博弈论Python仿真(二)
上一节《博弈论Python仿真(一)》传送门
一、Agenda
1、Prisoner’s dilemma game(囚徒困境)
2、When Finite number of games is played(玩有限次的博弈)
3、When Infinite number of games is played(无限次)
4、Payoff matrix in the two cases(收益矩阵)
5、Game visualization using sparklines(博弈可视化)
二、Axelrod
A Python library with the following principles and goals:
1、Enabling the reproduction of previous Iterated Prisoner's Dilemma research as easily as possible.
2、Creating the de-facto tool for future Iterated Prisoner's Dilemma research.
3、Providing as simple a means as possible for anyone to define and contribute new and original Iterated Prisoner's Dilemma strategies.
4、Emphasizing readability along with an open and welcoming community that is accommodating for developers and researchers of a variety of skill levels.
简单来说,这个库可以轻松地重复囚徒困境的研究,并提供简单策略。
GitHub项目地址:https://github.com/Axelrod-Python/Axelrod
Python中文网地址:https://www.cnpython.com/pypi/axelrod
需要 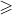 Python3.5
Python3.5
pip install axelrod三、囚徒困境收益矩阵
| Prisoner B | |||
| Cooperate(Deny) | Defect(Confess) | ||
| Prisoner A | Cooperate(Deny) | 3,3 |
0,5 |
| Defect(Confess) | 5,0 |
1,1 |
|
通过上一节已知每个囚犯的策略只有两个,分别是Confess和Deny,也就是坦白和否认。上面的表格不同于第一节的表格,这个表格是一个收益矩阵,这是axelrod的默认的收益矩阵。
通过上一节学到的博弈论的知识,通过Python仿真(或者手动穷举):
import nashpy
import numpy
a = numpy.array([[3, 0],
[5, 1]])
b = numpy.array([[3, 5],
[0, 1]])
rps = nashpy.Game(a, b)
print(rps)
equilibrium = rps.support_enumeration()
for eq in equilibrium:
print(eq)可以得到:
Bi matrix game with payoff matrices:
Row player:
[[3 0]
[5 1]]
Column player:
[[3 5]
[0 1]]
(array([0., 1.]), array([0., 1.]))可以看出纳什均衡是(Confess,Confess)。但是这显然不是最优策略。从合作方面来看,双方选择“认罪”策略,实际上是一种有缺陷的策略,双方都选择Confess其实不是最优的“合作”。而双方策略都选择“拒绝”,才意味着合作。
在上一节中,双方机会只有一次。现在,当游戏次数增加时,每个玩家都有一系列其他战略的可能性。可用的策略取决于游戏是finite/infinite(有限/无限)次。
四、有限次博弈
Case 1:Game is played for a finite number of times (say 10)
我们可以大胆的猜测一下,玩有限次数的博弈,那最终局之前的博弈,其实就是“游戏”啊,我随便怎么选择都行。但是最后一次,博弈完这次就没了,那没有合作的必要啊,我肯定要追求自己利益啊,所以这两个囚犯都会选择Confess,也就是坦白。
Hence, if the game is played a finite/fixed number of times, then each player will defect at each round. Players cooperate, thinking this will induce cooperation in the future. But if there is no chance of future play there is no need to cooperate now.
