【数据挖掘】分类与回归预测
OutLine
| 章节 | 概述 |
|---|---|
| 1 | 分类与预测 |
| 2 | 关于分类与预测中存在的问题 |
| 3 | 决策树分类 |
| 4 | 贝叶斯分类 |
| 5 | BP网络分类 |
| 6 | 其他分类算法 |
| 7 | 预测 |
| 8 | 准确性与误差 |
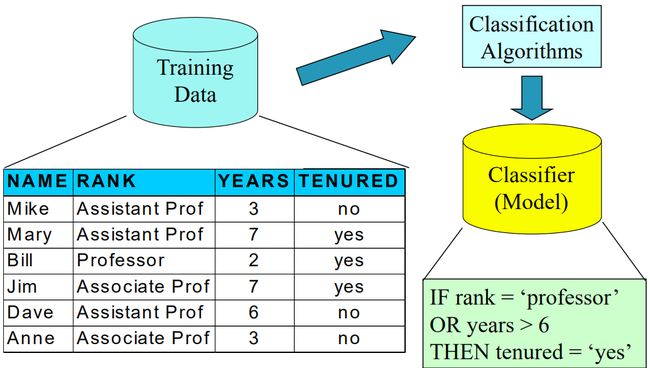
Chapter 1. 分类与预测
分类
- 预测分类标签,可以是离散数据或者是名义数据
- 根据训练集和分类属性中的类标签对记录进行分类,并且用这些规则对新的记录进行分类
整个分类过程包括两步,即模型构建和模型使用:
模型构建
描述一组预先定义好的数据
- 假定每个样本都属于一个事先定义的类,并且由类标签属性(class label attribute)决定
- 用于构建模型的数据是训练集
- 模型用数学语言、决策树、分类规则等进行描述
模型使用
用来对未知对象进行分类或者对未来进行预测
- 评估模型的精度
- 将测试集的已知样本跟预测结果相比较
- 测试集需要独立于训练集,否则会发生过拟合(Over-fitting)
- 若精度可以接受,就用这个模型去预测那些标签未知的数据

过拟合
- 一个假设在训练数据上能够获得比其他假设更好的拟合, 但是在训练数据外的数据集上却不能很好地拟合数据
- 造成这种的原因主要是存在噪声或者训练数据太少
预测
- 通过建模一个连续的函数,对未知或者缺失值进行预测
监督学习
监督学习也就是常说的分类,需要训练集带有标签,新的数据将基于这些训练集给出
无监督学习
也就是聚类,每个样本并没有提前给出类别标签。
Chapter 2. 分类与预测中的问题
准备工作
| Tasks | Description |
|---|---|
| 数据清洗 | 预处理数据,以减少噪声和处理缺失的值 |
| 相关性分析 | 删除不相关或冗余的属性 |
| 数据转换 | 生成或规范化数据 |
评估方法
| Methods | Description |
|---|---|
| 精度 | 分类或预测过程中正确性的度量 |
| 速度 | 训练速度、分类/预测速度 |
| 鲁棒性 | 处理噪声和缺失值的能力 |
| 可扩展性 | 磁盘驻留数据库的效率 |
| 可解释性 | 模型可以提供的理解和洞察力 |
评估分类精度
一般训练集和测试集的比例是64,73,82
或者用k折交叉验证
- 将数据集划分为k个部分
- 随机训练 k − 1 k-1 k−1个部分,剩下的部分作为测试集
- 重复 k k k次
- 对精度取平均值
Chapter 3. 决策树分类
决策树
-
流程图式树形结构
-
内部节点表示对属性进行拆分测试
-
Branch表示测试的结果
-
叶节点表示类分布
其生成过程可以表示为两个阶段,分别是生成和剪枝。
其算法可以表述为:
'''
生成决策树(D,attribute_list)
(1) 创建一个节点N;
(2) 如果D中的元组都是相同的类C,那么直接将N作为一个带有C标签的叶子 节点返回。
(3) 如果属性列是空的,那么
将N作为一个叶子节点返回,其标签为D中的主要类
(4) 使用方法 属性选择(D,attribute_list) 去找到最高的信息增益
(5) 将N标记为测试属性
(6) 对每个测试属性中的值a_i,有:
(7) 从节点N开始,为属性ta_i生长出一个分支
(8) 设s_i为D中的样本集,且属性为a_i
(9) 如果s_i是空的,那么
为N添加一个叶子节点,其标签为D中的主要类
(10) 否则,在N增加一个节点,节点的值为 递归执行 生成决策树(s_i,attribute_list) 后的子树
'''
基本思想
- 贪心算法
- 树的构造采用自顶向下递归分治方法
- 一开始,所有的训练示例都位于根节点
- 属性是分类的(如果是连续值,它们会提前离散化)
- 示例基于所选属性递归分区
- 测试属性的选择基于启发式或统计度量(例如,信息增益,基尼指数)
停止分区的条件
- 给定节点的所有示例都属于同一个类
- 没有用于进一步划分的剩余属性—使用多数投票对叶进行分类
- 没有数据了
信息增益
假设有两个类 P P P和 N N N
-
设集合S包含p个类p的元素和n个类n的元素
-
样品分类所需的信息量为:
-
I ( p , n ) = − p p + n l o g 2 p p + n − n p + n l o g 2 n p + n I(p,n)=-\frac{p}{p+n}log_2\frac{p}{p+n}-\frac{n}{p+n}log_2\frac{n}{p+n} I(p,n)=−p+nplog2p+np−p+nnlog2p+nn
其中,信息熵的计算公式为:
E n t r o p y = − ∑ p l o g 2 p Entropy=-\sum plog_2p Entropy=−∑plog2p
假设属性A具有v个不同的值,那么训练集将会被划分为v个不同的区间,此时我们若是用A作为划分标准,那么可以得到:
E ( A ) = ∑ i v p i + n i p + n I ( p i , n i ) E(A)=\sum_i^v\frac{p_i+n_i}{p+n}I(p_i,n_i) E(A)=i∑vp+npi+niI(pi,ni)
其信息增益为:
G a i n ( A ) = I ( p , n ) − E ( A ) Gain(A)=I(p,n)-E(A) Gain(A)=I(p,n)−E(A)
简单来说,就是:
如果一个属性 A A A有 n n n个唯一值,那么按照该属性生成的决策树也应该有 n n n个分支,这 n n n个分支每一个分支都有自己的信息量(也就是发生分类的信息量之和),也有发生该分支的概率,将信息量乘以分支发生概率(权重)后相加,就是属性 A A A对分类 C C C的信息熵了。
举个栗子:
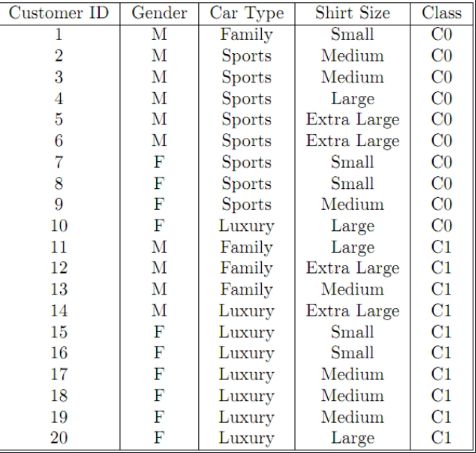
a) Compute the Information Gain for Gender, Car Type and Shirt Size. (15 points)
b) Construct a decision tree with Information Gain. (10 points)
Answer A
整体熵
| C0 | C1 |
|---|---|
| 10 | 20 |
根据公式
E ( s ) = − ∑ i n p l o g 2 ( p ) E(s)=-\sum_i^nplog_2(p) E(s)=−i∑nplog2(p)
有:
E ( s ) = − 10 20 l o g 2 ( 10 20 ) − 10 20 l o g 2 ( 10 20 ) = 1 E(s)=-\frac{10}{20}log_2(\frac{10}{20})-\frac{10}{20}log_2(\frac{10}{20}) \\ =1 E(s)=−2010log2(2010)−2010log2(2010)=1
下面我们计算各个属性列的信息增益
Gender属性列:
| C0 | C1 | |
|---|---|---|
| F | 6 | 4 |
| M | 6 | 4 |
E ( F ) = − ( 6 10 ) l o g 2 ( 6 10 ) − ( 4 10 ) l o g 2 ( 4 10 ) = 0.97095 E(F)=-(\frac{6}{10})log_2(\frac{6}{10})-(\frac{4}{10})log_2(\frac{4}{10}) \\=0.97095 E(F)=−(106)log2(106)−(104)log2(104)=0.97095
E ( M ) = − ( 6 10 ) l o g 2 ( 6 10 ) − ( 4 10 ) l o g 2 ( 4 10 ) = 0.97095 E(M)=-(\frac{6}{10})log_2(\frac{6}{10})-(\frac{4}{10})log_2(\frac{4}{10}) \\=0.97095 E(M)=−(106)log2(106)−(104)log2(104)=0.97095
根据信息增益公式:
g ( D , A ) = E ( D ) − E ( D ∣ A ) g(D,A)=E(D)-E(D|A) g(D,A)=E(D)−E(D∣A)
可得到:
G a i n ( G e n d e r ) = E ( s ) − 10 20 ∗ E ( F ) − 10 20 ∗ E ( M ) = 0.029 Gain(Gender)=E(s)-\frac{10}{20}*E(F)-\frac{10}{20}*E(M) \\ =0.029 Gain(Gender)=E(s)−2010∗E(F)−2010∗E(M)=0.029
同理,CarType属性列
| C0 | C1 | |
|---|---|---|
| F | 1 | 3 |
| L | 1 | 7 |
| S | 8 | 0 |
E ( F ) = − ( 1 4 ) l o g 2 ( 1 4 ) − ( 3 4 ) l o g 2 ( 3 4 ) = 0.81127 E(F)=-(\frac{1}{4})log_2(\frac{1}{4})-(\frac{3}{4})log_2(\frac{3}{4})\\=0.81127 E(F)=−(41)log2(41)−(43)log2(43)=0.81127
