使用MindStudio进行 FasterRCNN-FPN-DCN模型onnx推理
一:介绍
本帖将以FasterRCNN-FPN-DCN为例。以图文的方式较为详细的展示基于MindStudio和CANN架构的Pytorch离线推理全流程。技术问题可以登陆MindStudio昇腾论坛进行发帖和讨论。
下面对本次实验的任务进行一个简单的介绍。
任务场景:模型迁移
任务描述:将预训练好的FasterRCNN-FPN-DCN网络的pth权重模型,先转换成onnx模型,再转为昇腾om模型。随后基于om模型在昇腾的图形处理设备上(NPU Ascemd 310、NPU Ascemd 710)进行离线推理。
任务目标:模型的精度需要达到基准线的99%以上。710上的推理性能需要达到310的1.2倍。T4 GPU的1.6倍。
环境信息:昇腾设备:Ascend 310、Ascend 710、OS:Ubuntu Linux、CANN版本:5.1.RC1。
此外本次实验全程在MindStudio上进行,请先按照教程配置环境,安装MindStudio。MindStudio的是一套基于华为自研昇腾AI处理器开发的AI全栈开发工具平台,该IDE上功能很多,涵盖面广,可以进行包括网络模型训练、移植、应用开发、推理运行及自定义算子开发等多种任务。MindStudio除了具有工程管理、编译、调试、运行等一般普通功能外,还能进行性能分析,算子比对,可以有效提高工作人员的开发效率。除此之外,MIndStudio具有远端环境,运行任务在远端实现,对于近端的个人设备的要求不高,用户交互体验很好,可以让我们随时随地进行使用。
二:服务器端环境准备
2.1:服务器端主要依赖
| 依赖名称 |
版本 |
| ONNX |
1.9.0 |
| Pytorch |
1.8.0 |
| TorchVision |
0.9.0 |
| numpy |
1.21.6 |
| mmcv-full |
1.2.7 |
| mmdetection |
2.8.0 |
2.2:创建conda环境、安装pytorch(cpu)版本
1:conda create -n zyc710 python=3.7
2:pip install torch==1.8.0+cpu torchvision==0.9.0+cpu torchaudio==0.8.0 -f https://download.pytorch.org/whl/torch_stable.html
2.3:安装mmcv(需要严格执行下述语句安装对应分支)
1:git clone https://github.com/open-mmlab/mmcv -b master
2:cd mmcv
3:git checkout v1.2.7
4:MMCV_WITH_OPS=1 pip install -e .
5:patch -p1 < ../mmcv.patch
6:cd ..
2.4:安装mmdetection
1:git clone https://github.com/open-mmlab/mmdetection -b master
2:cd mmdetection
3:git reset --hard a21eb25535f31634cef332b09fc27d28956fb24b
4:patch -p1 < ../dcn.patch
5:pip3.7 install -r requirements/build.txt
6:python3.7 setup.py develop
7:cd ..
