准确的分类,因此提出了Soft Margin软间隔,即允许有分类错误的情况发生。如图所示,红色点样本点就是被分类错误的点。
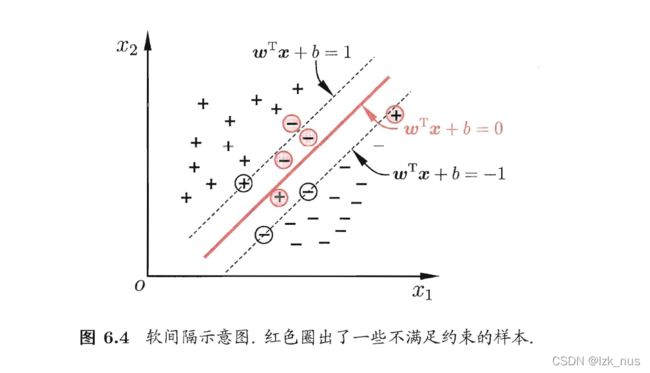
那么我们就在原来的目标函数中加入一个分类错误的损失 ξ i \xi_i ξi,在最小化 ∣ ∣ w ∣ ∣ 2 2 \frac{||w||^2}{2} 2∣∣w∣∣2的同时也最小化总体分类误差,即:
m i n i m i z e 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 n ξ i minimize \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \frac{1}{2}||w||^2 \ + \ C\sum_{i=1}^n\xi_i \ \ \ \ \ minimize 21∣∣w∣∣2 + Ci=1∑nξi
C是一个惩罚系数,C越大,代表模型对分类正确的要求越高
现在我们要考虑这个 ξ i \xi_i ξi到底应该是什么。在Hard Margin当中,我们提到了如果某个样本被分类正确,那么他应该满足的条件是:
y i ( w T x i + b ) ≥ 1 y_i(w^Tx_i+b)\ge1 yi(wTxi+b)≥1
因此,对于 ξ i \xi_i ξi,我们希望的是当样本满足上述条件时,等于0;否则,等于一个正比于 y i ( w T x i + b ) y_i(w^Tx_i+b) yi(wTxi+b)与 1 1 1之间差距的值。我们常用的损失函数有MSE、Sigmoid+Cross Entropy等等,如下图所示:
但我们会发现这些损失函数都不太符合我们的需求。因此,在SVM中,我们提出了Hinge Loss,即:
L h i n g e = { 0 y i ( w T x i + b ) ≥ 1 1 − y i ( w T x i + b ) y i ( w T x i + b ) < 1 L_{hinge} = \begin{cases} 0 \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ y_i(w^Tx_i+b)\ge1 \\ 1 - y_i(w^Tx_i+b) \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ y_i(w^Tx_i+b)\lt1 \end{cases} Lhinge={0 yi(wTxi+b)≥11−yi(wTxi+b) yi(wTxi+b)<1
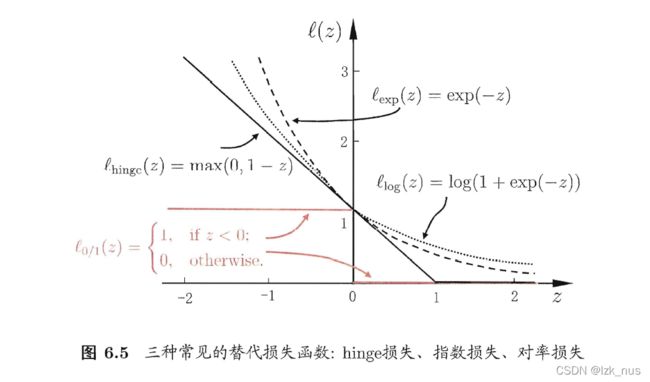
那么, ξ i \xi_i ξi也就可以用Hinge Loss来表示,与此同时,我们的约束条件也发生了一些变化:
m i n i m i z e 1 2 ∣ ∣ w ∣ ∣ 2 + C ∑ i = 1 n m a x ( 0 , 1 − y i ( w T x i + b ) ) s . t . y i ( w T x i + b ) ≥ 1 − ξ i ξ i ≥ 0 minimize \ \ \ \ \ \ \ \ \ \ \ \ \frac{1}{2}{||w||^2}+C\sum_{i=1}^nmax(0, 1-y_i(w^Tx_i+b)) \\ s.t. \ \ \ \ \ \ \ \ \ \ y_i(w^Tx_i+b)\ge1-\xi_i \\ \xi_i\ge0 minimize 21∣∣w∣∣2+Ci=1∑nmax(0,1−yi(wTxi+b))s.t. yi(wTxi+b)≥1−ξiξi≥0
我们看到这里的约束条件从 ≥ 1 \ge1 ≥1变成了 ≥ 1 − ξ i \ge1-\xi_i ≥1−ξi,也就是条件放宽了一些,因此我们也称 ξ i \xi_i ξi为松弛变量(slack variable)。
