深度学习系列1——Pytorch 图像分类(LeNet)
1. 概述
本文主要是参照 B 站 UP 主 霹雳吧啦Wz 的视频学习笔记,参考的相关资料在文末参照栏给出,包括实现代码和文中用的一些图片。
整个工程已经上传个人的 github https://github.com/lovewinds13/QYQXDeepLearning ,下载即可直接测试,数据集文件因为比较大,已经删除了,按照下文教程下载即可。
2. LeNet
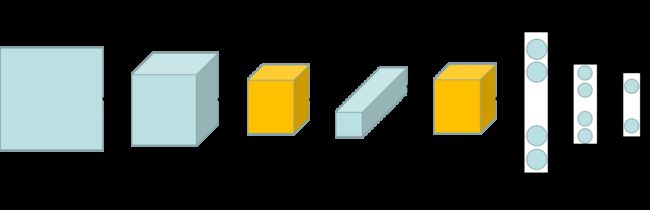
LeNet 可以说是第一个卷积神经网络,LeNet-5。LeNet-5 由Y. LeCun 在 1998 年发表的文章《Gradient-Based Learning Applied to Document Recognition 》中正式提出,应用于数字识别问题。LeNet 包含了卷积网络的基本组件,如下图:可以看到卷积层,池化层,全连接层。
2.1 网络结构

LeNet-5 由 2 个卷积层,2 个池化层(下采样层),3 个全连接层组成。
| 层 | 说明 |
|---|---|
| 输入层(INPUT) | 32 X 32 X 1 的图片(长、宽、色彩) |
| 卷积层(C1) | 输入 32 X 32 X 1,卷积核 5 X 5 X 6,步长(stride)为 1, 输出 28 X 28 X 6 的特征图 |
| 池化层(S2) | 输入 28 X 28 X 6, 过滤器为 2 X 2,输出 14 X 14 X 6 |
| 卷积层(C3) | 输入 14 X 14 X 6,卷积核 5 X 5 X 16,步长(stride)为 1, 输出 10 X 10 X 16 的特征图 |
| 池化层(S4) | 输入 10 X 10 X 16, 过滤器为 2 X 2,输出 5 X 5 X 16 |
| 全连接层(C5) | 输入 5 X 5 X 16,卷积核 5 X 5 X 120,步长(stride)为 1,输出 1 X 1 X 120 的特征图 |
| 全连接层(F6) | 输入 120 个节点,输出 84 个节点 |
| 全连接层(OUTPUT) | 输入 84 个节点,输出 10 个节点 |
模型框图:
3. demo 实现
针对 CIFAR10 数据集,进行图像识别。
整个过程实现流程:

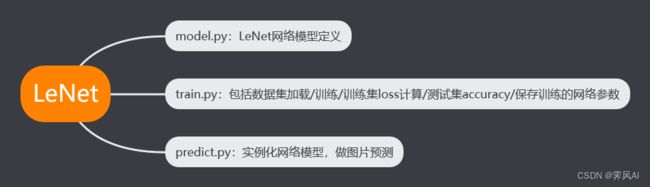
3.1 demo 结构:
demo 包含 model.py ,train.py,predict.py 三个文件。
3.2 model.py
"""
模型
"""
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module): # 集成nn.Module父类
def __init__(self):
super(LeNet, self).__init__()
# 看一下具体的参数
self.conv1 = nn.Conv2d(in_channels=3,
out_channels=16,
kernel_size=5,
stride=1,
padding=0,
bias=True
)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
# self.relu = nn.ReLU(inplace=True)
# 正向传播
def forward(self, x):
x = F.relu(self.conv1(x)) # 输入: (3, 32, 32), 输出: (16, 28, 28)
x = self.pool1(x) # 输出: (16, 14, 14)
x = F.relu(self.conv2(x)) # 输出: (32, 10, 10)
x = self.pool2(x) # 输出: (32, 5, 5)
x = x.view(-1, 32*5*5) # 输出: (32*5*5)
x = F.relu(self.fc1(x)) # 输出: (120)
x = F.relu(self.fc2(x)) # 输出: (84)
x = self.fc3(x) # 输出(10)
return x
"""
调试信息, 查看模型参数传递
"""
# import torch
# input1 = torch.rand([32, 3, 32, 32])
# modelx = LeNet()
# print(modelx)
# output = modelx(input1)
3.2.1 卷积后的图像尺寸
(1)正方形图像:输入大小 W X W,卷积核大小 F X F,步长 S,Padding 为 P,卷积之后输出大小为 N XN ,N 的计算如下:

x = F.relu(self.conv1(x)) # 输入: (3, 32, 32), 输出: (16, 28, 28)
(2)矩形图像:输入大小 H X W,卷积核大小 F X F,步长 S,Padding 为 P,卷积之后输出大小计算如下:

3.2.2 池化后的图像尺寸
输入大小 H X W,卷积核尺寸 F X F,步长 S,池化之后输出大小计算如下:

x = self.pool1(x) # 输入: (16, 28, 28), 输出: (16, 14, 14)
3.2.3 Tensor 展平
经过前面一层处理,数据输出为三维 Tensor (32, 5, 5),使用 view() 方法来展平数据。
x = x.view(-1, 32*5*5) # 输出: (32*5*5)
3.3 train.py
3.3.1 导入包
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import time
3.3.2 数据集预处理
transform = transforms.Compose([
transforms.ToTensor(), # 数据转为张量
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])
将数据转成张量,并做标准化处理。
3.3.3 导入数据集
数据集包括训练集和测试集,设置 download=True,自动从 Pytorch 网站下载数据集。下图为开始下载数据集。
3.3.4 数据集测试
可通过下面的代码,查看数据集图片。
# 定义的分类标签
class_labels = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 查看数据集的图片
def img_show(img):
img = img / 2 + 0.5
np_img = img.numpy()
plt.imshow(np.transpose(np_img, (1, 2, 0)))
plt.show()
# 查看数据集中的5张图像
print(''.join(" %5s " % class_labels[val_label[j]] for j in range(5)))
img_show(torchvision.utils.make_grid(val_image))
因为 Pytorch Tensor 读入数据时,维度参数顺序发生了变化。
Pytorch Tensor 对应 [深度,高度,宽度],而原始数据是[高度,宽度,深度]。故通过下面的代码调整,才能正常显示图片。
plt.imshow(np.transpose(np_img, (1, 2, 0)))
导入数据集:
# 导入训练集数据(50000张图片)
train_set = torchvision.datasets.CIFAR10(root='./data', # root: 数据集存储路径
train=True, # 数据集为训练集
download=False, # download: True时下载数据集(下载完成修改为False)
transform=transform # 数据预处理
)
# 加载训练集
train_loader = torch.utils.data.DataLoader(train_set, # 加载训练集
batch_size=50, # batch 大小
shuffle=True, # 是否随机打乱训练集
num_workers=0 # 使用的线程数量
)
# 导入测试集(10000张图片)
val_set = torchvision.datasets.CIFAR10(root='./data',
train=False, # 数据集为测试集
download=False,
transform=transform
)
# 加载测试集数据
val_loader = torch.utils.data.DataLoader(val_set,
batch_size=10000, # 测试集batch大小
shuffle=False,
num_workers=0
)
# 获取测试集中的图片和标签
val_data_iter = iter(val_loader)
# val_image, val_label = val_data_iter.next()
val_image, val_label = next(val_data_iter) #python 3
3.3.4 训练过程
(1)CPU 训练代码:
net = LeNet() # 用于训练的网络模型
# 指定GPU or CPU 进行训练
net.to("cpu")
loss_function = nn.CrossEntropyLoss() # 损失函数(交叉熵函数)
optimizer = optim.Adam(net.parameters(), lr=0.001) # 优化器(训练参数, 学习率)
# 训练的轮数
for epoch in range(5):
start_time = time.perf_counter()
running_loss = 0.0
# 遍历训练集, 从0开始
for step, data in enumerate(train_loader, start=0):
inputs, labels = data # 得到训练集图片和标签
optimizer.zero_grad() # 清除历史梯度
outputs = net(inputs) # 正向传播
loss = loss_function(outputs, labels) # 损失计算
loss.backward() # 反向传播
optimizer.step() #优化器更新参数
# 用于打印精确率等评估参数
running_loss += loss.item()
if step % 500 == 499: # 500步打印一次
with torch.no_grad():
outputs = net(val_image) # 传入测试集数据
predict_y = torch.max(outputs, dim=1)[1]
accuracy = torch.eq(predict_y, val_label).sum().item() / val_label.size(0)
# 打印训练轮数、精确率等
print("[%d, %5d] train_loss: %.3f test_accuracy: %.3f" %
(epoch + 1 , step + 1, running_loss / 500, accuracy)
)
running_loss = 0.0
end_time = time.perf_counter()
print("cost time = ", end_time - start_time)
print("Finished trainning")
save_path = "./LeNet.pth"
torch.save(net.state_dict(), save_path) # 保存训练输出的模型文件
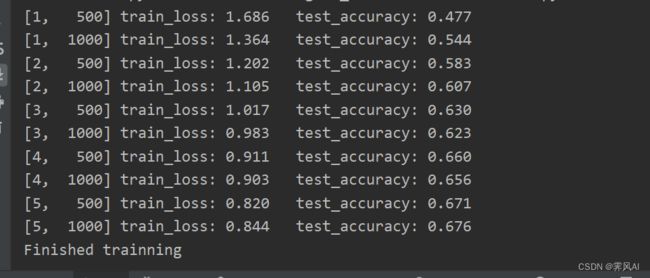
训练打印信息:
 (2)GPU 训练代码:
(2)GPU 训练代码:
需要将训练设备指定为 GPU,且需要修改对应数据和标签。
net = LeNet() # 用于训练的网络模型
# 指定GPU or CPU 进行训练
net.to("cuda")
loss_function = nn.CrossEntropyLoss() # 损失函数(交叉熵函数)
optimizer = optim.Adam(net.parameters(), lr=0.001) # 优化器(训练参数, 学习率)
# 训练的轮数
for epoch in range(2):
running_loss = 0.0
# 遍历训练集, 从0开始
for step, data in enumerate(train_loader, start=0):
inputs, labels = data # 得到训练集图片和标签
optimizer.zero_grad() # 清除历史梯度
outputs = net(inputs.to(device)) # 正向传播
loss = loss_function(outputs, labels.to(device)) # 损失计算
loss.backward() # 反向传播
optimizer.step() #优化器更新参数
# 用于打印精确率等评估参数
running_loss += loss.item()
if step % 500 == 499: # 500步打印一次
with torch.no_grad():
outputs = net(val_image.to(device)) # 传入测试集数据
predict_y = torch.max(outputs, dim=1)[1]
accuracy = torch.eq(predict_y, val_label.to(device)).sum().item() / val_label.size(0)
# 打印训练轮数、精确率等
print("[%d, %5d] train_loss: %.3f test_accuracy: %.3f" %
(epoch + 1 , step + 1, running_loss / 500, accuracy)
)
running_loss = 0.0
print("Finished trainning")
save_path = "./LeNet.pth"
torch.save(net.state_dict(), save_path) # 保存训练输出的模型文件
通过对比可发现,GPU 的速度快于 CPU。
注:
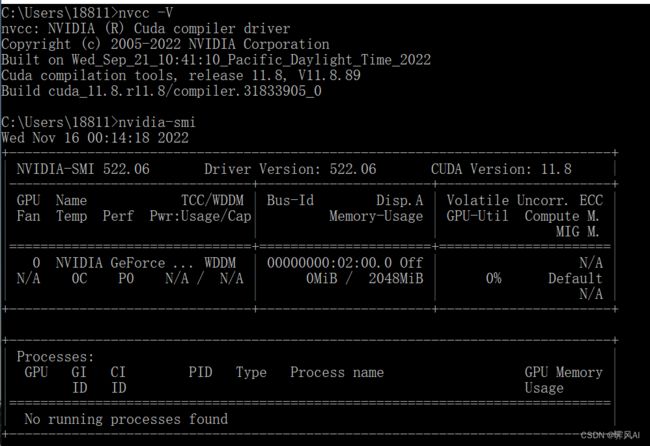
本文采用 pycharm 开发,需要安装对应 CUDA,具体的版本需要查看自己电脑对应的 GPU 型号,然后下载 CUDA 安装。本文的信息如下:
3.4. predict.py
此文件为模型测试代码。
""""
测试
"""
import torch
import torchvision.transforms as transforms
from PIL import Image
from model import LeNet
def main():
transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
data_class = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
net.load_state_dict(torch.load('LeNet.pth'))
# net.load_state_dict(torch.load('LeNet.pth', map_location=torch.device("cpu")))
test_image = Image.open('cat_test2.jpg')
test_image = transform(test_image) # [C H W]
test_image = torch.unsqueeze(test_image, dim=0) # [N C H W]
with torch.no_grad():
outputs = net(test_image)
predict = torch.max(outputs, dim=1)[1].numpy()
print(f"It is {data_class[int(predict)]}")
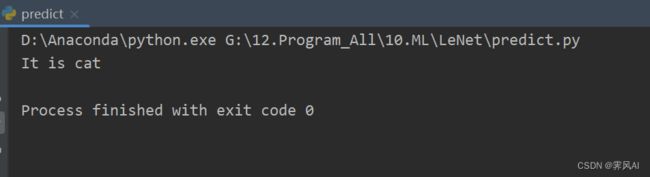
测试图片为:cat_test2.jpg

测试结果:
欢迎关注公众号:【千艺千寻】,共同成长
参考:
- pytorch图像分类篇:2.pytorch官方demo实现一个分类器(LeNet)
- B站——2.1 pytorch官方demo(Lenet)
- Pytorch中nn.Conv1d、Conv2D与BatchNorm1d、BatchNorm2d函数
- pytorch官方demo实现图像分类(LeNet)
- UP主代码——Test1_official_demo
- Pytorch中文
- pytorch中的卷积操作详解
- LeNet 论文地址
- LeNet:第一个卷积神经网络