2.5:完成示意图。有以下依赖即可

2.6:将官网文档下的代码数据包导入到服务器下自己的目录。
三:MindStudio配置
3.1:MindStudio配置环境与安装。
MindStudio是一套基于IntelliJ框架的开发工具链平台,提供了应用开发、调试、模型转换功能,同时还提供了网络移植、优化和分析功能,为用户开发应用程序带来了极大的便利,安装详见此处。
3.2:创建工程、连接服务器、同步项目文件。
Step1:安装完成后,首次登录MindStudio并点击 “New Project” 创建新的项目,进入创建工程界面。
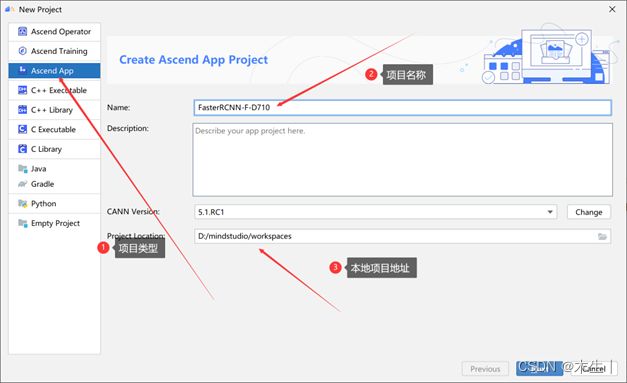
Step2:按照下述选择项目类型、项目名称以及本地地址
Step3:配置上述CANN Version选择远程服务器(点击Change出现以下界面)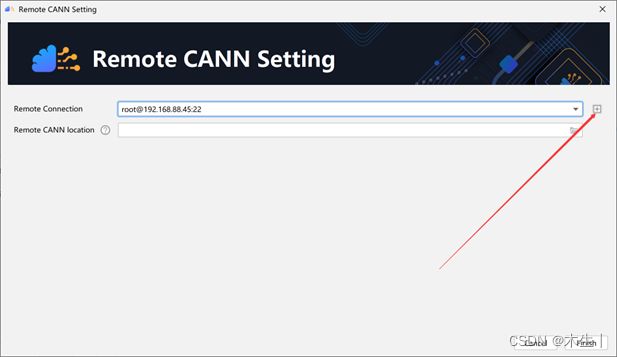
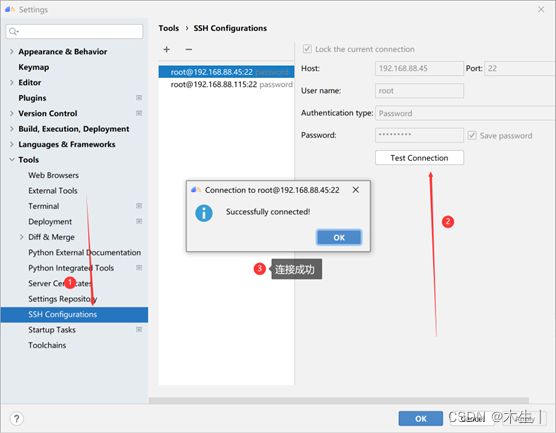
Step4:填写远程服务器信息,并测试是否连通

Step5:连接成功后返回上一页面选择CANN目录。具体如下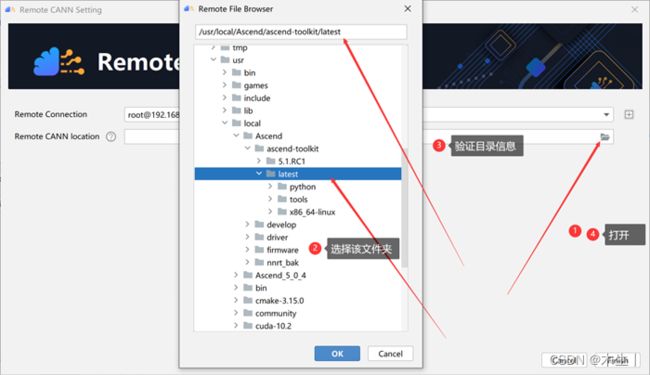
