yolo、voc格式数据集
文章目录
- 1、准备工作
- 2、需要这样的TXT
- 3、txt转xml,即yolo格式转voc格式
- 4、利用生成的xml生成4个txt,即拆分训练集和测试集
- 5、voc变为txt(yolo格式),生成每个类别对应的TXT,即数据集格式变为yolo格式
我的理解是:
yolo格式的数据集:每个图片对应一个txt文件的标签
voc格式的数据集:每张图片对应一个xml文件的标签
都有相应的标注工具。
1、准备工作
1.1、200类的,分类存放的数据集,每个文件夹内是具体的类别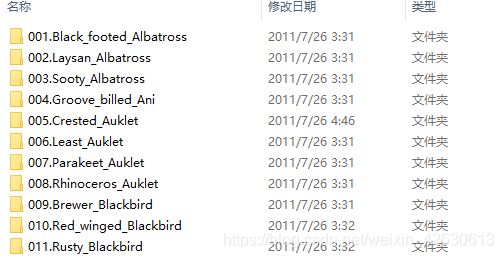
1.2、边框信息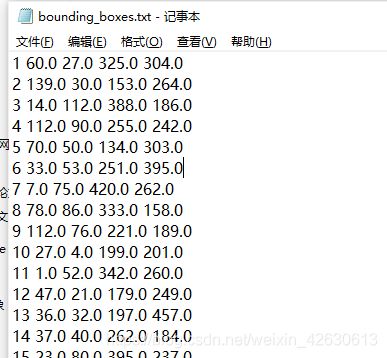
1.3、类别信息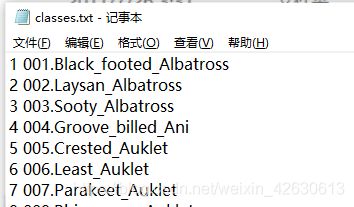
1.4、图片信息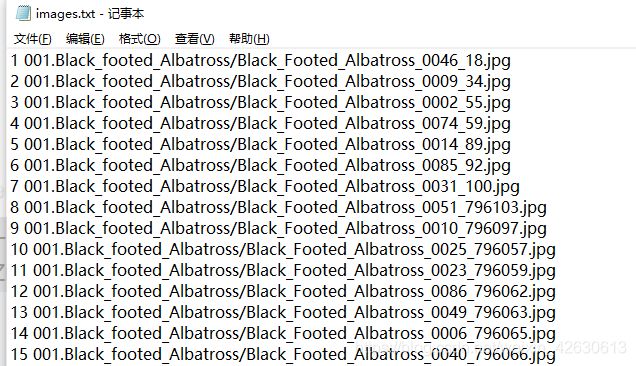
2、需要这样的TXT
2.1、只含类别的TXT
一个脚本其实可以实现,通过手动也可以实现,手动实现的方法:
可以将1.3的TXT复制到Excel中,选中,按.分列,然后将类别那列复制出来放到TXT里,这样可能会遇到别的编码的问题,具体遇到再说
最后得到:命名为voc_classes.txt
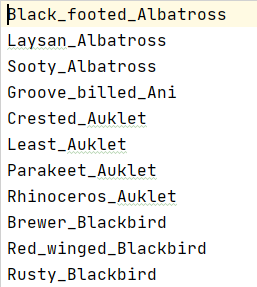
2.2 图片的位置即图片上目标位置的TXT
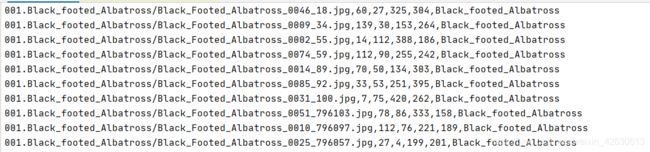
将1.2的边框信息和1.4的图片信息拼接到一起,还是用2.1中的那种Excel的方法进行
最后得到:命名为2010_train.txt
3、txt转xml,即yolo格式转voc格式
import os
import sys
from xml.etree import ElementTree
from xml.etree.ElementTree import Element, SubElement
from lxml import etree # 我用lxml
import copy
import codecs
import random
import cv2
from tqdm import tqdm
from PIL import Image
XML_EXT = '.xml'
ENCODE_METHOD = 'utf-8'
class PascalVocWriter:
def __init__(self, annotationDict): # annotationDict
self.annotationDict = annotationDict
def save(self, path=None): # 保存
"""
return:
生成一个VOC格式的xml,返回一个xml的根标签,以开始
"""
root = self.genXML() # 生成xml-----------top = Element('annotation')
if path is None: # 写进文件夹
out_file = codecs.open(self.annotationDict['filename'] + XML_EXT, 'w', encoding=ENCODE_METHOD)
# codecs.open(filepath, method, encoding)
else:
out_file = codecs.open(path, 'w', encoding=ENCODE_METHOD)
prettifyResult = self.prettify(root) # 转化格式
out_file.write(prettifyResult.decode('utf-8'))
out_file.close()
def genXML(self):
# 生成xml
top = Element('annotation')
folder = SubElement(top, 'folder')
folder.text = self.annotationDict['folder']
filename = SubElement(top, 'filename')
filename.text = self.annotationDict['filename']
path = SubElement(top, 'path')
path.text = self.annotationDict['path']
source = SubElement(top, 'source')
database = SubElement(source, 'database')
database.text = self.annotationDict['source']['database']
size_part = SubElement(top, 'size')
width = SubElement(size_part, 'width')
height = SubElement(size_part, 'height')
depth = SubElement(size_part, 'depth')
width.text = str(self.annotationDict['size']['width'])
height.text = str(self.annotationDict['size']['height'])
depth.text = str(self.annotationDict['size']['depth'])
segmented = SubElement(top, 'segmented')
segmented.text = str(self.annotationDict['segmented'])
for obj in self.annotationDict['objects']:
object_item = SubElement(top, 'object')
name = SubElement(object_item, 'name')
name.text = obj['name']
pose = SubElement(object_item, 'pose')
pose.text = obj['pose']
truncated = SubElement(object_item, 'truncated')
truncated.text = str(obj['truncated'])
difficult = SubElement(object_item, 'difficult')
difficult.text = str(obj['difficult'])
bndbox = SubElement(object_item, 'bndbox')
xmin = SubElement(bndbox, 'xmin')
xmin.text = str(obj['bndbox']['xmin'])
ymin = SubElement(bndbox, 'ymin')
ymin.text = str(obj['bndbox']['ymin'])
xmax = SubElement(bndbox, 'xmax')
xmax.text = str(obj['bndbox']['xmax'])
ymax = SubElement(bndbox, 'ymax')
ymax.text = str(obj['bndbox']['ymax'])
return top
def prettify(self, elem):
rough_string = ElementTree.tostring(elem, 'utf-8')# 改
# rough_string = etree.tostring(elem, 'utf8')
root = etree.fromstring(rough_string)
return etree.tostring(root, pretty_print=True, encoding=ENCODE_METHOD).replace(" ".encode(), "\t".encode())
# element, encoding=None, method=None, *,
# short_empty_elements=True
def loadTxt(txt_p):
with open(txt_p, 'r',encoding="utf-8") as f: # encoding="utf-8"加在这里有效
plist = [line[:-1] for line in f.readlines()]
return plist
def getGtBoxInfoDict(boxInfoTxt):
gtBoxInfoDict = {}
lines = loadTxt(boxInfoTxt)
for line in lines:
imgFilename, xmin, ymin, xmax, ymax, name = line.split(',')
boxInfoDict = {
'name': name,
'xmin': int(float(xmin)),
'ymin': int(float(ymin)),
'xmax': int(float(xmax)),
'ymax': int(float(ymax))
}
if gtBoxInfoDict.get(imgFilename, None) is None:
gtBoxInfoDict[imgFilename] = []
gtBoxInfoDict[imgFilename].append(boxInfoDict)
return gtBoxInfoDict
def createAnnotation(imgname, boxInfoList):
path_dir = './VOC2007/JPEGImages/' + imgname
img = Image.open(path_dir) # 1读图片
annotation = {
'folder': 'JPEGImages', 'filename': imgname,
'path': path_dir,
'source': {'database': 'Unknow'},
'size': {'width':img.size[0], 'height':img.size[1], 'depth': 3},
# 这里原代码有自己的赋值机制,对我的无效,我就改成了我的,用1读的图片进行取长宽操作,
# 深度都是彩色图,直接赋值3,如果不确定是否都为彩色可以用img.size[2]代替
'segmented': 0,
'objects': []
}
for boxInfo in boxInfoList:
obj = {
'name': boxInfo['name'],
'pose': 'Unspecified',
'truncated': 0,
'difficult': 0,
'bndbox': {
'xmin': boxInfo['xmin'],
'ymin': boxInfo['ymin'],
'xmax': boxInfo['xmax'],
'ymax': boxInfo['ymax']
}
}
annotation['objects'].append(obj)
return annotation
def main():
"""添加的utf8"""
# open("label/my.txt",encoding="gbk")
gt_txt = r'2012_train.txt' ##另一个.py生成的图片信息和位置信息放在一起的一个TXT##############################改了反斜杠#########
annotation_dir = r'./VOC2007/Annotation'
gtBoxInfoDict = getGtBoxInfoDict(gt_txt) #返回一个嵌套字典
for imgname, boxInfoList in gtBoxInfoDict.items():
# annotation = createAnnotation(imgname, boxInfoList)
# PascalVocWriter(annotation).save(os.path.join(annotation_dir, os.path.splitext(imgname)[0]+ XML_EXT))
annotation = createAnnotation(imgname, boxInfoList) #返回一个xml的东西
# createAnnotation(imgname, boxInfoList)
# my_path=r"os.path.splitext(imgname)[0]"
####################################################
data_list = imgname.split('/') # 我的图片里名称带路径,我要切开,如果你有更好的办法,哈哈求推荐
one = data_list[0]
two = data_list[1]
####################################################
PascalVocWriter(annotation).save(os.path.join(annotation_dir, one + os.path.splitext(two)[0] + XML_EXT))
# 切开路径为这里做准备
print(os.path.join(annotation_dir, one , os.path.splitext(two)[0] + XML_EXT))
# top = Element('annotation')
if __name__ == '__main__':
main()
生成的xml
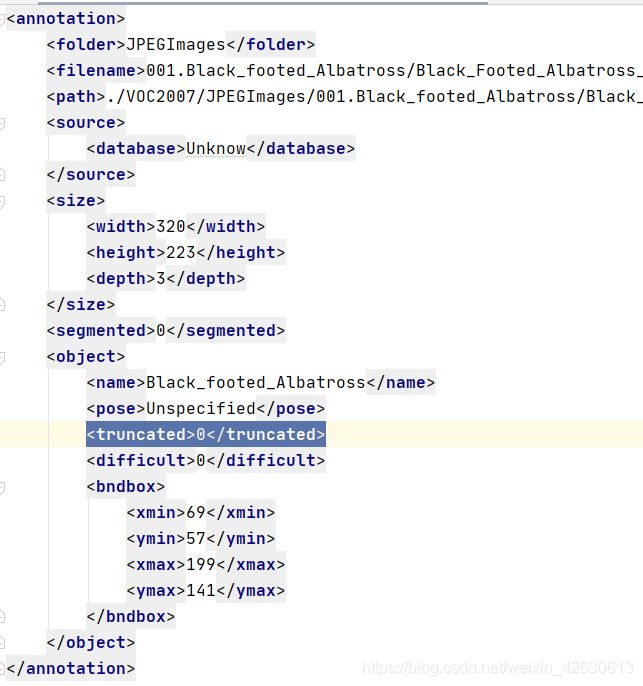
JPEGImages和Annotations中对应的文件名是一致的
4、利用生成的xml生成4个txt,即拆分训练集和测试集
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'D:/py_project/yolo2/VOCdevkit/VOC2007/Annotations'
txtsavepath = 'D:/py_project/yolo2/VOCdevkit/VOC2007/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('D:/py_project/yolo2/VOCdevkit/VOC2007/ImageSets/trainval.txt', 'w')
ftest = open('D:/py_project/yolo2/VOCdevkit/VOC2007/ImageSets/test.txt', 'w')
ftrain = open('D:/py_project/yolo2/VOCdevkit/VOC2007/ImageSets/train.txt', 'w')
fval = open('D:/py_project/yolo2/VOCdevkit/VOC2007/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
5、voc变为txt(yolo格式),生成每个类别对应的TXT,即数据集格式变为yolo格式
import xml.etree.ElementTree as ET
from read_class import csv_list ##生成类别列表1
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test', 'val']
##########生成的类别列表
class_path = "C:\\Users\\sy\\Desktop\\online\\my71000_665_1044839747790380683\\class.csv"##生成类别列表2
classes = csv_list(class_path) ##生成类别列表3
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('D:/py_project/yolo2/VOCdevkit/VOC2007/Annotations/%s.xml' % (image_id))
out_file = open('D:/py_project/yolo2/VOCdevkit/VOC2007/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('D:/py_project/yolo2/VOCdevkit/VOC2007/labels/'):
os.makedirs('D:/py_project/yolo2/VOCdevkit/VOC2007/labels/')
image_ids = open('D:/py_project/yolo2/VOCdevkit/VOC2007/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('D:/py_project/yolo2/VOCdevkit/VOC2007/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('D:/py_project/yolo2/VOCdevkit/VOC2007/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()