mlp实现mnist手写数据集的分类
首先看数据集,使用sklearn.datasets中的mnist手写数据集,先看看数据集。
from sklearn.datasets import load_digits
digits = load_digits()
x_data = digits.data
y_data = digits.target
print(x_data.shape)
print(y_data.shape)
digits中有1797条数据,每个图像有64(8*8)的维度。将x_data和y_data分为训练集和测试集。
x_train,x_test,y_train,y_test = train_test_split(x_data,y_data)train_test_spilt()j将x_data,y_data按比例分为训练集和测试集,test_size默认为0.3.
print(x_train.shape)
print(y_train.shape)
用MLPClassifier构造一个mlp模型,改变隐藏层参数,比较不同参数下的准确率。
mlp = MLPClassifier(hidden_layer_sizes=(100,50), max_iter=500)
mlp.fit(x_train,y_train)
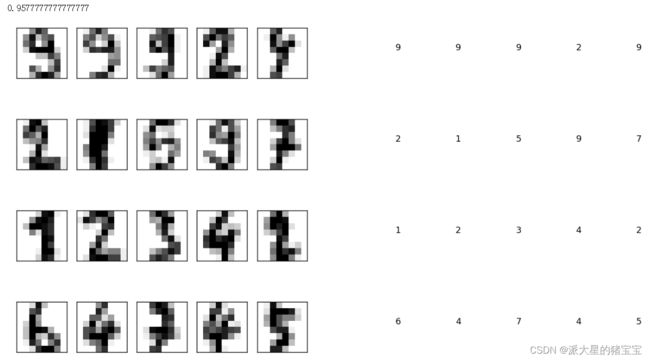
print(mlp.score(x_test,y_test)) ![]()
发现隐藏层越深,神经元个数越多的mlp有更高的准确率,三层隐藏层比两层隐藏层的准确率高,同样是两层隐藏层,每层中神经元个数越多准确率越高。当mlp隐藏层数太低,就会出现欠拟合的情况。
关于准确率的评价,有几种方式。
1.mlp.score
2.accuracy_score
第二种计算模型得分的函数是调用包
from sklearn.metrics import accuray_scorearruray_score 函数利用y_test和y_predict计算得分。如果有时我们不知道y_predict,只关注模型最终得分的话,可以使用第一种方法
mlp.score(x_test,y_test)完整代码:
from sklearn.neural_network import MLPClassifier
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
digits = load_digits()
x_data = digits.data
y_data = digits.target
##print(x_data.shape)
##print(y_data.shape)
y=digits.data[1].reshape([8, 8])
#数据拆分
x_train,x_test,y_train,y_test = train_test_split(x_data,y_data)
#构建模型,2个隐藏层,第一个隐藏层有100个神经元,第2隐藏层50个神经元,训练500周期
mlp = MLPClassifier(hidden_layer_sizes=(100,50), max_iter=500)
mlp.fit(x_train,y_train)
print(mlp.score(x_test,y_test))
#测试集准确率的评估
predictions = mlp.predict(x_test)
for i in range(1, 21):
plt.subplot(4,5, i) #划分成2行5列
plt.imshow(x_test[i - 1].reshape([8, 8]), cmap=plt.cm.gray_r)
plt.text(60, 3, str(predictions[i-1])) #在图片的任意位置添加文本
plt.xticks([]) #认为设置坐标轴显示的刻度值
plt.yticks([])
plt.rcParams['savefig.dpi'] = 128 #图片像素
plt.rcParams['figure.dpi'] = 128 #分辨率
plt.subplots_adjust(bottom=0.10,top=1.5)
plt.show()