数据分析之Numpy
NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
NumPy 是一个运行速度非常快的数学库,主要用于数组计算,包含:
1)一个强大的N维数组对象 ndarray
2)广播功能函数
3)整合 C/C++/Fortran 代码的工具
4)线性代数、傅里叶变换、随机数生成等功能
一、创建数组的方法
1.用array函数创建数组
array函数可以将输入的数据(可以是列表,元组,数组以及其它序列)转换成numpy数组,如果不在array函数中的参数dtype中指明数据类型,python将自动推断。array默认复制所有输入数据
实例如下:
import numpy as np
list = [1,2,3]
array = np.array(list)
print(array)输出如下:
[1 2 3]这样,我们就完成了一个利用列表创建数组的操作。
2. 用arange函数创建数组
arange函数可以简单的认为是array(range())的一个简化表示,其用法和range相同,唯一的区别是range返回的是一个列表,而arange返回的是一个数组。
实例如下:
>>> import numpy as np
>>> np.arange(5)
array([0, 1, 2, 3, 4])
>>> np.arange(1,10,2)
array([1,3,5,7,9])3.用ones/zeros/full函数创建数组
ones/zeros/full函数可以创建一个数据相同的任意形状的数组,在此之前吗,我们要引入数组的形状的概念。
1)数组的形状
数组的形状是根据数组的维度和数据量决定的,通俗来说就是你把数组打印出来后的形状,而这个形状是以元组的形式来描述。
如果想查询数组的形状,可以用shape()函数,把要查询的数组作为参数即可。
一维数组的形状:(x,) #其中x为行数
二维数组的形状:(x,y) #其中x为行数,y为列数
三维数组的形状:(z,x,y) #其中x为行数,y为列数,z为块数(即层数,也可以理解为其中的二维数组的个数)
注意:三维数组的形状表达规则与一维数组和二维数组稍有不同,它的行数并非放在第一个参数的位置。
2)ones/zeros/full函数的使用
这三个函数的第一个参数都是所要创建的数组的形状
ones/zeros函数所创建出来的数组中的数据分别是整数1和0,因此一般他们没有需要输入的第二参数,而full函数则可以自定义数组中的数据是什么,因此它的第二个参数则是你所要填充的数据。
实例如下:
>>> import numpy as np
>>> np.ones((3,4))
array([[1., 1., 1., 1.],
[1., 1., 1., 1.],
>>> np.zeros((5,6))
array([[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0.]])
>>> np.full((2,3),8)
array([[8, 8, 8],
[8, 8, 8]])
4.使用ones_like/zeros_like/full_like函数创建数组
这三个函数其实和ones/zeros/full三个函数差别不大,如同字面意思,它们唯一的区别是把ones/zeros/full函数中需要的第一个参数,由数组的形状改成了任意数组,ones_like/zeros_like/full_like函数可以先提取出数组的形状来进行ones/zeros/full三个函数的创建,省略了用户去提取目标数组的形状这一步。
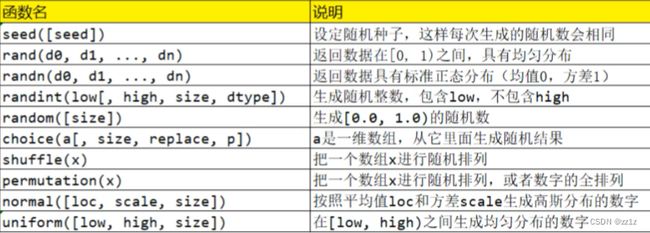
5.使用rondom模块进行对数组的创建
rondom模块是一个用于创建随机数的模块,当它应用于数组的创建时,自然就是可以用于创建随机数组。
注意:这里提到的rondom模块是numpy内置的一个rondom模块,和python自己的rondom模块稍有不同,因此我们想使用rondom模块创建数组时,需要加上numpy的调用(np.)。
二、改变数组的形状
如果想改变数组的形状,那么我们需要用到reshape函数。
1.reshape函数
reshape函数可以用于数组形状的修改,但它只能修改元素数相同的数组,如果修改前后的数组元素数不同,则该操作无法进行。
实例如下:
>>> import numpy as np
>>> np.arange(10).reshape(2,5)
array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])
可以把一个形状的数组改成另一个形状的数组
三、修改数组中的元素值
1)append函数(往数组的尾端添加元素)
append函数可以往数组的尾端增加元素。
实例如下:
>>> import numpy as np
>>> a = np.array([1,2,3])
>>> np.append(a,2)
array([1, 2, 3, 2])注意:numpy库中的append函数与python自带的append函数稍有区别,numpy库中的append函数不能对原数组进行修改,它会对原数组进行一个克隆,然后返回用克隆数组修改后的数组
2)insert函数 (往数组任意位置插入元素)
insert函数可以往数组中任意位置插入元素,用索引来指代对应的位置。
实例如下:
>>> import numpy as np
>>> a = np.array([1,2,3])
>>> np.insert(a,2,2)
array([1, 2, 2, 3])
注意:注意事项与append函数一致,numpy库中的insert函数不能对原数组进行修改,会返回修改后的数组。
3)repeat函数(对数组中的元素进行重复,克隆)
