最佳实践 | 联通数科基于 DolphinScheduler 的二次开发
点击上方 ![]() 蓝字关注我们
蓝字关注我们

✎ 编 者 按
数据时代下,井喷的数据量为电信行业带来新的挑战。面对每日数百 TB 的新增数据,稳定可靠的调度系统必不可少。
中国联通旗下的联通数字科技有限公司(以下简称“联通数科”),其数据智能事业部原来十分依赖商业调度系统。但随着公司业务规模扩大,和新场景需求的挑战下,事业部经过调研和多方考量,决定将调度系统替换为 Apache DolphinScheduler。从 2020 年 10 月上线首个版本以来,Apache DolphinScheduler 在联通数科已经过一年的实践检验,处理着中国联通来自各省市公司的日常数据。
![]()
背景
![]()
联通数科的数据智能事业部是中国联通全网数据商业运营的统一出口,有着大量的数据加工作业需求,因此,大数据调度系统对于这样一个重要部门来说必不可缺,而且由于其复杂独特的业务场景,公司内部对于调度系统的要求也较高。
在采用 DolphinScheduler 之前,联通数科使用原商业调度系统支撑着全域数据平台加工与调度,以接口机+Shell(HiveSQL)为主的开发编排运维模式,处理日均数万的流程实例和日均数十万的 Job 作业。但由于原调度系统承载业务量巨大,作业编排的控件类型又很多样化,作业定义与调度策略复杂,给部门的调度任务带来不小的难度。联通数科开始设想,是否可以用一款开源框架直接替换掉这套系统。
![]()
对新调度系统的要求
![]()
因为面对的业务量巨大,业务场景复杂,联通数科数据智能事业部对于调度系统的采用有着较高的要求:
1. 满足业务需求
联通数科已经沉淀了一些应对特有业务场景的解决方案,对调度系统的期望是需要能够适配现有方案的要求,或提出更好的方案。
2. 满足大数据量要求
支持日均两万流程实例,十万的任务实例。
3. 用户使用成本低
因为联通数科调度平台的用户不仅有技术人员,还包括生产运营、产品等其他部门人员,所以需要有直观的可视化工作流的定义,工作流实例的监控和问题排查功能。
4. 调度功能要求
需要满足复杂的调度策略和干涉策略,满足高稳定性,能够应对突发情况时作业量激增的情况。
![]()
Dolphin Scheduler恰好满足痛点需求
![]()
当时,国内外已经有不少开源的调度系统可供联通数科选择,如 Oozie、Azkaban 等流行调度产品。但是 Oozie 存在着配置工作流过程需要编写大量 xml 语言配置,社区活跃度低,代码复杂度比较高等问题,Azkaban 也存在创建 job 需要手动完成固定格式文件,任务执行中信息存储在内存中并没有持久化,一旦失败会丢失所有工作流等问题,这些缺点都不易于二次开发。

Airflow 与 DolphinScheduler 对比
经过综合对比分析,从学习和使用成本、任务规模支持程度、社区支持程度,以及社区活跃度角度出发,联通发现可以在其之上进行二次开发的最合适的开源调度系统,是 Apache DolphinScheduler。
这是因为 DolphinScheduler 满足了联通数科对调度系统的几个痛点需求:
其一,完美的无中心化架构设计,确保调度平台稳定性。
DolphinScheduler 分布式去中心化的架构优于其他流行调度系统的架构设计,能够满足其对于稳定性的要求。
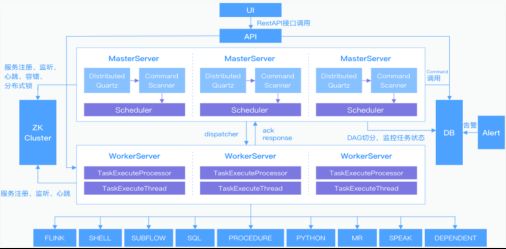
DolphinScheduler 的 MasterServer 为无中心设计,它主要负责 DAG 任务切分、任务提交监控,并同时监听其它 MasterServer 和 WorkerServer 的健康状态。MasterServer 服务启动时向 Zookeeper 注册临时节点,通过监听 Zookeeper 临时节点变化来进行容错处理。
WorkerServer 同样也是无中心设计,主要负责任务的执行和提供日志服务。WorkerServer 服务启动时向Zookeeper注册临时节点,并维持心跳。
去中心化的多 Master 和多 Worker, 自身支持 HA 功能, 采用任务队列来避免过载,不会造成机器卡死,保证了系统的高可靠性。
其二,图形化的页面设计,降低使用成本。
当时市场上常用的调度系统都需要用户编写脚本文件定义流程,对于核心调度系统的多部门用户来讲,使用成本较高。而维护页面的成本小于脚本,联通数科需要的是一个具备图形化数据流数据器设计的调度系统。这是其采用 DolphinScheduler 的重要原因,可视化的页面编排方式很好地切合了联通数科的场景需求。
其三,DolphinScheduler 支持多策略负载均衡。
DolphinScheduler 支持并行、串行、干涉多种调度方式,相较轮巡导致任务运行过慢甚至服务器宕机的情况,其支持多种策略自动化资源负载均衡,从服务器层面做到任务分发负载均的方式让联通数科很是惊喜,可实现高效调度,如任务调度分组、并发控制,以及根据资源动态调整优先级,在界面直观地看到CPU、内存、Worker、Master 等的负载情况。
其四,DolphinScheduler 支持多种调度机制。
1)任务调度机制,支持时间触发,包括定时触发、循环触发、间隔触发;
2)事件触发机制,支持前置触发和后置触发。
第五,DolphinScheduler 支持数据分析。
通过流程实例数据统计,时间分布甘特图,统计运行时间,流程数量,可视化分析运行时间分布和项目数量,工作流节点状态统计等数据的统计分析,可以更好地监控任务进行状况。


