CVF2020邻域自适应/语义分割:FDA: Fourier Domain Adaptation for Semantic SegmentationFDA:用于语义分割的傅立叶域自适应算法
邻域自适应/语义分割:FDA: Fourier Domain Adaptation for Semantic Segmentation FDA:用于语义分割的傅立叶域自适应算法
- 0.摘要
- 1.概述
-
- 1.1.相关工作
-
- 1.1.1语义分割
- 1.1.2.域自适应
- 2.方法
-
- 2.1. 傅立叶域自适应(FDA)
- 2.2.为语义分割设计的FDA
- 3.实验
-
- 3.1.数据集和训练细节
- 3.2.单一尺度的FDA
- 3.3.多波段转换(Multi-band Transfer:MBT)
- 3.4. MBT自我监督训练
- 3.5.基准
- 3.6.定性结果
- 4. 讨论
- 参考文献
论文地址
代码开源
0.摘要
我们描述了一种无监督域自适应的简单方法,即通过交换一个和另一个的低频谱来减少源分布和目标分布之间的差异。我们在语义分割中说明了这种方法,在语义分割中,密集注释的图像在一个领域(例如合成数据)中非常丰富,但在另一个领域(例如真实图像)中很难获得。当前最先进的方法非常复杂,有些方法需要对抗性优化,以使神经网络的主干对离散域选择变量保持不变。我们的方法不需要任何训练来执行域对齐,只需要一个简单的傅里叶变换及其逆变换。尽管它很简单,但当集成到一个相对标准的语义分割模型中时,它在当前的基准测试中实现了最先进的性能。我们的结果表明,即使是简单的程序也可以忽略数据中令人讨厌的可变性,而更复杂的方法很难了解这些可变性。1.
1.概述
无监督领域适应(UDA)指的是使一个模型适应一个分布(源)中经过注释的样本,以在没有给出注释的不同(目标)分布上运行。例如,源域可以由合成图像及其相应的像素级标签(语义分割)组成,而目标可以是没有地面真值注释的真实图像。由于协变量的变化,在源数据上简单地训练模型不会在目标数据上产生令人满意的性能。在某些情况下,除非执行UDA,否则低级统计数据中感知上不重要的变化可能会导致训练模型的性能显著恶化。
最先进的UDA方法为给定任务(比如语义分割)训练一个深度神经网络(DNN)模型,再加上一个辅助损失,使模型对源/目标域的二进制选择保持不变。这需要艰苦的对抗性训练。我们探索了这样一个假设,即源分布和目标分布之间的低级统计数据的简单对齐可以提高UDA的性能,而不需要在语义分割的主要任务之外进行任何培训。
我们的方法如图1所示:我们只需计算每个输入图像的(快速)傅里叶变换(FFT),并在使用源域中的原始注释,通过逆FFT(iFFT)重建用于训练的图像之前,将目标图像的低频率替换为源图像。
为了验证我们的假设,我们使用在源上训练的模型在目标数据上的性能作为基线(下限)。作为典范(上限),我们使用了最先进的模型和对抗性训练[19]。我们预计,这样一个简单的低水平统计“零炮”校准将改善基线,并有望接近典范。然而,该方法实际上在语义分割方面优于paragon。我们并不认为这意味着我们的方法是执行UDA的方法,尤其是对于语义分割之外的一般任务。然而,这样一种简单的方法优于复杂的对抗性学习,这一事实表明,这些模型在管理低水平的干扰可变性方面并不有效。
傅里叶域自适应需要选择一个自由参数,即要交换的光谱邻域的大小(图1中的绿色正方形)。我们测试了各种大小,以及一种简单的多尺度方法,该方法包括对不同域大小产生的结果进行平均。
我们采用这种方法的动机源于这样一个观察:低水平的频谱(振幅)可以显著变化,而不会影响对高水平语义的感知。物体是车辆还是人不应取决于传感器、光源或其他低水平变化源的特性。然而,这种可变性对频谱有重大影响,迫使基于学习的模型与其他讨厌的可变性一起“学习”。如果在训练集中没有表现出这种可变性,模型就无法推广。然而,我们从一开始就知道,存在一些不确定因素,这些因素并不能为手头的任务提供信息。如果我们操纵全局光度统计数据,图像的分类解释是不变的。任何单调的颜色图重缩放,包括非线性对比度变化,都是已知的干扰因素,可以在一开始就消除,而无需学习。这一点尤其重要,因为网络似乎无法在不同的低级统计数据之间很好地传输[1]。虽然人们可以规范化对比度变换,但在没有标准参考的情况下,我们的傅里叶变换是注册对比度变换的最简单方法之一。更广泛的一点是,已知的干扰可变性可以在一开始就处理,而无需通过复杂的对抗训练来学习。
在下一节中,我们将更详细地描述我们的方法,然后在标准UDA基准测试中进行经验测试。在这样做之前,我们把我们的工作放在当前文献的背景下。
1.1.相关工作
1.1.1语义分割
语义分割得益于DNN体系结构的不断演变[26,51,5,54,41]。它们通常是在具有密集像素级注释的数据集上训练的,比如城市景观[9]、PASCAL[11]和MSCOCO[24]。手动注释不可扩展[53],捕获代表性的成像条件增加了挑战。这激发了人们对使用合成数据的兴趣,例如来自GTA5[33]和SYNTHIA[34]的数据。由于领域转移,在前者基础上训练的模型在后者基础上往往表现不佳。
1.1.2.域自适应
旨在减少两种分布之间的转换[32,10,46]。常见的差异度量是MMD(最大平均差异)及其核变量[15,27],通过CMD(中心矩差异)[52]扩展到高阶统计量[3,30]。不幸的是,由于这些度量的表达能力有限,即使MMD最小化,也不能保证两个数据集对齐。用于领域适应的对抗性学习[14,44,39,21]使用经过训练的鉴别器来最大化源和目标表征之间的混淆,从而减少领域差异。与图像级分类[20,28,37]不同,高级特征空间[27,16,36,38,31]中的对齐对于语义分割可能适得其反,因为复杂的表示和稳定对抗训练的困难。
