浅析数据仓库与OLAP
文章向导
- 数据仓库
-
- 1.什么是数据仓库?
-
-
- (1)面向主题的
- (2)集成的
- (3)相对稳定的
- (4)反映历史变化
-
- 2.数据仓库架构
-
-
- (1)DB (Database 缩写)
- (2) ETL (抽取(extract)、转换(transform)、加载(load))
- (3) ODS (Operation Data Store 操作数据层)
- (4) DW (Data Warehouse 数据仓库)
- (5) DM(Data Mart 数据市集)
-
- OLAP
-
- Apache Kylin
-
- cube
数据仓库
1.什么是数据仓库?
- 官方解释
数据仓库,英文名称为Data Warehouse,数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。
——比尔·恩门(Bill Inmon)在1991年出版的“Building the Data Warehouse”(《建立数据仓库》
(1)面向主题的
数据仓库中的数据是按照一定的主题域进行组织。
主题是一个抽象的概念,是指用户使用数据仓库进行决策时所关心的重点方面,一个主题通常与多个操作型信息系统相关。而操作型数据库的数据组织面向事务处理任务,各个业务系统之间各自分离。
(2)集成的
数据仓库中的数据是在对原有分散的数据库数据抽取、清理的基础上经过系统加工、汇总和整理得到的,必须消除源数据中的不一致性,以保证数据仓库内的信息是关于整个企业的一致的全局信息。面向事务处理的操作型数据库通常与某些特定的应用相关,数据库之间相互独立,并且往往是异构的。
(3)相对稳定的
数据仓库的数据主要供企业决策分析之用,所涉及的数据操作主要是数据查询,一旦某个数据进入数据仓库以后,一般情况下将被长期保留,也就是数据仓库中一般有大量的查询操作,但修改和删除操作很少,通常只需要定期的加载、刷新。操作型数据库中的数据通常实时更新,数据根据需要及时发生变化。
(4)反映历史变化
数据仓库中的数据通常包含历史信息,系统记录了企业从过去某一时点(如开始应用数据仓库的时点)到目前的各个阶段的信息,通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。而操作型数据库主要关心当前某一个时间段内的数据。
2.数据仓库架构
- 数据仓库构建流程

(1)DB (Database 缩写)
在讲数据库前,先明确一下数据库与数据库管理系统的一个概念和关系
我们常常挂在嘴边的数据库有 MySQL ,SQL-Server, Oracle 等等,其实这种叫法都是错误的因为这些能叫出名字的它们都是软件,它们正确的加法应该是RDBMS (关系型数据库管理系统 - Relational Database Management System)注意这里因为我前面介绍的这些它们数据关系型数据库,所以我们才把它们加上Relational 关系型的头衔,因为有了关系型必然也有非关系型数据库管理系统例如Hbse,MongoDB,Redis等等。
我们大可把所有这些管理数据库的系统统称为DBMS (Database Management System)
先来看一看这些数据库管理系统里面的结构

| 比较项目 | 传统数据库 | 数据仓库 |
|---|---|---|
| 数据内容 | 当前值 | 历史的、归档的、集成的、计算过的数据(处理过) |
| 数据目标 | 面向业务操作程序、重复操作 | 面向主题、分析应用 |
| 数据特性 | 动态变化、更新 | 静态、不能直接更新、只能定时添加和更新 |
| 数据结构 | 高度结构化、复杂、适合操作计算 | 简单、适合分析 |
| 使用频率 | 高 | 低 |
| 数据访问量 | 每个事物一般之访问少量记录 | 每个事务一般访问大量的记录 |
| 响应时间要求 | 计时单位小,如秒甚至毫秒 | 计时单位相对较大、如分钟、小时等 |
(2) ETL (抽取(extract)、转换(transform)、加载(load))
很容易从名字解释出这一过程的作用和 RAW (read and write)的过程类似,不过中间多了一个转换的步骤
可能会有疑问为什么要有这一步,那我先用一个实际的例子来说,比如下图这个案例:

(3) ODS (Operation Data Store 操作数据层)
顾名思义,根据前面数据仓库的构建流程图可以看到这一层所在的位置就知道这一层中的数据是通过ETL清洗过的干净的数据,这一层相较于原始的业务数据库(DB层面),这一层的数据的定义做了统一,缺失数据做了补全,前面看到的这三个环节其实也就现在常说的中台这一层组织架构所做的事情。
(4) DW (Data Warehouse 数据仓库)
通过前面的步骤我们得到了较为干净的数据,现在我们需要对这一系列的数据做分类,其实也就是建模,我们需要将这些数据中的用于描述一件事物的属性提出来作为维度表(dim),其中一些表述业务具体产值之类的我们把它们作为度量值也就是放在事实表(fact)当中。
-
星型模型

-
雪花模型
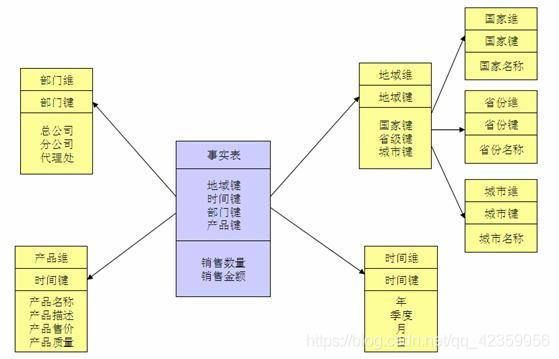
数据仓库中都会包括一个或多个事实数据表,包含在事实表中的“度量值”有两种,一种是可以累计的度量值,另一种是非累计的度量值。
从用途的不同来说,事实表可以分为三类,分别是事务事实、周期快照、累计快照。
维度:是人们观察数据的特定角度,是考虑问题时的一类属性,属性集合构成一个维,通常有日期、地区等维度。
切片:一种用来在数据仓库中将一个维度中的分析空间限制为数据子集的技术。
切块:一种用来在数据仓库中将多个维度中的分析空间限制为数据子集的技术。
星型模式:是数据仓库应用程序的最佳设计模式。它的命名是因其在物理上表现为中心实体,典型内容包括指标数据、辐射数据,通常是有助于浏览和聚集指标数据的维度。星形图模型得到的结果常常是查询式数据结构,能够为快速响应用户的查询要求提供最优的数据结构。星形图还常常产生一种包含维度数据和指标数据的两层模型。
雪花模式:指一种扩展的星形图。星形图通常生成一个两层结构,即只有维度和指标,雪花图生成了附加层。实际数据仓库系统建设过程中,通常只扩展三层:维度(维度实体)、指标(指标实体)和相关的描述数据(类目细节实体);超过三层的雪花图模型在数据仓库系统中应该避免。因为它们开始像更倾向于支持OLTP 应用程序的规格化结构,而不是为数据仓库和OLAP应用程序而优化的非格式化结构。
粒度:粒度将直接决定所构建仓库系统能够提供决策支持的细节级别。粒度越高表示仓库中的数据较粗,反之,较细。粒度是与具体指标相关的,具体表现在描述此指标的某些可分层次维的维值上。例如,时间维度,时间可以分成年、季、月、周、日等。
数据仓库模型中所存储的数据的粒度将对信息系统的多方面产生影响。事实表中以各种维度的什么层次作为最细粒度,将决定存储的数据能否满足信息分析的功能需求,而粒度的层次划分、以及聚合表中粒度的选择将直接影响查询的响应时间。
度量值:在多维数据集中,度量值是一组值,这些值基于多维数据集的事实数据表中的一列,而且通常为数字。此外,度量值是所分析的多维数据集的中心值。即,度量值是最终用户浏览多维数据集时重点查看的数字数据(如销售、毛利、成本)。
(5) DM(Data Mart 数据市集)
以具体某个业务应用为出发点而建设的局部dw,dw只关心自己需要的数据,不会全盘考虑企业整体的数据架构和应用。
这一层次其实说实话定义还是相对比较模糊,你就可以就根据他的名字来看,市集嘛其实就是离我们普通用户最近的数据了,就比如你平常在商店里面买东西,你必然也只能看到货架上摆出来的商品,而这些商品哪儿来,还不是得从超市的仓库(和我们这儿的数据仓库对应)中来,普通用户是没法直接进入我们的仓库中拿东西的,这里也是这个道理。
事实:是数据仓库中的信息单元,也是多维空间中的一个单元,受分析单元的限制。事实存储于一张表中(当使用关系数据库时)或者是多维数据库中的一个单元。每个事实包括关于事实(销售额,销售量,成本,毛利,毛利率等)的基本信息,并且与维度相关。在某些情况下,当所有的必要信息都存储于维度中时,单纯的事实出现就是对于数据仓库足够的信息。
OLAP
- 官方解释:
OLAP (Online Analytical Processing 联机分析处理)
它使分析人员能够迅速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的。它具有FASMI(Fast Analysis of Shared Multidimensional Information),即共享多维信息的快速分析的特征。其中F是快速性(Fast),指系统能在数秒内对用户的多数分析要求做出反应;A是可分析性(Analysis),指用户无需编程就可以定义新的专门计算,将其作为分析的一部 分,并以用户所希望的方式给出报告;M是多维性(Multi—dimensional),指提供对数据分析的多维视图和分析;I是信息性(Information),指能及时获得信息,并且管理大容量信息。 - 它与OLTP的区别:
OLTP(Online Transaction Processing)也称为面向交易的处理过程,其基本特征是前台接收的用户数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果,是对用户操作快速响应的方式之一。
| 对比项目 | OLTP | OLAP |
|---|---|---|
| 用户 | 操作人员、低层管理人员 | 决策人员、高级管理人员 |
| 功能 | 简单的事务、日常操作处理 | 复杂查询、分析决策 |
| DB设计 | 面向应用、业务的数据库 | 面向主题、分析的数据仓库 |
| 数据 | 读/写数十条记录 | 读上百万条记录 |
| 实效性 | 实时性 | 对实效性要求不严格 |
| 应用 | 数据库 | 数据仓库 |
Apache Kylin
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。之所以能提供低延迟(sub-second latency)的秘诀就是预计算,即针对一个星型拓扑结构的数据立方体,预计算多个维度组合的度量,然后将结果保存在hbase中,对外暴露JDBC、ODBC、Rest API的查询接口,即可实现实时查询。

