Heterogeneous Parallel Programming(异构并行编程)学习笔记(五)
这里主要讲述两种并行计算模式,前缀求和(Prefix Sum)以及卷积(Convolution)。
1. Prefix Sum
前缀求和由一个二元操作符和一个输入向量组成,虽然名字叫求和,但操作符不一定是加法。先解释一下,以加法为例:
第一行是输入,第二行是对应的输出。可以看到,Output[1] = Input[0] + Input[1],而Output[length - 1]就是整个输入向量元素之和。
为什么要使用并行计算?假如用串行计算来计算输出向量,那么向量中越靠后的元素需要等待的时间越长。最后一个元素需要等待0 + 1 + 2 + ... + (n - 2) = (n - 1)(n - 2) / 2次加法计算后,才开始计算该元素。在很多情况下是不容许等待这么长时间的。因此需要并行计算。
一个很简单的想法是为输出向量每一个元素分配一个线程,该线程计算对应元素的值。这个方法有两个明显的问题。首先,这样产生的线程的计算负载非常不均衡,T1只运行一次加法,而T[length - 1]需要运行n - 1次加法。整个并行算法的时间由负载最高的线程决定,也就是O(N)。其次,输入向量中,第一个元素会被所有线程读取,第二个被n - 1个线程读取,总共下来,会有O(N * N)次读取。前面也提到过,内存读取是一种比较慢的操作,过多的内存读取会影响算法的性能。
上面的想法也说明一个现象:并行计算非常的简单,只要不考虑计算的性能。
2. Prefix Sum并行算法一
下图是一种改进后的算法:
从队首开始,首先与相邻元素相加,然后与距离2,距离4的元素相加,以此类推。可以证明其正确性。显而易见,此算法需要O(logN)步,和O(NlogN)次的加法操作。这里就不细讲该算法了,因为下面要介绍一种设计更良好的算法。但是,在数据量不大的时候(即logN不大),上述算法会比下面介绍的算法速度更快,可以考虑使用。
3. Prefix Sum并行算法二
前面介绍过Reduction模型,现在就可以加以利用,如下图所示:
我们用Reduction方法得到了一个输出向量,其元素为图中绿色的元素。这个输出向量只包含了部分的最终结果,因此还需要对其进行处理。未得到最终结果的原因是因为有部分的元素对始终没有得到相加的机会,因此接下来需要将缺失的加法计算补充进去。我们这里使用一个逆Reduction方法,如下所示:
上面的图说明了这样的一个逆Reduction过程。将上述两步放在一起就可以很容易看出其模式:
注意上图中已经是16元素的向量了,而不是8元素。从上图可以看到,逆Reduction第一步补充了Reduction中倒数第二步,依此类推,逆Reduction最后一步补充了Reduction中第一步,至此,所有的元素都得到了相加。
容易看出,上述算法总共需要2 * O(logN)步,以及O(N)次加法操作。相比之前的并行算法,得到了很大的优化。
4. Convolution
卷积也是很常用的一种计算模式。卷积计算方法如下:对输出数据中的每一个元素,它的值是输入数据中相同位置上的元素与该元素周边元素的值的加权和。卷积中有一个被称为卷积核(Kernel)或卷积码(Mask)的数据段,指定了周边元素的权值。为了避免混淆,以后都称为卷积码。计算如下图所示:
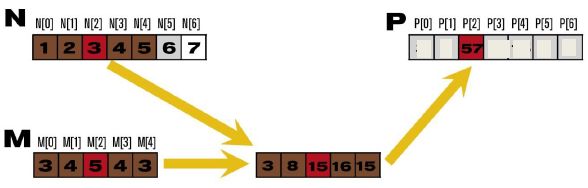
图中的M向量为卷积码,N向量为输入,P向量为输出。其中P[2] = N[0] * M[0] + ... + N[4] * M[4]。卷积计算需要考虑边界问题,如图,码长度为5,在计算前2个元素和后2个元素时需要的输入数据位置会越过边界。这时我们需要手动地添加被称为Ghost Cell的元素,该元素的值视情况而定,这里为了简便,取0值即可。
二维的卷积计算是一维卷积的推广,如下所示:
注意由此产生的Ghost Cell也是二维的。
5. Convolution并行算法
要并行计算卷积,一种很自然的想法就是为每一个输出元素建立一个线程,用以计算对应的值。这里可以用上前面介绍过的分块算法,同时,在计算时需要注意边界值的处理。分块如下所示:
这里取卷积码长度为5,分块大小为4,所以每一个Tile需要包含TILE_WIDTH + MASK_LENGTH - 1 = 8个元素,以满足分块内部元素的计算需要。首尾两个分块包含了Ghost Cell元素以及,和中间的分块一样,从相邻分块中读取的元素。所以,读入Share Memory的元素分为了三部分:一是从左邻块读取的该块的末尾元素,或者空元素;二是本块对应的元素;三是从右邻块读取的该块的开端元素,或者空元素。对应的代码如下:
// load left part
int n = Mash_Width / 2;
int index_left = (blockIdx.x - 1) * blockDim.x + threadIdx.x;
if (threadIdx.x >= blockDim.x - n) {
N_ds[threadIdx.x - (blockDim.x - n)] = (index_left < 0) ? 0 : N[index_left];
}
// load central part
N_ds[n + threadIdx.x] = N[blockIdx.x * blockDim.x + threadIdx.x];
// load right part
int index_right = (blockIdx.x + 1) * blockDim.x + threadIdx.x;
if (threadIdx.x < n) {
N_ds[n + blockDim.x + threadIdx.x] = (index_right >= Width) ? 0 : N[index_right];
}
这样就将每个分块的数据读入了Share Memory中,用以后面的计算。后面的卷积计算比较简单,在此不再赘述。
我们关心的是采用了分块方法后性能得到了多少提升,下面就来做一个简单的分析。
以上图为例,每一个P中的值都需要5次读取,如果没有用Share Memory,则需要8 × 5 = 40次的内存读取,而用了Share Memory后,只用了12次的内存读取,降低的比例为40 / 12 = 3.3。推广到一般情况,降低的比例为(Tile_Width * Mask_Length) / (Tile_Width + Maks_Length - 1)。
同样的方法,经过一定的修改后可以推广到二维分块计算。区别在于这里相邻的块包括了三个,以左上方为例,有左邻块,上邻块以及左上邻块。二维的分块计算其降低的比例更为显著。