我们通过Python仿真一下:
(注意:Axelrod软件包中的合作策略是指“ C”和叛逃策略是指“ D”)
import axelrod
players = (axelrod.Defector(), axelrod.Defector())
match = axelrod.Match(players, turns=10)
match.play()
输出结果:
[(D, D), (D, D), (D, D), (D, D), (D, D), (D, D), (D, D), (D, D), (D, D), (D, D)]可以看到,这两个囚犯,每次都会选择叛逃,也就是不合作。
五、无限次博弈
Case 2: Game is played for an infinite number of times
当游戏玩无限次的时候,策略就会发生改变。如果囚犯A在一轮博弈中拒绝合作,那么囚犯B可以在下一轮的博弈中拒绝合作。不合作的收益低,然后就威胁着囚犯选择合作,然后采用帕累托策略,即选择否认(Deny)。
这里我们不得不提到一种策略就是“Tit-for-Tat”,也就是以牙还牙,一报还一报。你上一把怎么对我的,我这把就怎么对你。你上把和我合作,我这把也和你合作;你上把不和我合作,我这把也不和你合作。
该策略之所以起作用,就是它立即对拒绝和作者进行惩罚,立即对合作者进行奖励。这最终会产生(Deny,Deny)的帕累托效率。
Python仿真:
For the purpose of illustration let us play the game 20 times. Player A plays ‘Tit-for-tat” strategy and let Player B play a random strategy.(出于示例的目的,让我们玩游戏20次。玩家A扮演“ tit-for-tat”策略,让玩家B播放随机策略。)
import axelrod
players = (axelrod.TitForTat(), axelrod.Random())
match = axelrod.Match(players, turns=20)
match.play()
结果:
可能的结果一:
[(C, C), (C, C), (C, D), (D, D), (D, C),
(C, C), (C, C), (C, C), (C, D), (D, D),
(D, C), (C, C), (C, C), (C, D), (D, C),
(C, C), (C, D), (D, D), (D, C), (C, D)]可能的结果二:
[(C, D), (D, D), (D, D), (D, C), (C, D),
(D, C), (C, C), (C, D), (D, C), (C, D),
(D, C), (C, D), (D, D), (D, D), (D, C),
(C, C), (C, C), (C, C), (C, C), (C, C)]可能的结果三:
[(C, D), (D, D), (D, C), (C, C), (C, D),
(D, C), (C, D), (D, D), (D, D), (D, D),
(D, C), (C, C), (C, D), (D, D), (D, C),
(C, C), (C, D), (D, C), (C, D), (D, C)]等等结果……
可以看到,第二个玩家是随机选择规则;而玩家一是根据玩家二上一把选择了什么,对玩家二进行奖励(Confuse)或者惩罚(Deny)。
六、收益和博弈可视化
Axelrod库中的默认收益如下:
| Prisoner B | |||
| Cooperate(Deny) | Defect(Confess) | ||
| Prisoner A | Cooperate(Deny) | R,R |
S,T |
| Defect(Confess) | T,S |
P,P |
|
这里的:
R:奖励回报(Reward payoff)(+3)
P:惩罚收益(Punishment payoff)(+1)
S:上当/损失收益(Sucker/Loss payoff)(+0)
T:诱惑收益(Temptation payoff)(+5)
也就是和最上面一样的表格:
| Prisoner B | |||
| Cooperate(Deny) | Defect(Confess) | ||
| Prisoner A | Cooperate(Deny) | 3,3 |
0,5 |
| Defect(Confess) | 5,0 |
1,1 |
|
Case 1:玩10把,都是默认策略
Python:
import axelrod
players = (axelrod.Defector(), axelrod.Defector())
match = axelrod.Match(players, turns=10)
match.play()
print(match.scores())
print(match.sparklines())
结果:
[(1, 1),
(1, 1),
(1, 1),
(1, 1),
(1, 1),
(1, 1),
(1, 1),
(1, 1),
(1, 1),
(1, 1)]
print(match.sparklines())这行代码是可视化玩家A和B决策的,但是在这个Case中,两个玩家都是选择的defect,也就都是空白的。
Case 2:Game is played for an infinite number of times(20次)
Python:
import axelrod
players = (axelrod.Random(), axelrod.TitForTat())
match = axelrod.Match(players, turns=20)
match.play()
print(match.scores())
print(match.sparklines())结果:
控制台:



七、部分其他玩家策略举例
Case 1:Cooperator 和 Alternator
Axelrod还带有Cooperator和Alternator两个策略,玩家如果选择了Cooperator,那么策略一直是合作;如果玩家选择了Alternator,会一直在合作和拒绝直接切换。
Python:
import axelrod
players = (axelrod.Cooperator(), axelrod.Alternator())
match = axelrod.Match(players, turns=15)
match.play()
print(match.sparklines())
结果:
███████████████
█ █ █ █ █ █ █ █Case 2: TrickyCooper
官方描述:
一个棘手的合作者。
A cooperator that is trying to be tricky.