我们利用图像到图像的翻译和风格转换[55,25,50,8]来改进语义分割的领域适应性。Cycada[19]在像素级和特征级对齐表示。DCAN[47]通过多层次特征的通道对齐来保留空间结构和语义。为了便于图像空间对齐,[4]提出了域不变结构提取,以分离域不变和特定于域的表示。[6] 使用密集深度,在合成数据中随时可用。[17] 在源和目标之间生成中间样式的图像。宗族[29]在全局对齐中加强局部语义一致性。[53]提出课程式学习,将图像的全局分布和地标超像素的局部分布结合起来。BDL[23]采用双向学习,图像变换网络利用分割网络。在输出空间[6,43]上还应用了鉴别器,以对齐源和目标分割。
在多个级别使用转换网络和鉴别器在计算上要求很高,在对抗性框架内进行训练更具挑战性。相比之下,我们的方法不使用任何图像转换网络来生成训练图像,也不使用鉴别器来对齐像素/特征级分布。在我们的方法中训练的唯一网络是用于语义分割的主要任务。我们使用一个完全卷积的网络,输出像素级(log)的可能性。注:在并行工作[48]中,以相位保持为约束训练的变压器网络也会生成保持源图像语义内容的域对齐图像。然后,通过使用条件先验网络学习场景兼容性来实现类似的自适应增益[49]。
2.方法
我们首先描述了不需要任何训练的简单傅立叶对齐,然后描述了我们用来训练整个语义分割网络以利用傅立叶对齐的损
失。 .
2.1. 傅立叶域自适应(FDA)
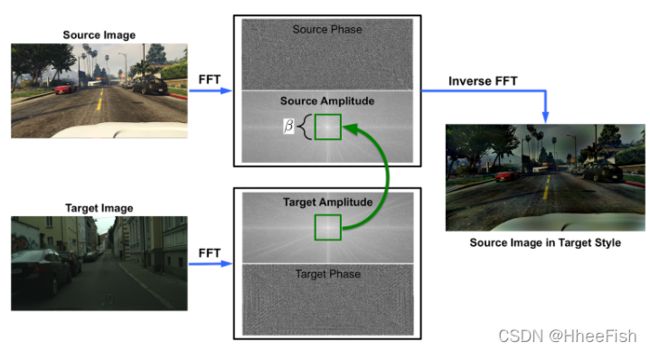
图1:光谱转移:在不改变语义内容的情况下,将源图像映射到目标“样式”。随机采样的目标图像通过将源图像频谱的低频分量与其自身频谱进行交换来提供样式。结果“目标风格的源图像”在感知上显示了更小的域差距,并改进了语义分割的迁移学习,如第3节中的基准测试所测。
图2。图1所示的域β大小的影响,其中光谱被交换:增加β将减少域间隙,但会引入伪影(参见放大的插图)。我们调整β,直到变换图像中的伪影变得明显,并在一些实验中使用单个值。在其他实验中,我们在多尺度设置中同时保持多个值(表1
在无监督域适配(UDA)中,我们得到一个源数据集Ds={(xsi,ysi)∼ P(xs,ys)}Nsi=1,其中xs∈ RH×W×3是彩色图像,ys∈ RH×W是与xs相关的语义映射。类似地,Dt={xti}Nti=1是目标数据集,其中缺少基本真语义标签。通常,在Ds上训练的分割网络在Dt上测试时,性能会下降。在这里,我们提出傅立叶域自适应(FDA)来减少两个数据集之间的域差距。
设Fa,Fp:RH×W×3→ RH×W×3是RGB图像的傅里叶变换F的振幅和相位分量,即对于单通道图像x,我们有:
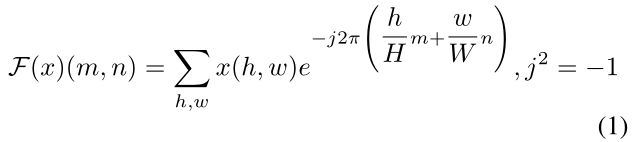
在[13]中使用FFT算法可以有效地实现。因此,F−1是将光谱信号(相位和振幅)映射回图像空间的傅里叶反变换。进一步,我们用Mβ表示一个掩码,其值为0,除了中心区域β∈(0,1):

在这里,我们假设图像的中心是(0,0)。注意,β不是以像素衡量的,因此β的选择不取决于图像大小或分辨率。给定两个随机采样图像xs ~ Ds, xt ~ Dt,傅里叶域适应可以形式化为:

其中源图像FA(xs)振幅的低频部分替换为目标图像xt的低频部分。然后,将x的修改后的光谱表示,不改变其相位分量,映射回图像xs→t,其内容与xs相同,但与Dt中样本的外观相似。该过程如图1所示,掩模Mβ以绿色表示。
β的选择
我们可以从公式(3)中看到,β = 0将渲染xs→t与原始源图像xs相同。另一方面,当β = 1.0时,xs的幅值将被xt的幅值所取代。图2显示了β的影响。我们发现,当β增加到1.0时,图像xs→t接近目标图像xt,但也显示出可见的伪影,可以从图2的放大区域看到。我们设置β≤0.15。然而,在表1中,我们展示了各种β选择的影响以及结果模型的平均值,类似于一个简单的多尺度池化方法。
2.2.为语义分割设计的FDA
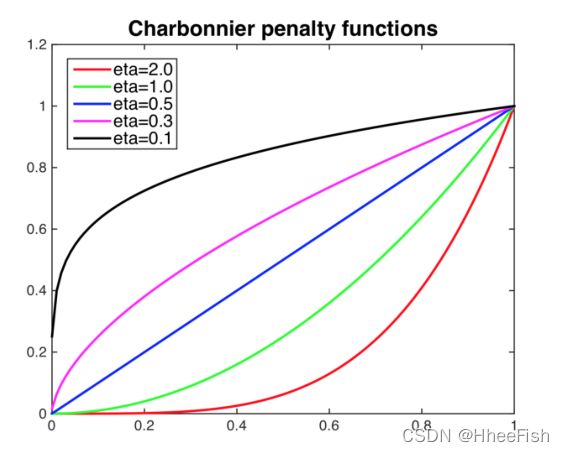
图3。Charbonnier惩罚用于鲁棒熵最小化,针对参数η的不同值可视化。
给定自适应源数据集Ds→t,我们可以通过最小化以下交叉熵损失来训练一个参数为w的语义分割网络:

由于FDA对这两个领域进行了校准,UDA就变成了一个半监督学习(SSL)问题。SSL的关键是规范化模型。我们用惩罚作为判定边界在未标记空间中跨簇的标准。
假设分类分离,这可以通过惩罚决策边界穿越数据点密集的区域来实现,而这又可以通过最小化目标图像上的预测熵来实现。然而,如[45]所述,这在低熵区域是无效的。我们使用了一个鲁棒的熵最小化加权函数,即
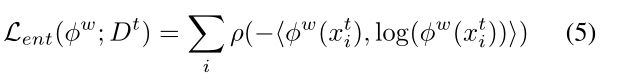
其中ρ(x) = (x2 + 0.0012)η是Charbonnier罚函数[2]。如图3所示,它对η > 0.5高熵预测的惩罚大于低熵预测。将此与自适应源图像的分割损失相结合,我们可以使用以下整体损失从头开始训练语义分割网络φw:
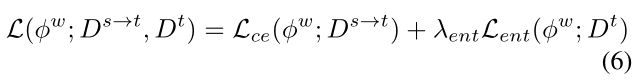
自监督训练(或者更准确地说,是“自学”)
是一种试图提高SSL性能的常用方法,它使用φw预测的高度自信的伪标签,就像它们是基本事实一样。在没有正规化的情况下,这种做法是自我参照的,所以我们关注正则化。
正如在[42]中观察到的,平均教师通过平均模型权值来提高半监督学习性能,这在学习过程中提供了正则化。在这里,我们建议使用多个模型预测的均值来规范自学习。然而,我们不像[21]那样使用相同的损失和显式的发散项来训练多个模型,而是在FDA过程中直接使用不同的β’训练多个φwβ模型,不需要显式强制模型发散。我们实例化了M=3个分割网络φwβm, M= 1,2,3,使用(6)从头训练,对某目标图像xti的均值预测可以通过:

请注意,网络的输出是softmax激活,因此平均值仍然是K类的概率分布。利用M模型生成的伪标签,我们可以训练φwβ,通过以下自我监督训练损失得到进一步的改进:

其中Dˆt是用伪标签yˆti增强的Dt^。由于我们的训练在FDA操作中需要不同的β,我们将使用不同分割网络的平均预测的自我监督训练称为多波段传输(MBT)。我们FDA语义分割网络的完整训练过程包括使用Eq.(6)对M模型进行一轮从头开始的初始训练,以及使用Eq.(8)进行另外两轮的自我监督训练,我们将在下一节详细介绍。
3.实验
3.1.数据集和训练细节
我们在两个具有挑战性的合成到真实无监督域适应任务上评估了所提出的方法,其中我们在合成域(源)中有丰富的语义分割标签,但在真实域(目标)中没有。这两个合成数据集分别是GTA5[33]和SYNTHIA [34];真正的域数据集是CityScapes [9]
GTA5:由24,966张在视频游戏中合成的图像组成,原始图像大小为1914×1052。在训练过程中,我们将图像大小调整为1280×720,然后随机裁剪到1024×512。最初的GTA5提供了33个类的像素级语义注释,但我们使用cityscape中常见的19个类来与其他最先进的方法进行标准比较。
SYNTHIA:也与其他SOTA方法一致,我们使用SYNTHIA- rand - cityscapes子集,它有9400张带有注释的图像,原始分辨率为1280×760。这些图像在训练期间被随机裁剪到1024×512。同样,这16个常见类用于培训,但是对这16个类和13个类的子集都执行了评估,并遵循标准协议。
CityScapes:是一个在驾驶场景中收集的真实世界的语义分割数据集。我们使用来自训练集的2975幅图像作为目标域数据进行训练。我们在500张带有大量手动注释的验证图像上进行测试。CityScapes中的图片大小调整为1024×512,没有随机裁剪。两个域适应场景是GTA5→CityScapes和SYNTHIA→CityScapes。
注意,在所有实验中,我们通过Eq.(3)对[0,255]范围内的训练图像进行FDA处理,然后才进行均值减法,因为我们采用的FFT算法对于非负值是数值稳定的。
语义分割网络φw:我们在两种不同的架构上进行了实验,以展示FDA的鲁棒性,即带有ResNet101[18]骨干网的DeepLabV2[5],以及带有VGG16[40]骨干网的FCN-8s[26]。对于两个网络,我们使用与[23]中相同的初始化。同样,分割网络φw是我们方法中唯一的网络。
训练:我们在GTX1080 Ti GPU上进行培训;由于内存限制,在我们所有的实验中,批处理大小都设置为1。使用SGD使用ResNet101训练DeepLabV2,初始学习率为2.5e-4,并根据功率为0.9的“poly”学习率调度程序进行调整,权重衰减0.0005。对于VGG16的FCN-8s,我们使用初始学习率为1e-5的ADAM,每50000步学习率降低0.1倍,直到150000步。我们也像[23]一样应用早期停止。Adam的momentum是0.9和0.99。

表1。GTA5→CityScapes任务的消融研究。。第一部分(T=0)显示了分段网络φwβ在使用公式(6)从头开始训练时的性能。注意,随着β的变化,每个φwβ的性能保持相似,而表现最好的条目(下划线)在三个单独的网络中平均分布。当对不同vφwβ的预测进行平均(MBT(T=0))时,mIOU比所有组成的预测都有所改善。即使在第一轮(T=1)和第二轮(T=2)使用等式(8)进行自我监督训练后,情况也是如此。还要注意的是,简单地进行自我监督训练而不求平均值(MBT),相对于(β=0.09(T=0))的改善是微乎其微的(β=0.09(SST))。
3.2.单一尺度的FDA
我们首先在GTA5→CityScapes任务上用单尺度测试了FDA提出的方法。我们实例化了三个φwβ的DeepLabV2分割网络,其中β = 0.01, 0.05, 0.09,并使用公式(6)分别对它们进行训练。我们设置λent = 0.005和η = 2.0。我们报告了表1中CityScapes的验证集上跨语义类联合评分的均值交集(mIOU),其中T=0表示从零开始训练。从表1的第一部分可以看出,在FDA操作中,使用不同β训练的分割网络保持了相似的性能。这表明在使用式(6)进行训练时,FDA对β的选择具有稳健性。
此外,简单地使用Eq. (4) (β =0.09, λent =0)训练的φwβ=0.09网络,即在没有熵损失的情况下,比基线Cycada[19]高出4.54%,这表明FDA比基于两阶段图像平移的对抗域适应更好地管理可变性。其中,图像转换器从一个域训练到另一个域,并训练鉴别器来区分这两个域。
3.3.多波段转换(Multi-band Transfer:MBT)
我们可以利用目标域生成的伪标签应用自训练(SST)来进一步提高单个网络的性能。然而,正如预期的那样,增益是相当少的,从表1的第二部分,条目(β=0.09, SST)可以看出。相对于第一部分的(β=0.09, T=0), SST后的相对改善仅为0.9%。然而,当我们分析第一部分中使用不同β从头训练的网络时,我们可以看到,尽管性能对β的变化是稳健的,但表现最好的条目(下划线标注)是在类之间平均分布的,而不是被单一的网络所控制。这意味着对不同φwβ的预测进行平均。通过简单平均第一轮的预测(MBT, T=0),我们得到了比第一轮的最佳表现(β = 0.09, T=0)3.9%的更显著的相对改进。在表1的第三和第四部分的后续自我监督训练中,也一直观察到这一点。
3.4. MBT自我监督训练

图4。较大的β如果从零开始训练,泛化效果会更好,但当与自我监督训练相结合时,会诱发更多的偏差。
我们可以将由MBT(T=0)生成的伪标签视为地面真值标签,使用公式(8)来训练φwβ。然而,这是自我参照的,不能指望奏效。为了正则化,我们还对每个预测的置信值应用阈值。更具体地说,对于每一个语义类,我们都会满怀信心地接受前66%或0.9%以上的预测。在选项卡的第三和第四部分中。1.我们列出了第一轮SST(T=1)和第二轮SST(T=2)后每个φwβ的性能。
然而,如果我们检查SST(T=0,1,2)对每个φwβ的相对改善,我们会发现从头开始的训练回合(T=0)中表现最好的是φwβ=0.09,在第一轮SST(T=1)中表现最差,最后,在第二轮SST(T=2)之后,φwβ=0.01成为评分表现最好的,而不是φwβ=0.09。我们推测,较小的β将产生较少的变化(伪影),因此,适应的源数据集Ds→t当β较大时生成的数据集覆盖目标数据集的机会较小。然而,当使用伪标签进一步对齐两个域时,Ds→t偏差较小,因为其中心更接近目标数据集,且方差较小。我们在图4中说明了这一点。此外,这一观察结果为我们提供了设置β的参考,即如果我们只进行单尺度FDA,我们可能希望使用相对较大的β,然而,对于MBT,我们可能会逐渐增加φwβ预测的权重,使用较小的β。
3.5.基准
GTA5→CityScapes:
我们在表2中报告了我们的方法的定量评价。同样,我们可以观察到,通过实例化一个图像转换器和一个鉴别器,带有ResNet101的单尺度FDA (FDA)优于大多数采用对抗训练的方法[19,43,17,29]。激活熵最小化后,单尺度FDA (FDA- ent)实现了与[4,45]类似的性能,它在熵图的结构化输出上合并了空间先验或更复杂的对抗训练。通过使用多波段传输的SST,我们的方法取得了最好的性能(FDA-MBT)。注意,BDL[23]在对抗性设置中也执行SST,我们的方法比BDL提高了4.0%。我们的方法的优势也在表2第二节的VGG骨干上得到了展示。
SYNTHIA→CityScapes:
遵循[23]中的评估协议,我们使用VGG16骨干在16个类上报告我们的方法的mIOU,使用ResNet101骨干在13个类上报告我们的方法的mIOU。定量比较如表3所示。再次注意,我们的方法使用不同的骨干实现了最高的性能,并分别比第二执行者BDL[23]高出2.1%和3.9%。
3.6.定性结果

表2。GTA5→Cityscapes的定量比较。每个主干下的分数代表上界(在源域上训练和测试)。FDA:我们的单标度方法;FDA-ENT:同样是单尺度,但采用熵正则化;FDA- mbt:具有多重量表和自我监督培训的FDA。请注意,我们的方法始终在不同的主干上获得更好的性能。

表3。SYNTHIA→Cityscapes的定量比较。每个骨干下面的分数代表上界。对于VGG,我们在16个子类上求值,对于ResNet101, 16个类中有13个按照文献中的求值协议求值。未求值的类将被替换为’ - '。“我们的方法在不同的主干上始终比其他方法取得更好的性能。

图5。视觉对比。从左到右:来自CityScapes的输入图像,ground truth语义分割,BDL [23], FDA-MBT。请注意,FDA-MBT的预测通常更平滑,例如道路在第一排和第四排,墙在第三排。此外,FDA-MBT在精细结构上取得了更好的性能,例如第五排的极点。
我们在视觉上比较第二个执行者BDL[23],它使用与我们相同的分段网络骨干。从图5中可以看出,我们的模型预测的噪声要小得多,就像第一排的道路一样。不仅光滑,而且我们的方法还可以保持精细的结构,如第五排的极点。此外,我们的方法在稀有类上表现良好,例如第二排的卡车,第三和第四排的自行车。我们认为这是由于单尺度FDA的泛化能力,以及我们的多波段转移的正则化SST。
4. 讨论
我们提出了一个简单的领域对齐方法,它不需要任何学习,可以很容易地集成到一个学习系统中,将无监督领域适应转换为半监督学习。需要注意的是适当的正则化损失函数,为此我们提出了一个各向异性(Charbonnier)加权熵正则化器。通过多频带转移方案解决了自监督训练中的自自由问题,该方案不需要对具有复杂模型选择的学生网络进行联合训练。
结果表明,我们的方法不仅改进了预期的基线,而且实际上超过了当前的技术水平,后者虽然简单,但涉及的内容要多得多。这表明,由于低水平统计导致的一些分布偏差(众所周知,这种偏差会对不同领域的泛化造成严重破坏)很容易通过快速傅里叶变换捕获。此外,实数信号的频谱的傅里叶反变换保证是实数的,因为我们可以很容易地证明,由于被积函数的偏对称性虚部被抵消了;因此,使用我们的方法进行域适应的图像仍然驻留在真实的图像空间中。
对影响图像域的讨厌变量的鲁棒性仍然是机器学习中的一个难题,我们不声称我们的方法是最终的解决方案。然而,我们表明,在某些情况下,可能没有必要学习我们已经知道的东西,例如,图像的低级统计数据可以在不影响底层场景语义的情况下有很大的变化。这种预处理可以替代复杂的架构或费力的数据增强。在未来,我们希望看到我们的方法在其他领域适应任务中的应用。
参考文献
[1] Alessandro Achille, Matteo Rovere, and Stefano Soatto. Critical learning periods in deep networks. In International Conference on Learning Representations, 2019. 2
[2] Andres Bruhn and Joachim Weickert. Towards ultimate motion estimation: Combining highest accuracy with real-time performance. In Tenth IEEE International Conference on Computer Vision (ICCV’05) V olume 1, volume 1, pages 749– 755. IEEE, 2005. 4
[3] Fabio Maria Cariucci, Lorenzo Porzi, Barbara Caputo, Elisa Ricci, and Samuel Rota Bulò. Autodial: Automatic domain alignment layers. In 2017 IEEE International Conference on Computer Vision (ICCV), pages 5077–5085. IEEE, 2017. 2
[4] Wei-Lun Chang, Hui-Po Wang, Wen-Hsiao Peng, and WeiChen Chiu. All about structure: Adapting structural information across domains for boosting semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1900–1909, 2019. 2, 6, 7
[5] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Y uille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE transactions on pattern analysis and machine intelligence, 40(4):834–848, 2017. 2, 5
[6] Y uhua Chen, Wen Li, Xiaoran Chen, and Luc V an Gool. Learning semantic segmentation from synthetic data: A geometrically guided input-output adaptation approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1841–1850, 2019. 2, 3, 7
[7] Y uhua Chen, Wen Li, and Luc V an Gool. Road: Reality oriented adaptation for semantic segmentation of urban scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7892–7901, 2018. 7
[8] Y unjey Choi, Minje Choi, Munyoung Kim, Jung-Woo Ha, Sunghun Kim, and Jaegul Choo. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8789–8797, 2018. 2
[9] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3213–3223, 2016. 2, 5
[10] Gabriela Csurka. A comprehensive survey on domain adaptation for visual applications. In Domain adaptation in computer vision applications, pages 1–35. Springer, 2017. 2
[11] Mark Everingham, SM Ali Eslami, Luc V an Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes challenge: A retrospective. International journal of computer vision, 111(1):98–136, 2015. 2
[12] Geoffrey French, Michal Mackiewicz, and Mark Fisher. Self-ensembling for visual domain adaptation. In International Conference on Learning Representations, number 6, 2018. 3
[13] Matteo Frigo and Steven G Johnson. Fftw: An adaptive software architecture for the fft. In Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP’98 (Cat. No. 98CH36181), volume 3, pages 1381–1384. IEEE, 1998. 3
[14] Yaroslav Ganin and Victor Lempitsky. Unsupervised domain adaptation by backpropagation. In International Conference on Machine Learning, pages 1180–1189, 2015. 2
[15] Bo Geng, Dacheng Tao, and Chao Xu. Daml: Domain adaptation metric learning. IEEE Transactions on Image Processing, 20(10):2980–2989, 2011. 2
[16] Muhammad Ghifary, W Bastiaan Kleijn, Mengjie Zhang, David Balduzzi, and Wen Li. Deep reconstructionclassification networks for unsupervised domain adaptation. In European Conference on Computer Vision, pages 597– 613. Springer, 2016. 2
[17] Rui Gong, Wen Li, Y uhua Chen, and Luc V an Gool. Dlow: Domain flow for adaptation and generalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2477–2486, 2019. 2, 6, 7
[18] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 5, 7
[19] Judy Hoffman, Eric Tzeng, Taesung Park, Jun-Yan Zhu, Phillip Isola, Kate Saenko, Alexei Efros, and Trevor Darrell. Cycada: Cycle-consistent adversarial domain adaptation. In Proceedings of the 35th International Conference on Machine Learning, 2018. 1, 2, 5, 6, 7
[20] Judy Hoffman, Dequan Wang, Fisher Y u, and Trevor Darrell. Fcns in the wild: Pixel-level adversarial and constraint-based adaptation. arXiv preprint arXiv:1612.02649, 2016. 2
[21] Abhishek Kumar, Prasanna Sattigeri, Kahini Wadhawan, Leonid Karlinsky, Rogerio Feris, Bill Freeman, and Gregory Wornell. Co-regularized alignment for unsupervised domain adaptation. In Advances in Neural Information Processing Systems, pages 9345–9356, 2018. 2, 4
[22] Samuli Laine and Timo Aila. Temporal ensembling for semisupervised learning. arXiv preprint arXiv:1610.02242, 2016. 3
[23] Y unsheng Li, Lu Y uan, and Nuno V asconcelos. Bidirectional learning for domain adaptation of semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6936–6945, 2019. 3, 5, 6, 7, 8
[24] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014. 2
[25] Ming-Y u Liu, Thomas Breuel, and Jan Kautz. Unsupervised image-to-image translation networks. In Advances in neural information processing systems, pages 700–708, 2017. 2
[26] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3431–3440, 2015. 2, 5
[27] Mingsheng Long, Y ue Cao, Jianmin Wang, and Michael Jordan. Learning transferable features with deep adaptation networks. In International Conference on Machine Learning, pages 97–105, 2015. 2
[28] Yawei Luo, Ping Liu, Tao Guan, Junqing Y u, and Yi Yang. Significance-aware information bottleneck for domain adaptive semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, pages 6778– 6787, 2019. 2, 7
[29] Yawei Luo, Liang Zheng, Tao Guan, Junqing Y u, and Yi Yang. Taking a closer look at domain shift: Category-level adversaries for semantics consistent domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2507–2516, 2019. 2, 6, 7
[30] Massimiliano Mancini, Lorenzo Porzi, Samuel Rota Bulò, Barbara Caputo, and Elisa Ricci. Boosting domain adaptation by discovering latent domains. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3771–3780, 2018. 2
[31] Saeid Motiian, Marco Piccirilli, Donald A Adjeroh, and Gianfranco Doretto. Unified deep supervised domain adaptation and generalization. In Proceedings of the IEEE International Conference on Computer Vision, pages 5715–5725, 2017. 2
[32] Vishal M Patel, Raghuraman Gopalan, Ruonan Li, and Rama Chellappa. Visual domain adaptation: A survey of recent advances. IEEE signal processing magazine, 32(3):53–69, 2015. 2
[33] Stephan R Richter, Vibhav Vineet, Stefan Roth, and Vladlen Koltun. Playing for data: Ground truth from computer games. In European conference on computer vision, pages 102–118. Springer, 2016. 2, 5
[34] German Ros, Laura Sellart, Joanna Materzynska, David V azquez, and Antonio M Lopez. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3234–3243, 2016. 2, 5
[35] Chuck Rosenberg, Martial Hebert, and Henry Schneiderman. Semi-supervised self-training of object detection models. In Proceedings of the Seventh IEEE Workshops on Application of Computer Vision (WACV/MOTION’05)-V olume 1-V olume 01, pages 29–36, 2005. 3
[36] Kuniaki Saito, Y oshitaka Ushiku, and Tatsuya Harada. Asymmetric tri-training for unsupervised domain adaptation. In Proceedings of the 34th International Conference on Machine Learning-V olume 70, pages 2988–2997. JMLR. org, 2017. 2
[37] Swami Sankaranarayanan, Y ogesh Balaji, Arpit Jain, Ser Nam Lim, and Rama Chellappa. Learning from synthetic data: Addressing domain shift for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3752–3761, 2018. 2, 7
[38] Ozan Sener, Hyun Oh Song, Ashutosh Saxena, and Silvio Savarese. Learning transferrable representations for unsupervised domain adaptation. In Advances in Neural Information Processing Systems, pages 2110–2118, 2016. 2
[39] Rui Shu, Hung H Bui, Hirokazu Narui, and Stefano Ermon. A dirt-t approach to unsupervised domain adaptation. In Proc. 6th International Conference on Learning Representations, 2018. 2
[40] Karen Simonyan and Andrew Zisserman. V ery deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014. 5, 7
[41] Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5693–5703, 2019. 2
[42] Antti Tarvainen and Harri V alpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Advances in neural information processing systems, pages 1195–1204, 2017. 3, 4
[43] Yi-Hsuan Tsai, Wei-Chih Hung, Samuel Schulter, Kihyuk Sohn, Ming-Hsuan Yang, and Manmohan Chandraker. Learning to adapt structured output space for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7472–7481, 2018. 3, 6, 7
[44] Eric Tzeng, Judy Hoffman, Kate Saenko, and Trevor Darrell. Adversarial discriminative domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7167–7176, 2017. 2
[45] Tuan-Hung Vu, Himalaya Jain, Maxime Bucher, Matthieu Cord, and Patrick Pérez. Advent: Adversarial entropy minimization for domain adaptation in semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2517–2526, 2019. 3, 4, 6, 7
[46] Mei Wang and Weihong Deng. Deep visual domain adaptation: A survey. Neurocomputing, 312:135–153, 2018. 2
[47] Zuxuan Wu, Xintong Han, Yen-Liang Lin, Mustafa Gokhan Uzunbas, Tom Goldstein, Ser Nam Lim, and Larry S Davis. Dcan: Dual channel-wise alignment networks for unsupervised scene adaptation. In Proceedings of the European Conference on Computer Vision (ECCV), pages 518– 534, 2018. 2, 7
[48] Yanchao Yang, Dong Lao, Ganesh Sundaramoorthi, and Stefano Soatto. Phase consistent ecological domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2020. 3
[49] Yanchao Yang and Stefano Soatto. Conditional prior networks for optical flow. In Proceedings of the European Conference on Computer Vision (ECCV), pages 271–287, 2018. 3
[50] Zili Yi, Hao Zhang, Ping Tan, and Minglun Gong. Dualgan: Unsupervised dual learning for image-to-image translation. In Proceedings of the IEEE international conference on computer vision, pages 2849–2857, 2017. 2
[51] Fisher Y u and Vladlen Koltun. Multi-scale context aggregation by dilated convolutions. arXiv preprint arXiv:1511.07122, 2015. 2
[52] Werner Zellinger, Thomas Grubinger, Edwin Lughofer, Thomas Natschläger, and Susanne Saminger-Platz. Central moment discrepancy (cmd) for domain-invariant representation learning. arXiv preprint arXiv:1702.08811, 2017. 2
[53] Yang Zhang, Philip David, and Boqing Gong. Curriculum domain adaptation for semantic segmentation of urban scenes. In Proceedings of the IEEE International Conference on Computer Vision, pages 2020–2030, 2017. 2
[54] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2881–2890, 2017. 2
[55] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycleconsistent adversarial networks. In Proceedings of the IEEE international conference on computer vision, pages 2223– 2232, 2017. 2
[56] Yang Zou, Zhiding Y u, BVK Vijaya Kumar, and Jinsong Wang. Unsupervised domain adaptation for semantic segmentation via class-balanced self-training. In Proceedings of the European Conference on Computer Vision (ECCV), pages 289–305, 2018. 3, 7