同理,我们还是写出拉格朗日乘子式,然后求对偶问题,可以得到:
m a x i m i z e α ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j x i T x j s . t . 0 ≤ α i ≤ C ∑ i = 1 n α i y i = 0 maximize_{\alpha} \ \ \ \ \ \ \ \ \ \ \ \ \ \sum_{i=1}^n{\alpha_i} - \frac{1}{2}\sum_{i=1}^n\sum_{j=1}^{n}{\alpha_i\alpha_jy_iy_jx_i^Tx_j} \\ s.t. \ \ \ \ \ \ \ \ \ \ 0\le\alpha_i\le C \\ \ \ \ \ \ \ \ \ \ \ \ \ \sum_{i=1}^n{\alpha_iy_i}=0 maximizeα i=1∑nαi−21i=1∑nj=1∑nαiαjyiyjxiTxjs.t. 0≤αi≤C i=1∑nαiyi=0
需要满足的KKT条件为:
{ 1 − ξ i − y i ( w T x i + b ) ≤ 0 α i ≥ 0 α i ( 1 − ξ i − y i ( w T x i + b ) ) = 0 ξ i ≥ 0 β i ξ i = 0 ( β 是另一个拉格朗日乘子 ) \begin{cases} 1-\xi_i-y_i(w^Tx_i+b)\le0 \ \ \ \ \ \ \ \ \ \ \ \\ \alpha_i\ge0 \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \\ \alpha_i(1-\xi_i-y_i(w^Tx_i+b))=0 \ \\ \xi_i\ge0 \\ \beta_i\xi_i=0(\beta是另一个拉格朗日乘子) \end{cases} ⎩ ⎨ ⎧1−ξi−yi(wTxi+b)≤0 αi≥0 αi(1−ξi−yi(wTxi+b))=0 ξi≥0βiξi=0(β是另一个拉格朗日乘子)
Kernel
Intuition
再来考虑一类问题,假如有一组样本,软间隔也失效了该怎么办,话可能不太好描述,直接看图:
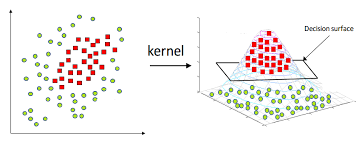
这种样本显然用线性的平面是不可能划分开的。但是假如我们能够把它映射到高维空间,那是不是就能线性可分了?如图:
再举一个例子,感知机中经典的异或问题,我们都知道异或问题单个感知机是无法实现的,但是如果我们将它映射到高维,如图:
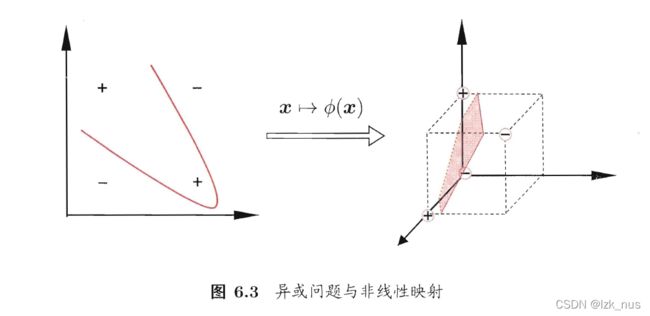
这样我们就能找到一个线性的平面实现划分了。
Kernel Function
从上面的图中我们发现,只要我们找到一种映射 x − > ϕ ( x ) x->\phi(x) x−>ϕ(x),或者说从空间 R R R到空间 H H H,然后就能在新的空间用线性的超平面进行划分。但是问题又来了,这种映射关系倒是很好找,例如 x = ( x 1 , x 2 … , x n ) x=(x_1,x_2\dots,x_n) x=(x1,x2…,xn), ϕ ( x ) = ( x 1 x 2 , x 1 x 3 , … , x 1 x n , x 2 x 1 , x 2 x 3 , … x 2 x n , … ) \phi(x)=(x_1x_2,x_1x_3,\dots,x_1x_n,x_2x_1,x_2x_3,\dots x_2x_n,\dots) ϕ(x)=(x1x2,x1x3,…,x1xn,x2x1,x2x3,…x2xn,…),即 ϕ ( x ) \phi(x) ϕ(x)表示 x x x中两两特征之积,那么当我们要计算 ϕ ( x ) \phi(x) ϕ(x)的时候,所花费的代价是 O ( n 2 ) O(n^2) O(n2)的。在机器学习或深度学习任务中,成千上万的数据量是非常正常的,这就导致了模型效率的大幅下降。