几乎总是合作,但会偶尔拒绝合作一次,来获得更好回报;三轮之后,如果对手没有背叛到最大历史深度10,则背叛。
Almost always cooperates, but will try to trick the opponent by defecting. Defect once in a while in order to get a better payout. After 3 rounds, if opponent has not defected to a max history depth of 10, defect.
Python:
示例1:(cooperator和trickyCooper的较量)
import axelrod
players = (axelrod.Cooperator(), axelrod.TrickyCooperator())
match = axelrod.Match(players, turns=15)
match.play()
print(match.sparklines())
结果:
███████████████
███ 可以看到,就前三次合作,后面一直在背叛。

示例2:(TitForTat 和 trickyCooper的较量)
Python:
import axelrod
players = (axelrod.TitForTat(), axelrod.TrickyCooperator())
match = axelrod.Match(players, turns=15)
match.play()
print(match.sparklines())
结果:
████ █████████
███ ██████████可以看到,第三次之后,trickyCooper背叛了,但是立马就被TitForTat以牙还牙,可以看出TitForTat还是比较克制trickyCooper的。
Case 3:TitFor2Tats
与TitForTat不同的是,第一次背叛我,我不背叛你;如果你还背叛我,sorry,我要以牙还牙了。
Python:
import axelrod
players = (axelrod.TitFor2Tats(), axelrod.TrickyCooperator())
match = axelrod.Match(players, turns=20)
match.play()
print(match.sparklines())结果:
█████ ████████████
███ ███████████ 
八、其他策略
总之,策略还有很多很多,感兴趣的可以仔细看看axelrod里面的player。
这里把代码粘贴上:
1、TitForTat系列
C, D = Action.C, Action.D
class TitForTat(Player):
"""
A player starts by cooperating and then mimics the previous action of the
opponent.
This strategy was referred to as the *'simplest'* strategy submitted to
Axelrod's first tournament. It came first.
Note that the code for this strategy is written in a fairly verbose
way. This is done so that it can serve as an example strategy for
those who might be new to Python.
Names:
- Rapoport's strategy: [Axelrod1980]_
- TitForTat: [Axelrod1980]_
"""
# These are various properties for the strategy
name = "Tit For Tat"
classifier = {
"memory_depth": 1, # Four-Vector = (1.,0.,1.,0.)
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
def strategy(self, opponent: Player) -> Action:
"""This is the actual strategy"""
# First move
if not self.history:
return C
# React to the opponent's last move
if opponent.history[-1] == D:
return D
return C
class TitFor2Tats(Player):
"""A player starts by cooperating and then defects only after two defects by
opponent.
Submitted to Axelrod's second tournament by John Maynard Smith; it came in
24th in that tournament.
Names:
- Tit for two Tats: [Axelrod1984]_
- Slow tit for two tats: Original name by Ranjini Das
- JMaynardSmith: [Axelrod1980b]_
"""
name = "Tit For 2 Tats"
classifier = {
"memory_depth": 2, # Long memory, memory-2
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
@staticmethod
def strategy(opponent: Player) -> Action:
"""Actual strategy definition that determines player's action."""
return D if opponent.history[-2:] == [D, D] else C
class TwoTitsForTat(Player):
"""A player starts by cooperating and replies to each defect by two
defections.
Names:
- Two Tits for Tats: [Axelrod1984]_
"""
name = "Two Tits For Tat"
classifier = {
"memory_depth": 2, # Long memory, memory-2
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
@staticmethod
def strategy(opponent: Player) -> Action:
"""Actual strategy definition that determines player's action."""
return D if D in opponent.history[-2:] else C
class DynamicTwoTitsForTat(Player):
"""
A player starts by cooperating and then punishes its opponent's
defections with defections, but with a dynamic bias towards cooperating
based on the opponent's ratio of cooperations to total moves
(so their current probability of cooperating regardless of the
opponent's move (aka: forgiveness)).
