Neural Approaches to Conversational AI Question Answering(问答,任务型对话,闲聊)
摘要
本文概述了最近几年开发的对话式AI神经方法。 我们将对话系统分为三类:(1)问答代理,(2)面向任务的对话代理和(3)聊天机器人。 对于每个类别,我们将使用特定的系统和模型作为案例研究,对当前最先进的神经方法进行回顾,画出它们与传统方法之间的联系,并讨论已取得的进展和仍面临的挑战。
Chapter 1 Introduction
开发一种智能对话系统1,不仅可以模拟人类对话,还可以回答有关电影明星的最新消息到爱因斯坦的相对论等主题的问题,并完成诸如旅行计划之类的复杂任务,这是该国运行时间最长的目标之一AI。直到最近,这个目标仍然遥不可及。但是,现在,随着大量的对话数据可用于培训,并且在深度学习(DL)和强化学习(RL)中的突破被应用到了对话AI中,我们在学术研究界和业界都看到了可喜的成果。
会话式AI是自然用户界面的基础。这是一个快速发展的领域,吸引了自然语言处理(NLP),信息检索(IR)和机器学习(ML)社区的许多研究人员。例如,SIGIR 2018创建了一条人工智能,语义学和对话的新轨道,以桥接AI和IR方面的研究,特别是针对问题解答(QA),深度语义以及与智能代理的对话。
近年来,有关深度学习和对话系统的小型教程和调查论文行业兴起。 Yih等。 (2015b,2016);高(2017)回顾了针对IR和NLP任务广泛的深度学习方法,包括对话。 Chen等。 (2017e)提出了有关对话的教程,重点是面向任务的代理。 Serban等。 (2015年; 2018年)调查了可用于发展对话主体的公共对话数据集。 Chen等。 (2017b)回顾了流行的用于对话的深度神经网络模型,重点是有监督的学习方法。目前的工作大大扩展了Chen等人的研究范围。 (2017b); Serban等。 (2015)通过超越数据和监督学习来提供我们认为是针对对话AI的神经方法的首次调查,针对NLP和IR受众。2其贡献是:
•我们对最近几年开发的对话式AI神经方法进行了全面调查,涵盖了QA,面向任务和社交机器人,并具有最佳决策的统一视图。
•我们在现代神经方法和传统方法之间建立了联系,使我们能够更好地了解研究的原因和方式,以及如何继续前进。
•我们提出了使用监督学习和强化学习来培训对话代理的最新方法。
•我们勾勒出了由研究团体开发并在行业中发布的对话系统的概况,并通过案例研究展示了已取得的进展以及我们仍面临的挑战。
1.1 Who Should Read this Paper?
本文基于2018年SIGIR和ACL大会(Gao等人,2018a,b)上提供的教程,其中IR和NLP社区是主要目标受众。 但是,具有其他背景(例如机器学习)的观众也将发现它是具有大量指针的对话式AI的无障碍入门,尤其是最近开发的神经方法。
我们希望本文能够为学生,研究人员和软件开发人员提供宝贵的资源。 它提供了一个统一的视图,并详细介绍了理解和创建现代对话代理所需的重要思想和见解,这将有助于以看起来自然和直观的方式使数百万用户访问世界知识和服务。
该调查的结构如下:
•本章的其余部分介绍了对话任务,并提供了一个统一的视图,其中将开放域对话表述为最佳决策过程。
•第2章介绍了基本的数学工具和机器学习概念,并回顾了深度学习和强化学习技术的最新进展,这是开发神经对话代理的基础。
•第3章介绍了问题解答(QA)代理,重点介绍了基于知识的QA和机器阅读理解(MRC)的神经模型。
•第4章介绍了面向任务的对话代理,着重于将深度强化学习应用于对话管理。
•第5章介绍社交聊天机器人,重点介绍完全数据驱动的神经方法,以端对端地生成对话响应。
•第6章简要回顾了行业中的几种对话系统。
•第7章在本文的结尾部分讨论了研究趋势。
1.2 Dialogue: What Kinds of Problems?
图1.1显示了制定业务决策过程中的人与人对话。该示例说明了对话系统希望解决的各种问题:
•问题解答:代理需要根据从各种数据源(包括文本集合(如Web文档)和预编译的知识库,如销售和营销数据集)中获得的丰富知识,为用户查询提供简洁,直接的答案,如图所示。在图1.1中将3变为5。
•任务完成:座席需要完成用户任务,从餐馆预订到会议安排(例如,图1.1中的6到7号弯),以及商务旅行计划。
•社交聊天:座席需要与用户无缝且适当地对话(例如通过图灵测试测得的人),并提供有用的建议(例如,图1.1中的1至2)。
可以设想,上述对话可以由一组代理(也称为机器人)共同完成,每个代理都旨在解决特定类型的任务,例如QA机器人,任务完成机器人,社交聊天机器人。根据是否进行对话以帮助用户完成特定任务(例如,获取查询的答案或安排会议),这些漫游器可以分为两类:面向任务和聊天。
当今市场上大多数流行的个人助理,例如Amazon Alexa,Apple Siri,Google Home和Microsoft Cortana,都是面向任务的机器人。这些只能处理相对简单的任务,例如报告天气和请求歌曲。聊天对话机器人的一个示例是Microsoft XiaoIce。建立对话代理程序以完成如图1.1所示的复杂任务,对于IR和NLP社区以及AI来说,仍然是最根本的挑战之一。
典型的面向任务的对话代理由四个模块组成,如图1.2(上图)所示:(1)自然语言理解(NLU)模块,用于识别用户意图并提取相关信息; (2)状态跟踪器,用于跟踪对话状态,以捕获到目前为止会话中的所有基本信息; (3)一种对话策略,可根据当前状态选择下一步操作; (4)自然语言生成(NLG)模块,用于将主体动作转换为自然语言响应。近年来,趋势是通过使用深度神经网络统一这些模块来开发完全数据驱动的系统,该神经网络将用户输入直接映射到代理输出,如图1.2(底部)所示。


大多数面向任务的机器人都是使用模块化系统实现的,该机器人通常可以访问外部数据库,以在该数据库上查询完成任务的信息(Young等,2013; Tur and De Mori,2011)。 另一方面,社交聊天机器人通常使用单一(非模块化)系统来实现。 由于社交聊天机器人的主要目标是通过情感联系而不是完成特定任务而成为人类的AI伴侣,因此通常通过在大量的人与人之间的对话数据上训练基于DNN的响应生成模型来模仿人类的对话( Ritter等人,2011; Sordoni等人,2015b; Vinyals and Le,2015; Shang等人,2015)。 直到最近,研究人员才开始探索如何在世界知识(Ghazvininejad等人,2018)和图像(Mostafazadeh等人,2017)中建立交流的基础,从而使对话更加有趣和有趣。
1.3 A Unified View: Dialogue as Optimal Decision Making
图1.1中的示例对话可以表述为决策过程。它具有自然的层次结构:顶层进程选择要为特定子任务激活的代理(例如,回答问题,安排会议,提供推荐或只是随意聊天),而底层进程则受控制通过选定的代理,选择原始操作来完成子任务。
这样的分层决策过程可以在马尔可夫决策过程(MDP)的选项数学框架中进行铸造(Sutton等人,1999b),其中选项将原始动作概括为更高级别的动作。这是对传统MDP设置的扩展,在传统MDP设置中,代理只能在每个时间步选择原始动作,而代理可以选择“多步”动作,例如可以是一系列完成原始任务的原始动作。
如果我们将每个选项都视为一项行动,那么强化学习框架自然可以捕获高层和低层流程。对话代理在MDP中导航,并通过一系列离散步骤与其环境进行交互。在每个步骤中,代理都会观察当前状态,并根据策略选择一个操作。然后,特工会收到奖励并观察到新的状态,继续循环直到情节终止。对话学习的目标是找到最佳策略,以最大化预期的回报。表1.1使用统一的RL视图制定了一个对话主体样本,其中状态-动作空间描述了问题的复杂性,而奖励是要优化的目标函数。
分层MDP的统一视图已经被用来指导一些大型开放域对话系统的开发。最近的例子包括获得了2017年Amazon Alexa奖的社交聊天机器人Sounding Board 3,以及自2014年发布以来可以吸引全球超过6.6亿用户的最受欢迎的社交聊天机器人Microsoft XiaoIce4。这两种系统都使用分层对话经理:管理整个对话过程的管理员(最高级别),以及处理不同类型的会话段(子任务)的技能(低级)集合。
表1.1中的奖励功能在CPS中似乎是矛盾的(例如,我们需要最小化CPS才能有效完成任务,而最大化CPS来提高用户参与度),建议我们在开发时必须平衡长期和短期收益对话系统。例如,XiaoIce是针对用户参与度进行了优化的社交聊天机器人,但还配备了230多种技能,其中大部分是质量检查和任务导向的。 XiaoIce针对预期的CPS进行了优化,该CPS对应于长期而非短期的参与。尽管结合许多面向任务和QA技能可以在短期内降低CPS,因为这些技能可以通过最小化CPS来帮助用户更有效地完成任务,但是这些新技能使XiaoIce成为了有效且值得信赖的个人助手,从而加强了与人类用户的情感纽带长期来说。
尽管RL为构建对话代理提供了统一的ML框架,但应用RL需要通过与真实用户进行交互来训练对话代理,这在许多领域中都非常昂贵。因此,在实践中,我们经常使用结合了不同ML方法优势的混合方法。例如,我们可能会使用模仿和/或监督学习方法(如果存在大量的人与人之间的会话语料库)来获得合理的良好代理,应用RL继续改进它。 在本文的其余部分,我们将研究这些机器学习方法及其在训练对话系统中的用途。

1.4 The Transition of NLP to Neural Approaches
现在,神经方法正在改变NLP和IR的领域,其中数十年来,符号方法一直占据主导地位。
NLP应用程序与其他数据处理系统的不同之处在于,它们使用各种级别的语言知识,包括语音,形态,语法,语义和语篇(Jurafsky和Martin,2009年)。从历史上看,许多NLP领域都围绕着图1.3的体系结构进行组织,研究人员将其工作与一个或另一个组件任务(例如形态分析或解析)保持一致。通过将自然语言语句映射到(或从)一系列人类定义的,明确的符号表示(或从中生成),可以将这些组成任务视为在不同级别上解决(或实现)自然语言的歧义(或多样性)。作为词性(POS)标签,上下文无关文法,一阶谓词演算。随着数据驱动和统计方法的兴起,这些组件仍然存在,并已被改编为丰富的工程特征来源,可用于各种机器学习模型(Manning等人,2014)。
神经方法不依赖任何人类定义的符号表示,而是学习特定于任务的神经空间,其中使用低维连续向量将特定于任务的知识隐式表示为语义概念。如图1.4所示,神经方法通常通过三个步骤来执行NLP任务(例如,机器阅读理解和对话):(1)将符号用户输入和知识编码为它们的神经语义表示,其中语义相关或相似的概念是表示为彼此接近的向量; (2)在神经空间中进行推理以根据输入和系统状态生成系统响应; (3)将系统响应解码为在符号空间中输出的自然语言。编码,推理和解码是使用(不同体系结构的)神经网络实现的,可以通过反向传播和随机梯度下降以端到端的方式堆叠到深度神经网络中。
端到端训练导致最终应用程序与神经网络体系结构之间更紧密的耦合,从而减少了对传统NLP组件边界(如形态分析和解析)的需求。这极大地拉平了图1.3的技术堆栈,并大大减少了特征工程的需求。取而代之的是,重点已转移到针对最终应用精心定制日益复杂的神经网络架构。
混合方法的研究也结合了神经方法和符号方法的优势,例如(Mou等,2016; Liang等,2016)。 如图1.4所示,神经方法可以端到端的方式进行训练,对释义替换很健壮,但是在执行效率和可解释性方面很弱。 另一方面,象征性方法很难训练并且对释义交替很敏感,但是执行起来更容易解释和有效。

Chapter 2
Machine Learning Background
本章在后面的章节中简要介绍了与对话式AI最相关的深度学习和强化学习技术。
2.1 Machine Learning Basics
Mitchell(1997)广泛地将机器学习定义为包括任何计算机程序,该程序可以通过经验E改善在某些任务T上的性能,该任务由P度量。
如表1.1所示,对话是一个定义明确的学习问题,其中T,P和E指定如下:
•T:与用户进行对话以实现用户的目标。
•P:表1.1中定义的累积奖励。
•E:一组对话,每个对话都是一系列用户-代理交互。
举一个简单的例子,通过人工标注问题-答案对的经验,单回合QA对话代理可能会提高其性能,这可以通过在QA任务中生成的答案的准确性或相关性来衡量。
使用监督学习(SL)构建ML代理的常用方法包括数据集,模型,成本函数(又称损失函数)和优化过程。
•数据集由(x,y ∗)对组成,其中每个输入x都有一个真实的输出y ∗。在QA中,x由输入问题和从中生成答案的文档组成,而y ∗是由知识渊博的外部主管提供的所需答案。
•模型的形式通常为y = f(x;θ),其中f是由θ参数化的函数(例如神经网络),该函数将输入x映射到输出y。
•成本函数的形式为L(y ∗,f(x;θ))。 L(。)isoften设计了错误的平滑功能,并且可以区分。 θ。满足这些条件的常用成本函数是均方误差(MSE),定义为:

该优化可视为一种搜索算法,用于确定使L(。)最小的最佳θ。 鉴于L是可微的,深度学习最广泛使用的优化程序是小批量随机梯度下降(SGD),每批更新后的θ为

其中N是批次大小,α是学习率。
Common Supervised Learning Metrics.
训练模型后,可以在保留数据集上对其进行测试,以评估其泛化性能。 假设模型为f(·;θ),并且保持集包含N个数据点:D = {((x1,y1 ∗),(x2,y2 ∗),。 。 。 ,(xN,yN ∗)}。
第一个指标是上述均方误差,适用于回归问题(即yi ∗被视为实数值):

对于分类问题,yi ∗从被视为类别的有限集中获取值。 为简单起见,在此假设yi ∗∈{+1,−1},因此如果yi ∗为+1,则示例(xi,yi ∗)被称为正(或负)。
(或-1)。 •
经常使用以下指标:
准确性:f正确预测的示例分数:

其他度量也被广泛使用,尤其是对于二进制分类以外的复杂任务,例如BLEU评分(Papineni等,2002)。
Reinforcement Learning.以上SL配方适用于固定数据集上的预测任务。 但是,在诸如对话1的交互问题中,要获得既要正确又代表代理人必须采取行动的所有状态的期望行为的示例,可能是具有挑战性的。 在未开发的领土上,代理必须学习如何通过自身与未知环境进行交互来采取行动。 这种学习天堂被称为强化学习(RL),其中在主体和外部环境之间存在反馈回路。 换句话说,虽然SL从经验丰富的外部主管提供的以前的经验中学习,但RL则通过自己的经验来学习。 RL在几个重要方面与SL有所不同(Sutton和Barto,2018; Mitchell,1997)
Exploration-exploitation tradeoff.
在RL中,代理需要从环境中收集奖励信号。 这就提出了一个问题,即哪种实验策略可导致更有效的学习。 代理必须利用其已知的知识来获得高额报酬,同时还必须探索未知的状态和操作以在将来做出更好的操作选择。
Delayed reward and temporal credit assignment.
在RL中,不能像SL中那样以(x,y ∗)形式获得训练信息。 相反,当代理执行一系列操作时,环境仅提供延迟的奖励。 例如,直到会话结束,我们才知道对话是否能够成功完成任务。 因此,代理人必须确定产生其最终奖励将被归功于其序列中的哪些动作,这就是时间信用分配问题。
Partially observed states.
在许多RL问题中,在每个步骤中从环境中感知到的观察结果(例如,每个对话回合中的用户输入)仅提供了有关环境整体状态的部分信息,代理选择了下一步行动就基于该信息。 神经方法通过对在当前和过去的步骤中观察到的所有信息进行编码来学习一个深层的神经网络来表示状态,例如,所有先前的对话转弯以及从外部数据库中检索到的结果。
SL和RL的主要挑战是泛化-代理商在看不见的输入上表现良好的能力。 已经提出了许多学习理论和算法来成功地应对挑战,例如通过在可用的训练经验量与模型能力之间寻求良好的权衡来避免欠拟合和过拟合。 与以前的技术相比,神经方法通过利用深度神经网络的表示学习能力提供了一种可能更有效的解决方案,我们将在下一部分中进行简要介绍。
2.2 Deep Learning
深度学习(DL)涉及训练神经网络,其原始形式由单个层(即感知器)组成(Rosenblatt,1957)。 感知器甚至无法学习诸如逻辑XOR之类的简单功能,因此后续工作探索了“深度”架构的使用,该架构在输入和输出之间增加了隐藏层(Rosenblatt,1962; Minsky和Papert,1969),一种形式。 神经网络,通常称为多层感知器(MLP)或深度神经网络(DNN)。 本节介绍一些用于NLP和IR的常用DNN。 感兴趣的读者可以参考Goodfellow等。 (2016)进行全面讨论。
2.2.1 Foundations
考虑文本分类问题:用诸如“体育”和“政治”之类的域名标记文本字符串(例如,文档或查询)。如图2.1(左)所示,经典的ML算法首先使用一组手工设计的特征(例如,单词和字符的n元语法,实体和词组等)将文本字符串映射到矢量表示x,然后学习具有softmax层的线性分类器,以计算域标签y = f(x; W)的分布,其中W是使用SGD从训练数据中学习的矩阵,以最大程度地减少误分类错误。设计工作主要集中在要素工程上。
DL方法不是使用针对x的手工设计特征,而是使用DNN共同优化了特征表示和分类,如图2.1(右)所示。我们看到DNN由两半组成。上半部可视为线性分类器,类似于图2.1中的经典ML模型(左),不同之处在于其输入向量h不是基于手工设计的特征,而是使用下半部学习的DNN,可以看作是与分类器一起以端到端的方式优化的特征生成器。与经典ML不同,设计DL分类器的工作主要在于优化DNN架构以进行有效的表示学习。
对于NLP任务,根据我们希望在文本中捕获的语言结构的类型,我们可以应用不同类型的神经网络(NN)层结构,例如用于局部词依存关系的卷积层和用于全局词序列的递归层。这些层可以组合和堆叠以形成一个深层的体系结构,以在不同的抽象级别捕获不同的语义和上下文信息。下面介绍了几个广泛使用的NN层:
Word Embedding Layers.在符号空间中,每个单词都表示为一个热向量,其维数n是预定义词汇表的大小。 词汇量通常很大; 例如,n> 100K。 我们应用由线性投影矩阵We∈Rn×m参数化的词嵌入模型,将每个单热向量映射到m维实值向量(m≪ n)在神经空间中,语义上更相似的词的嵌入向量彼此更接近。
Fully Connected Layers.
它们执行Wx的线性投影。2我们可以堆叠多个完全连接的层,以在每个线性投影之后引入非线性激活函数g来形成深前馈NN(FFNN)。 如果我们将文本视为袋字(BOW)并让x为文本中所有单词的嵌入向量之和,则深度FFNN可以提取高度非线性的特征,以表示文本在不同位置的隐藏语义主题 层,例如h(1)= gW(1)x
在第一层,h(2)= gW(2)h(1),依此类推,其中W是可训练矩阵。
Convolutional-Pooling Layers.
卷积神经网络(CNN)的示例如图2.1(右)所示。 卷积层分两步形成单词wi的局部特征向量,表示为ui。 它首先通过连接wi的词嵌入向量及其由固定长度窗口定义的周围词来生成上下文向量ci。 然后执行投影以获得ui = g(WcWci),其中Wc是可训练矩阵,g是激活函数。 然后,池化层将输出ui,i = 1 ... L组合到单个全局特征向量h中。 例如,在图2.1中,在通过卷积层计算的矢量序列的每个“时间” i上应用最大池化操作以获得h,其中每个元素的计算公式为hj =max1≤i≤Lui, 。 另一个流行的合并功能是平均合并。
Recurrent Layers.
递归神经网络(RNN)的示例如图2.2所示。 RNN通常用于句子嵌入,其中我们将文本视为单词序列,而不是
比弓。 他们通过顺序将文本映射到密集的低维语义矢量然后循环处理每个单词,然后将子序列映射到当前单词到一个
低维向量,例如hi = RNN(xi,hi-1):= g(Wxi +Wrhi-1),其中xi是词ih在文本中嵌入第i个单词时,Whi和Wr是可训练的矩阵,而hi是直到第i个单词的单词序列的语义表示

2.2.2 Two Examples
本节简要介绍了DNN模型的两个示例,分别针对排名和文本生成任务而设计。 它们由上一节中描述的NN层组成。
DSSM排名。 在排序任务中,给定输入查询x,我们希望基于相似性评分函数sim(x,y)对所有候选答案y∈Y进行排序。 该任务是许多IR和NLP应用程序的基础,例如查询文档排名,QA中的答案选择以及对话响应选择。
DSSM代表深度结构化语义模型(Huang等,2013; Shen等,2014),或更笼统地说,是深度语义相似模型(Gao等,2014b)。 DSSM是用于测量一对输入(x,y)3的语义相似性的深度学习模型。如图2.3所示,DSSM由一对DNN(f1和f2)组成,它们将输入x和y映射到 共同的低维语义空间中的对应向量。 然后用余弦测量x和y的相似度

两个向量的距离。 f1和f2可以具有不同的架构,具体取决于x和y。 例如,为了计算图像-文本对的相似度,f1可以是深度卷积NN,f2可以是RNN。
设θ为f1和f2的参数。 学会了θ来识别x和y的最有效特征表示,这些特征表示直接针对最终任务进行了优化。 换句话说,我们学习一个由θ参数化的隐藏语义空间,其中空间中向量之间距离的语义是由任务或更具体地由任务的训练数据定义的。 例如,在Web文档排名中,距离用于度量查询文档的相关性,并且使用成对的排名损失来优化θ。 考虑一个查询x和两个候选文档y +和y-,其中y +比y-与x更相关。 设simθ(x,y)是θ参数化的语义空间中x和y的相似度,

Seq2Seq for Text Generation.
在一个文本生成任务中,给定输入文本x,我们想生成输出文本y。这项任务对于诸如机器翻译和对话响应生成之类的应用程序而言至关重要。
Seq2seq代表序列到序列架构(Sutskever等,2014),也称为编码器-解码器架构(Cho等,2014b)。 Seq2Seq通常基于序列模型(如RNN或门控RNN)实现。 Gate RNN,例如长期记忆(LSTM)(Hochreiter和Schmidhuber,1997)和基于门控循环单元(GRU)的网络(Cho等,2014b)是图2.2中RNN的扩展,并且由于使用门控单元,它们具有随时间变化的路径而导数既不消失也不爆炸,因此在捕获长期依存关系方面通常更有效。我们将详细说明LSTM如何在Sec中应用于端到端会话模型。 5.1。
Seq2seq将生成以x为条件的y的概率定义为P(y | x)4。如图2.4所示,seq2seq模型由(1)输入RNN或编码器f1组成,将输入序列x编码为上下文向量c,通常是其最终隐藏状态的简单功能; (2)输出RNN或解码器f2,其产生以c为条件的输出序列y。 x和y的长度可以不同。联合训练由θ参数化的两个RNN,以最小化训练数据中所有(x,y)对上的损失函数

2.3 Reinforcement Learning
本节回顾了强化学习,以促进后续章节中的讨论。 为了对该主题进行全面处理,有兴趣的读者可以参考现有的教科书和评论,例如Sutton和Barto(2018); Kaelbling等。 (1996); Bertsekas和Tsitsiklis(1996); Szepesvári(2010); Wiering和van Otterlo(2012); 李(2018)。

2.3.1 Foundations
强化学习(RL)是一种学习范例,其中智能代理通过与最初未知的环境进行交互来学习做出最佳决策(Sutton和Barto,2018)。 与监督学习相比,RL中的一个独特挑战是没有老师(即没有监督标签)的学习。 正如我们将看到的,这将导致RL特有的算法考虑。
如图2.5所示,代理人与环境的相互作用通常被建模为离散时间马尔可夫决策过程或MDP(Puterman,1994),由五元组M =〈S,A,P,R,γ 〉:
•S是环境可能处于无限状态的集合;
•A是代理在状态下可以采取的一系列可能无限的操作;
•P(s'| s,a)给出在状态s采取动作a后环境降落到新状态s'的转变概率;
•R(s,a)是代理商在状态s中采取行动a后立即获得的平均奖励; 和
•γ∈(0,1]是折现因子。
可以将相交记录为轨迹(s1,a1,r1,...),其生成如下:在步骤t =1,2,...,
•代理观察环境的当前状态st∈S,并在∈A处采取措施;
•过渡状态st + 1的环境过渡,根据过渡概率P(·| st,at)分布;
•与过渡相关的是立即回报rt∈R,其平均值为R(st,at)。
省略下标,每个步骤都会导致一个元组(s,a,r,s'),称为过渡。 RL代理的目标是通过采取最佳行动(即将定义)来最大化长期回报。 用π表示的其动作选择策略可以是确定性的或随机的。 无论哪种情况,我们都使用一个π(s)来表示在状态s中跟随π的动作选择。 给定策略π,状态s的值是该状态的平均长期长期折扣:

我们对优化策略感兴趣,以便使所有状态的Vπ都最大化。 用π∗表示最优策略,用V ∗表示其相应的值函数(也称为最优值函数)。 在许多情况下,使用另一种形式的值函数(称为Q函数)更为方便:
![]()
它通过首先选择状态s中的a,然后遵循策略π来度量平均折现长期奖励。 与最优策略相对应的最优Q函数用Q *表示。
2.3.2 Basic Algorithms
现在,我们描述两种流行的算法类别,分别以Q学习和策略梯度为例。
Q学习。 第一族基于这样的观察结果:如果可以使用最佳Q函数,则可以立即检索最佳策略。 具体而言,可以通过以下方式确定最佳策略:
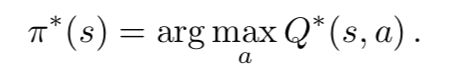
因此,大量的RL算法专注于学习Q ∗(s,a),并统称为基于值函数的方法。
实际上,当问题很严重时,用一张表来表示Q(s,a)是很昂贵的,每个不同的(s,a)都有一个表项。 例如,围棋游戏中的状态数大于2×10170(Tromp和Farnebäck,2006)。 因此,我们经常使用紧凑形式来表示Q。特别是,我们假设Q函数具有预定义的参数形式,并由某些矢量θ∈Rd参数化。 一个例子是线性逼近:

其中φ(s,a)是状态动作对(s,a)的d维手编码特征向量,而θ是要从数据中学习的对应系数向量。 通常,Q(s,a;θ)可以采用不同的参数形式。 例如,在深层Q网络(DQN)的情况下,Q(s,a;θ)采用深层神经网络的形式,例如多层感知器和卷积网络(Tesauro,1995; Mnih等, (2015年),循环网络(Hausknecht和Stone,2015年; Li等,2015年)等。更多示例将在后面的章节中看到。 此外,可以使用决策树(Ernst等人,2005)或高斯过程(Engel等人,2005)以非参数的方式表示Q函数,这不在本介绍的范围之内。 部分。
为了学习Q函数,我们在观察到状态转换(s,a,r,s')之后使用以下更新规则修改参数θ:
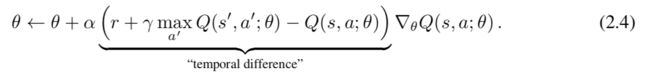
定期将θtarget更新为θ,然后继续进行处理。
上面描述的基本Q学习最近有了许多改进,例如决斗Q网络(Wang等人,2016),双重Q学习(van Hasselt等人,2016)和可证明的收敛性 SBEED算法(Dai等人,2018b)。
Policy Gradient.
另一类算法试图直接优化策略,而不必学习Q函数。 这里,策略本身直接由θ∈Rd参数化,并且π(s;θ)通常是作用上的分布。 给定任何θ,该策略自然会根据其在长度为H的轨迹中获得的平均长期奖励进行评估,τ=(s1,a1,r1,...,sH,aH,rH):5

如果有可能从采样轨迹中估算出梯度∇θJ,则可以进行随机梯度上升6以最大化J:
![]()
其中α还是一个stepsize参数。
一种这样的算法,称为REINFORCE(Williams,1992),其梯度估算如下。 令τ为由π(·;θ)生成的长度H轨迹; 也就是说,每t约为π(st;θ)。 然后,基于该单个轨迹的随机梯度为

REINFORCE在实践中可能会出现较大差异,因为它的梯度估计直接取决于整个轨迹上的奖励总和。 它的方差可以通过使用当前政策的估计值函数来减少,该函数通常在参与者批评算法中被称为批评者(Sutton等,1999a; Konda和Tsitsiklis,1999):

其中Qˆ(s,a,h)是当前策略π(s;θ)的估计值函数,用于
在等式中,Hh= tγh-trh附近。 2.7。 Qˆ(s,a,h)可以通过标准时差方法(类似于Q学习)来学习,但是存在许多变体。 此外,在比Eqn更有效地计算梯度θθJ的方法方面,还有很多工作要做。 2.8。 有兴趣的读者可以参考一些相关的著作以及其中的参考文献以获取更多详细信息(Kakade,2001; Peters等,2005; Schulman等,2015a,b; Mnih等,2016; Gu等,2017 ; Dai等,2018a; Liu等,2018b)。
2.3.3 Exploration
到目前为止,我们已经描述了在将转换作为输入时更新值函数或策略的基本算法。 通常,RL代理还必须确定如何选择操作以收集所需的过渡以进行学习。 始终选择看似最好的操作(“开发”)是有问题的,因为不选择被称为“探索”的新颖操作(即,到目前为止收集的数据代表性不足或什至不存在)可能会导致以下风险: 没有看到可能更好的结果。 有效平衡探索和开发是强化学习中的独特挑战之一。
基本的探索策略被称为ε贪心。 这个想法是选择概率最高的最佳动作(用于开发),选择概率较小的随机动作(用于探索)。 对于DQN,假设θ是Q函数的当前参数,则状态s的动作选择规则如下:

在许多问题中,这种简单的方法是有效的(尽管不一定是最佳的)。 在第二节中可以找到进一步的讨论。 4.4.2。
Chapter 3
Question Answering and Machine Reading Comprehension
近年来,对会话式问答(QA)代理的需求不断增长,该代理允许用户查询自然语言的大型知识库(KB)或文档集合。前者称为KB-QA代理,后者称为文本QA代理。 KB-QA代理比传统的类似SQL的系统更加灵活和用户友好,因为用户可以交互查询知识库,而无需编写复杂的类似SQL的查询。与传统的搜索引擎(例如Bing和Google)相比,Text-QA代理在移动设备中的使用要容易得多,因为它们可以为用户查询提供简洁,直接的答案,而不是相关文档的排名列表。
值得一提的是,多回合,对话式质量检查是一个新兴的研究主题,其研究不如单回合的质量检查。本章回顾的许多论文都集中在后者。但是,单次回合质量检查是进行各种对话(例如闲聊和面向任务的对话)必不可少的基石,如果我们要开发现实世界的对话系统,应该引起我们的充分注意。
在本章中,我们首先回顾基于语义解析的KB和KB-QA的符号方法。我们展示了一个符号系统很难扩展,因为该系统使用的基于关键字匹配的,查询到答案的推理在很大的KB上效率低下,并且对措辞不强健。为了解决这些问题,开发了神经方法来使用连续的语义向量表示查询和知识库,以便可以在紧凑的神经空间中的语义级别上进行推理。我们还以电影点播代理为例,描述了多回合会话KB-QA代理的典型体系结构,并回顾了最近开发的几个会话KB-QA数据集。
然后,我们讨论神经文本QA代理。这种系统的核心是神经机器阅读理解(MRC)模型,该模型基于(一组)段落生成对输入问题的答案。在回顾了流行的MRC数据集和TREC text-QA开放式基准之后,我们从两个方面描述了为最新的MRC模型开发的技术:(1)在神经空间中将问题和段落编码为矢量的方法(2)在神经空间中进行推理以生成答案的方法。我们还将描述多轮对话式文本QA代理的体系结构,以及将MRC任务和模型扩展到对话式QA设置的方式。
3.1 Knowledge Base
整理世界的事实并将其存储在结构化的数据库中,像DBPedia(Auer et al。,2007),Freebase(Bollacker et al。,2008)和Yago(Suchanek et al。,2007)之类的大规模知识库(KB)具有 成为支持开放域质量检查的重要资源。
典型的KB由一组主谓谓三元组(s,r,t)组成,其中s,t∈E是实体,r∈R是谓语或关系。 这种形式的KB由于其图形表示形式,通常称为知识图(KG),即,实体是节点,并且关系是链接节点的有向边。
图3.1(左)显示了Freebase的一小段子图,它与电视节目Family Guy有关。 节点包括一些名称,日期和特殊的“复合值类型”(CVT)实体。1有向边描述了两个实体之间的关系,并用谓词标记。

3.2 Semantic Parsing for KB-QA
KB-QA的大多数最新符号方法都是基于语义解析的,其中将问题映射到其形式含义表示形式(例如逻辑形式),然后翻译为KB查询。然后,可以通过在知识库中找到与查询匹配的一组路径并检索这些路径的末端节点来获得问题的答案(Richardson等,1998; Berant等,2013; Yao和Van Durme, 2014; Bao等,2014; Yih等,2015b)。
我们以Yih等人使用的示例为例。 (2015a)来说明质量检查流程。图3.1(右)显示了“谁在家常人家上首次向梅格说话?”问题的λ演算形式及其相应的图形表示形式,即查询图。请注意,查询图基于Freebase。 MegGriffin和FamilyGuy这两个实体由两个圆角矩形节点表示。圆圈节点y表示应该存在一个实体,该实体描述一些角色,演员和角色开始时间等角色关系。 y在这种情况下以CVT实体为基础。带阴影的圆圈节点x也称为答案节点,用于映射查询所检索的实体。菱形节点arg min约束答案必须是该角色的最早演员。如图3.1(左)所示,对图表运行没有聚合函数的查询图将同时匹配LaceyChabert和MilaKunis。但是,只有LaceyChabert才是更早开始担任该角色的正确答案(通过检查接地CVT节点的from属性)。
将符号KB-QA系统应用于非常大的KB具有挑战性,这有两个原因:
自然语言的措辞:这导致了表达相同问题的广泛多样的表达方式,在KB-QA设置中,这可能会导致自然语言问题与KB中使用的节点和边的标签名称(例如谓词)不匹配。 如图3.1中的示例,我们需要衡量问题中使用的谓词与Freebase中的谓词匹配的可能性,例如“谁在家庭盖伊上首先向梅格说话?”与演员。 Yih等。 (2015a)建议使用第7节中介绍的学习的DSSM。 2.2.2,从概念上讲,这是一种基于嵌入的方法,我们将在本节中进行介绍。 3.3。
•搜索复杂度:搜索所有可能与复杂查询匹配的多步(组合)关系路径的成本过高,因为候选路径的数量随路径长度呈指数增长。 我们将在第二节中回顾符号和神经方法进行多步推理。 3.4。
3.3 Embedding-based Methods
为了解决释义问题,基于嵌入的方法将KB中的实体和关系映射到神经空间中的连续向量。 参见,例如,Bordes等。 (2013); Socher等。 (2013); 杨等。 (2015); Yih等。 (2015b)。 该空间可以视为隐藏的语义空间,其中具有相同语义含义的各种表达式映射到相同的连续向量。
大多数知识库嵌入模型都是为知识库完成(KBC)任务开发的:预测存在知识库中看不到的三元组(s,r,t)。 与KB-QA相比,这是一项更简单的任务,因为它只需要预测事实是否为真,因此不会遭受搜索复杂性问题的困扰。
双线性模型是基本的KB嵌入模型之一(Yang等,2015; Nguyen,2017)。 它为每个关系e学习一个向量xe∈Rd和每个关系r的amatrixWr∈Rd×d。该模型使用以下公式对三元组(s,r,t)保持的可能性进行评分

模型参数θ(即嵌入向量和矩阵)在成对训练样本上以与本教程中描述的DSSM类似的方式进行训练。 2.2.2。 对于KB中用x +表示的每个正三元组(s,r,t),我们通过破坏s,t或r来构造一组负三元组x-。 训练目标是使等式的成对秩损失最小化。 2.2,或更常见的基于保证金的损失定义为

其中[x] +:= max(0,x),γ是边缘超参数,D是三元组的训练集。
这些基本的知识库模型已扩展为回答称为路径查询的多步关系查询,例如“塔德·林肯父母的住所?”(Toutanova等人,2016; Guu等人,2015; Neelakantan等人) 。,2015)。 路径查询由初始锚实体s(例如TadLincoln)组成,然后是要遍历的关系序列(r1,...,rk)(例如(父母,位置))。我们可以使用向量空间组合来组合单个关系ri的嵌入 嵌入路径(r1,...,rk)中。 方程双线性模型的自然组成。 3.1是矩阵乘法。 因此,为了回答路径查询(q,t)成立的可能性,其中q =(s,r1,...,rk),我们将计算

在验证给定现有KB的情况下验证看不见的事实(例如三元组和路径查询)方面,这些KB嵌入方法显示出良好的泛化性能。 有兴趣的用户可以参考Nguyen(2017)进行KBC嵌入模型的详细调查。
3.4 Multi-Step Reasoning on KB
知识库推理(KBR)是KB-QA的子任务。 如第二节所述。 3.2,KB-QA分两个步骤执行:(1)语义解析将问题转换为KB查询,然后(2)KBR遍历KB中与查询匹配的路径以找到答案。
为了推理出一个KB,对于每个关系r∈R,我们有兴趣学习以关系路径π=(r1,...,rk)形式的一组一阶逻辑规则。 对于图3.2中的KBR示例,给定问题“奥巴马的公民身份是什么?”,它以主谓谓宾三元组的形式翻译的知识库查询为(奥巴马,公民身份,?)。 除非三胞胎(奥巴马,公民身份,美国)已明确存储在知识库中,[2]需要采取多步推理程序,才能从包含相关三元组的路径(例如,奥巴马,出生于夏威夷)和(夏威夷,美国部分)中得出答案 ),使用学习的关系路径,例如(出生,部分)。
下面,我们描述三步多步KBR方法。 它们的区别在于是在离散的符号空间还是在连续的神经空间中进行推理。


3.4.1 Symbolic Methods
路径排序算法(PRA)(Lao and Cohen,2010; Lao et al。,2011)是学习大KB中的关系路径的主要符号方法之一。 PRA使用随机游走并重新启动以执行多个有界的深度优先搜索,以找到关系路径。 表3.1显示了PRA学习的关系路径的示例。 关系路径是序列π=(r1,...,rk)。 关系路径的一个实例是节点e1,...,ek + 1的序列,这样(ei,ri,ei + 1)是有效的三元组。
在KBR期间,给定查询q =(s,r,?),PRA选择r的一组关系路径,用Br = {π1,π2,...}表示,然后根据查询遍历KB和Br ,并使用线性模型对每个候选答案t进行评分


其中λπ是学习的权重,P(t | s,π)是通过实例化关系路径π的随机游走从s到达t的概率,也称为路径约束随机游走。
因为PRA在完全离散的空间中运行,所以它没有考虑关系之间的语义相似性。结果,PRA甚至可以以很短的路径长度轻松生成数百万个类别截然不同的路径,这不仅不利于泛化,而且使推理变得非常昂贵。为了减少在KBR中需要考虑的关系路径的数量,Lao等人(英文)。 (2011年)使用了启发式方法(例如,仅当在训练数据中检索到至少一个目标实体时才要求将路径包括在PRA中),并在损失函数中添加了L1正则项以训练Eqn的线性模型。 3.3。 Gardner等。 (2014年)提出了对PRA的一种修改,该修改利用了KB嵌入方法,如第6节所述。 3.3,根据关系嵌入折叠和聚类PRA路径
3.4.2 Neural Methods
提出了隐式ReasoNet(IRN)(Shen等人,2016,2017a)和神经逻辑编程(Neural LP)(Yang等人,2017a)来在神经空间中执行多步KBR并实现现状 流行基准的艺术效果。 这些方法的总体架构如图3.3所示,可以视为图1.4(右)所示的神经方法的一个实例。 接下来,我们以IRN为例来说明这些神经方法的工作方式。 IRN由四个模块组成:编码器,解码器,共享存储器和控制器,如图3.3所示。
Encoder and Decoder
这两个模块是任务相关的。 给定输入查询(s,r,?),编码器分别将s和r映射到它们的嵌入向量3中,然后将这两个向量连接起来以形成控制器的初始隐藏状态向量s0。
解码器输出预测向量o = tanh(Wost + bo),这是从时间s的状态s开始的非线性投影,其中Wo和bo分别是权重矩阵和偏置向量。 在KBR中,我们可以基于L1距离将符号向量o映射到符号空间中的符号节点的答案节点(实体)o,其中o = argmine∈E| o − xe | 1,其中xe是实体e的嵌入向量。
共享内存共享内存M是可微的,它由向量{mi}1≤i≤| M |的列表组成。 通过训练中的反向传播随机初始化和更新。 M存储为KBR任务优化的压缩KB版本。 也就是说,每个向量代表一个概念(一组关系或实体),向量之间的距离代表这些概念的语义相关性。 例如,即使系统找到M中的相关事实,例如,(美国夏威夷州的奥巴马)和(美国部分夏威夷州),系统也可能无法回答问题(奥巴马,公民身份,?), 因为它不知道钻孔和公民身份是在语义上相关的关系。 为了纠正错误,需要使用梯度更新M,以通过在神经空间中将两个关系向量彼此移近来对新信息进行编码。
控制器控制器被实现为RNN。 给定初始状态s0,它会根据Eqn使用注意力来迭代查找并从M中获取信息以在时间t更新状态st。 3.4,直到它决定终止推理过程并调用解码器以生成输出。
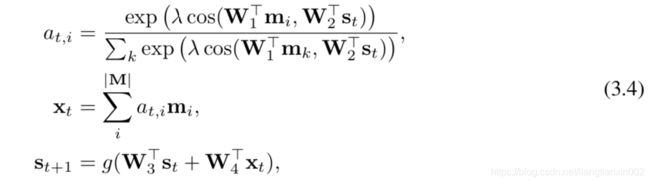
其中W是学习的投影矩阵,λ是比例因子,而g是非线性激活函数。
IRN的推理过程可以看作是马尔可夫决策过程(MDP),如第二节所述。 2.3.1。信息查找和方程式获取序列中的步长。 3.4不是由训练数据给出的,而是由控制器实时决定的。更复杂的查询需要更多步骤。因此,IRN学习了一种随机策略,以通过REINFORCE算法(Williams,1992年)对终止和预测行为进行分配,该方法在第6节中进行了介绍。 2.3.2和等式2.7。由于IRN的所有模块都是可微的,因此IRN是一个端到端可微神经模型,其参数(包括嵌入式KB矩阵M)可以使用SGD在从KB导出的训练样本上共同优化,如图2所示。 3.3。
如图1.4所示,神经方法在连续的神经空间中运行,并且不会遭受与符号方法相关的问题的困扰。它们对于释义替换是健壮的,因为知识是通过连续的向量和矩阵由语义类隐式表示的。即使是复杂查询(例如路径查询)和很大的KB,它们也不会遭受搜索复杂性问题的困扰,因为它们基于KB的紧凑表示形式(例如,IRN中共享内存中的矩阵M),而不是KB本身。
这些方法的主要限制之一是缺乏可解释性。与PRA不同,PRA显式地遍历图中的路径为Eqn。 3.3,IRN在推理过程中不会显式遵循KB中的任何路径,而是会注意,使用RNN控制器迭代地对共享内存执行查找操作,每次都使用修订的内部状态s作为查找查询。从神经控制器中恢复查询和路径(或一阶逻辑规则)的符号表示仍然具有挑战性。参见(Shen et al。,2017a; Yang et al。,2017a)了解神经方法的一些有趣的初步结果
3.4.3 Reinforcement Learning based Methods
DeepPath(Xiong等,2017),MINERVA(Das等,2017b)和M-Walk(Shen等,2018)是使用RL进行多步推理的最新方法之一超过KB。他们使用具有基于KB嵌入的连续状态的基于策略的代理来遍历知识图,从而识别输入查询的答案节点(实体)。由于使用连续向量进行状态表示,因此基于RL的方法与神经方法一样健壮,并且由于代理明确遍历图中的路径,因此与符号方法一样可解释。
我们将KBR公式化为由元组(S,A,R,P)定义的MDP,其中S是连续状态空间,A是可用动作集,P是状态转换概率矩阵,R是奖励函数。下面,我们按照M-Walk来详细描述这些组件。我们将KB表示为图形G(E,R),其中包括实体节点E和链接节点的关系边R的集合。我们将KB查询表示为q =(e0,r ,?),其中e0和r分别是给定的源节点和关系,以及?要标识的答案节点。
状态让st表示时间t处的状态,该状态编码直到t为止的所有遍历节点的信息,所有先前选择的动作以及初始查询q。 st可以递归定义如下:

其中在∈A是代理在时间t处选择的动作,et是当前访问的节点,Ret∈R是与et连接的所有边的集合,Eet∈E是与et连接的所有节点的集合 。 请注意,在基于RL的方法中,st使用例如M-Walk和MINERVA中的RNN或DeepPath中的MLP表示为连续向量。
动作基于st,代理选择以下动作之一:(1)在Eet中选择一条边并移至下一个节点et + 1∈E,或(2)终止推理过程并将当前节点et输出为a答案节点eT的预测。
过渡过渡是确定性的。如图3.2所示,一旦选择了at动作,就知道下一个节点et + 1及其关联的Eet + 1和Ret + 1。
奖励如果eT是正确答案,我们只能获得+1的最终奖励,否则获得0。
策略网络策略πθ(a | s)表示在给定状态s下选择动作的概率,并实现为以θ为参数的神经网络。优化策略网络以最大化E [Vθ(s0)],这是从s0开始并随后遵循策略πθ的长期奖励。在KBR中,可以使用RL(例如REINFORCE方法)从从KB中提取的三元组(es,r等)的训练样本中训练策略网络。为了解决奖励稀疏性问题(即,奖励仅在路径的末尾可用),Shen等人。 (2018)建议利用蒙特卡洛树搜索(Monte Carlo Tree Search)来生成一组模拟路径,以利用给定知识图谱的所有转换都是确定性的事实。
3.5 Conversational KB-QA Agents
到目前为止,我们所描述的所有KB-QA方法都是基于单回合代理,它们假定用户可以一次组成一个复杂的,组成自然的语言查询,可以唯一地识别KB中的答案。
但是,在许多情况下,假设用户无需事先了解要查询的KB结构就可以构造组成查询是不合理的。因此,会话式KB-QA代理更为可取,因为它们允许用户以交互方式查询KB,而无需编写复杂的查询。
对话式KB-QA代理对于许多交互式KB-QA任务(例如点播电影)很有用,其中用户尝试根据该电影的某些属性来查找电影,如图3.4中的示例所示,其中电影DB可以看作是由实体属性值三元组组成的以实体为中心的KB。
除了通常由语义解析器和KBR引擎组成的核心KB-QA引擎之外,对话式KB-QA代理还配备了一个对话管理器(DM),该对话管理器跟踪对话状态并确定要有效询问的问题帮助用户浏览KB以搜索实体(电影)。电影点播会话代理的高级体系结构如图3.5所示。在每个回合中,代理都会接收自然语言话语ut作为输入,并选择∈A处的动作作为输出。动作空间A包括一组问题,每个问题用于请求一个属性的值,以及一个通知用户有关检索到的实体的有序列表的动作。该代理是图1.2(上图)中一个典型的面向任务的对话系统,由(1)信念跟踪器模块组成,该信念跟踪器模块用于使用会话上下文解决用户话语中的共指和省略号,识别用户意图,提取关联的属性并跟踪对话状态(2)与KB的接口,用于查询相关结果(即,Soft-KB Lookup组件,可以使用前面几节中描述的KB-QA模型来实现,除了我们需要基于信念追踪器捕获的对话历史记录,而不仅仅是Suhr等人(2018)中所述的当前用户话语; (3)信念汇总模块,将状态汇总为向量; (4)对话策略,其基于对话状态选择下一动作。该政策可以被编程(Wu等,2015)或接受对话培训(Wen等,2017; Dhingra等,2017)。Wu等。 (2015年)提出了一种熵最小化对话管理(EMDM)策略。代理始终要求对KB中的其余条目具有最大熵的属性值。在没有语言理解错误的情况下,EMDM被证明是最佳的。但是,它没有考虑到一些问题易于用户回答,而另一些问题则不然。例如,在电影点播任务中,代理可以要求用户提供每个电影唯一的电影发行ID,但普通用户通常不知道。
Dhingra等。 (2017年)提出了KB-InfoBot –一种完全神经端到端多回合对话代理,用于点播电影任务。代理完全根据用户反馈进行培训。它不会受到EMDM问题的困扰,并且始终会向用户询问易于回答的问题以帮助在KB中进行搜索。像所有KB-QA代理一样,KB-InfoBot需要与外部KB进行交互以检索实际知识。传统上,这是通过向KB发出符号查询以基于条目的属性来检索条目来实现的。但是,这样的符号操作破坏了系统的可区分性,并阻止了对话代理的端到端训练。 KB-InfoBot通过用指示用户感兴趣的条目的KB上的后验分布替换符号查询来解决此限制,该后验分布表明用户感兴趣的条目。可以使用前面各节中描述的神经KB-QA方法来实现归纳。实验表明,将归纳过程与RL集成在一起可以在模拟和针对真实用户的情况下提高任务成功率和回报4。
最近,已经开发了一些数据集来构建会话KB-QA代理。艾耶尔等。 (2017年)通过利用WikiTableQuestions(WTQ(Pasupat和Liang,2015年))通过众包收集了一个顺序问题回答(SQA)数据集,其中包含与Wikipedia的HTML表相关的高度组成的问题。如图3.6中的示例(左)所示,每个众包任务包含一个最初来自WTQ的长而复杂的问题作为问题意图。要求工人撰写一系列更简单但相互关联的问题,以形成最终意图。简单问题的答案是表中单元格的子集。
萨哈等。 (2018)提出了一个由200K QA对话组成的数据集,用于复杂序列问题回答(CSQA)任务。 CSQA包含两个子任务:(1)通过大规模KB上的复杂推理来回答事实性问题,以及(2)学习通过一系列连贯的QA对进行交谈。如图3.6(右)中的示例,CSQA要求使用对话KB-QA代理,该代理结合了本章中介绍的许多技术,包括(1)解析复杂的自然语言查询,如本节中所述。 3.2,(2)使用对话上下文来解决用户话语中的共指和省略号,例如图3.5中的信念跟踪器,(3)询问歧义查询的分类问题,例如图3.5中的对话管理器,以及(4 )检索知识库中的相关路径,以按照第2节中的说明回答问题。 3.4。


3.6 Machine Reading for Text-QA
机器阅读理解(MRC)是一项具有挑战性的任务:目标是让机器阅读一组文本段落,然后回答有关该段落的任何问题。 MRC模型是文本QA代理的核心组件。
最近在MRC上取得的重大进展很大程度上归功于研究社区在各种文本源上创建的大量大规模数据集的可用性,这些数据源来自Wikipedia(WikiReading(Hewlett等人,2016),SQuAD(Rajpurkar等人。 (2016年),WikiHop(Welbl等人,2017年),DRCD(Shao等人,2018年),新闻和其他文章(CNN / Daily Mail(Hermann等人,2015年),NewsQA(Trischler等人, 2016年),RACE(Lai等人,2017年),ReCoRD(Zhang等人,2018d)),虚构故事(MCTest(Richardson等人,2013年),CBT(Hill等人,2015年),NarrativeQA(Kocˇisky)等人(2017)),科学问题(ARC(Clark等人,2018))和一般Web文档(MS MARCO(Nguyen等人,2016),TriviaQA(Joshi等人,2017),SearchQA( Dunn等人,2017),DuReader(He等人,2017b))。
队。这是斯坦福NLP小组发布的MRC数据集。它由人群工作者在一组维基百科文章上提出的10万个问题组成。如图3.7(左)中的示例所示,在SQuAD上定义的MRC任务涉及一个问题和一个段落,并旨在在该段落中找到答案范围。例如,为了回答“是什么导致沉淀物下降?”的问题,人们可能会首先找到“沉淀物...落入重力”这一段落的相关部分,然后说“下”是指原因。 (而不是位置),从而确定正确的答案:“重力”。尽管基于跨度的答案的问题比用户提交给Google和Bing等网络搜索引擎的实际问题更受限制,但SQuAD提供了丰富的问题和答案类型,并成为该领域中使用最广泛的MRC数据集之一研究社区。

马可女士。这是Microsoft发布的大规模现实MRC数据集,旨在弥补其他学术数据集的局限性。例如,MS MARCO与SQuAD的不同之处在于:(1)SQuAD包括人群工作者提出的问题,而MS MARCO是从真实用户查询中采样的; (2)SQuAD使用少量高质量的Wikipedia文章,而MS MARCO是从大量Web文档中采样的;(3)MS MARCO包含一些无法回答的查询5;(4)SQuAD需要在段落中标识答案范围,而MS MARCO要求从可能与也可能不与给定问题相关的多个段落中生成答案(如果有)。结果,MS MARCO更具挑战性,并且需要更复杂的阅读理解技能。如图3.7(右)中的示例所示,考虑到“如果我是加拿大新移民,我将有资格获得OSAP”的问题,因此可能首先找到相关段落,其中包括:“您必须是加拿大人1公民; 2名永久居民;或3个受保护的人...”,而成为该国的新移民通常与成为公民,永久居民等相反,因此请确定正确的答案:“不,您没有资格”。
除了我们上面描述的公共MRC数据集之外,TREC6还提供了一系列文本QA开放式基准测试。
自动质量检查跟踪。直到2007年,这是TREC中最受欢迎的曲目之一(Dang等,2007; Agichtein等,2015)。它专注于为人类问题提供自动答案的任务。该曲目主要处理事实性问题,参与者提供的答案摘自新闻文章集。尽管任务逐渐发展为对日益现实的信息需求进行建模,解决问题序列,列出问题甚至进行交互式反馈,但仍然存在主要局限性:问题并非直接来自实时真实用户。
LiveQA曲目。该课程始于2015年(Agichtein et al。,2015),专注于实时回答用户问题。真实的用户问题,即尚未回答的在Yahoo Answers(YA)网站上提交的新问题,被发送到参与者系统,该系统实时提供答案。返回的答案由TREC编辑以4级Likert量表进行判断。 LiveQA恢复了已冻结了几年的流行QA跟踪,引起了QA研究界的极大关注。
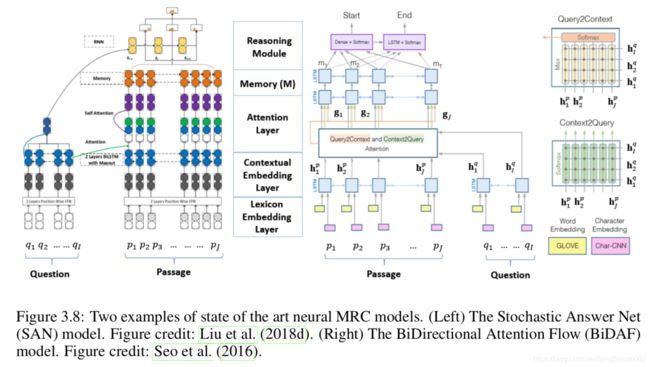
3.7神经MRC模型
本节中的描述基于在SQuAD上开发的最新模型,其中给定问题Q =(q1,...,qI)和段落P =(p1,...,pJ),我们需要在P中找到答案范围A =(开始,结束)
尽管模型结构和关注类型多种多样(Chen等,2016a; Xiong等,2016; Seo等,2016; Shen等,2017c; Wang等,2017b),典型神经MRC模型按三个步骤执行阅读理解,如图1.4所示:(1)将问题和段落的符号表示编码为神经空间中的一组向量; (2)在神经空间中进行推理以识别答案矢量(例如,在SQuAD中,这等效于对P中所有可能的文本跨度的嵌入矢量进行排名和重新排名)。 (3)将答案向量解码为在符号空间中输出的自然语言(例如,这等效于将答案向量映射到P中的文本跨度)。由于解码模块对于SQuAD模型非常简单,因此我们在下面的讨论中将重点放在编码和推理上。
图3.8显示了神经MRC模型的两个示例。 BiDAF(Seo等人,2016)是研究社区中使用最广泛的最先进的MRC基线模型之一,而SAN(Liu等人,2018d)是截至SQuAD1.1排行榜上记录最充分的MRC模型7 2017年12月19日。
3.7.1编码
大多数MRC模型通过三层对问题和段落进行编码:词典嵌入层,上下文嵌入层和注意层。
词典嵌入层。这将从单词级别的Q和P中提取信息,并规范化词汇变体。它通常使用预先训练的单词嵌入模型(例如word2vec(Mikolov等,2013)或GloVe(Pennington等,2014))将每个单词映射到向量空间,从而将语义相似的单词映射到向量它们在神经空间中彼此靠近(另请参阅第2.2.1节)。可以通过将每个单词嵌入向量与其他语言嵌入(例如从字符,词性(POS)标签和命名实体等派生的语言嵌入)进行级联来增强单词嵌入。给定Q和P,标记的单词嵌入Q中的是矩阵Eq∈Rd×I,P中的标记是Ep∈Rd×J,其中d是词嵌入的维数。这利用了周围单词的上下文提示来完善单词的嵌入。结果,同一单词可能会根据其上下文映射到神经空间中的不同向量,例如“河岸”与“美国银行”。这通常是通过使用双向长短期内存(BiLSTM)网络来实现的,8这是图2.2 RNN的扩展。如图3.8所示,我们分别在两个方向上放置了两个LSTM,并连接了这两个LSTM的输出。因此,我们获得矩阵Hq∈R2d×I作为Q的上下文感知表示,以及矩阵Hp∈R2d×J作为P的上下文感知表示。
ELMo(Peters等人,2018)是最先进的上下文嵌入模型之一。它基于深层BiLSTM。 ELMo不仅只使用BiLSTM的输出层表示形式,还结合了BiLSTM中的中间层表示形式,其中结合权重针对特定于任务的训练数据进行了优化。
BERT(Devlin et al。,2018)与ELMo和BiLSTM的不同之处在于,它旨在通过在所有层的左和右上下文上共同进行条件化来预训练深度双向表示。可以仅使用一个附加的输出层对预训练的BERT表示进行微调,以创建适用于各种NLP任务(包括MRC)的最新模型。
由于使用并行计算很难有效地训练RNN / LSTM,Yu等人。 (2018)提出了一种不需要RNN的新的上下文嵌入模型:其编码器仅包含卷积和自我注意,其中卷积模型局部交互而自我注意模型全局交互。与在GPU群集上基于RNN的模型相比,可以更快地训练这种模型一个数量级。
注意层。这耦合了问题和段落向量,并为段落中的每个单词生成了一组查询感知特征向量,并生成了执行推理的工作存储器M。这是通过注意过程9汇总来自Hq和Hp的信息来实现的,该过程包括以下步骤:
1.计算注意力分数,该分数表示哪个查询词与每个关键词最相关:sij =simθs(hqi,hpj)∈R对于Hq中的每个hqi,其中simθs是相似性函数,例如双线性模型,由θs。
2.通过softmax计算归一化注意权重:αij= exp(sij)/kexp(skj)。
3.通过hˆ pj =iαijhqi总结每个段落词的信息。因此,我们获得矩阵Hˆ p∈R2d×J作为P的问题感知表示。
接下来,我们在神经空间中形成工作记忆M为M =fθ(Hˆp,Hp),其中fθ是融合其输入矩阵(由θ参数化)的函数。 fθ可以是任意可训练的神经网络。例如,SAN中的融合功能包括串联层,自我注意层和BiLSTM层。 BiDAF在两个方向上计算注意力:从段落到问题Hˆ q以及从问题到段落Hˆ p。 BiDAF中的融合功能包括一个将三个矩阵Hp,Hˆ p和Hˆ q连接起来的层,以及一个两层的BiLSTM来为每个单词编码其相对于整个段落和查询的上下文信息。
3.7.2推理
MRC模型可以根据它们执行推理以生成答案的方式分为不同的类别:单步模型和多步模型。
单步推理。 单步推理模型仅将问题和文档匹配一次,并产生最终答案。 我们以图3.8(左)中的单步SAN10版本为例来描述推理过程。 我们需要找到工作记忆M上的答案范围(即起点和终点)。首先,总结的问题向量形成为

βi= exp(w⊤hqi)/kexp(w⊤hqk),以及可训练向量。然后,使用双线性函数通过以下方法获得整个通道的起始索引的概率分布:
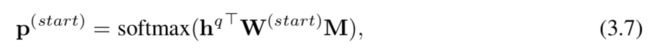
其中W(start)是权重矩阵。 另一个双线性函数用于获得结束索引的概率分布,其中结合了由等式获得的跨度开始的信息。 3.7,作为
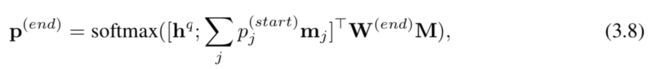
分号的地方; 指示向量或矩阵并置运算符,p(start)是j
段落中第j个单词是答案跨度的开始的概率,W(end)是权重矩阵,mj是M的第j个向量。
单步推理既简单又有效,并且可以使用经典的反向传播算法训练模型参数,因此大多数系统都采用了这种方法(Chen等人,2016b; Seo等人,2016; Wang等人,2016)。 ,2017b; Liu等人,2017; Chen等人,2017a; Weissenborn等人,2017; Hu等人,2017)。 但是,由于人类通常会在到达最终答案之前通过多次阅读和重新消化文档来解决提问任务(这可能是基于问题和文档的复杂性,如图3.9中的示例所示) ,很自然地想出一种迭代方法来找到答案,作为多步推理。
多步骤推理。 Hill等人率先提出了多步推理模型。 (2015); Dhingra等。 (2016); Sordoni等。 (2016); Kumar等。 (2016),他们使用了预定数量的推理步骤。沉等。 (2017b,c)表明,在两个不同的MRC数据集(SQuAD和MS MARCO)上,多步推理优于单步推理,而动态多步推理又优于固定多步推理。但是必须使用RL方法(例如策略梯度)来训练动态多步推理模型,由于不稳定问题,难以实施。 SAN结合了两种类型的多步骤推理模型的优势。如图3.8(左)所示,SAN(Liu等人,2018d)使用固定数量的推理步骤,并在每个步骤中生成预测。在解码期间,答案基于所有步骤中预测的平均值。但是,在训练期间,SAN会通过随机辍学丢弃预测,并根据剩余预测的平均值生成最终结果。尽管简单,但该技术显着提高了模型的鲁棒性和整体准确性。此外,可以使用简单有效的反向传播训练SAN。
以SAN为例,多步骤推理模块计算T个存储步骤,并输出答案范围。它基于RNN,类似于图3.5中的IRN。它维护一个状态向量,该向量在每个步骤上都会更新。最初,初始状态s0是由方程式Eqn计算得出的汇总问题向量。 3.6。在{1,2,...,T}范围内的时间步t处,状态由st = RNN(sg-1,xt)定义,其中xt包含使用先前状态向量作为a从内存中检索到的信息。通过关注过程进行查询:M:xt =jγjmj和γ= softmax(st-1⊤W(att)M),
其中W(att)是可训练的权重矩阵。最后,类似于方程式,使用双线性函数在每个推理步骤t处找到答案跨度的起点和终点。 3.7和3.8 其中p(start)是向量p(start)的第j个值,表示第j个通过的概率t,j t单词是推理步骤t答案范围的开始。
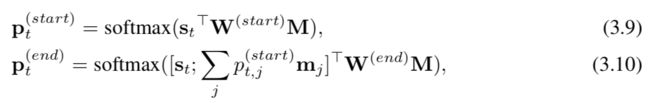
3.7.3培训
可以将神经MRC模型看作是一个深层神经网络,其中包括所有本身也是神经网络的组件模块(例如,嵌入层和推理引擎)。 因此,可以通过反向传播和SGD以端到端的方式对训练数据进行优化,如图1.4所示。 对于SQuAD模型,我们通过最小化定义为地面真实答案跨度起点和终点的负对数概率之和的损失函数,并通过预测分布对所有训练样本取平均值,来优化模型参数θ:

3.8会话文本QA代理
而所有的神经MRC模型均在本节中介绍。 3.7假设单回合的质量保证设置,实际上,人们经常在对话环境中提问(Ren等,2018a)。例如,用户可能会问“加利福尼亚何时成立?”的问题,然后根据收到的答案询问“加利福尼亚州的州长是谁?”和“人口是多少?”,两者均指“加利福尼亚州”。 -nia”是第一个问题。这个渐进的方面虽然使人类的对话变得简洁,但也提出了大多数最新的单轮MRC模型无法直接解决的新挑战,例如使用共指和务实推理回溯对话历史(Reddy等,2008)。 。,2018)。
对话型文本QA代理使用与图3.5相似的体系结构,不同之处在于,Soft-KB Lookup模块由文本QA模块代替,该模块由搜索引擎(例如Google或Bing)组成,该模块可检索与给定问题,以及一个MRC模型,该模型从检索的段落中生成答案。需要扩展MRC模型以解决对话设置中的上述挑战,此后称为对话MRC模型。
最近,已经开发了一些数据集来建立会话MRC模型。如图3.10所示,其中包括CoQA(会话问答(Reddy等人,2018))和QuAC(上下文问答(Choi等人,2018))。对话式MRC的任务定义如下。给定段落P,问题答案对{Q1,A1,Q2,A2,...,Qi-1,Ai-1}和问题Qi的形式的对话历史,MRC模型需要预测答案i
对话式MRC模型扩展了第2节中描述的模型。 3.7在两个方面。首先,扩展了编码模块,不仅可以对P和Ai进行编码,还可以对对话历史进行编码。其次,推理模块扩展为能够(可能不通过P)生成答案(通过实用推理)。例如,Reddy等。 (2018)提出了一个推理模块,将DrQA的跨文本MRC模型(Chen等人,2017a)和PGNet的生成模型(参见等人,2017)相结合。为了生成自由形式的答案,DrQA首先指向文本中的答案证据(例如,图3.10中的R5(右)),然后PGNet根据证据生成答案(例如,A5)。

图3.10:来自两个对话质量检查数据集的示例。 (左)QuAC数据集中的QA对话示例。 看不见段落(章节文字)的学生提出问题。 老师以文本跨度和对话行为的形式提供答案。 这些行为包括:(1)学生应该should→可以,→̄,还是可以̸→要求跟进; (2)确认(是/否),以及(3)否定答案。 图来源:Choi等。 (2018)。 (右)CoQA数据集中的QA对话示例。 每个对话回合都包含一个问题(Qi),一个答案(Ai)和支持该答案的基本原理(Ri)。 图来源:Reddy等。 (2018)。
Chapter 4
Task-oriented Dialogue Systems
本章重点介绍面向任务的对话系统,该系统可帮助用户解决任务。与用户寻求答案或某些信息的应用程序不同(上一章),此处讨论的对话通常用于完成任务,例如预订酒店或预订电影票。此外,与聊天机器人(下一章)相比,这些对话通常有特定的目标要实现,并且通常取决于域。
尽管面向任务的对话系统已经研究了数十年,但近年来,无论是在研究界还是在工业界,它们都迅速受到越来越多的关注。本章侧重于基础和算法方面,而第6章将讨论工业应用。此外,我们将对话仅限于用户输入以原始文本(而非口头语言)的形式进行的对话,而是其中的许多技术和讨论。本章可以适应口头对话系统。
本章组织如下。它从基本概念,术语和面向任务的对话系统的典型体系结构的概述开始。其次,它回顾了对话系统评估的代表性方法。该部分在很大程度上与用于构建这些系统的具体技术正交。接下来的三个部分重点介绍典型对话系统中的三个主要组成部分,重点介绍了最新的神经方法。最后,我们回顾了端到端对话系统的一些最新工作,这些工作是由深度学习和强化学习的交叉方面的最新进展所推动的,最后一节提供了进一步的讨论和建议。
4.1概述
我们从对面向任务的对话系统的简要概述开始,着重于有助于以后讨论的方面。欲了解更多信息和历史发展,请阅读Jurafsky和Martin的教科书(2018年,第25和26章)。
老虎机对话
在本章中,我们重点讨论相对简单但重要的一类对话,这些对话涉及在任务可以成功完成之前为一组预定的插槽填充值。这些对话(称为空位填充或表单填充)在实践中有许多用途。表4.1给出了用户与对话系统之间对话的示例。为了成功完成预订机票的交易,系统必须通过与用户交谈来收集必要的信息。

插槽填充对话框可以应用于许多其他域,例如电影(如上例所示),餐厅,机票预订等。对于每个域,一组插槽由域专家定义并且是特定于应用程序的。例如,在电影域中,诸如电影名称,剧院名称,时间,日期,门票价格,数量门票等插槽是必需的。
最后,如果该时隙的值可用于限制通话,例如电话号码,则该时隙称为“信息通知”。如果演讲者可以要求提供其值,则该时隙被称为可请求的作为门票价格。请注意,广告位可以是可告知的也可以是可请求的,例如电影名称。
对话行为
如上一示例所示,对话代理与用户之间的交互反映了RL代理与环境之间的交互(图2.5),其中用户的言语是观察,系统的言语是由用户选择的动作对话代理。对话行为理论为这种直觉提供了正式的基础(Core and Allen,1997; Traum,1999)。
在此框架中,用户或代理的话语被认为是可以更改用户和系统的(心理)状态,从而改变会话状态的动作。这些动作可以用来建议,告知,请求某些信息等等。迎接一个简单的示例对话行为,它对应于自然语言的句子,例如“你好!有什么我可以帮助的吗?”。它允许系统问候用户并开始对话。某些对话行为可能以插槽或插槽值对作为参数。例如,上面的电影预订示例中的以下问题:

对话作为最佳决策
配备了对话行为,我们准备将对话代理与用户之间的多回合对话建模为RL问题。 在这里,对话系统是RL代理,而用户是环境。 对话的每一步,
•座席根据对话中到目前为止显示的信息跟踪对话状态,然后采取措施; 该动作可以是对话动作形式的对用户的响应,或者是内部操作,例如数据库查找或API调用;
•用户以下一个话语做出响应,代理将在下一个回合中使用它来更新其内部对话状态;
•计算即时奖励以衡量此会话的质量和/或成本。
这个过程恰好是本节中讨论的主体与环境的相互作用。 2.3。 现在我们讨论如何确定奖励函数。

对话经理
关于建立(口语)对话管理器的文献很多。全面的调查超出了本章的范围。感兴趣的读者可以参考一些较早的示例(Cole,1999; Larsson和Traum,2000; Rich等,2001; Allen等,2001; Bos等,2003; Bohus和Rudnicky,2009)。以及McTear(2002),Paek和Pieraccini(2008)和Young等人的优秀调查。 (2013)了解更多信息。在这里,我们从本文采用的决策理论观点回顾一小部分传统方法。
Levin等。 (2000)认为对话是一个决策问题。 Walker(2000)和Singh等。 (2002年)是强化学习管理对话系统的两个早期应用。尽管这些方法很有希望,但它们假定对话状态只能采用有限的许多可能值,并且是完全可观察到的(即DST是完美的)。鉴于用户话语模棱两可以及NLU中不可避免的错误,这两个假设在现实世界的应用程序中经常被违反。
为了处理对话系统中固有的不确定性,Roy等人。 (2000)和Williams and Young(2007)提出使用部分可观察的马尔可夫决策过程(POMDP)作为用于建模和优化对话系统的有原则的数学框架。这个想法是将用户的话语作为观察,以保持未观察到的对话状态的后验分布。由于POMDP中的精确优化在计算上难以实现,因此作者研究了近似技术(Roy等人,2000; Williams and Young,2007; Young等人,2010; Li等人)。 (2009年; Gasic和Young,2014年)以及诸如信息状态框架之类的替代表示形式(Larsson和Traum,2000年; Daubigney等人,2012年)。尽管如此,与后面几节介绍的神经方法相比,这些方法通常需要更多领域知识来设计特征和设计状态。
传统方法的另一个重要限制是,图4.1中的每个模块通常都是单独优化的。因此,当系统运行不正常时,解决“信用分配”问题(即识别系统中的哪个组件会导致不期望的系统响应并需要改进)可能是一项挑战。确实,正如McTear(2002)所言,“成功对话系统的关键是将这些组件集成到工作系统中。”可区分的神经模型和强化学习的最新结合使对话系统得以优化。以端到端的方式,可能会提高对话质量;见第二节4.6,以供进一步讨论和有关该主题的最新著作。
4.2 Evaluation and User Simulation
评估一直是对话系统的重要研究课题。已经使用了不同的方法,包括基于语料库的方法,用户模拟,实验室用户研究,实际用户研究等。我们将讨论这些方法的优缺点,并在实践中进行权衡以找到最佳选择或他们的结合。
4.2.1评估指标
对话系统中的各个组件通常可以针对更明确定义的指标(例如准确性,准确性,召回率,F1和BLEU分数)进行优化,而评估整个对话系统则需要更全面的看法,并且更具挑战性(Walker等人(1997,1998,2000; Paek,2001; Hartikainen等,2004)。在强化学习框架中,这意味着奖励功能必须考虑对话质量的多个方面。在实践中,奖励函数通常是以下指标的子集的加权线性组合。
第一类指标衡量任务完成的成功程度。最常见的选择可能是任务成功率-成功解决用户问题(购买正确的电影票,找到合适的餐馆等)的对话比例。实际上,该度量对应的奖励每回合为0,但最后一次回合除外,在该回合中,成功对话为+1,否则为-1。在文献中发现了很多例子(Walker等,1997; Williams,2006; Peng等,2017)。还使用了其他变体,例如用于衡量部分成功的变体(Singh等,2002; Young等,2016)。
第二类度量对话中发生的成本,例如经过的时间。一个简单而有用的例子是转数,这是从希望的角度出发,在其他所有条件都相同的情况下,更简洁的对话是可取的。尽管存在更复杂的选择,但相应的报酬是每转一圈-1。(Walker等,1997)。
此外,对话质量的其他方面也可以编码到奖励函数中,尽管这是一个相对未充分研究的方向。在聊天机器人的背景下(第5章),连贯性,多样性和个人风格已被用来产生更多类似于人的对话(Li等,2016a,b)。它们对于面向任务的对话也很有用。在秒4.4.6,我们将回顾一些旨在从数据中自动学习奖励功能的近期著作。
4.2.2基于仿真的评估
通常,RL算法需要与用户进行交互才能学习(第2.3节)。但是在招募用户或实际用户上运行RL可能会很昂贵。解决这一难题的自然方法是建立一个模拟用户,RL算法实际上可以与该用户交互,而无需任何成本。本质上,模拟用户试图模仿真实用户在对话中的行为:它跟踪对话状态,并与RL对话系统进行对话。
大量研究已经投入到构建现实的用户模拟器中(Schatzmann等,2005a; Georgila等,2006; Pietquin和Dutoit,2006; Pietquin和Hastie,2013)。有许多不同的维度可对用户模拟器进行分类,例如确定性与随机性,基于内容的基于协作的,对话期间的静态与非静态用户目标等。在这里,我们重点介绍两个方面,并向感兴趣的用户推荐Schatzmann等。 (2006)进一步了解创建和评估用户模拟器的细节:
•在粒度维度上,用户模拟器可以在对话行为级别(也称为意图级别)或话语级别(Jung等,2009)运行。
•在方法论维度上,可以使用基于规则的方法或基于模型的方法(从真实会话语料库中学习模型)来实现用户模拟器。
基于议程的仿真。例如,我们描述了由Schatzmann和Young(2009)开发的一种流行的基于隐藏议程的用户模拟器,该方法在Li等人的论文中得到了实例化。 (2016d)和Ultes等。 (2017c)。每次对话模拟都从对话管理器未知的随机生成的用户目标开始。通常,用户目标由两部分组成:通知插槽包含许多插槽值对,这些对值用作用户要施加在对话上的约束;请求时隙是用户最初不知道其值的时隙,并且将在对话过程中被填写。图4.2显示了一个电影领域的示例用户目标,其中用户试图为明天的电影蝙蝠侠对超人购买3张票。
此外,为了使用户目标更切合实际,添加了特定于域的约束,因此要求某些位置出现在用户目标中。例如,要求用户知道她在电影域中想要的票数是有意义的。
在对话过程中,模拟用户会维护一个堆栈数据结构,称为用户议程。议程中的每个条目都与用户要实现的待定意图相对应,其优先级由议程堆栈中的后进先出操作隐式确定。换句话说,议程提供了一种方便的方式来编码对话历史记录和用户的“心态”。当显示更多信息时,用户的模拟归结为每次对话后如何维护议程。机器学习或专家定义的规则可用于在堆栈更新过程中设置参数。
基于模型的仿真。构建用户模拟器的另一种方法完全基于数据(Eckert等,1997; Levin等,2000; Chandramohan等,2011)。在这里,由于El Asri等人,我们描述了一个最近的例子。 (2016)。类似于基于议程的方法,模拟器还以随机生成的用户目标和约束开始情节。这些在对话过程中已修复。
在每个回合中,用户模型都将到目前为止在对话中收集的一系列上下文作为输入,并输出下一个动作。具体来说,对话时的上下文包括:
•最近的机器动作,
•机器信息和用户目标之间的不一致,
•约束状态,和•请求状态。
在这些上下文中,LSTM或其他序列到序列模型用于输出下一个用户话语。可以从人与人对话语料库中学习该模型。实际上,通过结合基于规则和基于模型的技术来创建用户模拟器,它通常可以很好地工作。
关于用户模拟的进一步说明。尽管在用户模拟方面已经进行了大量工作,但是构建类似人类的模拟器仍然具有挑战性。实际上,即使用户模拟器评估本身仍然是一个持续的研究主题(Williams,2008; Ai和Litman,2008; Pietquin和Hastie,2013)。在实践中,经常观察到在为另一个用户模拟器或真实人服务时,过分适合特定用户模拟器的对话策略可能无法很好地发挥作用(Schatzmann等,2005b; Dhingra等,2017)。用户模拟器和人类之间的鸿沟是基于用户模拟的对话策略优化的主要限制。
某些用户模拟器可公开用于研究目的。 Li等人提到的基于议程的模拟器除外。 (2016d); Ultes等。 (2017c)是一个具有评估环境的大型语料库,名为AirDialogue(在航班预订领域),最近才可用(Wei等人,2018)。在2018年举行的IEEE口语技术研讨会上,微软通过提供一个实验平台在多个领域提供内置的用户模拟器,组织了一场对话挑战,以构建端到端面向任务的对话系统。 2018)。
4.2.3基于人的评估
由于模拟用户和人类用户之间的差异,通常需要测试人类用户的对话系统以可靠地评估其质量。人类用户大致有两种类型。
首先是可能通过众包平台在实验室研究中招募的人类受试者。通常,要求参与者测试使用对话系统来解决给定任务(取决于对话的域),以便获得对话的集合。可以像模拟用户一样测量感兴趣的指标,例如任务完成率和每次对话的平均转弯次数。在其他情况下,要求这些受试者中的一小部分使用基准对话系统进行测试,以便可以将它们与各种指标进行比较。
许多涉及人类受试者的已发表研究都是第一类的(Walker,2000; Singh等,2002; Ai等,2007; Rieser and Lemon,2011; Gasˇić等,2013; Wen等,2015) ; Young等人,2016; Peng等人,2017; Lipton等人,2018)。尽管此方法相对于基于模拟的评估具有优势,但要获得大量可以长时间参与的主题却相当昂贵且耗时。因此,它具有以下限制:
•主题数量少,无法检测到统计上显着但数值上很小的度量差异,通常会导致不确定的结果。
•只能比较很少的对话系统。
•运行通过与这些用户进行交互来学习的RL代理通常是不切实际的,除了
在相对简单的对话应用程序中。
用于对话系统评估的另一类人员是实际用户(例如Black等人(2011年))。它们与第一类用户相似,不同之处在于它们附带了要与系统对话解决的实际任务。因此,对它们进行评估的指标甚至比对具有人工生成任务的新招募人类受试者所计算的指标更加可靠。此外,实际用户的数量可能会更大,从而导致评估的更大灵活性。在此过程中,可以使用许多在线和离线评估技术,例如A / B测试和反事实估计(Hofmann等,2016)。尝试使用实际用户的主要缺点是存在负面用户体验和正常服务中断的风险。
4.2.4其他评估技术
最近,研究人员已开始研究一种不同的评估方法,该方法受RL中的自我扮演技术的启发(Tesauro,1995; Mnih et al。,2015)。此技术通常用于两人游戏(例如围棋游戏)中,其中两个玩家都由同一个RL代理控制,初始化方式可能不同。通过与代理人对抗,可以以相对较低的成本生成大量轨迹,RL代理可以从中学习良好的策略。
自我演奏必须适合用于对话管理,因为参与对话的两个方通常扮演不对称角色(不同于诸如Go之类的游戏)。 Shah等。 (2018)描述了这种对话自演过程,该过程可以在模拟用户和系统代理之间生成对话。在谈判对话(Lewis等人,2017)和面向任务的对话(Liu和Lane,2017; Shah等人,2018; Wei等人,2018)中观察到了有希望的结果。它提供了一种有趣的解决方案,可以避免因涉及人类用户而导致的评估成本以及对不真实的模拟用户的过度拟合。
在实践中,采用混合方法进行评估是合理的。一种可能性是从模拟用户开始,然后验证或微调与人类用户的对话策略(参见Shah等人(2018))。此外,还有更系统的方法来使用两种用户来源进行策略学习(请参阅第4.4.5节)。
4.3自然语言理解和对话状态跟踪
NLU和DST是对话系统必不可少的两个紧密相关的组件。它们可能会对整个系统的性能产生重大影响(例如,参见Li等人(2017e))。本节回顾一些经典的和最新的方法。
4.3.1自然语言理解
NLU模块将用户话语作为输入,并执行三个任务:域检测,意图确定和插槽标记。图4.3给出了这三个任务的示例输出。通常,采用流水线方法,以便依次解决这三个任务。准确性和F1分数是用于评估模型的预测质量的两个最常用的指标。 NLU是对话系统中后续模块的预处理步骤,其质量对系统的整体质量有重大影响(Li等,2017d)。
其中,前两个任务通常被归类为一个分类问题,根据当前用户的话语推断出领域或意图(从一组预定义的候选对象中得出)(Schapire和Singer,2000; Yaman等,2008)。 ; Sarikaya et al。,2014)。在最近的文献中已经使用了神经分类方法来进行多类分类,其效果优于传统的统计方法。 Ravuri和Stolcke(2015; 2016)研究了标准循环神经网络的使用,发现它们更有效。对于必须从上下文中推断出信息的短句子,Lee and Dernoncourt(2016)提出使用递归和卷积神经网络,该网络也考虑了当前发声之前的文本。在多个基准测试中显示出更好的结果。
槽标签的更具挑战性的任务通常被视为序列分类,其中分类器为输入话语的子序列预测语义分类标签(Wang等,2005; Mesnil等,2013)。图4.3展示了一个由内而外开始(IOB)格式的ATIS(航空公司旅行信息系统)话语示例(Ramshaw和Marcus,1995),其中,每个单词的模型都用来预测语义标签。
姚等。 (2013)和Mesnil等。 (2015年)将递归神经网络应用于时隙标记,其中输入是话语中单词的一键编码,并且比诸如条件随机场和支持向量机之类的统计基线获得更高的准确性。此外,还表明,可以将先验单词信息有效地合并到基本的递归模型中,以进一步提高准确性。
例如,本节将按照Hakkani-Tür等人的描述,在NLU任务中使用双向LSTM(Graves和Schmidhuber,2005)或简称bLSTM。 (2016年),他还讨论了用于相同任务的其他模型。 如图4.4所示,该模型使用两组应用于输入序列(正向)和反向输入序列(反向)的LSTM单元。 向前和向后LSTM的串联隐藏层用作另一个神经网络的输入


其中ht-1是隐藏层,W⋆是可训练参数,g(·)是S型函数。 与标准LSTM中一样,ft和ot分别是输入,忘记和输出门。 后面的部分相似,输入相反。
为了预测如图4.3所示的时隙标签,输入的wt通常是单词嵌入向量的一个热向量。 根据以下分布pt预测输入wt时的输出:

上标(f)和(b)分别表示bLSTM的前向和后向部分。对于领域和意图分类之类的任务,在输入序列的末尾预测输出,并且可以使用更简单的体系结构(Ravuri和Stolcke,2015,2016)。
在许多情况下,仅当前的话语可能会模棱两可或缺少所有必要的信息。包含来自先前话语的信息的上下文有望帮助提高模型的准确性。 Hori等。 (2015年)将对话历史视为一长串单词,具有不同的角色(来自用户的单词与来自系统的单词),并提出了一种LSTM的变体,其中具有角色依赖层。 Chen等。 (2016b)建立在记忆网络上,该记忆网络在进行广告位标记预测时了解应该关注上下文信息的哪一部分。两种模型都比无上下文模型获得更高的准确性。
尽管通常会单独研究这三个NLU任务,但在多个域中联合解决它们(类似于多任务学习)还是有好处的,因此可能需要更少的标记为新域创建NLU模型时的数据(Hakkani-Tür等人,2016; Liu和Lane,2016)。 可以导致新域中的标签成本大幅降低的另一项有趣的工作是零镜头学习,通过嵌入时隙(文本)描述,在共享的潜在语义空间中表示来自不同域的时隙(Bapna 等人,2017; Lee和Jha,2019)。 感兴趣的读者可参考Chen和Gao(2017)和Chen等人的最新教程。 (2017e),了解更多详细信息。

