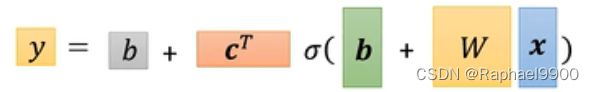【学习3】python后续知识补足和深度学习模型
·自定义函数
在Python语言中,除内建函数外的其他类型函数通常被称为第三方函数。内建函数可以直接使用,第三方函数需要使用import命令导入相应的库才能使用。对于自定义函数,其定义和调用可以在同一个文件中,也可分离成不同的文件。
在同一个文件夹下面有两个文件:
其中,demo2.py文件里面含有一个func(src)的函数

在demo1.py文件中调用demo2.py文件的func函数可以这样:
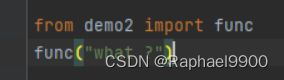
·在Python语言中,还可以把函数名赋给一个变量,相当于给这个函数起了一个“别名”。abs没有小括号,因此加了小括号相当于调用函数了。
a = abs
print(a(-1))#1
(2)函数参数
· 参数种类
函数参数分为可变类型和不可变类型,其调用结果是不同的。
1)可变类型:类似c++的引用传递,如列表、字典等。如果传递的参数是可变类型,则在函数内部对传入参数的修改会影响到外部变量。
2)不可变类型:类似c++的值传递,如整数、字符串、元组等。如果传递的参数是不可变类型,则在函数内部对传入参数的修改不会影响到外部变量。
可变类型:
lis = ["a", "b", "c"]
def funcu(list):
list.append(["d", "e", "f", "g"])
print("yes")
funcu(lis)
print(lis)
yes
['a', 'b', 'c', ['d', 'e', 'f', 'g']]
·默认参数
编写函数时,可给每个形参指定默认值。在调用函数时,如果给形参提供了实参,Python语言将使用指定的实参值;否则,将使用形参的默认值。给形参指定默认值后,可在函数调用中省略相应的实参。
def descro(name, age='18'):
print("name: " + name)
print("age: " + age)
descro('joan', '30') # 第二个参数得是字符串,是数值会报错
descro('abc')
name: joan
age: 30
name: abc
age: 18
默认参数很有用,但使用时要牢记一点,默认参数必须指向不可变对象,否则会出现错误
def test_add(a=[]):
a.append('END')
return a
print(test_add([1, 2, 3]))
print(test_add(['a', 'b', 'c']))
print(test_add())
print(test_add())
print(test_add())
[1, 2, 3, 'END']
['a', 'b', 'c', 'END']
['END']
['END', 'END']
['END', 'END', 'END']
从上述代码可以看出,默认参数是空列表[],但是函数test_add()似乎每次都“记住了”上次添加了’END’后的list。这是因为在Python语言中,函数在定义的时候,默认参数H的值就被计算出来了,即[]。因为默认参数H也是一个变量,它指向对象[]。每次调用该函数,如果改变了H的内容,则下次调用时,默认参数的内容就变了,不再是函数定义时的[]了。
·不定长参数
在Python语言中,函数还可以定义不定长参数,也叫可变参数。开发者可以把不指定长度的参数作为一个list或tuple传进来。
def calc(numbers):
sum = 0
for n in numbers:
sum = sum + n
return sum
print(calc([1, 2, 3])) # 结果是6
print(calc([1, 2, 3,4])) # 结果是10
在Python语言中,可以在函数参数前面添加“*”号把该参数定义为不定长参数。
def calc(*numbers):
sum = 0
for n in numbers:
sum = sum + n
return sum
print(calc(1, 2, 3, 4))
print(calc())
num = [1, 2, 3]
print(calc(*num))
·关键字参数
*表示不定长参数
**表示不定长的关键字参数
·匿名函数
Python语言经常使用lambda来创建匿名函数。lambda [arg1[,arg2],....argn]]:expression
5、类和对象
·类的创建
Python语言中,使用class关键字来创建类
class ClassName(bases):
# class documentation string 类文档字符串,对类进行解释说明
class_suite
class是关键字,bases是要继承的父类,默认继承object类。
class documentation string是类文档字符串,一般用于类的注释说明。class_suite是类体,主要包含属性和方法。
Python的类分为以下两种:
经典类:Python2.x中类定义的默认方式,不继承object类,其内部由属性和方法组成。class A: pass
新式类:Python3.x中类定义的默认方式,必须继承object方法。class A(object): pass
·新式类添加了一些内置属性和方法
__name__ :属性的名字
__doc__ :属性的文档字符串
__get__(object) :获取对象属性值的方法
__set__(object, value) :设置对象属性值的方法
__delete__(object, value) :删除对象属性的方法
·内置类属性:
__name__ :属性的名字
__doc__ :属性的文档字符串
_bases_:所有父类构成的元祖
_dict_:类的属性
_module_:类定义所在的模块
_class_:实例对应的类
·内置示例属性:
_dict_:实例对象的属性
_class_:实例对象所属的类名
·对象的创建
people = People("李四", 20, "50kg") # 实例化一个对象
Python语言对于属性的设置采用“类.属性 = 值”或“实例.属性 = 值”的形式。
Python语言中的属性操作遵循三个规则:
(1)属性的获取是按照从下到上的顺序来查找属性;
(2)类和实例是两个完全独立的对象;
(3)属性设置是针对实例本身进行的。
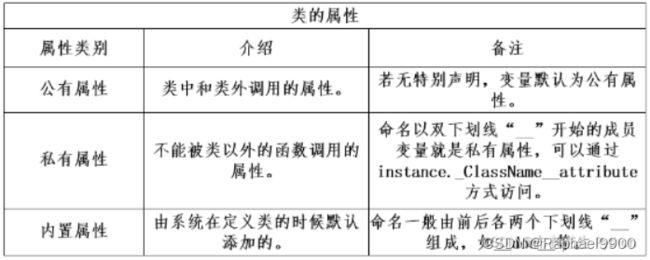
属性按使用范围分为公有属性和私有属性

·类方法和静态方法原理上有以下区别:
(1)静态方法不能使用self的方式调用。
(2)静态方法调用时会预先将类中用到的属性和方法进行加载,而类方法则是随调随用。因此,类方法相比静态方法具有不占资源的优势,但是速度不及静态方法。
(3)静态方法调用类中的属性时需要使用“类名.属性”的格式。
·内部类
内部类:类的内部定义的类,主要目的是为了更好抽象现实世界。
内部类调用有两种方式。
(1)直接使用外部类调用内部类;
(2)先对外部类进行实例化,然后再实例化内部类。
·魔术方法
在Python语言中,所有以双下划线“__”包起来的方法,都统称为“魔术方法”。 这些方法在实例化时会自动调用,
魔术方法中的“__init__()”方法一般叫做构造函数,用于初始化类的内部状态和参数。 如果不提供,Python语言会给出一个默认的“__init__()”方法 魔术方法中的“__ del __()”函数叫做析构函数,用于释放对象占用的资源。“__del__()”函数是可选的, 如果不提供,Python语言会在后台提供默认析构函数。
调用析构函数的两种方法:
对象.__del__() # 调用析构函数
del 对象
当对象自动执行析构函数“A.del()”后,对象仍然存在,但是在调用“del A”,后,对象就已经被回收删除,无法再次使用。
·类间关系
依赖关系:用实例方法执行某个功能时,如果需要使用另一个类的实例的方法来完成,则称这两个类之间存在关联关系。
class Person():
def play(self, tools):
tools.run()
print("很开心,能玩游戏了")
class Phone():
def run(self):
print("手机开机,可以运行")
phone = Phone()
p = Person()
p.play(phone)
- 基本技能
- python文件读写的方式
·打开一个文件:
f = open(file,mode,encoding=‘utf8’)#文件路径,打开模式,文件编码
·文件读取
file = '1.txt'
file_obj = open(file,‘r’,encoding='utf-8')
content = file_obj.read()
print(content)
file_obj.close()
for line in file_obj.readlines(): #读取多行
·文件的写入write() 和 writelines()
f1 = open('1.txt', 'w')
f1.write("123")
fl.close()
--------------
f1 = open('1.txt', 'w')
f1.writelines(["1\n", "2\n", "3\n"])
fl.close()
机器学习/深度学习
- 如何知道一个函数呢?(linear model)
如下是训练步骤:
第一步,先进行函数预测,比如说点阅人数预测函数为:y=b+wx(model模型,x为已知点阅数,y为想要预测的点阅数,b和w为未知数,w是weight,b是bias)。
第二步,定义一个loss(这个loss是一个函数Loss(b,w)),输入是b和w。如何知道参数设置的是否好呢?那就需要用到过去的点阅次数计算loss。已知2017年1月2日的预测值为y,真实值(label)为y*,计算损失e=|y-y*|(用绝对值计算差距MAE;如果是用差值的平方算出的e,那就是MSE![]() )。然后不断计算误差,求和取平均之后这个L就是我们的loss。改变不同的b和w得到的等高线图是Error Surface.