Names:
- Dynamic Two Tits For Tat: Original name by Grant Garrett-Grossman.
"""
name = "Dynamic Two Tits For Tat"
classifier = {
"memory_depth": float("inf"),
"stochastic": True,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
def strategy(self, opponent):
"""Actual strategy definition that determines player's action."""
# First move
if not opponent.history:
# Make sure we cooperate first turn
return C
if D in opponent.history[-2:]:
# Probability of cooperating regardless
return self._random.random_choice(
opponent.cooperations / len(opponent.history)
)
else:
return C
class Bully(Player):
"""A player that behaves opposite to Tit For Tat, including first move.
Starts by defecting and then does the opposite of opponent's previous move.
This is the complete opposite of Tit For Tat, also called Bully in the
literature.
Names:
- Reverse Tit For Tat: [Nachbar1992]_
"""
name = "Bully"
classifier = {
"memory_depth": 1, # Four-Vector = (0, 1, 0, 1)
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
@staticmethod
def strategy(opponent: Player) -> Action:
"""Actual strategy definition that determines player's action."""
return C if opponent.history[-1:] == [D] else D
class SneakyTitForTat(Player):
"""Tries defecting once and repents if punished.
Names:
- Sneaky Tit For Tat: Original name by Karol Langner
"""
name = "Sneaky Tit For Tat"
classifier = {
"memory_depth": float("inf"), # Long memory
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
def strategy(self, opponent: Player) -> Action:
"""Actual strategy definition that determines player's action."""
if len(self.history) < 2:
return C
if D not in opponent.history:
return D
if opponent.history[-1] == D and self.history[-2] == D:
return C
return opponent.history[-1]
class SuspiciousTitForTat(Player):
"""A variant of Tit For Tat that starts off with a defection.
Names:
- Suspicious Tit For Tat: [Hilbe2013]_
- Mistrust: [Beaufils1997]_
"""
name = "Suspicious Tit For Tat"
classifier = {
"memory_depth": 1, # Four-Vector = (1.,0.,1.,0.)
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
@staticmethod
def strategy(opponent: Player) -> Action:
"""Actual strategy definition that determines player's action."""
return C if opponent.history[-1:] == [C] else D
class AntiTitForTat(Player):
"""A strategy that plays the opposite of the opponents previous move.
This is similar to Bully, except that the first move is cooperation.
Names:
- Anti Tit For Tat: [Hilbe2013]_
- Psycho (PSYC): [Ashlock2009]_
"""
name = "Anti Tit For Tat"
classifier = {
"memory_depth": 1, # Four-Vector = (1.,0.,1.,0.)
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
@staticmethod
def strategy(opponent: Player) -> Action:
"""Actual strategy definition that determines player's action."""
return D if opponent.history[-1:] == [C] else C
class HardTitForTat(Player):
"""A variant of Tit For Tat that uses a longer history for retaliation.
Names:
- Hard Tit For Tat: [PD2017]_
"""
name = "Hard Tit For Tat"
classifier = {
"memory_depth": 3, # memory-three
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
@staticmethod
def strategy(opponent: Player) -> Action:
"""Actual strategy definition that determines player's action."""
# Cooperate on the first move
if not opponent.history:
return C
# Defects if D in the opponent's last three moves
if D in opponent.history[-3:]:
return D
# Otherwise cooperates
return C
class HardTitFor2Tats(Player):
"""A variant of Tit For Two Tats that uses a longer history for
retaliation.
Names:
- Hard Tit For Two Tats: [Stewart2012]_
"""
name = "Hard Tit For 2 Tats"
classifier = {
"memory_depth": 3, # memory-three
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
@staticmethod
def strategy(opponent: Player) -> Action:
"""Actual strategy definition that determines player's action."""
# Cooperate on the first move
if not opponent.history:
return C
# Defects if two consecutive D in the opponent's last three moves
history_string = actions_to_str(opponent.history[-3:])
if "DD" in history_string:
return D
# Otherwise cooperates
return C
class OmegaTFT(Player):
"""OmegaTFT modifies Tit For Tat in two ways:
- checks for deadlock loops of alternating rounds of (C, D) and (D, C),
and attempting to break them
- uses a more sophisticated retaliation mechanism that is noise tolerant
Names:
- OmegaTFT: [Slany2007]_
"""
name = "Omega TFT"
classifier = {
"memory_depth": float("inf"),
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
def __init__(
self, deadlock_threshold: int = 3, randomness_threshold: int = 8
) -> None:
super().__init__()
self.deadlock_threshold = deadlock_threshold
self.randomness_threshold = randomness_threshold
self.randomness_counter = 0
self.deadlock_counter = 0
def strategy(self, opponent: Player) -> Action:
"""Actual strategy definition that determines player's action."""
# Cooperate on the first move
if not self.history:
return C
# TFT on round 2
if len(self.history) == 1:
return opponent.history[-1]
# Are we deadlocked? (in a CD -> DC loop)
if self.deadlock_counter >= self.deadlock_threshold:
move = C
if self.deadlock_counter == self.deadlock_threshold:
self.deadlock_counter = self.deadlock_threshold + 1
else:
self.deadlock_counter = 0
else:
# Update counters
if opponent.history[-2:] == [C, C]:
self.randomness_counter -= 1
# If the opponent's move changed, increase the counter
if opponent.history[-2] != opponent.history[-1]:
self.randomness_counter += 1
# If the opponent's last move differed from mine,
# increase the counter
if self.history[-1] != opponent.history[-1]:
self.randomness_counter += 1
# Compare counts to thresholds
# If randomness_counter exceeds Y, Defect for the remainder
if self.randomness_counter >= self.randomness_threshold:
move = D
else:
# TFT
move = opponent.history[-1]
# Check for deadlock
if opponent.history[-2] != opponent.history[-1]:
self.deadlock_counter += 1
else:
self.deadlock_counter = 0
return move
class OriginalGradual(Player):
"""
A player that punishes defections with a growing number of defections
but after punishing for `punishment_limit` number of times enters a calming
state and cooperates no matter what the opponent does for two rounds.
The `punishment_limit` is incremented whenever the opponent defects and the
strategy is not in either calming or punishing state.
Note that `Gradual` appears in [CRISTAL-SMAC2018]_ however that version of
`Gradual` does not give the results reported in [Beaufils1997]_ which is the
paper that first introduced the strategy. For a longer discussion of this
see: https://github.com/Axelrod-Python/Axelrod/issues/1294. This is why this
strategy has been renamed to `OriginalGradual`.
Names:
- Gradual: [Beaufils1997]_
"""
name = "Original Gradual"
classifier = {
"memory_depth": float("inf"),
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
def __init__(self) -> None:
super().__init__()
self.calming = False
self.punishing = False
self.punishment_count = 0
self.punishment_limit = 0
def strategy(self, opponent: Player) -> Action:
"""Actual strategy definition that determines player's action."""
if self.calming:
self.calming = False
return C
if self.punishing:
if self.punishment_count < self.punishment_limit:
self.punishment_count += 1
return D
else:
self.calming = True
self.punishing = False
self.punishment_count = 0
return C
if D in opponent.history[-1:]:
self.punishing = True
self.punishment_count += 1
self.punishment_limit += 1
return D
return C
class Gradual(Player):
"""
Similar to OriginalGradual, this is a player that punishes defections with a
growing number of defections but after punishing for `punishment_limit`
number of times enters a calming state and cooperates no matter what the
opponent does for two rounds.