E ( L ) = − ( 1 8 ) l o g 2 ( 1 8 ) − ( 7 8 ) l o g 2 ( 7 8 ) = 0.543564 E(L)=-(\frac{1}{8})log_2(\frac{1}{8})-(\frac{7}{8})log_2(\frac{7}{8})\\=0.543564 E(L)=−(81)log2(81)−(87)log2(87)=0.543564
E ( S ) = − ( 1 ) l o g 2 ( 1 ) = 0 E(S)=-(1)log_2(1)=0 E(S)=−(1)log2(1)=0
最终结果为
G a i n ( C a r T y p e ) = E ( s ) − p ( F ) E ( F ) − p ( L ) E ( L ) − p ( S ) E ( S ) = 1 − 4 20 ∗ E ( F ) − 8 20 ∗ E ( L ) − 8 20 ∗ E ( S ) = 0.6205 Gain(CarType)=E(s)-p(F)E(F)-p(L)E(L)-p(S)E(S)\\=1-\frac{4}{20}*E(F)-\frac{8}{20}*E(L)-\frac{8}{20}*E(S)\\=0.6205 Gain(CarType)=E(s)−p(F)E(F)−p(L)E(L)−p(S)E(S)=1−204∗E(F)−208∗E(L)−208∗E(S)=0.6205
对于Shirt Size属性列
| C0 | C1 | |
|---|---|---|
| E | 2 | 2 |
| L | 2 | 2 |
| M | 3 | 4 |
| S | 3 | 2 |
E ( E ) = − ( 2 4 ) l o g 2 ( 2 4 ) − ( 2 4 ) l o g 2 ( 2 4 ) = 1 E(E)=-(\frac{2}{4})log_2(\frac{2}{4})-(\frac{2}{4})log_2(\frac{2}{4})\\=1 E(E)=−(42)log2(42)−(42)log2(42)=1
E ( L ) = − ( 2 4 ) l o g 2 ( 2 4 ) − ( 2 4 ) l o g 2 ( 2 4 ) = 1 E(L)=-(\frac{2}{4})log_2(\frac{2}{4})-(\frac{2}{4})log_2(\frac{2}{4})\\=1 E(L)=−(42)log2(42)−(42)log2(42)=1
E ( M ) = − ( 3 7 ) l o g 2 ( 3 7 ) − ( 4 7 ) l o g 2 ( 4 7 ) = 0.985228 E(M)=-(\frac{3}{7})log_2(\frac{3}{7})-(\frac{4}{7})log_2(\frac{4}{7})\\=0.985228 E(M)=−(73)log2(73)−(74)log2(74)=0.985228
E ( S ) = − ( 3 5 ) l o g 2 ( 3 5 ) − ( 2 5 ) l o g 2 ( 2 5 ) = 0.97095 E(S)=-(\frac{3}{5})log_2(\frac{3}{5})-(\frac{2}{5})log_2(\frac{2}{5})\\=0.97095 E(S)=−(53)log2(53)−(52)log2(52)=0.97095
最终结果为:
G a i n ( C a r T y p e ) = E ( s ) − p ( E ) E ( E ) − p ( L ) E ( L ) − p ( S ) E ( S ) − p ( M ) E ( M ) = 1 − 4 20 ∗ E ( E ) − 4 20 ∗ E ( L ) − 5 20 ∗ E ( S ) − 7 20 E ( M ) = 0.012432 Gain(CarType)=E(s)-p(E)E(E)-p(L)E(L)-p(S)E(S)-p(M)E(M)\\=1-\frac{4}{20}*E(E)-\frac{4}{20}*E(L)-\frac{5}{20}*E(S)-\frac{7}{20}E(M)\\=0.012432 Gain(CarType)=E(s)−p(E)E(E)−p(L)E(L)−p(S)E(S)−p(M)E(M)=1−204∗E(E)−204∗E(L)−205∗E(S)−207E(M)=0.012432
| Val | |
|---|---|
| Gain(Gender) | 0.029 |
| Gain(CarType) | 0.621 |
| Gain(ShirtSize) | 0.012 |
Answer B
通过计算结果可知,CarType属性对Class属性的信息增益率最大,因而决策树的第一个节点可以选择CarType。
而此时CarType有三个分支,分别是
| Entropy | |
|---|---|
| Family | 0.81 |
| Luxury | 0.54 |
| Sports | 0 |
我们通过这三个分支划分数据,值得注意的是,Sports分支没必要再分了
所以第一个分裂节点为:
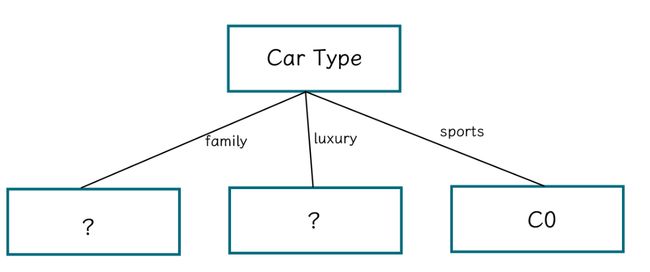
我们进行第二次迭代,用family划分的数据集为:

用Luxury划分的数据集为:

迭代计算信息增益,family的信息增益为:
E ( f ) = 0.81127 E(f)=0.81127 E(f)=0.81127
用Gender划分后的信息增益:
E ( G ) = − 1 4 l o g 2 1 4 − 3 4 l o g 2 3 4 = 0.811278 E(G)=-\frac{1}{4}log_2{\frac{1}{4}}-\frac{3}{4}log_2{\frac{3}{4}}\\ =0.811278 E(G)=−41log241−43log243=0.811278
用ShirtSize划分后:
E ( S ) = 1 4 [ 0 + 0 + 0 + 0 ] = 0 E(S)=\frac{1}{4}[0+0+0+0]=0 E(S)=41[0+0+0+0]=0
| Gain | |
|---|---|
| Gender | 0 |
| ShirtSize | 0.81127 |
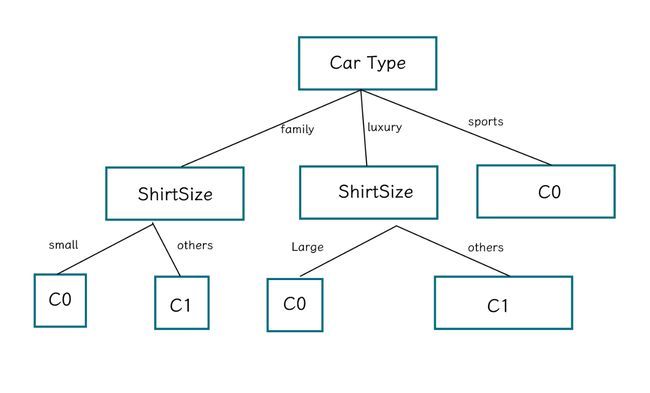
我们选择ShirtSize进一步划分。此时,Gender已经不能提供任何的信息了,可以直接完成叶子结点的工作。

再来看luxury划分的数据集,
| C0 | C1 | |
|---|---|---|
| F | 1 | 6 |
| M | 0 | 1 |
G ( G e n d e r ) = E ( l u x u r y ) − ( 0 − 7 8 ( 1 7 l o g 2 1 7 − 6 7 l o g 2 6 7 ) ) = 0.022 G(Gender)=E(luxury)-(0-\frac{7}{8}(\frac{1}{7}log_2{\frac{1}{7}}-\frac{6}{7}log_2\frac{6}{7}))\\ =0.022 G(Gender)=E(luxury)−(0−87(71log271−76log276))=0.022
| C0 | C1 | |
|---|---|---|
| E | 0 | 1 |
| L | 1 | 1 |
| M | 0 | 3 |
| S | 0 | 2 |
G ( S h i r t S i z e ) = 0.515 G(ShirtSize)=0.515 G(ShirtSize)=0.515
所以我们用ShirtSize进行划分。

再往后的节点为:

此时,该节点已经没办法带来任何的信息收益了,我们可以考虑将其进行剪枝,那最终的一个决策树结果为
信息增益比
信息增益是ID3决策树使用的分裂算法,而信息增益比则是C4.5决策树所选择的分裂算法。
信息增益会偏向选择更多值的数据,为了处理这一问题,C4.5采用了信息增益比来替代。
其计算公式为:
G a i n R a t i o ( A ) = G a i n ( A ) S p l i t I n f o ( A ) GainRatio(A)=\frac{Gain(A)}{SplitInfo(A)} GainRatio(A)=SplitInfo(A)Gain(A)
而
S p l i t I n f o ( A ) = − ∑ j i ∣ D j ∣ D l o g 2 ∣ D j ∣ D SplitInfo(A)=-\sum_j^i\frac{|D_j|}{D}log_2\frac{|D_j|}{D} SplitInfo(A)=−j∑iD∣Dj∣log2D∣Dj∣
这个就是将特征 A A A当做类别计算熵了,说白了就是惩罚系数,特征个数越多,惩罚系数越大,特征个数越小,惩罚系数越小。
Gini 指数
基尼指数的定义为:
如果一个数据集 T T T包含了 n n n个类,那么基尼指数可以定义为:
g i n i ( T ) = 1 − ∑ j n p j 2 gini(T)=1-\sum_j^np^2_j gini(T)=1−j∑npj2
其中 p j p_j pj是类 j j j的相对频率
同样,如果将数据集拆分,拆分的基尼指数可以写成
g i n i s p l i t ( T ) = 1 N ∑ N i g i n i ( T i ) gini_{split}(T)=\frac{1}{N}\sum N_igini(T_i) ginisplit(T)=N1∑Nigini(Ti)
该属性提供了选择最小的基尼指数来拆分节点(需要为每个属性枚举所有可能的拆分点)
如何表述决策树的规则?

采用IF + AND + THEN的模式
过拟合
诱导树可能会对训练数据进行过拟合
- 分支过多,有些可能反映为噪声或异常值引起的异常
- 对未知(其他)的样本准确率差
防止过拟合
预剪枝
- 尽早停止树的构造——如果这将导致优度度量低于阈值,则不要拆分节点
- 但是很难确定阈值
后剪枝
- 从一棵“完全生长”的树上移除树枝,得到一系列逐步修剪的树
•使用一组不同于训练数据的数据来决定哪棵树是“最好的修剪树”
关于决策树算法的评价
- 相对较快的学习速度
- 可转换为简单易懂的分类规则
- 可扩展到大型数据库
- 与其他方法相比可接受的精度
对基本决策树算法的增强
- 允许连续值的属性
- 动态定义新的离散值属性,将连续属性值划分为一组离散的区间
- 处理缺失的属性值
- 分配属性的最常用值
- 属性构造
- 基于现有属性创建新属性
Chapter 4. 贝叶斯分类
贝叶斯分类是一类分类算法的总称,这类算法均已贝叶斯定理为基础,采用了概率推理的方法。
算法原理
假设 P ( h ) P(h) P(h)表示在没有训练数据前提下假设 h h h的初始概率,也称为先验概率; P ( D ) P(D) P(D)表示将要观测的训练数据 D D D的先验概率, P ( D ∣ h ) P(D|h) P(D∣h)表示假设 h h h成立下数据 D D D的概率。
于是,我们可以通过贝叶斯定理,计算假设 h h h的后验概率:
p ( h ∣ D ) = p ( D ∣ h ) P ( h ) P ( D ) p(h|D)=\frac{p(D|h)P(h)}{P(D)} p(h∣D)=P(D)p(D∣h)P(h)
其中,数据 D D D称为某目标函数的训练样本, h h h称为候选目标函数空间。
朴素贝叶斯
给定一个分类标签 y y y和自由特征变量 x 1 , x 2 , . . . , x n , x i = 1 x_1,x_2,...,x_n,x_i=1 x1,x2,...,xn,xi=1表示样本具有特征 i i i, x i = 0 x_i=0 xi=0表示样本不具有特征 i i i,如果要知道具有特征 1 n 1~n 1 n的向量是否属于分类标签 y k y_k yk,可以利用贝叶斯公式:
P ( y k ∣ x 1 , . . . x n ) = P ( y k ) P ( x 1 , . . . , x n ∣ y k ) P ( x 1 , . . . , x n ) P(y_k|x_1,...x_n)=\frac{P(y_k)P(x_1,...,x_n|y_k)}{P(x_1,...,x_n)} P(yk∣x1,...xn)=P(x1,...,xn)P(yk)P(x1,...,xn∣yk)
假设某一属性值在给定类上的影响独立于其他属性的值,这一假定称为类条件独立性。做词假设是为了简化计算,并称其为“朴素的"(naive)
此时有:
P ( x 1 , . . . x n ∣ y k ) = ∏ i n P ( x i ∣ y k ) P(x_1,...x_n|y_k)=\prod_i^nP(x_i|y_k) P(x1,...xn∣yk)=i∏nP(xi∣yk)
说人话就是,假定每个向量分量都是相互独立的,所以可以直接用他们在属于 y k y_k yk的概率下发生的概率的乘积作为条件概率。
我们从样本中是可以知道 P ( x 1 , . . . , x n ) P(x_1,...,x_n) P(x1,...,xn)的,此时,比较 P ( y 1 ∣ x 1 , . . . x n ) P(y_1|x_1,...x_n) P(y1∣x1,...xn)与 P ( y 2 ∣ x 1 , . . . x n ) P(y_2|x_1,...x_n) P(y2∣x1,...xn)等价于比较 P ( y 1 ) P ( x 1 , . . . x n ∣ y 1 ) P(y_1)P(x_1,...x_n|y_1) P(y1)P(x1,...xn∣y1)和 P ( y 2 ) P ( x 1 , . . . x n ∣ y 2 ) P(y_2)P(x_1,...x_n|y_2) P(y2)P(x1,...xn∣y2)
假设有 m m m种标签,我们取最大值就ok了。
y ^ = a r g k m a x P ( y ) ∏ P ( x i ∣ y ) k \hat y=arg_kmax P(y)\prod P(x_i|y)k y^=argkmaxP(y)∏P(xi∣y)k
原始的朴素贝叶斯只能处理离散,我们可以用高斯朴素贝叶斯完成连续任务的分类。
此时我们的假设变成了:每个类的连续变量服从高斯分布,算法更新为:
P ( x i = v ∣ y k ) = 1 2 π σ y k 2 e x p ( − ( v − μ y k ) 2 2 σ y k 2 ) P(x_i=v|y_k)=\frac{1}{\sqrt{2\pi\sigma^2_{yk}}}exp(-\frac{(v-\mu_{yk})^2}{2\sigma^2_{yk}}) P(xi=v∣yk)=2πσyk21exp(−2σyk2(v−μyk)2)
至于为啥能用贝叶斯这样去推呢?
是因为我们的先验概率 P ( A ) P(A) P(A)是可以从统计样本中得到的,再加上独立性假设,每一类的先验概率都是可以通过统计样本得到的,最后做个连乘就行了。
执果索因
优点
-
易于实现
-
在大多数情况下获得了良好的结果
缺点
-
假设:类条件独立,因此失去准确性
-
实际上,变量之间确实存在依赖关系
-
这些之间的依赖关系不能通过Naïve建模
如何处理这些依赖关系?
- 贝叶斯网络BNN
Chapter 5. BP神经网络
好玩的来了。
后向传播神经网络
一、原理
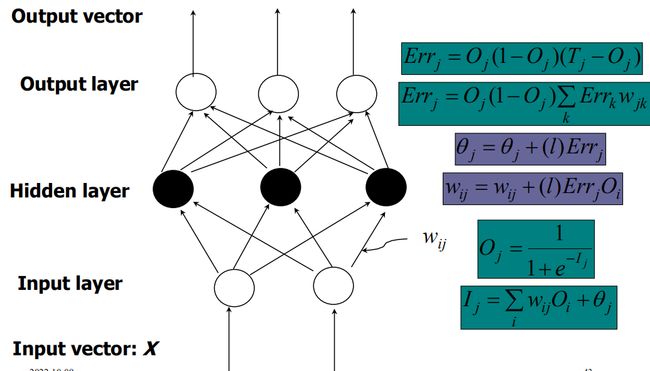
BP(Back Propagation)算法是通过将网络预测值与实际值做对比,不断修改权重从而尽量将他们之间的均方根误差降低到最小的算法。该算法由最后的节点向前不断传递信息,所以被称为后向传播算法。BP算法具有简单易行、计算量小和并行性强等优点,其实质是求解误差函数最小值的问题,但由于梯度下降本身的缺点,容易陷入局部最小值,且根据学习率,有可能会导致收敛速度慢,学习效率低等缺点。
整个BPNN可以划分为两个阶段:
第一阶段:前向传播阶段
这一阶段,节点之间通过权重边相互映射到新的节点中,第 i i i层的节点信息由第 i − 1 i-1 i−1层映射得到,满足以下公式:
I i = ∑ i = 1 n w i j O j + θ i I_i=\sum_{i=1}^nw_{ij}O_j+\theta_i Ii=i=1∑nwijOj+θi
其中, O j O_j Oj表示上一层节点的输出信息, w i j w_{ij} wij表示节点 j j j和节点 i i i的权重边, θ i \theta_i θi表示偏置量(Bias)。
我们通过添加一个激活函数,将原先的线性映射变为非线性映射,例如使用Sigmoid函数:
O i = 1 1 + e − I i O_i=\frac{1}{1+e^{-I_i}} Oi=1+e−Ii1
第二阶段:反向传播
BP算法基于梯度下降,每次对参数的迭代都是梯度最快下降的方向,其误差值的评估为:
E = 1 2 ∑ j = 1 l ( y ^ j k − y j k ) 2 E=\frac{1}{2}\sum_{j=1}^l(\hat y_j^k-y_j^k)^2 E=21j=1∑l(y^jk−yjk)2
前面的0.5是为了化简求导,常数项影响不大。
对于某一权重参数 w h j w_{hj} whj,给定一个学习率 σ \sigma σ,其变化率为对误差值(也称作损失函数)的求导:
△ w h j = δ E δ w h j \triangle w_{hj}=\frac{\delta E}{\delta w_{hj}} △whj=δwhjδE
根据梯度下降算法,他的变化值应该是其梯度的反方向。再加上学习率做平滑,所以最后的更新量为:
△ w h j = − σ δ E δ w h j \triangle w_{hj}=-\sigma\frac{\delta E}{\delta w_{hj}} △whj=−σδwhjδE
注意Sigmoid函数的求导结果为:
O ′ = O ( 1 − O ) O'=O(1-O) O′=O(1−O)
这里不给出具体求导步骤,感兴趣的朋友可以自己试着推一推。
于是,根据链式求导规则,在输出层单元 j j j,误差 E r r Err Err的计算表达为:
E r r j = O j ( 1 − O j ) ( T j − O j ) Err_j=O_j(1-O_j)(T_j-O_j) Errj=Oj(1−Oj)(Tj−Oj)
T j T_j Tj表示在这个单元上的真实结果。
根据BP原理,对于单元 j j j的误差,来源于与他相关的 n n n个隐含层单元映射,而对于某个隐含层映射 i i i,也有可能对 k k k个输出层节点产生影响(多对多关系),所以在隐层的更新中,需要考虑所有从输出层传播回来的信息。
对于隐层节点 i i i,有:
E r r i = O i ( 1 − O i ) ∗ ∑ j = 1 k w i j E r r j Err_i=O_i(1-O_i)*\sum_{j=1}^kw_{ij}Err_j Erri=Oi(1−Oi)∗j=1∑kwijErrj
了解完误差传播的规则之后,我们就需要对参数进行更新啦!