因此,我们希望找到某种函数 K ( x , z ) K(x,z) K(x,z),使得我们不需要显式地写出映射关系 ϕ ( x ) \phi(x) ϕ(x),就能计算得到 ϕ ( x ) T ϕ ( z ) \phi(x)^T\phi(z) ϕ(x)Tϕ(z)的结果。我们称这样的函数为核函数。下面举个例子:
证明 K ( x , z ) = ( x ⋅ z ) 2 是一个核函数 , x , z ∈ R 2 x = ( x 1 , x 2 ) z = ( z 1 , z 2 ) ( x ⋅ z ) 2 = ( x 1 x 2 + z 1 z 2 ) 2 = x 1 2 x 2 2 + 2 x 1 x 2 z 1 z 2 + z 1 2 z 2 2 于是 , 对于 ϕ ( x ) = ( x 1 2 , x 1 x 2 , x 2 2 ) , K ( x , z ) = ϕ ( x ) T ϕ ( z ) = ( x ⋅ z ) 2 所以利用核函数 K ( x , z ) = ( x ⋅ z ) 2 , 我们可以将数据映射到 R 3 空间 证明K(x,z)=(x\cdot z)^2是一个核函数,x,z\in R^2 \\ x=(x_1,x_2) \ \ \ \ z=(z_1,z_2) \\ (x\cdot z)^2=(x_1x_2+z_1z_2)^2=x_1^2x_2^2+2x_1x_2z_1z_2+z_1^2z_2^2 \\ 于是,对于\phi(x)=(x_1^2,x_1x_2,x_2^2),K(x,z)=\phi(x)^T\phi(z)=(x\cdot z)^2\\ 所以利用核函数K(x,z)=(x \cdot z)^2,我们可以将数据映射到R^3空间 证明K(x,z)=(x⋅z)2是一个核函数,x,z∈R2x=(x1,x2) z=(z1,z2)(x⋅z)2=(x1x2+z1z2)2=x12x22+2x1x2z1z2+z12z22于是,对于ϕ(x)=(x12,x1x2,x22),K(x,z)=ϕ(x)Tϕ(z)=(x⋅z)2所以利用核函数K(x,z)=(x⋅z)2,我们可以将数据映射到R3空间
下面是核函数的严格定义:

Sufficient&Necessary Condition
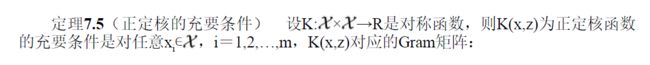

了解即可
Common Kernel Function
Linear Kernel
K ( x , z ) = x T z + c K(x,z)=x^Tz+c K(x,z)=xTz+c
Polynomial Kernel
K ( x , z ) = ( a x T z + b ) c K(x,z)=(ax^Tz+b)^c K(x,z)=(axTz+b)c
RBF Kernel
K ( x , z ) = e x p ( ∣ ∣ x − z ∣ ∣ 2 − 2 σ 2 ) K(x,z)=exp(\frac{||x-z||^2}{-2\sigma^2}) K(x,z)=exp(−2σ2∣∣x−z∣∣2)
Laplacian Kernel
K ( x , z ) = e x p ( − ∣ ∣ x − z ∣ ∣ σ ) K(x,z)=exp(-\frac{||x-z||}{\sigma}) K(x,z)=exp(−σ∣∣x−z∣∣)
Non-Linear SVM
上面介绍Kernel的目的就是引出下面的非线性SVM。对于线性不可分的问题,SVM中就是使用核函数技巧将原样本映射到高维空间,在高维空间寻找线性解。而我们唯一需要做的变化就是将原来目标函数中的 x i T x j x_i^Tx_j xiTxj变为 K ( x i , x j ) K(x_i,x_j) K(xi,xj),就实现了从低位到高维空间的映射,即:
m a x i m i z e α ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j K ( x i , x j ) s . t . 0 ≤ α i ≤ C ∑ i = 1 n α i y i = 0 maximize_{\alpha} \ \ \ \ \ \ \ \ \ \ \ \ \ \sum_{i=1}^n{\alpha_i} - \frac{1}{2}\sum_{i=1}^n\sum_{j=1}^{n}{\alpha_i\alpha_jy_iy_jK(x_i,x_j)} \\ s.t. \ \ \ \ \ \ \ \ \ \ 0\le\alpha_i\le C \\ \ \ \ \ \ \ \ \ \ \ \ \ \sum_{i=1}^n{\alpha_iy_i}=0 maximizeα i=1∑nαi−21i=1∑nj=1∑nαiαjyiyjK(xi,xj)s.t. 0≤αi≤C i=1∑nαiyi=0
事实上,对于任意的模型,只要目标函数中出现了 x x x的内积形式,我们都可以应用核技巧。
SMO Algorithm
前面我们只得到了最终要优化的函数,但是还没有讲到底怎么得到最优的 α \alpha α。首先,我们引入一个定理:

这个定理告诉我们,只要求解出最优的 α \alpha α,我们就可以返回去求出最优的划分平面。
接下来,我们来一步步地推导SMO算法,这是一个非常复杂的过程。SMO地思想是每次找到两个变量 α i α j \alpha_i \ \alpha_j αi αj,针对这两个变量构建一个凸二次规划问题。最终,当所有的 α \alpha α都满足KKT条件时,我们的优化就完成了。而每次选取两个变量的标准就是, α i \alpha_i αi选择样本中违反KKT条件最严重的, α j \alpha_j αj根据约束条件来自动确定,下面开始推导。
Mathematical Deduction
不失一般性,我们假设选择的两个变量为 α 1 , α 2 \alpha_1,\alpha_2 α1,α2,其他变量 α j \alpha_j αj看作是固定的常数,于是我们要优化的问题就可以写成:
m i n i m i z e α 1 , α 2 1 2 K 11 α 1 2 + 1 2 K 22 α 2 2 + K 12 α 1 α 2 − ( α 1 + α 2 ) + y 1 α 1 ∑ i = 3 n y i α i K i 1 + y 2 α 2 ∑ i = 3 n y i α i K i 2 s . t . α 1 y 1 + α 2 y 2 = − ∑ i = 3 n α i y i = δ 0 ≤ α i ≤ C minimize_{\alpha_1,\alpha_2} \ \ \ \ \ \frac{1}{2}K_{11}{\alpha_1^2}+\frac{1}{2}K_{22}{\alpha_2^2}+K_{12}{\alpha_1\alpha_2}-(\alpha_1+\alpha_2)+y_1\alpha_1\sum_{i=3}^ny_i\alpha_iK_{i1}+y_2\alpha_2\sum_{i=3}^ny_i\alpha_iK_{i2} \\ s.t. \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \alpha_1y_1+\alpha_2y_2=-\sum_{i=3}^n{\alpha_iy_i}=\delta \\ 0\le\alpha_i\le C minimizeα1,α2 21K11α12+21K22α22+K12α1α2−(α1+α2)+y1α1i=3∑nyiαiKi1+y2α2i=3∑nyiαiKi2s.t. α1y1+α2y2=−i=3∑nαiyi=δ0≤αi≤C
首先我们来分析约束条件 α 1 y 1 + α 2 y 2 \alpha_1y_1+\alpha_2y_2 α1y1+α2y2,对于两个变量,我们可以用图像来表示