This version of Gradual is an update of `OriginalGradual` and the difference
is that the `punishment_limit` is incremented whenever the opponent defects
(regardless of the state of the player).
Note that this version of `Gradual` appears in [CRISTAL-SMAC2018]_ however
this version of
`Gradual` does not give the results reported in [Beaufils1997]_ which is the
paper that first introduced the strategy. For a longer discussion of this
see: https://github.com/Axelrod-Python/Axelrod/issues/1294.
This version is based on https://github.com/cristal-smac/ipd/blob/master/src/strategies.py#L224
Names:
- Gradual: [CRISTAL-SMAC2018]_
"""
name = "Gradual"
classifier = {
"memory_depth": float("inf"),
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
def __init__(self) -> None:
super().__init__()
self.calm_count = 0
self.punish_count = 0
def strategy(self, opponent: Player) -> Action:
"""Actual strategy definition that determines player's action."""
if len(self.history) == 0:
return C
if self.punish_count > 0:
self.punish_count -= 1
return D
if self.calm_count > 0:
self.calm_count -= 1
return C
if opponent.history[-1] == D:
self.punish_count = opponent.defections - 1
self.calm_count = 2
return D
return C
@TrackHistoryTransformer(name_prefix=None)
class ContriteTitForTat(Player):
"""
A player that corresponds to Tit For Tat if there is no noise. In the case
of a noisy match: if the opponent defects as a result of a noisy defection
then ContriteTitForTat will become 'contrite' until it successfully
cooperates.
Names:
- Contrite Tit For Tat: [Axelrod1995]_
"""
name = "Contrite Tit For Tat"
classifier = {
"memory_depth": 3,
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
def __init__(self):
super().__init__()
self.contrite = False
self._recorded_history = []
def strategy(self, opponent: Player) -> Action:
"""Actual strategy definition that determines player's action."""
if not opponent.history:
return C
# If contrite but managed to cooperate: apologise.
if self.contrite and self.history[-1] == C:
self.contrite = False
return C
# Check if noise provoked opponent
if self._recorded_history[-1] != self.history[-1]: # Check if noise
if self.history[-1] == D and opponent.history[-1] == C:
self.contrite = True
return opponent.history[-1]
class AdaptiveTitForTat(Player):
"""ATFT - Adaptive Tit For Tat (Basic Model)
Algorithm
if (opponent played C in the last cycle) then
world = world + r*(1-world)
else
world = world + r*(0-world)
If (world >= 0.5) play C, else play D
Attributes
world : float [0.0, 1.0], set to 0.5
continuous variable representing the world's image
1.0 - total cooperation
0.0 - total defection
other values - something in between of the above
updated every round, starting value shouldn't matter as long as
it's >= 0.5
Parameters
rate : float [0.0, 1.0], default=0.5
adaptation rate - r in Algorithm above
smaller value means more gradual and robust
to perturbations behaviour
Names:
- Adaptive Tit For Tat: [Tzafestas2000]_
"""
name = "Adaptive Tit For Tat"
classifier = {
"memory_depth": float("inf"),
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
world = 0.5
def __init__(self, rate: float = 0.5) -> None:
super().__init__()
self.rate = rate
self.world = rate
def strategy(self, opponent: Player) -> Action:
"""Actual strategy definition that determines player's action."""
if len(opponent.history) == 0:
return C
if opponent.history[-1] == C:
self.world += self.rate * (1.0 - self.world)
else:
self.world -= self.rate * self.world
if self.world >= 0.5:
return C
return D
class SpitefulTitForTat(Player):
"""
A player starts by cooperating and then mimics the previous action of the
opponent until opponent defects twice in a row, at which point player
always defects
Names:
- Spiteful Tit For Tat: [Prison1998]_
"""
name = "Spiteful Tit For Tat"
classifier = {
"memory_depth": float("inf"),
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
def __init__(self) -> None:
super().__init__()
self.retaliating = False
def strategy(self, opponent: Player) -> Action:
"""Actual strategy definition that determines player's action."""
# First move
if not self.history:
return C
if opponent.history[-2:] == [D, D]:
self.retaliating = True
if self.retaliating:
return D
else:
# React to the opponent's last move
if opponent.history[-1] == D:
return D
return C
class SlowTitForTwoTats2(Player):
"""
A player plays C twice, then if the opponent plays the same move twice,
plays that move, otherwise plays previous move.
Names:
- Slow Tit For Tat: [Prison1998]_
"""
name = "Slow Tit For Two Tats 2"
classifier = {
"memory_depth": 2,
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
def strategy(self, opponent: Player) -> Action:
"""Actual strategy definition that determines player's action."""
# Start with two cooperations
if len(self.history) < 2:
return C
# Mimic if opponent plays the same move twice
if opponent.history[-2] == opponent.history[-1]:
return opponent.history[-1]
# Otherwise play previous move
return self.history[-1]
@FinalTransformer((D,), name_prefix=None)
class Alexei(Player):
"""
Plays similar to Tit-for-Tat, but always defect on last turn.
Names:
- Alexei: [LessWrong2011]_
"""
name = "Alexei"
classifier = {
"memory_depth": float("inf"),
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
def strategy(self, opponent: Player) -> Action:
"""Actual strategy definition that determines player's action."""
if not self.history:
return C
if opponent.history[-1] == D:
return D
return C
@FinalTransformer((D,), name_prefix=None)
class EugineNier(Player):
"""
Plays similar to Tit-for-Tat, but with two conditions:
1) Always Defect on Last Move
2) If other player defects five times, switch to all defects.
Names:
- Eugine Nier: [LessWrong2011]_
"""
name = "EugineNier"
classifier = {
"memory_depth": float("inf"),
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
def __init__(self):
super().__init__()
self.is_defector = False
def strategy(self, opponent: Player) -> Action:
"""Actual strategy definition that determines player's action."""
if not self.history:
return C
if not (self.is_defector) and opponent.defections >= 5:
self.is_defector = True
if self.is_defector:
return D
return opponent.history[-1]
class NTitsForMTats(Player):
"""
A parameterizable Tit-for-Tat,
The arguments are:
1) M: the number of defection before retaliation
2) N: the number of retaliations
Names:
- N Tit(s) For M Tat(s): Original name by Marc Harper
"""
name = "N Tit(s) For M Tat(s)"
classifier = {
"memory_depth": float("inf"),
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
def __init__(self, N: int = 3, M: int = 2) -> None:
"""
Parameters
----------
N: int
Number of retaliations
M: int
Number of defection before retaliation
Special Cases
-------------
NTitsForMTats(1,1) is equivalent to TitForTat
NTitsForMTats(1,2) is equivalent to TitFor2Tats
NTitsForMTats(2,1) is equivalent to TwoTitsForTat
NTitsForMTats(0,*) is equivalent to Cooperator
NTitsForMTats(*,0) is equivalent to Defector
"""
super().__init__()
self.N = N
self.M = M
self.classifier["memory_depth"] = max([M, N])
self.retaliate_count = 0
def strategy(self, opponent: Player) -> Action:
"""Actual strategy definition that determines player's action."""
# if opponent defected consecutively M times, start the retaliation
if not self.M or opponent.history[-self.M :].count(D) == self.M:
self.retaliate_count = self.N
if self.retaliate_count:
self.retaliate_count -= 1
return D
return C
@FinalTransformer((D,), name_prefix=None)
class Michaelos(Player):
"""
Plays similar to Tit-for-Tat with two exceptions:
1) Defect on last turn.
2) After own defection and opponent's cooperation, 50 percent of the time,
cooperate. The other 50 percent of the time, always defect for the rest of
the game.
