通过图注意力网络对多变量时序异常检测
原文:Multivariate Time-series Anomaly Detection via Graph Attention Network
现有的多变量时序异常检测一个主要的局限是不能明确地捕获不同时序的关系,导致错误告警。
本文提出一种自监督框架,处理多变量时序异常检测的这种问题。
本框架将每个单变量时序作为一个单独的特征,含有两种图注意力层并行学习多变量在时间和特征维度复杂的依赖关系。
模型的关键是两个图注意力层,即特征图注意力层和时间图注意力层。特征图注意力层捕获多特征间的因果关系,时间图注意力层突出时间维度的依赖。
本文的主要贡献:
1. 提出了一种新的自监督框架解决多参数时间序列异常检测问题;其性能在公开数据集上优于现有方法,F1值在生产数据上提升了9%。
2. 首次平衡了两个并行的图注意力层(GAT)动态学习不同时序和时间戳的关系。特别是可以在没有先验知识的前提下捕获不同时序的相关性。
3. 通过引入一个连接优化目标整合了预测模型和重构模型的优势。预测模型集中于单时间戳的预测,而重构模型学习潜在的整体时间序列的表征。
4. 网络有很好的可解释性。分析通过图注意力层学习的多重时间序列的注意力分数,其结果符合人们的直觉。同时网络有异常诊断的能力。
预测模型专注于下一个时间戳的特征工程的预测;构建的模型负责捕获整个时间序列的数据分布。
多变量时间序列异常检测目的是在实体层级检测异常。
问题定义:多变量实际学异常检测的输入定义为 x ,x 属于 n * k 的自然数矩阵,n 是输入的特征数量。对一个长时间序列,通过长度为 n 的滑窗产生固定长度的输入。多变量时间序列异常检测任务是输出向量 y,数量为 n,yn范围在0,1间用于判断时间戳是否异常。
网络工作流程
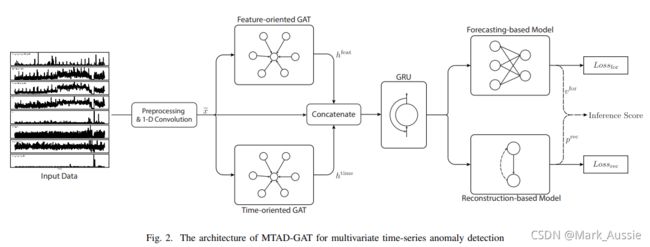
1. 应用一维卷积,7个核在第一层抽取每个时间序列输入的高维特征。
2. 一维卷积层的输出再通过两个平行的图注意力层(GAT)处理,找出多特征和时间戳间的关系。
3. 合并连个GAT层输出的结果,放入GRU层,GRU有 d1 个隐藏层维度。GRU层是为了捕获时间序列的序列模式。
4. GRU的输出放入并行的预测和重构模型获取最终结果。使用预测模型作为全连接网络,采用VAE作为重构模型。
数据处理
数据正则化:为增强模型鲁棒性,对数据正则化处理并对每个单独的时间序列清洗。对训练和测试数据都要正则化,数据清洗只对训练数据。使用训练数据的最大最小值对时间序列正则化。
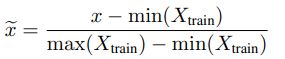
数据清理:预测和构造的模型对不规律和异常的样本敏感。为缓解此问题,使用单变量异常检测的方法--SR,在训练数据中每个时间序列中检测异常的时间戳。将检测到的异常时间戳使用正常值替代。 SR不会给整个模型添加过多开销。
Graph Attention Layer (GAT):构建任意图节点间的关系。给定一个有 n 个节点的图,组成为{v1, v2, ...vn},vi 代表每个几点的特征向量。GAT层计算每个几点输出表征公式如下:
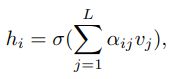
hi 表示节点 i 的输出表征,其 shape 和输入的 vi 一样;σ 表示 sigmoid激活函数,α(ij) 是注意力分数,可衡量节点 j 对节点 i 的影响,节点 j 是节点 i 的临近节点;L 代表节点 i 临近节点的数量。