repeat函数可以对数组中的元素进行重复。
实例如下:
>>> import numpy as np
>>> a = np.array([1,2,3])
>>> a.repeat(3)
array([1, 1, 1, 2, 2, 2, 3, 3, 3])注意:与上面函数的注意事项一致,repeat函数不能对原数组进行修改,会返回修改后的数组。
4)put函数(对数组中任意位置的元素进行修改)
put函数可以对数组中任意位置的元素进行修改(重新赋值),用索引来指代对应的位置。
import numpy as np
>>> a = np.array([1,2,3])
>>> a.put(1,9)
>>> a
array([1, 9, 3])注意:put函数可以直接在原数组上面进行修改,因此put函数没有返回值。
四、数组的四则运算
数组之间的四则运算非常简单,就是将各个位置上的对应元素分别进行运算。
实例如下:
import numpy as np
>>> a = np.array([[1,2,3,4],[1,2,3,4]])
>>> b = np.array([[4,3,2,1],[4,3,2,1]])
>>> a + b
array([[5, 5, 5, 5],
[5, 5, 5, 5]])
>>> a * b
array([[4, 6, 6, 4],
[4, 6, 6, 4]])1.广播原则(低维数组与高维数组之间的运算规则)
广播原则指的是当低维数组和高维数组进行运算时,由于维度的不同,低维数组会不断的对自身进行克隆,直到维度与高维数组相同,然后进行运算。
实例如下:
import numpy as np
>>> a = np.array([1,2,3])
>>> b = np.array([[4,5,6],[7,8,9]])
>>> a + b
array([[ 5, 7, 9],
[ 8, 10, 12]])
>>> a * b
array([[ 4, 10, 18],
[ 7, 16, 27]])
五、布尔索引
布尔索引指的是用布尔值来作为索引对数组进行切片,对应元素为True的则返回,对应位置为False的则去除。
实例如下:
>>> import numpy as np
>>> a = np.arange(10)
>>> a
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> b = a > 5
>>> b
array([False, False, False, False, False, False, True, True, True,
True])
>>> a[b]
array([6, 7, 8, 9])
也来对切片后的进行比较符的筛选,这样可以达到只修改部分元素的效果。
六、神奇索引
神奇索引可以理解为是一个用一个索引集来作为一个数组的索引,而这个索引集是以数组(列表)的形式储存的。相当于依次对索引集中的每个索引进行数组的切片,最后再返回由所有切片组成的一个总的数组切片。
1.同维度的神奇索引和低维度的神奇索引
同维度神奇索引非常好理解,就是把索引集的每个索引一 一取出进行提取。下面直接用实例说明:
>>> import numpy as np
>>> A = np.array([3,6,7,9,5,2,7])
>>> A[[2,3,5]]
array([7, 9, 2])
>>> import numpy as np
>>> A = np.arange(32).reshape(8,4)
>>> A
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31]])
>>> A[[1,5,7,2],[0,3,1,2]]
array([ 4, 23, 29, 10])
当使用二维神奇索引来提取时,如第二个例子,第一个数组(列表)是作为行数组,第二个数组(列表)是作为列数组,而把两个数组(列表)的对应元素便作为行索引和列索引来分别对目标数组进行提取,最后得到了一个一维数组。
2.低维度的神奇索引(本质还是同维度的神奇索引)
其实不存在什么低纬度的神奇索引,本质是将别的维度用:号代替,:号代表着所有,下面用实例说明:
>>> import numpy as np
>>> A = np.arange(32).reshape(8,4)
>>> A
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23],
[24, 25, 26, 27],
[28, 29, 30, 31]])
>>> A[[4,3,0,6]]
array([[16, 17, 18, 19],
[12, 13, 14, 15],
[ 0, 1, 2, 3],
[24, 25, 26, 27]])3.高维度的神奇索引(重点)
如果说在前面的所有神奇神奇索引中,我们都可以使用列表来代替数组进行神奇索引的操作,但在高维度的神奇索引中,只能使用数组来作为神奇索引进行操作,这就意味着我们需要先创建一个数组类型,再将其作为神奇索引使用,下面来看实例:
>>> import numpy as np
>>> A = np.arange(10)
>>> A
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> B = np.array([[0,2],[1,3]])
>>> B
array([[0, 2],
[1, 3]])
>>> A[B]
array([[0, 2],
[1, 3]])
如上所示,高维的神奇索引会先变成多个与目标数组同维的数组,然后分别进行同维的神奇索引,再最后整合成高维的数组。
之所以这个时候只能使用数组作为神奇索引而不是列表,是因为数组具有列表不具有的迭代性,这也是数组的一个重要性质,这也是引入数组这一数据集的重要性。