如上图所示,Kylin从Hadoop Hive中获取数据,然后经过Cube Build Engine,将Hive中的数据Build成一个OLAP Cube保存在HBase中。用户执行SQL查询时,通过Query引擎,将SQL语句解析成OLAP Cube查询,然后将结果返回给用户
cube
也就是通过在Kylin中构建好相应的模型后,然后Kylin通过解析这个模型,再到对应底层数据仓库当中拉取相应的数据,通过各个维度进行排列组合,然后将这些不同的维度组合对应出来的度量聚合值进行预计算,也就成立下面的数据立方体

我们将不同的维度排列组合后,聚合计算出来的度量值,我们会存在Hbbase(一个列簇数据库)中,之所以要用列簇数据库是因为数据量量很大,而且往往我们的需求是通过用户传入的SQL,我们分析出SQL中的逻辑和筛选条件,我们可以很快的通过这些条件以 映射的方式在Hbase 中找到我们提前与计算好的值,直接拿出来即可。而如果利用行索引的数据库我们在查找时会增加很多不必要的查询时间的开销。cube 的理想状态是能够让用户所有的SQL都能直接在我们的预计算集合中取,而不是重新计算。当然这样是理想话的,实际中往往我们只需要分析出使用频繁的查询SQL,然后把里面的条件提取出来进预计算即可,我们通常把一个SQL 能够不计算就能在cube中取出数,这样的一个情况叫做命中,肯定一个cube 的命中率是越高越好。这就是Kylin cube 的一个作用。