昨日流程数据统计
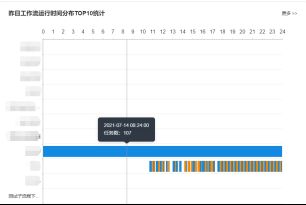
时间分布甘特图
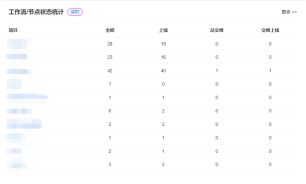
工作流/节点状态统计

工作流运行时统计
第六,直观的可视化监控功能。
DolphinScheduler 的特色之一是 DAG 监控界面,所有流程定义都是可视化的,通过拖拽任务定制 DAG,通过 API 方式与第三方系统对接,可实现一键部署。

第七,完善的告警模块。
DolphinScheduler 有完善的系统服务监控,智能预警机制可根据保留数据计算当前执行节点是否超时,超时则触发预警。
另外不可忽略的一点是,当时联通团队已经对 DolphinScheduler 的源码做了深入研究和分享,也与原始开发团队建立了紧密沟通渠道,在研发方案层面可获得外部专家支持,并看好 DolphinScheduler 开源社区的项目支持、贡献和发展,于是果断决定将原有系统替换为 DolphinScheduler。在系统替换过程中,DolphinScheduler 活跃的社区也为联通数科使用和后期改造提供了很多帮助。
![]()
应用场景&二次开发解决方案
![]()
采用 DolphinScheduler 之后,联通数科根据实际业务需求进行了二次开发,很好地解决了一些特殊挑战,包括以下几个典型应用场景:
1.全局变量
记录 shell 的输出日志,进行解析后获取用户定义的输出变量,并通过 netty 返回给 master,记录在 task Instance 中,下游节点在已完成节点集合中取出上游节点,得到变量池,获取所需变量,实现变量传递。
2. Switch节点
当时 DolphinScheduler 的 condition 节点只支持判断上游节点的成功失败状态,增加全局变量后需要判断变量的值执行不同的下游分支。将表达式格式化为脚本后进行解析,能够解析逻辑表达式。
3. 任务组
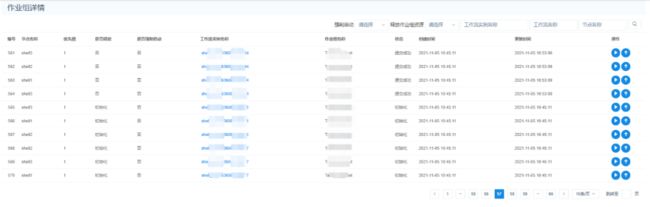
能够控制跨工作流节点并发的功能,在节点从 master 发送到 worker 之前判断资源池是否满足要求,如果不满足则等待,满足则继续执行,节点执行结束后将资源释放。在节点等待期间会根据用户设置的优先级争取资源,并且用户可以选择节点在等待期间强制启动,绕过资源池的限制。
![]()
用户反馈
![]()
![]()
Dolphinscheduler 为大数据调度产品新增了全新的选择,提供了优秀的、多方面可扩展的底层架构设计,我们也和 DolphinScheduler 一起在不断进步的社区环境中共同成长。
——联通数字科技数据智能事业部高级专家 谭晟中
![]()
满怀期待,不断进化
![]()
在经过一年多的生产环境检验后,DolphinScheduler 仍在联通数科平稳运行,处理其 7000+ 的流程实例和数万的任务实例,以及 70 台的 worker 节点。未来,联通数科表示还将根据生产运维方面的需求,在系统自身监控和告警功能优化等方面投入更多精力。

左:联通数科生产运维工程师 程鸣,右:联通数科软件开发工程师 王兴杰

联通数科大数据开发工程师 范伟强
DolphinScheduler 虽然很好地满足了联通数科的调度需求,但任何产品都贵在精益求精,联通数科也表达了对 DolphinScheduler 的期待,希望未来可以增加一些强大的功能,如角色权限管理、血缘功能、对历史数据的处理,以及优化工作流实例、任务实例页面的响应速度等。
带着用户的信任和期待,DolphinScheduler 将在未来版本中逐渐实现这些用户所迫切需求的功能,秉持“大道至简”的原则,在简单易用的基础上,把简单带给用户,将复杂留给自己,打造一个更加好用的大数据工作流任务调度平台!
社区官网
https://dolphinscheduler.apache.org/
代码仓地址
https://github.com/apache/dolphinscheduler
您的 Star,是 Apache DolphinScheduler 为爱发电的动力❤️ ~
添加社区小助手微信
(Leonard-ds)



☞DolphinScheduler 荣获 2021 中国开源云联盟优秀开源项目奖!
☞议题征集令 | Apache DolphinScheduler Meetup 2021 来啦,议题征集正式开启!
☞Apache DolphinScheduler 1.3.9 发布,新增 StandaloneServer
☞美女亲自带你快速上手 DolphinScheduler
☞手把手教你 Apache DolphinScheduler 本地开发环境搭建 | 中英文视频教程☞Apache DolphinScheduler使用规范与使用技巧分享
点击阅读原文,加入开源!
![]()
点个在看你最好看