那么每一层权重的更新可以表示为:
△ w i j = σ E r r j O i w i j = w i j + △ w i j \triangle w_{ij}=\sigma Err_jO_i\\ w_{ij}=w_{ij}+\triangle w_{ij} △wij=σErrjOiwij=wij+△wij
偏置的更新可以表示为:
△ θ j = σ E r r j θ j = θ j + σ △ θ j \triangle \theta_{j}=\sigma Err_j\\ \theta_{j}=\theta_{j}+\sigma \triangle \theta_{j}\\ △θj=σErrjθj=θj+σ△θj
BP算法迭代停止条件为:
- 前一周期所有的权重变化率都小于给定阈值
- 前一周期误差百分比小于给定阈值
- 超出给定的迭代周期数
二、案例
给定一个前馈神经网络如下,共有九个输入节点,可以看做九个特征维度,两个隐层节点和一个输出层节点。
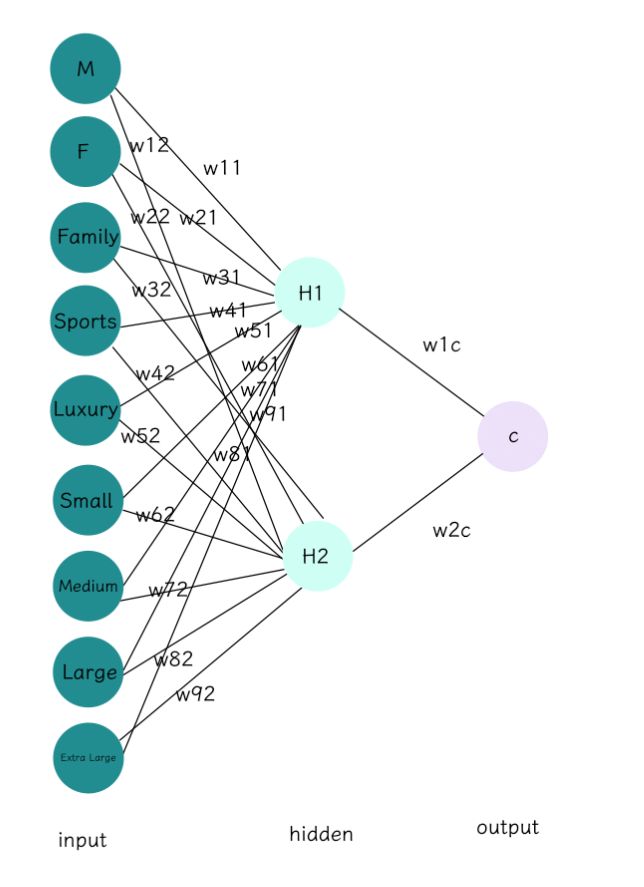
首先第一步,我们需要给定权重的初始值和学习率:
隐层
| w11 | w21 | w31 | w41 | w51 | w61 | w71 | w81 | w91 |
|---|---|---|---|---|---|---|---|---|
| 0.1 | 0.2 | 0.3 | -0.4 | -0.1 | -0.2 | -0.3 | 0.4 | 0.5 |
| w12 | w22 | w32 | w42 | w52 | w62 | w72 | w82 | w92 |
| 0.2 | 0.4 | 0.1 | -0.2 | -0.4 | 0.3 | 0.2 | 0.4 | -0.2 |
输出层
| w1c | w2c |
|---|---|
| 0.7 | 0.5 |
输入初始值为
1,0,1,0,0,1,0,0,0
学习率
lr=0.01
偏置
| θ h 1 \theta_{h1} θh1 | -0.1 |
|---|---|
| θ h 2 \theta_{h2} θh2 | 0.2 |
| θ c \theta_{c} θc | 0.1 |
对于每个节点,净输入值表示为:
I = θ + ∑ i = 1 n w i v i I=\theta+\sum_{i=1}^nw_iv_i I=θ+i=1∑nwivi
其中, θ \theta θ 表示偏置量, w i w_i wi表示分支权重, v i v_i vi表示节点值。
输出值表示为:
O = 1 1 + e − I O=\frac{1}{1+e^{-I}} O=1+e−I1
输出结果
| 单元 | 净输入 | 输出 |
|---|---|---|
| H1 | − 0.1 + 0.1 ∗ 1 + 0.3 ∗ 1 − 0.2 ∗ 1 = 0.1 -0.1+0.1*1+0.3*1-0.2*1=0.1 −0.1+0.1∗1+0.3∗1−0.2∗1=0.1 | 1 1 + e − 0.1 = 0.525 \frac{1}{1+e^{-0.1}}=0.525 1+e−0.11=0.525 |
| H2 | 0.2 + 0.2 ∗ 1 + 0.1 ∗ 1 + 0.3 ∗ 1 = 0.8 0.2+0.2*1+0.1*1+0.3*1=0.8 0.2+0.2∗1+0.1∗1+0.3∗1=0.8 | 1 1 + e − 0.8 = 0.690 \frac{1}{1+e^{-0.8}}=0.690 1+e−0.81=0.690 |
| C | 0.1 + 0.7 ∗ 0.55 + 0.5 ∗ 0.65 = 0.81 0.1+0.7*0.55+0.5*0.65=0.81 0.1+0.7∗0.55+0.5∗0.65=0.81 | 1 1 + e − 0.81 = 0.692 \frac{1}{1+e^{-0.81}}=0.692 1+e−0.811=0.692 |
输出层的误差值计算为
E r r = O ∗ ( 1 − O ) ∗ ( T − O ) Err=O*(1-O)*(T-O) Err=O∗(1−O)∗(T−O)
其中, O O O表示节点输出, T T T表示真实值
隐层节点的误差计算为:
E r r = O ∗ ( 1 − O ) ∗ ∑ i = 1 n E r r i ∗ w i Err=O*(1-O)*\sum_{i=1}^nErr_i*w_i Err=O∗(1−O)∗i=1∑nErri∗wi
其中, E r r Err Err表示从高层传过来的误差。
计算每个节点的误差
| 单元 | 误差 |
|---|---|
| C | 0.692 ∗ ( 1 − 0.692 ) ∗ ( 1 − 0.692 ) = 0.066 0.692*(1-0.692)*(1-0.692)=0.066 0.692∗(1−0.692)∗(1−0.692)=0.066 |
| H1 | 0.525 ∗ ( 1 − 0.525 ) ∗ 0.066 ∗ 0.7 = 0.012 0.525*(1-0.525)*0.066*0.7=0.012 0.525∗(1−0.525)∗0.066∗0.7=0.012 |
| H2 | 0.69 ∗ ( 1 − 0.69 ) ∗ 0.066 ∗ 0.5 = 0.007 0.69*(1-0.69)*0.066*0.5=0.007 0.69∗(1−0.69)∗0.066∗0.5=0.007 |
偏置量的更新方程表示为:
θ n e w = θ o l d + l r ∗ ( E r r ) \theta_{new}=\theta_{old}+lr*(Err) θnew=θold+lr∗(Err)
权重的更新方程表示为:
w n e w = w o l d + l r ∗ E r r ∗ O w_{new}=w_{old}+lr*Err*O wnew=wold+lr∗Err∗O
更新权重和偏置
这里只给出了链式求导用到的节点和权重
| w 1 c w_{1c} w1c | 0.7 + 0.01 ∗ ( 0.066 ∗ 0.525 ) = 0.7003465 0.7+0.01*(0.066*0.525)=0.7003465 0.7+0.01∗(0.066∗0.525)=0.7003465 |
|---|---|
| w 2 c w_{2c} w2c | 0.5 + 0.01 ∗ ( 0.066 ∗ 0.69 ) = 0.5004554 0.5+0.01*(0.066*0.69)=0.5004554 0.5+0.01∗(0.066∗0.69)=0.5004554 |
| w 11 w_{11} w11 | 0.1 + 0.01 ∗ ( 0.012 ) ∗ 1 = 0.10012 0.1+0.01*(0.012)*1=0.10012 0.1+0.01∗(0.012)∗1=0.10012 |
| w 12 w_{12} w12 | 0.2 + 0.01 ∗ ( 0.007 ) ∗ 1 = 0.20007 0.2+0.01*(0.007)*1=0.20007 0.2+0.01∗(0.007)∗1=0.20007 |
| w 31 w_{31} w31 | 0.3 + 0.01 ∗ ( 0.012 ) ∗ 1 = 0.30012 0.3+0.01*(0.012)*1=0.30012 0.3+0.01∗(0.012)∗1=0.30012 |
| w 32 w_{32} w32 | 0.1 + 0.01 ∗ ( 0.007 ) ∗ 1 = 0.1007 0.1+0.01*(0.007)*1=0.1007 0.1+0.01∗(0.007)∗1=0.1007 |
| w 61 w_{61} w61 | − 0.2 + 0.01 ∗ ( 0.012 ) ∗ 1 = − 0.19988 -0.2+0.01*(0.012)*1=-0.19988 −0.2+0.01∗(0.012)∗1=−0.19988 |
| w 62 w_{62} w62 | 0.3 + 0.01 ∗ ( 0.007 ) ∗ 1 = 0.3007 0.3+0.01*(0.007)*1=0.3007 0.3+0.01∗(0.007)∗1=0.3007 |
| θ c \theta_{c} θc | 0.1 + 0.01 ∗ ( 0.066 ) = 0.10066 0.1+0.01*(0.066)=0.10066 0.1+0.01∗(0.066)=0.10066 |
| θ h 1 \theta_{h1} θh1 | − 0.1 + 0.01 ∗ ( 0.012 ) = − 0.09988 -0.1+0.01*(0.012)=-0.09988 −0.1+0.01∗(0.012)=−0.09988 |
| θ 42 \theta_{42} θ42 | 0.2 + 0.01 ∗ ( 0.007 ) = 0.20007 0.2+0.01*(0.007)=0.20007 0.2+0.01∗(0.007)=0.20007 |
三、代码实现
1️⃣ 导入需要的库,以及我们需要用的函数
import math
import random
# step 1. 构建常用函数
# 激活函数
def sigmoid(x):
return math.tanh(x)
def ReLU(x):
return x if x>0 else 0
def derived_sigmiod(x):
# (O)(1-O)(T-O)
return x-x**2
# 生成随机数
def getRandom(a,b):
return (b-a)*random.random()+a
# 生成一个矩阵
def makeMatrix(m,n,val=0.0):
# 默认以0填充这个m*n的矩阵
return [[val]*n for _ in range(m)]
2️⃣ 初始化参数
这个阶段我们需要做的工作有:
- 初始化节点个数
- 创建权重矩阵并给定初始值
- 保存各种参数量
- 创建数据容器保存各层输出结果
- 也可以设置动量参数
# step 2. 初始化参数
# 这部分主要有:节点个数、隐层个数、输出层个数
# 可以类似于torch.nn.Linear
class BPNN:
def __init__(self,n_in,n_out,n_hidden=10,lr=0.1,m=0.1):
self.n_in=n_in+1 # 加一个偏置节点
self.n_hidden=n_hidden+1 # 加一个偏置节点
self.n_out=n_out
self.lr=lr
self.m=m
# 生成链接权重
# 这里用的是全连接,所以对应的映射就是 [节点个数A,节点个数B]
self.weight_hidden=makeMatrix(self.n_in,self.n_hidden)
self.weight_out=makeMatrix(self.n_hidden,self.n_out)
# 对权重进行初始化
for i,row in enumerate(self.weight_hidden):
for j,val in enumerate(row):
self.weight_hidden[i][j]=getRandom(-0.2,0.2)
for i,row in enumerate(self.weight_out):
for j,val in enumerate(row):
self.weight_out[i][j]=getRandom(-0.2,0.2)
# 存储数据的矩阵
self.in_matrix=[1.0]*self.n_in
self.hidden_matrix=[1.0]*self.n_hidden
self.out_matrix=[1.0]*self.n_out
# 设置动量矩阵
# 保存上一次梯度下降方向
self.ci=makeMatrix(self.n_in,self.n_hidden)
self.co=makeMatrix(self.n_hidden,self.n_out)
3️⃣ 正向传播
这个阶段,我们要做的有:
- 将输入数据保存到数据容器中
- 开始根据正向传播规则传播数据
# step 3. 正向传播
# 根据传播规则对节点值进行更新
def update(self,inputs):
if len(inputs)!=self.n_in-1:
raise ValueError("Your data length is %d, but our input needs %d"%(len(inputs),self.n_in-1))
# 设置初始值
self.in_matrix[:-1]=inputs
# 注意我们最后一个节点依旧是1,表示偏置节点
# 隐层
for i in range(self.n_hidden-1):
accumulate=0
for j in range(self.n_in-1):
accumulate+=self.in_matrix[j]*self.weight_hidden[j][i]
self.hidden_matrix[i]=sigmoid(accumulate)
# 输出层
for i in range(self.n_out):
accumulate = 0
for j in range(self.n_hidden - 1):
accumulate += self.hidden_matrix[j] * self.weight_out[j][i]
self.out_matrix[i] = sigmoid(accumulate)
return self.out_matrix[:] # 返回一个副本
4️⃣ 反向传播
这一阶段,我们要做的工作有:
- 反向计算误差
- 反向更新参数量
# step 4. 误差反向传播
def backpropagate(self,target):
if len(target) != self.n_out :
raise ValueError("Your data length is %d, but our input needs %d" % (len(target), self.n_out))
# 计算输出层的误差
# 根据公式: Err=O(1-O)(T-O)=(O-O**2)(True-O)
out_err=[derived_sigmiod(o:=self.out_matrix[i])*(t-o) for i,t in enumerate(target)]
# 计算隐层的误差
# 根据公式:Err=(O-O**2)Sum(Err*W)
hidden_err=[0.0]*self.n_hidden
for i in range(self.n_hidden):
err_tot=0.0
for j in range(self.n_out):
err_tot+=out_err[j]*self.weight_out[i][j]
hidden_err[i]=derived_sigmiod(self.hidden_matrix[i])*err_tot
# 更新权重
# 输出层:
# w=bias+lr*O*Err+m*(w(n-1))
# m表示动量因子,w(n-1)是上一次的梯度下降方向
for i in range(self.n_hidden):
for j in range(self.n_out):
# 更新变化量 change=O*Err
change=self.hidden_matrix[i]*out_err[j]
self.weight_out[i][j]+=self.lr*change+self.m*self.co[i][j]
# 更新上一次的梯度
self.co[i][j]=change
# 隐含层
for i in range(self.n_in):
for j in range(self.n_hidden):
change=hidden_err[j]*self.in_matrix[i]
self.weight_hidden[i][j]+=self.lr*change+self.m*self.ci[i][j]
self.ci[i][j]=change
# 计算总误差
err=0.0
for i,v in enumerate(target):
err+=(v-self.out_matrix[i])**2
err/=len(target)
return math.sqrt(err)
总的代码为:
import math
import random
def sigmoid(x):
return math.tanh(x)
def ReLU(x):
return x if x>0 else 0
def derived_sigmiod(x):
return x-x**2
def getRandom(a,b):
return (b-a)*random.random()+a
def makeMatrix(m,n,val=0.0):
return [[val]*n for _ in range(m)]
class BPNN:
def __init__(self,n_in,n_out,n_hidden=10,lr=0.1,m=0.1):
self.n_in=n_in+1
self.n_hidden=n_hidden+1
self.n_out=n_out
self.lr=lr
self.m=m
self.weight_hidden=makeMatrix(self.n_in,self.n_hidden)
self.weight_out=makeMatrix(self.n_hidden,self.n_out)
for i,row in enumerate(self.weight_hidden):
for j,val in enumerate(row):
self.weight_hidden[i][j]=getRandom(-0.2,0.2)
for i,row in enumerate(self.weight_out):
for j,val in enumerate(row):
self.weight_out[i][j]=getRandom(-0.2,0.2)
self.in_matrix=[1.0]*self.n_in
self.hidden_matrix=[1.0]*self.n_hidden
self.out_matrix=[1.0]*self.n_out
self.ci=makeMatrix(self.n_in,self.n_hidden)
self.co=makeMatrix(self.n_hidden,self.n_out)
def update(self,inputs):
self.in_matrix[:-1]=inputs
for i in range(self.n_hidden-1):
accumulate=0
for j in range(self.n_in-1):
accumulate+=self.in_matrix[j]*self.weight_hidden[j][i]
self.hidden_matrix[i]=sigmoid(accumulate)
for i in range(self.n_out):
accumulate = 0
for j in range(self.n_hidden - 1):
accumulate += self.hidden_matrix[j] * self.weight_out[j][i]
self.out_matrix[i] = sigmoid(accumulate)
return self.out_matrix[:]
def backpropagate(self,target):
out_err=[derived_sigmiod(o:=self.out_matrix[i])*(t-o) for i,t in enumerate(target)]
hidden_err=[derived_sigmiod(self.hidden_matrix[i])*sum(out_err[j]*self.weight_out[i][j] for j in range(self.n_out)) for i in range(self.n_hidden) ]
for i in range(self.n_hidden):
for j in range(self.n_out):
change=self.hidden_matrix[i]*out_err[j]
self.weight_out[i][j]+=self.lr*change+self.m*self.co[i][j]
self.co[i][j]=change
for i in range(self.n_in):
for j in range(self.n_hidden):
change=hidden_err[j]*self.in_matrix[i]
self.weight_hidden[i][j]+=self.lr*change+self.m*self.ci[i][j]
self.ci[i][j]=change
err=0.0
for i,v in enumerate(target):
err+=(v-self.out_matrix[i])**2
err/=len(target)
return math.sqrt(err)
5️⃣ 模型使用
在这阶段我们新加两个API,用于网络训练和拟合
def train(self,data,epochs=1000):
best_err=1e10
for i in range(epochs):
err=0.0
for j in data:
x=j[0]
y=j[1]
self.update(x)
err+=self.backpropagate(y)
if err<best_err:
best_err=err
print(best_err)
def fit(self,x):
return [self.update(i) for i in x]
我们也可以创建一个随机数据生成器用来获取随机数据
def getData(m,n,c=None):
# 随机生成一组大小为m*n,类别为c的数据
if c!=None:
data=[[[random.uniform(0.0,2.0)]*n,[random.randint(0,c)]] for i in range(m)]
else:
data=[[random.uniform(0.0,2.0)]*n for _ in range(m)]
return data
d_train=getData(20,5,1)
d_test=getData(10,5)
不过我们这里使用固定的模式进行测试:
# 固定模式
d=[
[[1,0,1,0,1],[1]],
[[1,0,1,0,1],[1]],
[[1,0,1,0,1],[1]],
[[1,0,1,1,1],[0]],
[[1,0,1,0,1],[1]],
[[1,0,1,1,1],[0]],
]
c=[
[1,0,1,0,1],
[1,0,1,0,1],
[1,0,1,1,1],
[1,0,1,0,1],
[1,0,1,1,1],
[1,0,1,0,1],
[1,0,1,0,1],
[1,0,1,1,1],
[1,0,1,0,1],
[1,1,1,0,1],
]
输入数据是一个6*5大小的数据,label是一个一维数据,所以我们需要创建一个输入维度为5,输出维度为1的BPNN:
net=BPNN(5,1)
net.train(d)
print(net.fit(c))
得到的结果为:
[[0.9831619856205059], [0.9831619856205059], [0.023029882403248512], [0.9831619856205059], [0.023029882403248512], [0.9831619856205059], [0.9831619856205059], [0.02302988]]
可以发现确实简单实现了二分类。
当然我们也可以设定输出维度为2,结果表示为:
net=BPNN(5,2)
net.train(d)
print(["cat" if i[0]>i[1] else 'dog' for i in net.fit(c)])
Err: 0.10754377610345334
result:
['cat', 'cat', 'dog', 'cat', 'dog', 'cat', 'cat', 'dog', 'cat', 'cat']
优点
-
对噪声数据有较高的容忍度
-
适合连续值的输入和输出
-
成功处理大量真实世界的数据
-
最近开发了从训练过的神经网络中提取规则的技术
缺点
- 训练时间长
- 可解释性差
- 参数初始化是个问题
- 选择结构也是个问题
Chapter 6. 其他分类方法
K-Nearest Neighbor KNN,比较常见的算法。
- 所有实例都对应到n维空间上的点
- 找到欧式距离最近的两个点
- 目标函数可以是离散的,也可以是实值的
- 对于离散值,k- nn返回最接近X的k个训练示例中最常见的值(一般是投票)
探讨
k-NN用于给定未知元组的实值预测,返回最近邻居的平均值(或者是投票结果)。这种结构是一种Lazy-Learner懒学习,不需要构建分类器,存储所有的训练样本,对噪声的鲁棒性良好。但是,每个新元组的计算成本很高。
集成方法
通过模型组合的方式来提高精度
主要有两种主流的集成方式:Bagging和Boosting
Bagging就是多个弱分类器一起投票,最后计算得票最多的结果。
可以通过取给定测试元组的每个预测的平均值,可以应用于连续值的预测
一般来说,Bagging有以下优点:
-
通常显著优于派生的单个分类器
-
对于噪声数据响应良好,更健壮
-
提高了预测的准确性
Boosting算法的核心框架就是弱分类器一起变强:
- 我们有一个不那么牛的分类器 f ( x 1 ) f(x1) f(x1)
- 我们用一个跟他互补的也是不那么牛的分类器 f ( x 2 ) f(x2) f(x2)辅助它
- 一直执行下去,直到最后的结果还不错
正规来说,可以这样说:
- 学习一个分类器 M i M_i Mi后,更新权重,使后续的分类器 M i + 1 M_{i+1} Mi+1更多地关注被 M i M_i Mi错误分类的训练元组
- 一系列的 k k k个分类器被迭代学习,最后的 M ∗ M* M∗组合了每个分类器的投票,其中每个分类器的投票权重是其准确性的函数
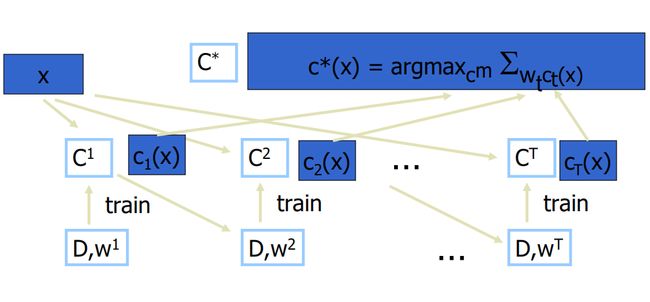
比较
| Bagging | Boosting |
|---|---|
| 随机抽样,独立分类器 | 续的分类器 M i + 1 M_{i+1} Mi+1更多地关注被 M i M_i Mi错误分类的训练元组 |
| 合并时是同等权重 | 合并时采用精确度作为权重 |
一般来说,Boosting精度会更高,因为有针对性,但是面临过拟合的风险。
Chapter 7. 预测
预测不同于分类,预测的对象是连续的,而不是像分类一样一般是有限个离散集合。
其主要手段就是回归
回归是一种手段,与分类真正相对应的是预测
这里我们介绍一些回归方法
回归分析
回归分析的核心在于确定变量之间存在着的函数关系
各个变量之间可以分为确定关系和非确定关系(相对关系),我们要做的就是对这种关系进行建模和解释。
其主要流程可以解释如下:
- 收集一组包含因变量和自变量的数据
- 根据因变量和自变量之间的关系,初步设定回归模型
- 求解合理的回归系数
- 进行相关性检验,确定相关系数
- 利用模型对因变量做出预测或解释,并计算预测值的置信区间。
一、一元线性回归分析
表达式如下:
y = f ( x , θ ) + ε = β 0 + β 1 x + ε y=f(x,\theta)+\varepsilon=\beta_0+\beta_1x+\varepsilon y=f(x,θ)+ε=β0+β1x+ε
其中, ε \varepsilon ε表示误差项,其期望 E ( ε ) = 0 E(\varepsilon)=0 E(ε)=0,方差等于 D ( ε ) = σ 2 D(\varepsilon)=\sigma^2 D(ε)=σ2, β 0 \beta_0 β0为常数项,也称为截距, β 1 \beta_1 β1为斜率。
求解参数的主流方法有最小二乘法、最大似然法、矩方法。下面介绍最小二乘法。
最小二乘法(Least Squares Estimation,LSE)通过最小化误差的平方和来寻找数据的最佳匹配。
我们定义残差平方和(Residual Sum of Squares,RSS), △ y = ( y − y ^ ) \triangle y=(y-\hat y) △y=(y−y^)表示残差:
Q ( β 0 , β 1 ) = ∑ i = 1 n ( y i − y ^ i ) 2 = ∑ i = 1 n ( y i − β ^ 0 − β ^ 1 x i ) 2 Q(\beta_0,\beta_1)=\sum_{i=1}^n(y_i-\hat y_i)^2 \\ =\sum_{i=1}^n(y_i-\hat\beta_0-\hat\beta_1x_i)^2 Q(β0,β1)=i=1∑n(yi−y^i)2=i=1∑n(yi−β^0−β^1xi)2
根据微积分知识,这玩意的极值点应该在导数为0的时候取得,我们对 Q Q Q求偏导,得到:
{ σ Q σ β ^ 0 = − 2 ∑ i = 1 n ( y i − β ^ 0 − β ^ 1 x i ) σ Q σ β ^ 1 = − 2 ∑ i = 1 n ( y i − β ^ 0 − β ^ 1 x i ) x i \begin{cases} \frac{\sigma Q}{\sigma \hat\beta_0}=-2\sum_{i=1}^n(y_i-\hat\beta_0-\hat\beta_1x_i)\\ \frac{\sigma Q}{\sigma \hat\beta_1}=-2\sum_{i=1}^n(y_i-\hat\beta_0-\hat\beta_1x_i)x_i\\ \end{cases} {σβ^0σQ=−2∑i=1n(yi−β^0−β^1xi)σβ^1σQ=−2∑i=1n(yi−β^0−β^1xi)xi
求解方程组得到:
{ β ^ 0 = y ˉ − β ^ 1 x ˉ β ^ 1 = ∑ i = 1 n ( x i − x ˉ ) ( y i − y ˉ ) ∑ i = 1 n ( x i − x ˉ ) 2 \begin{cases} \hat\beta_0=\bar y-\hat\beta_1\bar x\\ \hat\beta_1=\frac{\sum_{i=1}^n(x_i-\bar x)(y_i-\bar y)}{\sum_{i=1}^n(x_i-\bar x)^2} \end{cases} {β^0=yˉ−β^1xˉβ^1=∑i=1n(xi−xˉ)2∑i=1n(xi−xˉ)(yi−yˉ)
将其带入方程,即可得到最佳拟合曲线。
误差估计
SSE:
∑ i = 1 n e i 2 = ∑ i = 1 n ( y i − y ^ i ) 2 \sum_{i=1}^ne_i^2=\sum_{i=1}^n(y_i-\hat y_i)^2 i=1∑nei2=i=1∑n(yi−y^i)2
MSE是对SSE的无偏估计量
σ 2 = S S E n − 2 = M S E \sigma^2=\frac{SSE}{n-2}=MSE σ2=n−2SSE=MSE
Python实现一元线性回归
Step 1️⃣ 数据准备
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.linear_model import LinearRegression
# 导入数据集
iris=load_iris()
data=pd.DataFrame(iris.data)