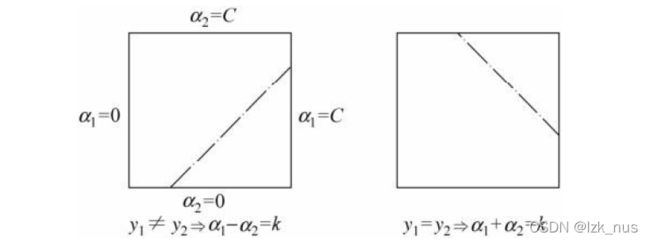
其实这就是一个直线方程, y 1 , y 2 y_1,y_2 y1,y2有两种情况:同号和异号
因此我们要求的的是目标函数在平行于对角线的线段上的最优值,这样我们又可以转化为一个单变量的最优化问题,不妨只考虑 α 2 \alpha_2 α2
假设初始可行解为 α 1 o l d , α 2 o l d \alpha_1^{old},\alpha_2^{old} α1old,α2old最优解为 α 1 n e w , α 2 n e w \alpha_1^{new},\alpha_2^{new} α1new,α2new, 假设在沿着约束方向未经修剪的 α 2 \alpha_2 α2的最优解为 α 2 n e w , u n c \alpha_2^{new,unc} α2new,unc。由于 α 2 n e w \alpha_2^{new} α2new要满足不等式约束,因此 L ≤ α 2 n e w ≤ H L\le\alpha_2^{new}\le H L≤α2new≤H, L , H L,H L,H是 α 2 n e w \alpha_2^{new} α2new的上下界。
- 当 y 1 = y 2 y_1=y_2 y1=y2时
- 下界: L = m i n ( 0 , α 2 o l d − α 1 o l d ) L=min(0, \alpha_2^{old}-\alpha_1^{old}) L=min(0,α2old−α1old)
- 上界: H = m a x ( C , C + α 2 o l d − α 1 o l d ) H=max(C,C+\alpha_2^{old}-\alpha_1^{old}) H=max(C,C+α2old−α1old)
- 当 y 1 ≠ y 2 y_1\neq y_2 y1=y2时,
- 下界: L = m i n ( 0 , α 2 o l d + α 1 o l d − C ) L=min(0,\alpha_2^{old}+\alpha_1^{old}-C) L=min(0,α2old+α1old−C)
- 上界: H = m a x ( C , α 2 o l d + α 1 o l d ) H=max(C,\alpha_2^{old}+\alpha_1^{old}) H=max(C,α2old+α1old)
下面,首先求未经约束条件修剪的最优值 α 2 n e w , u n c \alpha_2^{new,unc} α2new,unc
记 g ( x ) = ∑ i = 1 n α i y i K ( x i , x ) + b g(x)=\sum_{i=1}^n{\alpha_iy_iK(x_i,x)}+b g(x)=∑i=1nαiyiK(xi,x)+b
令 E i = g ( x i ) − y i = ( ∑ j = 1 n α j y j K ( x j , x i ) + b ) − y i i = 1 , 2 E_i=g(x_i)-y_i=(\sum_{j=1}^n{\alpha_j}y_jK(x_j,x_i)+b)-y_i \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ i=1,2 Ei=g(xi)−yi=(∑j=1nαjyjK(xj,xi)+b)−yi i=1,2
那么 E i E_i Ei就表示预测值与真实值之间的误差

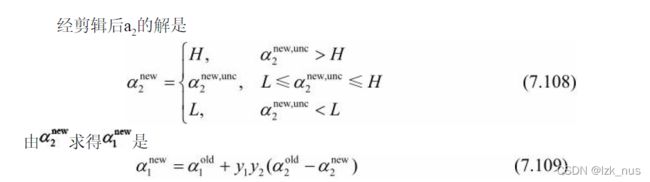
接下来计算阈值b和差值E


Principle of Choosing Variable


其实当我们优化完得到最后所有的 α i \alpha_i αi后,我们会发现只有少数的 α i \alpha_i αi不为 0 0 0,而那些不为 0 0 0的 α \alpha α就是我们的支持向量!