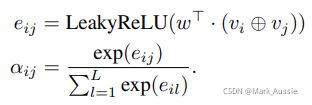
⊕ 表示合并两个节点的表征, w 是 2 * m 的可学习参数向量,m 是每个节点的特征维度,LeakyReLu 是非线性激活函数。
特征图注意力层:需要在没有先验知识前提下检测多变量的关系。将多变量时序作为一张完整图,其中每个节点代表一个特征,每个边代表两个对应特征的关系。毗邻节点的关系可通过图注意力操作捕获。每个节点 xi 通过一个序列向量 {xi,t|t∈[0,n)} 表示,共有 k 个节点,n 是时间戳的总数量,k 是多变量特征的总数量。
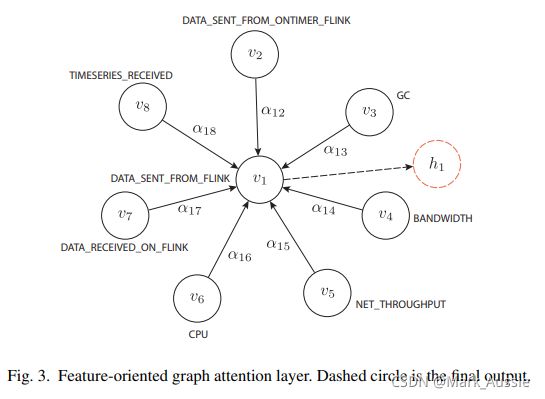
时间图注意力层:使用图注意力网络捕获时序中的时间依赖。一个滑动窗口内所有的时间戳作为一张完整的图。一个节点 xt 代表时间戳 t 的特征向量,其毗邻节点包含滑窗内所有其他时间戳。(类似Transformer 模型)。特征图注意力层输出是 k * n 的矩阵,每行是一个 n 维向量,表示节点输出,共有 k 个节点。时间图注意力层的输出也是 n * k。
连接优化:在训练过程中,两个模型参数是同时更新的。损失函数是两个优化目标的和。
Loss_for是预测模型的损失函数;Loss_rec是构造模型的损失函数
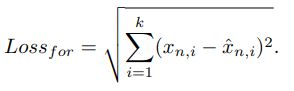
预测模型预测下一个时间戳的值。在GRU层后,使用三个隐层维度为 d2 的全连接层做预测。损失函数使用RMSE。xn 表示相对于当前输入的 x = (x0,...xn-1)的下一个时间戳;xˆn,i代表预测模型的预测值。
重构模型目的是潜在表征 z 学习数据的边缘分布。使用变化的自编码器(VAE),其可以提供对描述在临近空间的一个观测值的概率方式。将时序值作为变量,VAE 模型可以捕获整个时序的数据分布。给定输入 x,可以通过条件分布 pθ(x|z) 重构,z 是临近空间的向量表征。最优化的目标是找到最好的模型参数可重构 x 及其最近的数据分布。
真实的后验密度: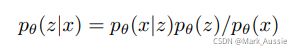
边缘密度公式如下: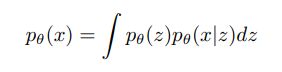
上述等式很难计算,需要使用认知模式 qφ(z|x) 近似后验分布。
戈丁认知模型(编码器) qφ(z|x),生成模型(解码器) pθ(ˆx|z),重构模型损失函数如下:
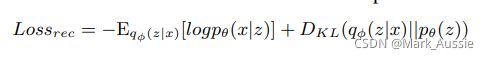
第一部分是给定的输入的期望负对数似然。第二部分是 KL散度作为正则项。
如果时间戳对应的分数大于阈值,则认定此时间戳异常。
可使用POT 方法自动选择阈值。(使用极值理论检测异常的方法),分数计算公式如下:
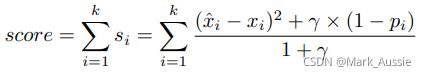
(ˆxi−xi)^2:预测值 xˆi 与实际值 xi之间的误差平方,表明特征值 i 的真实值和预测值偏离的程度;根据重构模型 (1−pi) 是特征 i 是异常值得概率;γ 是超参数,用于合并预测的误差和重构的概率。γ 可通过在验证集上交叉搜索选择。
可从两个方面改进,一是现有模型没有使用特征间的先验知识,可根据用户反馈或领域知识改善模型性能;二是现在的异常诊断是从相对简易场景学习的,可再继续研究更复杂的样例。