Step6:等待连接完成
Step7:完成同步后,选择MindX SDK Project项目。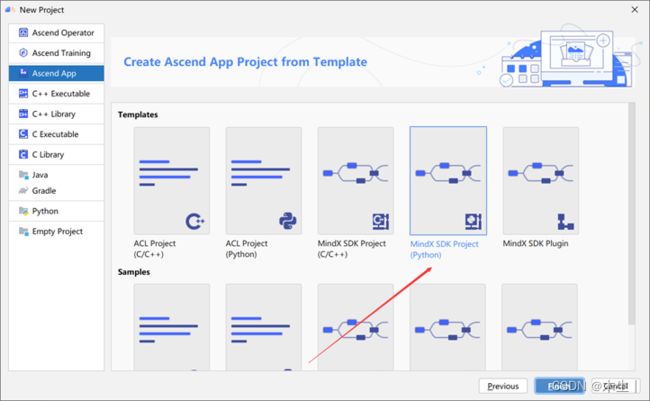
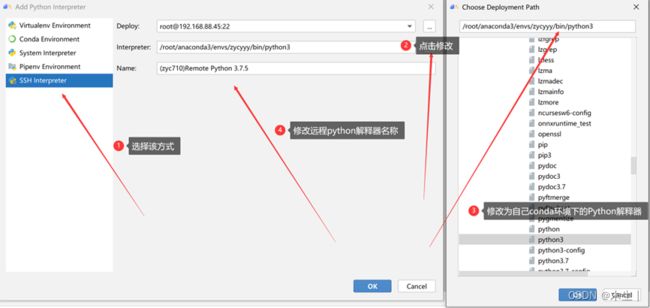
Step8:添加远程python SDK(服务器自己conda环境下的python sdk)

Step9:添加完远程Python SDK后,在project和modules中进行相应设置。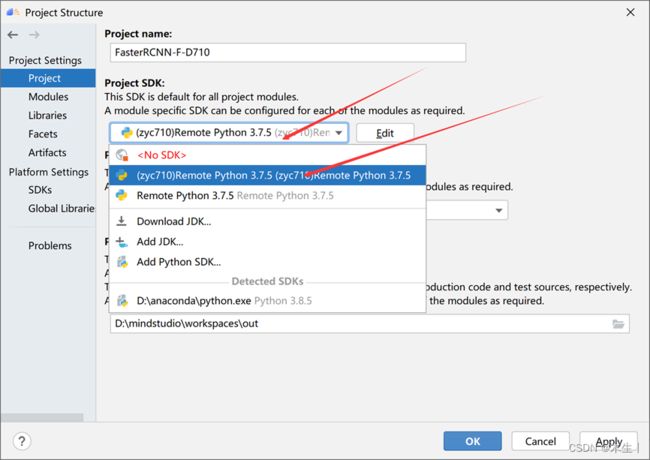

Step10:至此,配置本地项目使用远程服务器自己的conda环境下的Python以完成。下面配置本地文件夹与远程服务器映射Deployment。(打开file→settings进行如下选择)
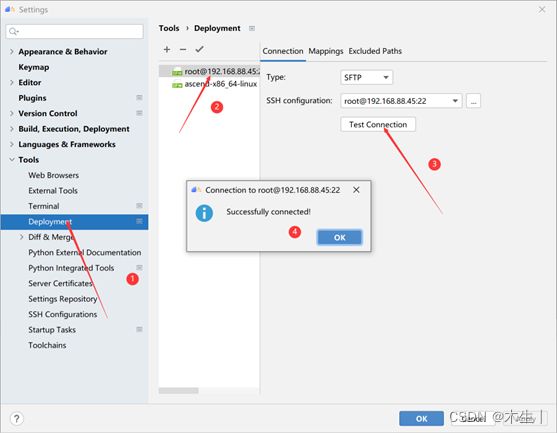
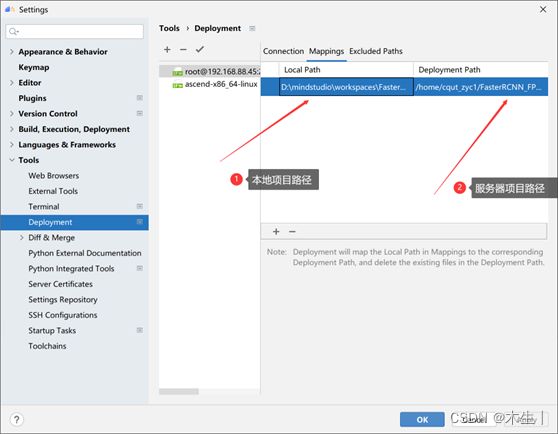
Step11: 准备本地项目。
此步骤较为麻烦,①可以选择从服务器下载项目文件到本地,②也可以直接将2.6中的项目文件直接放入本地路径中。①整体过程较慢,推荐使用②。①操作方法如下所示。
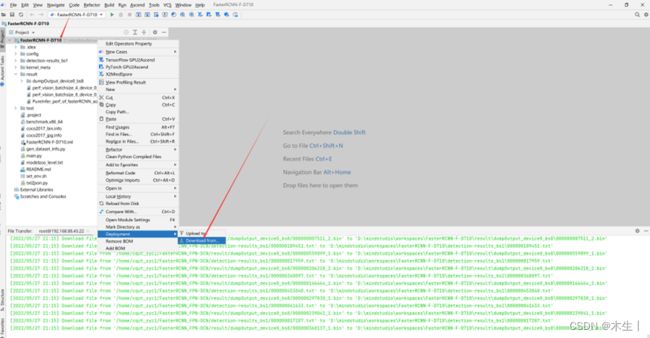
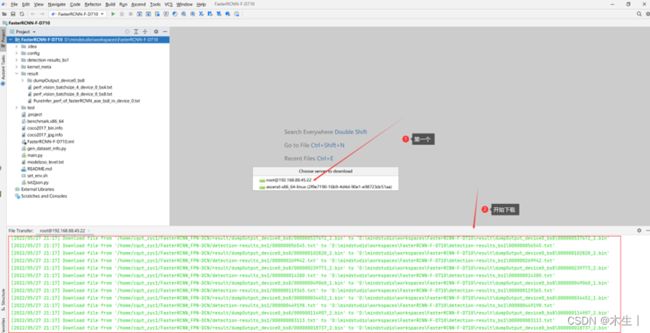
Step12:完成下载后需保持本地路径与远程路径的文件同步。
注:在执行代码时候会自动校验本地目录和远程目录,若不相同。远程目录会以本地目录为参考对象进行删除!强烈建议一定要设置好了不同步文件夹后再执行代码。
设置文件夹不进行同步,如下图所示。具体参考此处链接。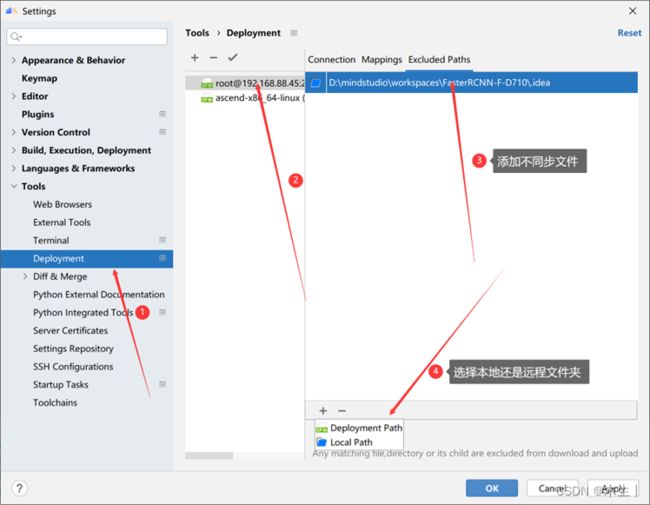
其中local path与Deploymente path区别如下
Step13:通过上述过程完成了本地的mindstudio项目连接远程服务器,并创建了同步的本地文件夹和远程文件夹。执行创建项目自带的main.py测试是否正常执行。(该步骤会自动校验文件,耗时较长。建议根据step12设置部分文件夹不同步:如数据集、权重模型文件夹等)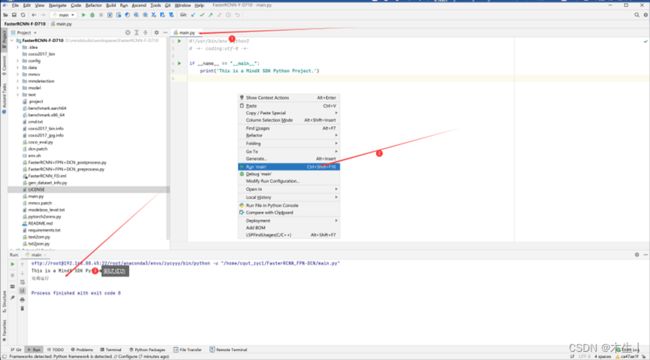
3.3:转换模型文件(pth→onnx→om)
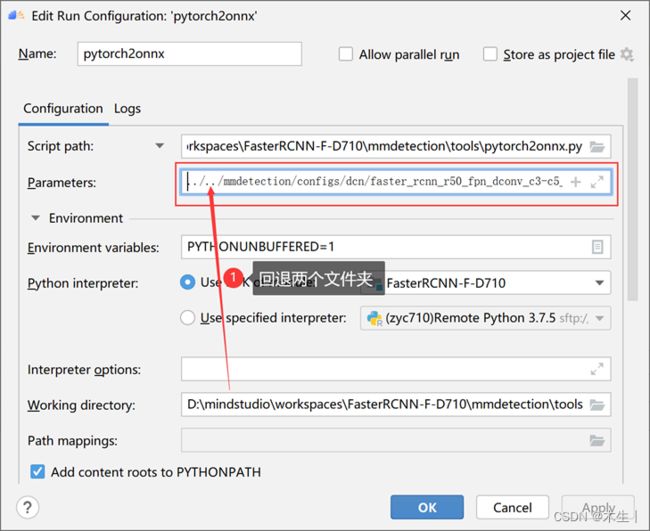
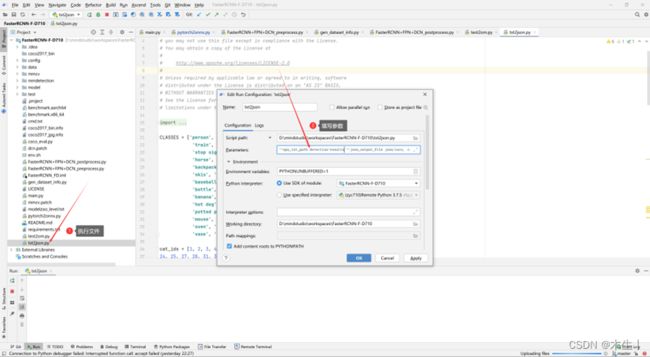
3.3.1:pth转onnx模型。填写参数文件时按照此链接填写。
需要注意的是不能在本地终端执行Python文件。需要直接找到本文件点击run。参数文件填写时需要回退两个文件夹(即:FasterRCNN_FPN-DCN/mmdetection/tools回退到FasterRCNN_FPN-DCN/)路径才正确。
注:下述所有需要填写的代码参数均以此链接“快速上手”里面的预处理python语句为准。
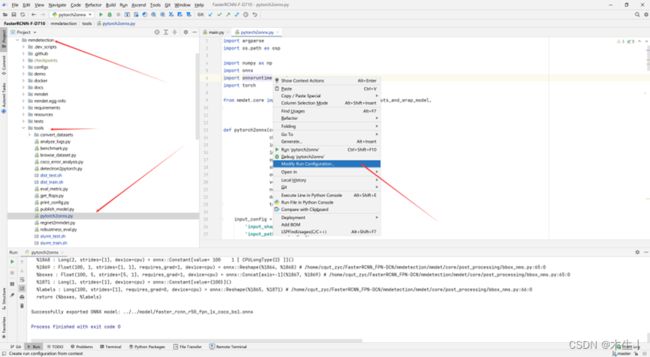

3.3.2:onnx转om模型。
注:此处pth转出来的onnx不能成功转换为om模型,需要添加代码进行相应修改。
- 打开Mindstudio自带的om模型转换工具(onnx→om):
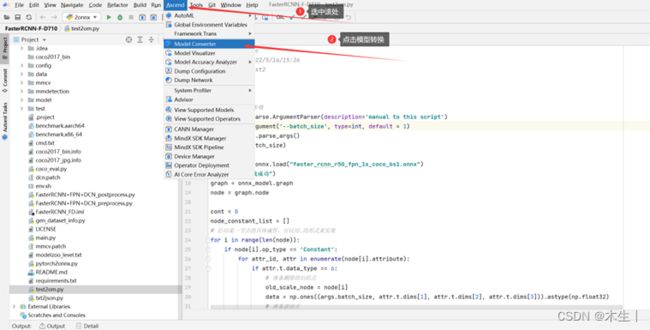
- ①直接转换示例(会失败):
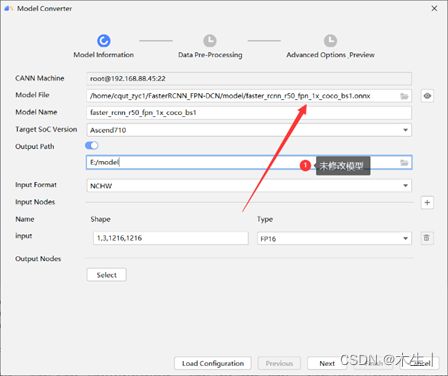
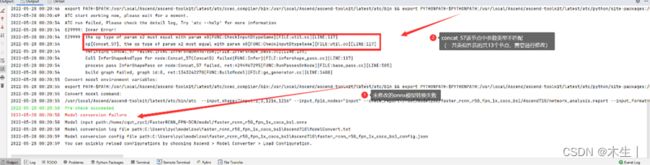
- ②修改后转换示例:
执行代码:(远程终端)
1:cd model
2:python test2om.py --batch_size=1
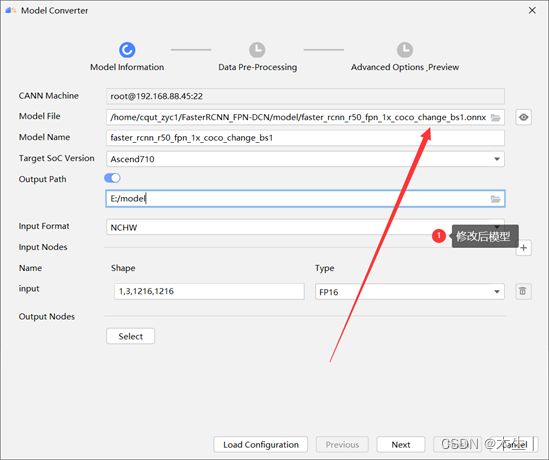
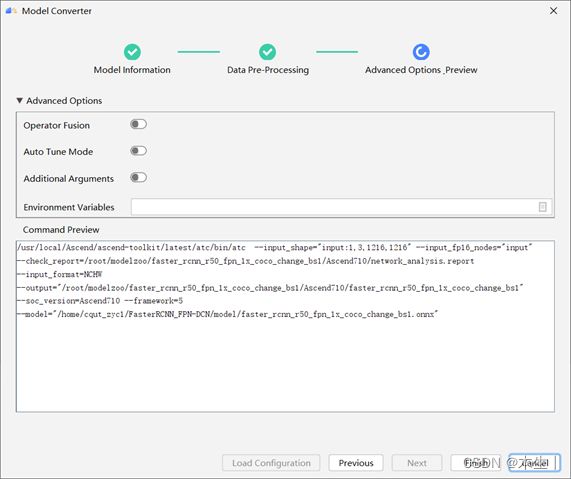

得到faster_rcnn_r50_fpn_1x_coco_change_bs1.onnx模型文件,此时再次通过model converter进行转换。即可成功转为om模型。
3.4:数据预处理
①运行“FasterRCNN+FPN+DCN_preprocess.py”脚本文件。得到coco2017_bin文件夹。

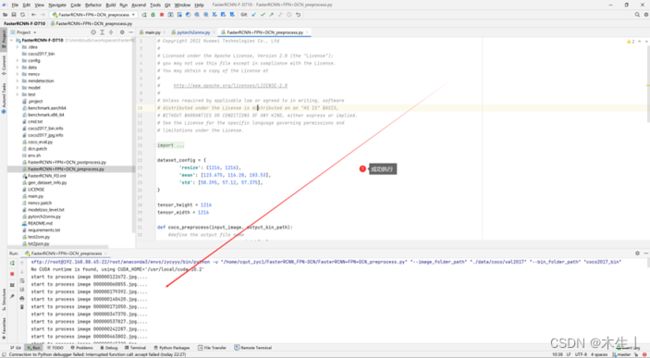
②数据集jpg照片转info文件

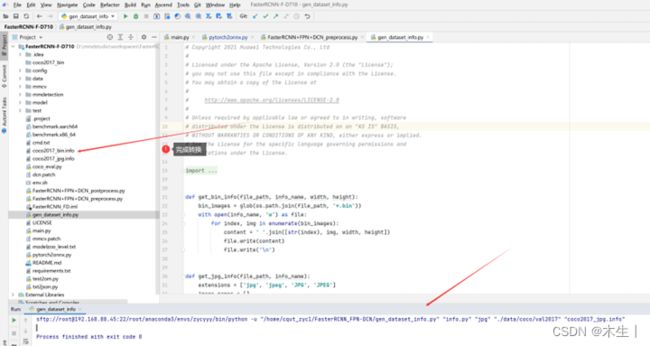
③Coco2017_bin转info文件
3.5:执行推理验证。(此部分需要在远程终端进行)
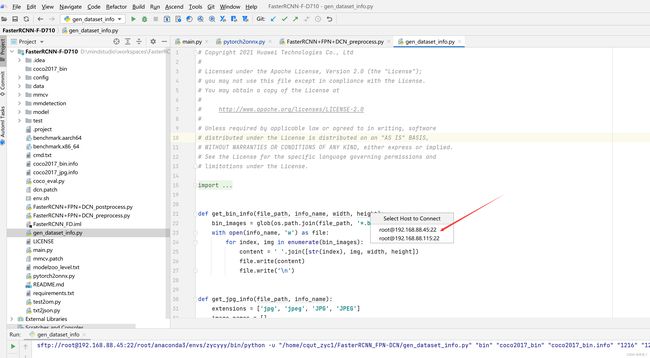
3.5.1:连接远程终端
3.5.2:激活环境与推理工具

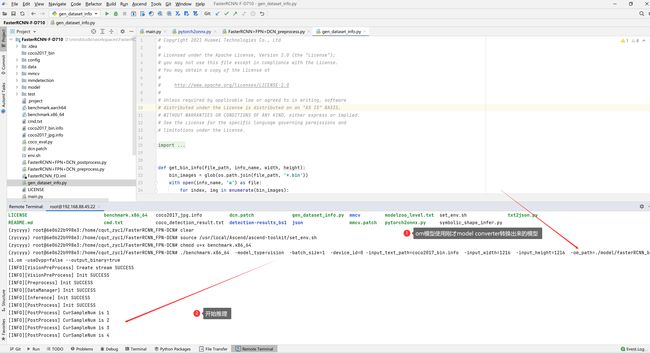
3.5.3:开始推理
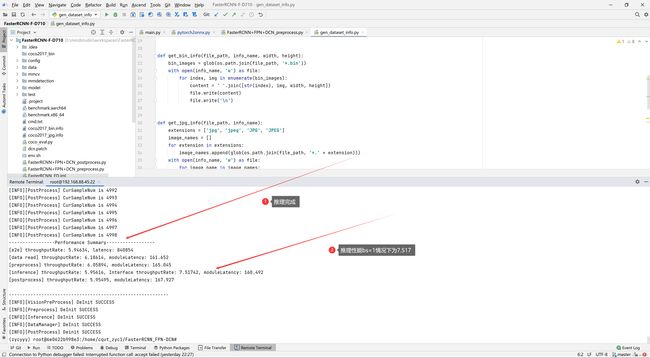
3.6:数据后处理部分
3.6.1:将推理得到的bin文件夹(dumpOutput_device0)转为txt文件夹(detection-results)

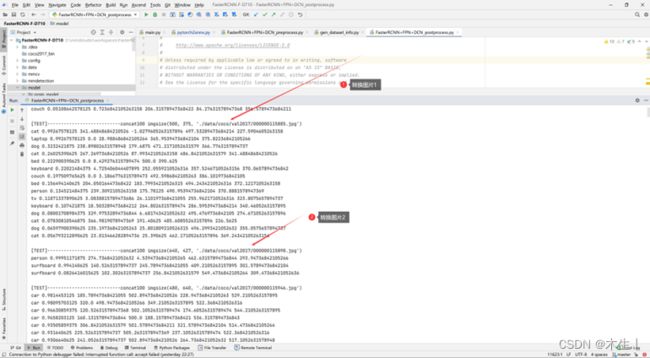
3.6.2:将得到的txt文件夹 (detection-results)转为json数据
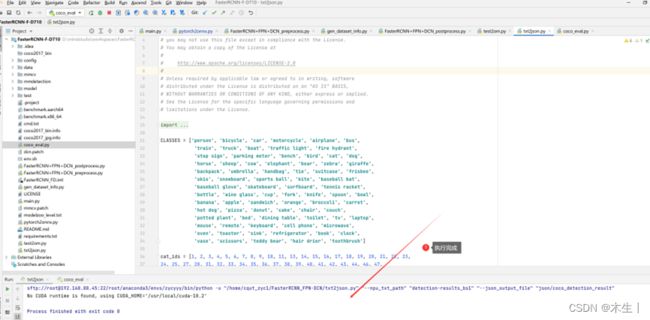
3.6.3:将得到的json文件和coco给出的验证集json文件进行对比。

总结
1:精度数据如上3.6.3所示。性能数据在3.5.3中最后一图
2:310与710上述流程相同。
3:经过转换后,模型精度和性能达到要求。针对每个步骤提供了详细的图文描述。
FAQ
1:为什么自带的pth转的Onnx模型,转不了om模型?
答:通过远程终端执行ATC语句进行转换,或是使用Mindstudio自带的Model Converter进行转换均会报错:“Concat结点的参数0和参数3类型不一致。”经过可视化发现其参数3的数组数据类型为Int32应修改为Float32。
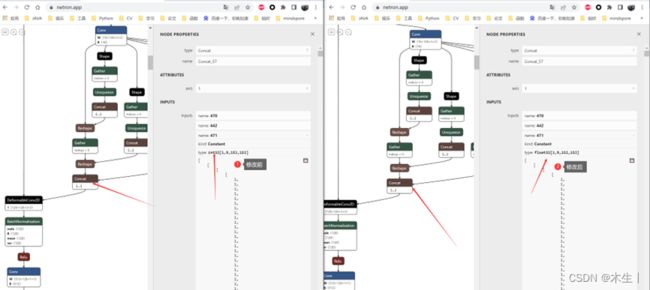
同样类型的结点有13个,需要进行结点的查找和修改。相关代码写在了3.3.1中提到的test2om.py文件中。
2:为什么得不到batch_size > 1时的模型推理精度数据?
这也是这个模型的一个“坑”,我在测试不同batch_size下的精度数据和性能数据时也发现了这个问题。总的来说是因为以下两点。
①:本模型是一个静态模型,其中定义了很多constant常量数组都不支持动态batch。
②:后处理代码FasterRCNN+FPN+DCN_postprocess.py文件的编写逻辑也是只支持batch_size为1的情况。
具体分析如下:
首先我在测试不同batch_size情况下的om模型的推理性能时。发现上述图中的constant数组,其第一维度均定义为了1。加上此模型为静态模型。故只支持batch_size=1情况下的推理。
然后经过对上述13个constant数组的查找和修改其第一维度的数值为batch_size后(该功能也在test2om中实现了),也可成功转为om后面进行benchmark测试,并得到相应的bin文件。但后续执行FasterRCNN+FPN+DCN_postprocess.py(bin→txt)后处理代码只能处理bs=1的情况下,故无法进行后续的精度测试。(但执行benchmark的过程中可以得到不同bs下的性能指标。)
小结:所以在利用test2om.py文件对onnx模型进行修后。可以测试得到不同bs下的推理性能。但是只能得到bs=1时候的推理精度数据。