)。然后不断计算误差,求和取平均之后这个L就是我们的loss。改变不同的b和w得到的等高线图是Error Surface.
第三步,最优化,寻找一组w和b能使loss最小。这里用到的最优化optimization方法是gradient descent。做法:假设只有一个未知数w的时候,首先随机选取一个初始w0,计算微分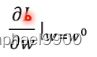 (斜率)。除了斜率会影响步伐之后,还有n(learning rate学习速率,n由自己自行设置的大小)会影响步伐。在机器学习的过程中需要自己设定的东西,叫hyperparameters。在找到斜率为0的时候,就会出现局部最优值(从图中可以看出,这个并不是全局最低点,因为gradient descent会出现local minima,找到的不是global minima)。现在取消假设,现在有两个未知数w和b的时候,也是计算微分(
(斜率)。除了斜率会影响步伐之后,还有n(learning rate学习速率,n由自己自行设置的大小)会影响步伐。在机器学习的过程中需要自己设定的东西,叫hyperparameters。在找到斜率为0的时候,就会出现局部最优值(从图中可以看出,这个并不是全局最低点,因为gradient descent会出现local minima,找到的不是global minima)。现在取消假设,现在有两个未知数w和b的时候,也是计算微分(
 ),然后
),然后 计算到0,不断更新w和b,最后找到最好的w和b。
计算到0,不断更新w和b,最后找到最好的w和b。

但是这种模型的预测并不是很好,所以需要进行改进。
当考虑多天的时候,比如说7天、28天、56天,预测值确实更好了。

应该是这种线性模型太简单了,我们预测的真实结果并不是一个线性的模型。线性模型有很严重的限制,这种称作model bisa。
当真实结果是折线的时候,如图红色线,那么我们可以用一个常数项加三个蓝色折线组成。
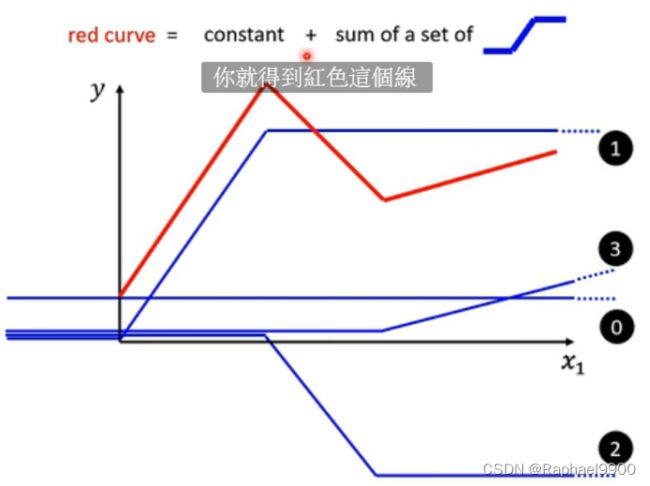
根据【学习1】,我们可以得到更好的模型: