源自双11混部实战,Koordinator 如何保障应用服务质量?
作者:张佐玮、韩柔刚 Koordinator 团队
在洪峰流量下,如何确保应用的服务质量不受影响的同时,最大限度提升资源利用率,是考验混部技术成熟度的关键。本文将展开介绍Koordinator在资源隔离,单机QoS保障,以及应用干扰检测方面的设计实现和进展。
一、背景
今年双十一已经正式落下帷幕,转眼间,这个节日已经走过了14个年头。对阿里巴巴的技术人员来说,每年的双十一都是一次大考,是评价一项技术成熟度的关键因素;同时,双十一又是一个绝佳的孵化平台,各种极致的指标要求不断催生着新技术的演进和创新。
离线混部系统作为阿里巴巴的核心项目,自2014年起已经连续通过了8年双十一的考核,历经三轮大的架构升级,在去年完成了向“统一调度技术”的全面升级。目前,阿里巴巴实现全业务规模超千万核的云原生混部,混部 CPU 利用率超 50%,助力 2022 年“双11”计算成本大幅下降。
二、Koordinator的发展历程
基于在混部技术领域多年的实践经验,阿里巴巴正式开源了 Koordinator 项目,帮助企业快速收获云原生混部带来的技术红利,提高全局的资源利用效率。Koordinator 有效解决了广大企业在应用混部的过程中面临的两大挑战:如何将应用接入到混部平台;以及如何让应用在平台上能够稳定、高效的运行。
Koordinator 开源社区自2022年4月正式启动以来,阿里巴巴会同业界多个伙伴一起参与共建,贡献了众多的想法、代码和场景,推动了 Koordinator 项目的成熟发展。日前最新发布的 1.0 版本,在标准化、通用化上做出了更多的突破。
在双十一这种洪峰流量下,如何能够确保应用的服务质量不受影响的同时,最大限度提升资源利用率,是考验混部技术成熟度的关键。
三、什么是 Koordinator
双十一大促中,集群的资源利用率进一步提升,在应用间会存在更多潜在的资源竞争,众多资源隔离机制和单机 QoS 保障策略在过去一次或多次大促实践中得到了考验和锤炼,我们在不断的反馈中逐步迭代出更成熟的方案,标准化输出到 Koordinator 中。
3.1 资源优先级和 QoS
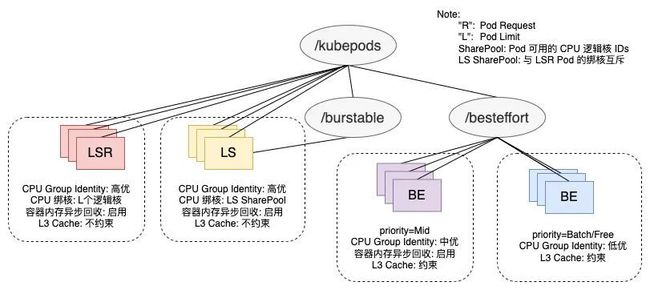
阿里巴巴的混部系统基于不同工作负载类型的资源需求特征,将应用按优先级(Priority)和服务质量(QoS)划分为出不同的资源保障等级。其中,Priority 表示应用满足资源的先后顺序,比如在调度队列的相对位置,以及节点上资源不足时保障运行的先后,包含了 Prod、Mid、Batch 和 Free 四个 PriorityClass,对应不同的资源调度模型,低优先级能够复用高优先级已分配但未使用的资源。QoS 表示应用在节点上运行时得到的物理资源质量,包含了 LSR(Latency-Sensitive Reserved)、LS(Latency-Sensitive)和 BE(Best Effort),对应着节点上物理资源分配的差异,例如 CPU 绑核、内核调度优先级、LLC 资源划分等。
不同优先级应用间的资源复用带来了混部后的利用率提升,另一方面也对应用资源质量的保障带来了挑战,因此需要在混部系统中合理地规划应用的 Priority 和 QoS 等级。例如,电商等在线服务类应用对响应延迟比较敏感,业务的延时抖动是难以忍受的,对应 LS 或 LSR(LSR 针对对绑核编排有要求的应用)的 QoS 等级,但其日常的 CPU 利用率通常不高,调度后往往存在一部分空闲资源,比较适合分配 Prod 资源;大数据计算等离线任务类应用对短周期的响应延迟不敏感,能够使用 BE 的 QoS 等级,而对资源量的有一定需求,适合分配 Batch 资源。因此考虑将这两类应用混部起来,将电商应用声明为 Prod +LS/LSR(在线),将大数据应用声明为 Batch+BE(离线)。在购物高峰期优先保障电商应用(Prod)的响应延迟,压制大数据作业(Batch)的运行,在夜晚等低谷期回收(Reclaim)更多资源给大数据作业运行。
3.2 资源保障策略
面对大促的资源水位上涨,机器的物理资源压力增大,电商相关应用的服务质量需要得到重点保障,以避免在峰值流量来临之际有业务 RT 的损失。在离线混部系统针对应用容器的 Priority 和 QoS 等级,设置差异化的资源隔离配置以及 QoS 保障策略。CPU 方面,通过内核自研的 Group Identity 机制,针对不同 QoS 等级设置内核调度的优先级,优先保障 LSR/LS 的 cpu 调度,允许抢占 BE 的 CPU 使用,以达到最小化在线应用调度延迟的效果;此外,对于 LS 应用的突发流量,提供了 CPU Burst 策略以规避非预期的 CPU 限流。内存方面,由于容器 cgroup 级别的直接内存回收会带来一定延时,LS 应用普遍开启了容器内存异步回收能力,规避同步回收带来的响应延迟抖动。除此之外,针对末级缓存(Last-Level Cache,LLC)这种共享资源,为了避免大数据等 BE 应用大量刷 Cache 导致 LS/LSR 应用的 Cache Miss Rate 异常增大,降低流水线执行效率,引入了 RDT 技术来限制 BE 应用可分配的 Cache 比例,缩小其争抢范围。
这些资源隔离配置与 QoS 策略看似清晰直观,实际都来自于生产实践的经验积累,并在大促场景得到不断锤炼。
例如,过去许多电商应用在 cpushare 化后时常遭受 CPU Throttled 的影响,业务的平均利用率通常不高,但偶发的流量波动却会因 Pod 的 CFS Quota 限制而被内核限流,导致响应延时的抖动。我们为 cpushare 化应用普遍开启了 CPU Burst 策略后,这类应用的 Throttled 率显著降低,在日常态有很好的应用效果。但是,对整体 CPU 利用率较高的机器,大范围上调节点上 Throttled Pod 的 CPU Limit,存在着较大的 CPU 超卖风险,可能反而导致容器间毫秒级的 CPU 争抢,加剧应用延时的波动。因此,CPU Burst 策略引入了对节点 CPU 利用率的实时监控,当节点利用率高出冷却阈值(Cooling)时,延缓当前 Throttled Pod 的 CPU Limit 上调;当节点利用率进一步高出过载阈值(Overload)时,关闭所有 Pod 的 CPU Limit 上调。在本次大促中,CPU Burst 策略基于实时的节点 CPU 利用率监控,规避 Burst 带来的竞争加剧,从日常态到大促台完整地保障了在线 cpushare 应用的 Burst 使用。