Names:
- Michaelos: [LessWrong2011]_
"""
name = "Michaelos"
classifier = {
"memory_depth": float("inf"),
"stochastic": True,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
def __init__(self):
super().__init__()
self.is_defector = False
def strategy(self, opponent: Player) -> Action:
"""Actual strategy definition that determines player's action."""
if not self.history:
return C
if self.is_defector:
return D
if self.history[-1] == D and opponent.history[-1] == C:
decision = self._random.random_choice()
if decision == C:
return C
else:
self.is_defector = True
return D
return opponent.history[-1]
class RandomTitForTat(Player):
"""
A player starts by cooperating and then follows by copying its
opponent (tit for tat style). From then on the player
will switch between copying its opponent and randomly
responding every other iteration.
Name:
- Random TitForTat: Original name by Zachary M. Taylor
"""
# These are various properties for the strategy
name = "Random Tit for Tat"
classifier = {
"memory_depth": 1,
"stochastic": True,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
def __init__(self, p: float = 0.5) -> None:
"""
Parameters
----------
p, float
The probability to cooperate
"""
super().__init__()
self.p = p
self.act_random = False
if p in [0, 1]:
self.classifier["stochastic"] = False
def strategy(self, opponent: Player) -> Action:
"""This is the actual strategy"""
if not self.history:
return C
if self.act_random:
self.act_random = False
try:
return self._random.random_choice(self.p)
except AttributeError:
return D if self.p == 0 else C
self.act_random = True
return opponent.history[-1]
2、Cooperator系列
C, D = Action.C, Action.D
class Cooperator(Player):
"""A player who only ever cooperates.
Names:
- Cooperator: [Axelrod1984]_
- ALLC: [Press2012]_
- Always cooperate: [Mittal2009]_
"""
name = "Cooperator"
classifier = {
"memory_depth": 0,
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
@staticmethod
def strategy(opponent: Player) -> Action:
"""Actual strategy definition that determines player's action."""
return C
class TrickyCooperator(Player):
"""
A cooperator that is trying to be tricky.
Names:
- Tricky Cooperator: Original name by Karol Langner
"""
name = "Tricky Cooperator"
classifier = {
"memory_depth": 10,
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
_min_history_required_to_try_trickiness = 3
_max_history_depth_for_trickiness = -10
def strategy(self, opponent: Player) -> Action:
"""Almost always cooperates, but will try to trick the opponent by
defecting.
Defect once in a while in order to get a better payout.
After 3 rounds, if opponent has not defected to a max history depth of
10, defect.
"""
if (
self._has_played_enough_rounds_to_be_tricky()
and self._opponents_has_cooperated_enough_to_be_tricky(opponent)
):
return D
return C
def _has_played_enough_rounds_to_be_tricky(self):
return len(self.history) >= self._min_history_required_to_try_trickiness
def _opponents_has_cooperated_enough_to_be_tricky(self, opponent):
rounds_to_be_checked = opponent.history[
self._max_history_depth_for_trickiness :
]
return D not in rounds_to_be_checked
3、Defector系列
C, D = Action.C, Action.D
class Defector(Player):
"""A player who only ever defects.
Names:
- Defector: [Axelrod1984]_
- ALLD: [Press2012]_
- Always defect: [Mittal2009]_
"""
name = "Defector"
classifier = {
"memory_depth": 0,
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
@staticmethod
def strategy(opponent: Player) -> Action:
"""Actual strategy definition that determines player's action."""
return D
class TrickyDefector(Player):
"""A defector that is trying to be tricky.
Names:
- Tricky Defector: Original name by Karol Langner
"""
name = "Tricky Defector"
classifier = {
"memory_depth": float("inf"), # Long memory
"stochastic": False,
"long_run_time": False,
"inspects_source": False,
"manipulates_source": False,
"manipulates_state": False,
}
def strategy(self, opponent: Player) -> Action:
"""Almost always defects, but will try to trick the opponent into
cooperating.
Defect if opponent has cooperated at least once in the past and has
defected for the last 3 turns in a row.
"""
if (
opponent.history.cooperations > 0
and opponent.history[-3:] == [D] * 3
):
return C
return D