data.columns=['sepal-length','sepal-width','petal-length','petal-width']
print(data.head())
sepal-length sepal-width petal-length petal-width
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
# 使用scikit-learn完成回归
x=data['petal-length'].values
y=data['petal-width'].values
x=x.reshape(len(x),1)
y=y.reshape(len(y),1)
clf=LinearRegression()
clf.fit(x,y)
pre=clf.predict(x)
# 绘制图形
plt.scatter(x,y,s=50)
plt.plot(x,pre,'r-',linewidth=2)
plt.xlabel("petal-length")
plt.ylabel("petal-wdith")
for idx,m in enumerate(x):
# 绘制长条
# 从(m,y[idx])到(m,pre[idx])
plt.plot([m,m],[y[idx],pre[idx]],'g-')
plt.show()

step 2️⃣ 显示回归参数
print("斜率",clf.coef_)
print("截距",clf.intercept_)
print("MSE",np.mean((y-pre)**2))
斜率 [[0.41575542]]
截距 [-0.36307552]
MSE 0.04206730919499318
step 3️⃣ 进行预测
print(clf.predict([[3.9]]))
[[1.2583706]]
二、多元线性回归
也就是有多个参数啦。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression
# 导入数据集
d=load_boston()
data=pd.DataFrame(d.data)
data['price']=d.target
print(data.sample(5))
0 1 2 3 4 ... 9 10 11 12 price
373 11.10810 0.0 18.10 0.0 0.668 ... 666.0 20.2 396.90 34.77 13.8
491 0.10574 0.0 27.74 0.0 0.609 ... 711.0 20.1 390.11 18.07 13.6
91 0.03932 0.0 3.41 0.0 0.489 ... 270.0 17.8 393.55 8.20 22.0
363 4.22239 0.0 18.10 1.0 0.770 ... 666.0 20.2 353.04 14.64 16.8
322 0.35114 0.0 7.38 0.0 0.493 ... 287.0 19.6 396.90 7.70 20.4
[5 rows x 14 columns]
多元线性回归
y=d.target
x=d.data
clf=LinearRegression()
from sklearn.model_selection import train_test_split
# 分割训练集
x_train,x_test,y_train,y_test=train_test_split(x,y)
clf.fit(x_train,y_train)
print("多元线性回归模型参数",clf.coef_)
print("多元线性回归模型常数项",clf.intercept_)
print("预测",clf.predict([x_test[0]]))
多元线性回归模型参数 [-1.11747256e-01 4.05201935e-02 -6.69439553e-04 3.34919157e+00
-1.83818082e+01 3.95199967e+00 -9.12733246e-03 -1.31523502e+00
2.44628300e-01 -1.08309725e-02 -1.00522555e+00 7.56771086e-03
-4.23492114e-01]
多元线性回归模型常数项 36.524193135861886
预测 [15.9054318]
模型分析
y_predict=clf.predict(x_test)
from sklearn.metrics import mean_absolute_error
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
print("预测值均方误差",mean_squared_error(y_test,y_predict))
print("R2得分",r2_score(y_test,y_predict))
print("回归得分",clf.score(x_test,y_test))
print("各个特征间的系数矩阵",clf.coef_)
print("影响房价的特征排序",np.argsort(clf.coef_))
print("影响房价的特征排序",d.feature_names[np.argsort(clf.coef_)])
预测值均方误差 26.66065801123315
R2得分 0.7170059315243467
回归得分 0.7170059315243467
各个特征间的系数矩阵 [-1.24752898e-01 4.23381228e-02 7.89030069e-03 2.76191464e+00
-1.86055326e+01 3.76015663e+00 -3.25002550e-03 -1.49233753e+00
3.12843628e-01 -1.40160600e-02 -8.47213267e-01 7.64996205e-03
-5.32883469e-01]
影响房价的特征排序 [ 4 7 10 12 0 9 6 11 2 1 8 3 5]
影响房价的特征排序 ['NOX' 'DIS' 'PTRATIO' 'LSTAT' 'CRIM' 'TAX' 'AGE' 'B' 'INDUS' 'ZN' 'RAD'
'CHAS' 'RM']
三、逻辑回归
如果说线性回归偏向数学,那么逻辑回归就是机器学习从统计领域借鉴来的技术
逻辑回归用来分析二分类或有序的因变量与解释变量之间的关系,算是广义上的线性回归分析方法。他在线性回归的基础上利用Sigmoid函数对事件发生的概率进行预测。
线性回归可以得到一个预测值,然后通过S函数封装后,就能得到一个概率值,再通过概率值进行分类。(上清下浊)
Sigmoid的函数能够将任意值转化为[0,1]范围内,其定义如下:
g ( z ) = 1 1 + e − z g(z)=\frac{1}{1+e^{-z}} g(z)=1+e−z1
我们来看下函数曲线
宏观尺度
微观尺度
def sigmoid(x):
return 1./(1.+np.exp(-x))
Python 实现
x=load_iris().data
y=load_iris().target
# 归一化
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25,random_state=0)
from sklearn.preprocessing import StandardScaler
sc=StandardScaler()
x_train=sc.fit_transform(x_train)
x_test=sc.transform(x_test)
# 进行逻辑回归
from sklearn.linear_model import LogisticRegression
classifier=LogisticRegression(random_state=0)
classifier.fit(x_train,y_train)
y_pred=classifier.predict(x_test)
# 测试准确性
print("Accuracy of LR %.3f"%classifier.score(x_test,y_test))
Accuracy of LR 0.974
我们可以看一下经过逻辑回归后的数据:
[2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0 2]
这是个多分类的回归。
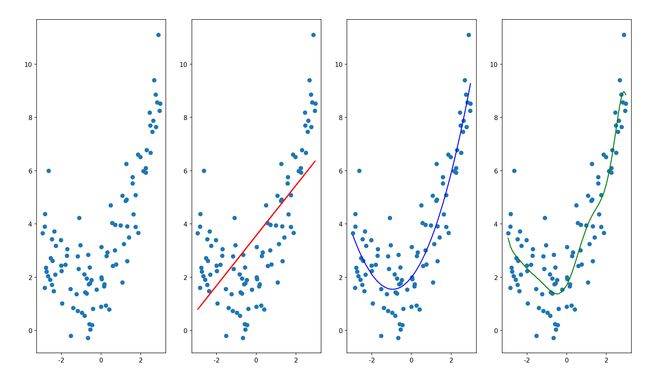
四、多项式回归
适用于非线性关系。
# 线性回归
lin_reg=LinearRegression()
lin_reg.fit(X,y)
y_pre=lin_reg.predict(X)
plt.rcParams['font.family']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
ax[1].scatter(x,y)
ax[1].plot(x,y_pre,color="r")
# 多项式回归
from sklearn.preprocessing import PolynomialFeatures
POLY=PolynomialFeatures(degree=2) # 设置最多几次幂
POLY.fit(X)
x2=POLY.transform(X)
# 这个多项式回归是对x进行处理后,让其成为非线性关系
# 譬如:
print(x.shape)
print(x2.shape)
# (100,)
# (100, 3)
# 之后的操作与LR完全相同,所以Polynomial并没有作为独立的API
# 而是放在preprocessing
lin_reg2=LinearRegression()
lin_reg2.fit(x2,y)
y_pre2=lin_reg2.predict(x2)
ax[2].scatter(x,y)
# 此时的关系并不再是原先的对应了
ax[2].plot(np.sort(x),y_pre2[np.argsort(x)],color="b")
# degree调成10 后
POLY=PolynomialFeatures(degree=10) # 设置最多几次幂
POLY.fit(X)
x2=POLY.transform(X)
# 这个多项式回归是对x进行处理后,让其成为非线性关系
# 譬如:
print(x.shape)
print(x2.shape)
# (100,)
# (100, 11)
# 之后的操作与LR完全相同,所以Polynomial并没有作为独立的API
# 而是放在preprocessing
lin_reg2=LinearRegression()
lin_reg2.fit(x2,y)
y_pre2=lin_reg2.predict(x2)
ax[3].scatter(x,y)
ax[3].plot(np.sort(x),y_pre2[np.argsort(x)],color="g")
plt.show()
五、岭回归
岭回归(Ridge Regression)是一种专用于共线性数据分析的有偏估计回归方法,实质上是改良的最小二乘法。通过放弃无偏性,降低部分信息为代价,使回归系数更加可靠,对病态数据的耐受性远高于最小二乘法。
通常的岭回归是在顺势函数中加入L2正则项:
L ( θ ) = 1 N ∑ i = 1 N ( f ( x i ; θ ) − y i ) 2 + λ 2 ∣ ∣ θ ∣ ∣ 2 L(\theta)=\frac{1}{N}\sum_{i=1}^N(f(x_i;\theta)-y_i)^2+\frac{\lambda}{2}||\theta||^2 L(θ)=N1i=1∑N(f(xi;θ)−yi)2+2λ∣∣θ∣∣2
其中, ∣ ∣ θ ∣ ∣ ||\theta|| ∣∣θ∣∣表示向量 θ \theta θ的 L 2 L2 L2范数。岭回归的 R 2 R^2 R2往往会小于线性回归,但其具有更强的泛化能力,也能解决线性回归汇总的不可逆问题。
from sklearn.linear_model import Ridge,RidgeCV
# Ridge CV是广义交叉验证的岭回归
X,y=load_iris(return_X_y=True)
x=X[:,1].reshape(len(X),-1)
y=X[:,0].reshape(len(X),-1)
model=Ridge(alpha=0.5)
model1=RidgeCV(alphas=[0.1,1.0,10.0]) # cross validation
model.fit(x,y)
model1.fit(x,y)
print("系数矩阵",model.coef_)
print("线性回归模型",model)
print("CV最优alpha值",model1.alpha_)
# 模型预测
pre=model.predict(x)
plt.scatter(x,y)
plt.plot(x,pre)
plt.show()
系数矩阵 [[-0.2194842]]
线性回归模型 Ridge(alpha=0.5)
CV最优alpha值 10.0
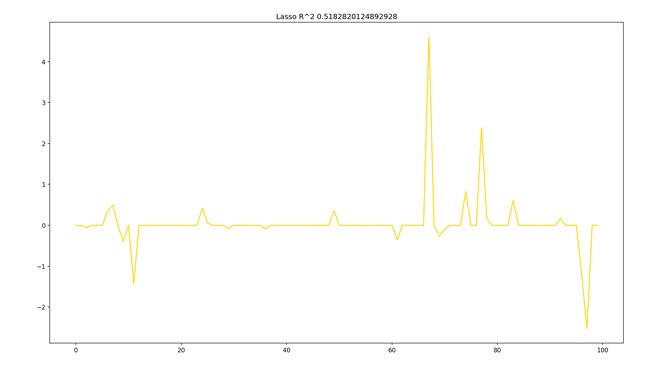
六、Lasso回归
L 2 L2 L2正则只能削弱影响,而不能剔除变量。Lasso(Least Absolute Shrinkage and Selection Operator)模型将惩罚项换为了 L 1 L1 L1正则,从而达到剔除变量的作用。
from sklearn.metrics import r2_score
# 产生一些稀疏数据
np.random.seed(42)
n_samples,n_features=50,100
X=np.random.randn(n_samples,n_features)
coef=3*np.random.randn(n_features) # 每个特征对应一个系数
inds=np.arange(n_features)
np.random.shuffle(inds)
coef[inds[10:]]=0 # 随机将向量中的10个变为0 稀疏化
y=np.dot(X,coef)
# 添加高斯噪声
y+=0.01*np.random.normal(size=n_samples)
# 划分数据集
n_samples=X.shape[0]
X_train,y_train=X[:n_samples//2],y[:n_samples//2]
X_test,y_test=X[n_samples//2:],y[n_samples//2:]
# 训练Lasson模型
from sklearn.linear_model import Lasso
alpha=0.1
lass=Lasso(alpha=alpha)
y_pre=lass.fit(X_train,y_train).predict(X_test)
r2_score_lasso=r2_score(y_test,y_pre)
print("R^2 socre",r2_score_lasso)
plt.plot(lass.coef_,color='gold')
plt.title("Lasso R^2 %s"%r2_score_lasso)
plt.show()
回归案例–波士顿数据处理
import numpy as np
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression,SGDRegressor,Ridge,Lasso
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error,accuracy_score
from sklearn.model_selection import train_test_split
def linearModel():
# 1. load dataset
X,y=load_boston(return_X_y=True)
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25)
# 2. Standard
std=StandardScaler()
X_train=std.fit_transform(X_train)
X_test=std.transform(X_test)
# 添加维度
# y=y[:,np.newaxis]
y_test=y_test[:,np.newaxis]
y_train=y_train[:,np.newaxis]
std_y=StandardScaler()
y_train=std_y.fit_transform(y_train)
y_test=std_y.transform(y_test)
# 3. training
lr=LinearRegression()
sgd=SGDRegressor()
rid=Ridge(alpha=0.5)
las=Lasso(alpha=0.5)
lr.fit(X_train,y_train)
y_lr_pre=lr.predict(X_test)
# 还原真实值
# 这是因为我们做处理用的都是标准化
# 所以最后跟原始数据比较需要反标准化
y_lr_pre=std_y.inverse_transform(y_lr_pre)
sgd.fit(X_train,y_train)
y_sgd_pre=sgd.predict(X_test)
y_sgd_pre=std_y.inverse_transform(y_sgd_pre)
rid.fit(X_train, y_train)
y_rid_pre = rid.predict(X_test)
y_rid_pre = std_y.inverse_transform(y_rid_pre)
las.fit(X_train, y_train)
y_las_pre = las.predict(X_test)
y_las_pre = std_y.inverse_transform(y_las_pre)
# 4. evaluation
y_test=std_y.inverse_transform(y_test)
print("线性回归的均方误差为: ",mean_squared_error(y_test,y_lr_pre))
print("梯度下降的均方误差为: ",mean_squared_error(y_test,y_sgd_pre))
print("岭回归的均方误差为: ",mean_squared_error(y_test,y_rid_pre))
print("Lasson均方误差为: ",mean_squared_error(y_test,y_las_pre))
linearModel()
线性回归的均方误差为: 24.474589501317524
梯度下降的均方误差为: 23.82902862765662
岭回归的均方误差为: 24.433234356526174
Lasson均方误差为: 61.95307932912878
Chapter 8. 精度与误差评估
| C1 | C2 | Total | |
|---|---|---|---|
| C1 | True Positive | False Negative | pos |
| C2 | False Positive | True Negative | neg |
| Total | TP+FP | TN+FN | pos+neg |
分类的精度就是正确预测的占数据的总量啦
A c c u r a c y = T P + T N p o s + n e g Accuracy=\frac{TP+TN}{pos+neg} Accuracy=pos+negTP+TN
敏感性就是,对正例的识别准确度,所以样本区间是真正例
s e n s i t i v i t y = T P p o s sensitivity=\frac{TP}{pos} sensitivity=posTP
特异性就是对负例的识别准确度
s p e c i f i c i t y = T N n e g specificity=\frac{TN}{neg} specificity=negTN
准确率就是,预测为正的值里,实际为正的值,是对模型本身的评价
p r e c i s i o n = T P T P + F P precision=\frac{TP}{TP+FP} precision=TP+FPTP
Chapter 9. 总结
- 分类和预测是数据分析的两种形式,可用于提取描述重要数据类别的模型或预测未来的数据趋势。
- 已经发展了有效的和可扩展的方法来归纳决策树、贝叶斯分类,反向传播,最近邻分类器。
- 线性、非线性和广义线性回归模型可用于预测。通过对预测变量进行变换,许多非线性问题可以转化为线性问题。
- K-fold交叉验证是一种推荐的精度估计方法。
- Bagging和boosting可以通过学习和组合一系列单独的模型来提高整体精度。
- 对于所有数据集,没有一种方法优于其他方法。
- 必须考虑诸如准确性、训练时间、健壮性、可解释性和可伸缩性等问题。