下面本文将结合以上策略,具体展开介绍Koordinator在资源隔离,单机QoS保障,以及应用干扰检测方面的设计实现和进展。
四、混部资源隔离
4.1 CPU资源隔离
Koordinator 的单机组件 koordlet 会根据节点的负载水位情况,调整 BestEffort 类型 Pod 的 CPU 资源额度。这种机制称为 CPU Suppress。当节点的在线服务类应用的负载较低时,koordlet 会把更多空闲的资源分配给 BestEffort 类型的 Pod 使用;当在线服务类应用的负载上升时,koordlet 又会把分配给 BestEffort 类型的 Pod 使用的 CPU 还给在线服务类应用。

同时,Koordinator还支持了龙蜥操作系统(Anolis OS)的 Group Identity 机制,通过为容器设置不同的身份标识,可以区分容器中进程任务的优先级。内核在调度不同优先级的任务时有以下特点:
-
高优先级任务的唤醒延迟最小化;
-
低优先级任务不对高优先级任务造成性能影响。主要体现在:
-
低优先级任务的唤醒不会对高优先级任务造成性能影响;
-
低优先级任务不会通过 SMT 调度器共享硬件 unit(超线程场景)而对高优先级任务造成性能影响。

4.2 内存资源等级
在 Linux 内核中,全局内存回收对系统性能影响很大。特别是离线任务时常会瞬间申请大量的内存,使得系统的空闲内存触及全局最低水位线(global wmark_min),引发系统所有任务进入直接内存回收的慢速路径,进而导致延迟敏感型业务的性能抖动。
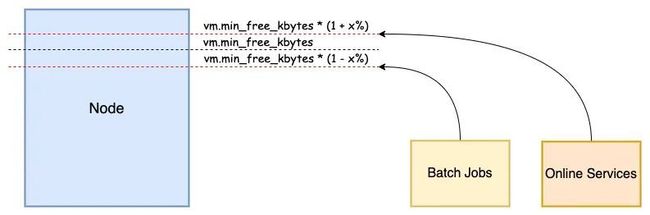
基于上述场景下的问题,Koordinator 对接了Anolis OS 的全局最低水位线分级功能。将离线的内存回收水位上调,使其提前进入直接内存回收。将在线服务的回收水位下调,使其尽量避免直接内存回收。这样即便离线瞬间申请大量内存,也会在上移的水位下受到短时间抑制,避免直接触发在线应用的内存回收,影响服务质量。
4.3 LLC及内存带宽隔离
混部场景下,同一台机器上部署不同类型的工作负载,这些工作负载会在硬件更底层的维度发生频繁的资源竞争。因此如果竞争冲突严重时,无法保障工作负载的服务质量。
Koordinator 基于 Resource Director Technology (RDT, 资源导向技术) ,控制由不同优先级的工作负载可以使用的末级缓存(服务器上通常为 L3 缓存)。RDT 还使用内存带宽分配 (MBA) 功能来控制工作负载可以使用的内存带宽。这样可以隔离工作负载使用的 L3 缓存和内存带宽,确保高优先级工作负载的服务质量,并提高整体资源利用率。
五、单机QoS保障策略
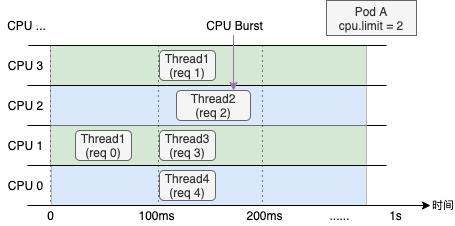
5.1 CPU Burst
CPU Burst 是针对在线应用的QoS保障策略。受内核调度器的约束,容器设置的 CPU Limit 压制容器的 CPU,这个过程称为 CPU Throttle,降低应用程序的性能。

Koordinator 自动检测 CPU Throttle 事件,并自动将 CPU Limit 调整为适当的值,并自动对接内核的 CPU Burst 接口,能够极大地提高延迟敏感的应用程序的性能。
5.2 基于内存安全阈值的主动驱逐机制
当延迟敏感的应用程序对外提供服务时,内存使用量可能会由于突发流量而增加。类似地,BestEffort 类型的工作负载可能存在类似的场景,例如,当前计算负载超过预期的资源请求/限制。这些场景会增加节点整体内存使用量,对节点侧的运行时稳定性产生不可预知的影响。例如,它会降低延迟敏感的应用程序的服务质量,甚至变得不可用。尤其是在混部场景下,这个问题更具挑战性。
我们在 Koordinator 中实现了基于内存安全阈值的主动驱逐机制。koordlet 会定期检查 Node 和 Pods 最近的内存使用情况,检查是否超过了安全阈值。如果超过,它将驱逐一些 BestEffort 类型的 Pod 释放内存。在驱逐前根据 Pod 指定的优先级排序,优先级越低,越优先被驱逐。相同的优先级会根据内存使用率(RSS)进行排序,内存使用率越高越优先被驱逐。
5.3 基于资源满足度的驱逐机制
离线任务在混部时往往会受到资源的频繁压制,导致离线任务的性能得不到满足,严重的也会影响到离线的服务质量。而且频繁的压制还存在一些极端的情况,如果离线任务在被压制时持有内核全局锁等特殊资源,那么频繁的压制可能会导致优先级反转之类的问题,反而会影响在线应用。虽然这种情况并不经常发生。

为了解决这个问题,Koordinator 提出了一种基于资源满足度的驱逐机制。我们把实际分配的 CPU 总量与期望分配的 CPU 总量的比值成为 CPU 满足度。当离线任务组的 CPU 满足度低于阈值,而且离线任务组的 CPU 利用率超过 90% 时,koordlet 会驱逐一些低优先级的离线任务,释放出一些资源给更高优先级的离线任务使用。通过这种机制能够改善离线任务的资源需求。
六、应用干扰检测
Koordinator 基于 QoS 和 PriorityClass 设置了先验的资源隔离和调整策略,在资源紧张时通过资源压制或驱逐等手段尽量满足高优 Pod 的资源需求。而在真实的生产环境下,单机的运行时状态是一个“混沌系统”,资源竞争产生的应用干扰无法绝对避免。因此还需要后验的策略,通过提取应用运行状态的指标,进行实时的分析和检测,在发现干扰后对目标应用和干扰源采取更具针对性的策略。
干扰检测和优化的过程可以分为以下几个过程:
-
干扰指标的采集和分析:选取干扰检测使用的指标需要考虑通用性和相关性,并尽量避免引入过多额外的资源开销。
-
干扰识别模型及算法:分为横向和纵向两个维度,横向是指分析同一应用中不同容器副本的指标表现,纵向是指分析在时间跨度上的数据表现,识别异常并确定“受害者”和“干扰源”。
-
干扰优化策略:充分评估策略成本,通过精准的压制或驱逐策略,控制“干扰源”引入的资源竞争,或将“受害者”进行迁移。同时建设相关模型,用于指导应用后续的调度,提前规避应用干扰的发生。
Koordinator 目前正在筹划应用干扰检测和优化的能力建设,将在后续版本中陆续发布,欢迎有兴趣的朋友一起参与!
七、欢迎加入 Koordinator 社区
Koordinator 是一个开放的社区,更多有关混部和调度的能力将在后续版本中陆续发布,非常欢迎广大云原生爱好者们通过各种方式一起参与共建,无论您在云原生领域是初学乍练还是驾轻就熟,我们都非常期待听到您的声音!
Github 地址:
https://github.com/koordinator-sh/koordinator
访问 Koordinator 官网,了解更多有关混部的详细介绍和使用方法。