4.3.2对话状态跟踪
在空位填充问题中,对话状态包含有关用户在当前对话时正在寻找什么的所有信息。此状态是对话策略所采用的输入,用于决定下一步应采取的措施(图4.1)。
例如,在餐厅域中,用户尝试进行预订,对话状态可能包含以下组件(Henderson,2015年):
•每个可告知时段的目标约束,其形式为该时段的值分配。该值可以是“无关”(如果用户没有偏好)或“无”(如果用户尚未指定该值)。
•用户要求系统通知的请求插槽的子集。
•当前的对话搜索方法,通过约束,替代方式获取值
并完成。它对用户尝试与对话系统进行交互的方式进行编码。
文献中也使用了许多替代方法,例如Kotti等人最近提出的紧凑的二进制表示形式。 (2018),以及Ren等人的StateNet跟踪器。 (2018b),它可以随着域大小(插槽数和插槽值数)进行扩展。
过去,DST可以由专家创建,也可以通过统计学习算法(例如条件随机字段)从数据中获取(Henderson,2015年)。最近,神经方法开始流行起来,其中较早的例子是深度神经网络(Henderson等,2013)和递归网络(Mrksˇić等,2015)的应用。
最新的DST模型是Mrksˇic等人提出的神经信仰追踪器。 (2017),如图4.5所示。该模型将三项作为输入。前两个是最后的系统话语和用户话语,每个话语都首先映射到内部矢量表示。作者研究了基于多层感知器和卷积神经网络的两种表示学习模型,它们都利用了预先训练的词向量集合,并为输入话语输出嵌入。第三个输入是DST跟踪的任何插槽值对。然后,这三个嵌入可以在它们之间进行交互以进行上下文建模,以从会话流和语义解码中提供更多的上下文信息,从而确定用户是否明确表达了与输入槽值对匹配的意图。最后,上下文建模和语义解码向量经过softmax层以产生最终预测。对所有可能的候选时隙值对重复相同的过程。
Lei等人探索了对话状态的另一种表示形式,称为信念跨度。 (2018)在Sequicity框架中。置信范围由两个字段组成:一个字段用于通知时隙,另一个字段用于请求时隙。每个字段都会收集到目前为止在会话中为各个插槽找到的值。信念范围和安全性的主要好处之一是,它有助于使用神经序列到序列模型来学习对话系统,该系统将信念范围作为输入和输出系统的响应。与更传统的流水线方法相比,这大大简化了系统设计和优化(参见第4.6节)。
对话状态跟踪挑战(DSTC)是一系列挑战,为对话状态跟踪提供了通用的测试平台和评估措施。从威廉姆斯等人开始。 (2013年),它成功吸引了许多研究团队专注于DST中的各种技术问题(Williams等,2014; Henderson等,2014b,a; Kim等,2016a,b; Hori等)。等人,2017)。 DSTC多年来使用的公司涵盖了人机对话和人与人之间的对话,以及餐厅和旅游者等不同领域的跨语言学习。可以在DSTC网站上找到更多信息。2
4.4对话政策学习
在本节中,我们将重点介绍基于强化学习的对话策略优化。
4.4.1用于策略优化的Deep RL
对话策略可以通过许多标准的强化学习算法来优化。有两种使用RL的方法:在线和批处理。在线方法要求学习者与用户互动以改进其政策;批处理方法假设有一组固定的过渡,并且仅基于数据优化策略,而无需与用户进行交互(例如,参见Li等人(2009); Pietquin等人(2011))。在本章中,我们将讨论通常将批处理学习作为内部步骤的在线设置。在批处理设置中,许多涵盖的主题可能很有用。在这里,我们以Lipton等人的DQN为例。 (2018),以说明基本工作流程。
模型:体系结构,培训和推理。 DQN的输入是当前对话状态的编码。一种选择是将其编码为特征向量,包括:(1)对话动作和对应于最后一个用户动作的广告位的单幅表示; (2)对话动作和对应于最后一个系统动作的时段的相同的一次性表示; (3)一袋与到目前为止对话中所有先前填充的插槽相对应的插槽; (4)当前转数; (5)知识库中与已填充的已知槽位约束匹配的结果数。用s表示此输入向量。
DQN输出实值向量,其条目对应于对话系统可以选择的所有可能的(对话动作,时隙)对。如果某些(对话动作,插槽)对对系统没有意义,例如request(price),则可以使用现有的先验知识来减少输出数量。用q表示该输出向量。

其中g(·)是激活函数,例如ReLU或S型。请注意,最后一层不需要
激活函数,并且输出q近似于状态s中的Q值Q(s,·)。
要学习网络中的参数,可以使用现成的强化学习算法(例如,具有经验重播的等式2.4或2.5);见第二节2.3获取确切的更新规则和改进的算法。一旦学习了这些参数,网络便会诱导出如下所示的贪婪动作选择策略:对于当前对话状态s,使用网络上的前向通过来计算q,即所有动作的Q值。可以选择一个动作,即(对话动作,槽)对,它对应于q中具有最大值的条目。由于需要探索,可能不需要上面的贪婪选择。见第二节4.4.2对此主题的讨论。
热启动政策。从头开始学习好的政策通常需要很多数据,但是可以通过使用专家生成的对话(Henderson等,2008)或老师的建议(Chen等,2017d)限制政策搜索,从而大大加快这一过程。 ,或在切换到与(模拟)用户的在线互动之前,将该策略初始化为合理的策略。
一种方法是使用模仿学习(也称为行为克隆)来模仿专家提供的策略。一种流行的选择是使用监督学习来直接了解某个状态下专家的行为;见Su等。 (2016b); Dhingra等。 (2017);威廉姆斯等。 (2017); Liu和Lane(2017)列举了一些最近的例子。 Li等。 (2014年)将模仿学习转化为诱导强化学习问题,然后应用了现成的RL算法来学习专家的政策。
最后,Lipton等。 (2018)提出了一种简单而有效的替代方法,称为重播缓冲区加标(RBS),特别适合DQN。这个想法是通过运行一个幼稚但偶尔会成功的基于规则的代理程序来生成少量对话,从而预填充DQN的体验重播缓冲区。在模拟研究中,该技术对于DQN必不可少。
其他方法。 在以上示例中,在DQN中使用了标准的多层感知器来近似Q函数。 它可能会被其他模型所取代,例如为有效探索而在下一个小节中描述的贝叶斯模型以及可以更轻松地从对话中捕获信息的循环网络(Zhao和Eskénazi,2016; Williams等,2017)。 历史比专家设计的对话状态要好。 在另一个最近的例子中,Chen等。 (2018年)使用图神经网络建模Q函数,图中的节点对应于域的插槽。 节点可以跨多个时隙共享一些参数,因此提高了学习速度。
此外,可以用策略梯度(2.3.2节)代替上述基于价值函数的方法,如Fatemi等人所做的。 (2016); Dhingra等。 (2017); Strub等。 (2017); 威廉姆斯等。 (2017); 刘等。 (2018a)。
4.4.2高效探索和领域扩展
在没有老师帮助的情况下,RL代理可以通过与最初未知的环境进行交互来从收集的数据中学习。通常,代理必须尝试在新状态下采取新措施,以发现可能更好的策略。因此,它必须在开发(选择好的行动以最大化报酬)和勘探(选择新颖的行动以发现可能更好的替代品)之间取得良好的权衡,从而导致需要有效的勘探(Sutton and Barto,2018)。在对话策略学习的背景下,这意味着策略学习者会积极尝试与用户进行对话的新方法,以期从长远来看发现更好的策略。参见,例如,Daubigney等。 (2011)。
虽然对有限状态RL的探索相对容易理解(Strehl等,2009; Jaksch等,2010; Osband和Roy,2017; Dann等,2017),但使用神经网络等参数模型时的探索是活跃的研究主题(Bellemare等,2016; Osband等,2016; Houthooft等,2016; Jiang等,2017)。在此,描述了一种通用的探索策略,该策略特别适合可能随时间演变的对话系统。
在部署了面向任务的对话系统为用户提供服务后,可能需要随着时间的流逝添加更多的意图和/或位置以使系统更加通用。这个问题称为域扩展(Gasˇic等人,2014),这使探索更具挑战性:代理商需要明确量化其意图/广告位参数的不确定性,以便在避免探索的情况下更积极地探索新事物。那些已经学过的。 Lipton等。 (2018)使用DQN的Bayesian-by-Backprop变体解决了这个问题。
他们的模型称为BBQ,与DQN相同,不同之处在于它在网络权重w =(w1,w2,...,wd)上保持后验分布q。为了便于计算,q是具有对角协方差的多元高斯分布,其参数为θ= {((i,ρi)} di = 1,其中权重wi具有高斯后验分布,N(μi,σi2)和σi= log(1 + exp(ρi))。后验信息根据汤普森抽样(汤普森,1933; Chapelle and Li,2012; Russo et al。,2018)的启发,提出了自然勘探策略。当选择动作时,代理简单地画出一个随机权重w ̃ q,然后选择网络输出的最高值的动作。实验表明,对于对话域扩展,BBQ的探索效率要高于最新基准。
BBQ模型是更新的。GivenobservedtransitionsT = {(s,a,r,s')},使用目标网络(请参见第2.3节)来计算T中每个(s,a)的目标值,从而得出D = {(x ,y)},其中x =(s,a)和y可以像DQN中那样计算。然后,更新参数θ以表示权重的后验分布。由于确切的后验不再是高斯,因此不能用BBQ表示,因此可以近似如下:通过最小化变分自由能来选择θ(Hinton和Van Camp,1993),变分近似q之间的KL散度(w |θ)和后验p(w | D):

4.4.3复合任务对话
在许多实际问题中,一个任务可能包含一组需要共同解决的子任务。同样,对话通常可以分解为一系列相关的子对话,每个子对话都集中于一个子主题(Litman和Allen,1987)。例如,考虑一个旅行计划对话系统,该系统需要以集体的方式预订机票,酒店和租车,以便满足某些跨子任务限制(称为时段限制)(Peng等人,2017年)。插槽限制是特定于应用程序的。在旅行计划问题中,一个自然的限制条件是出站航班的到达时间应早于酒店的登机时间。
Peng等人将具有时隙限制的复杂任务称为复合任务。 (2017)。针对复合任务优化对话策略具有挑战性,原因有二。首先,该策略必须处理许多插槽,因为每个子任务通常对应于具有自己的插槽组的域,并且复合任务的插槽组由所有子任务的插槽组成。此外,由于插槽限制,这些子任务无法独立解决。因此,复合任务考虑的状态空间要大得多。第二,复合任务对话通常需要完成更多的转弯。典型的奖励功能仅在整个对话结束时才给出成功或不成功的奖励。结果,该奖励信号非常稀疏并且大大延迟,从而使策略优化变得更加困难。
Cuayáhuitl等(2010)建议使用表格强化的MAXQ(Dietterich,2000)和分层抽象机器(Parr and Russell,1998)的方法,使用分层强化学习来优化复合任务的对话策略。尽管它们的解决方案很有希望,但它们假定的状态是有限的,因此不能直接应用于较大规模的会话问题。
最近,Peng等。 (2017年)在更通用的选择框架下解决了复合任务对话政策学习问题(Sutton等,1999b),其中任务层次分为两个层次。如图4.6所示,顶层策略πg选择要解决的子任务g,底层策略πa,g解决πg指定的子任务。假设有预定义的子任务,它们将扩展DQN模型,从而大大加快学习速度并提供更好的策略。 Budzianowski等人采用了类似的方法。 (2017),他使用高斯过程RL而非深度RL进行政策学习
在基于选项/子目标的层次强化学习中的主要假设是对合理选项和子目标的需求。唐等。 (2018)考虑了从对话示威中发现子目标的问题。受成功应用于机器翻译的序列分割方法的启发(Wang等人,2017a),作者开发了子目标发现网络(SDN),该网络学习了在成功对话中识别“瓶颈”状态的方法。结果表明,用SDN发现的子目标优化的分层DQN与专家设计的子目标相比具有竞争力。
最后,Casanueva等人进行了另一项有趣的尝试。 (2018)基于封建强化学习(FRL)(Dayan and Hinton,1993)。与上述将任务分解为时间上分离的子任务的方法相反,FRL在空间上分解复杂的决策。在对话的每一轮中,封建政策首先在信息收集行动和信息提供行动之间做出决定,然后根据这一高层决定来选择原始行动。
4.4.4多域对话
多域对话可以与用户交谈,以进行可能涉及多个域的对话(Komatani等,2006; Hakkani-Tür等,2012; Wang等,2014)。表4.2显示了一个示例,其中对话涵盖了酒店和饭店域,此外还有一个特殊的子对话元域,其中子对话包含与域无关的系统和用户响应。
与复合任务不同,对话中与不同域相对应的子对话是单独的任务,没有跨任务插槽限制。与复合任务系统相似,多域对话系统需要跟踪更大的对话状态空间,该对话空间具有来自所有域的时隙,因此直接应用RL可能效率低下。因此,这就需要学习可重用的策略,只要它们相互关联,就可以在多个域之间共享其参数。
Gasˇić等。 (2015)提出使用贝叶斯委员会机器(BCM)进行有效的多领域政策学习。在培训期间,针对不同的,可能很小的数据集对许多策略进行了培训。作者使用高斯过程RL算法优化了这些策略,尽管可以用深度学习替代方法来代替它们。在测试期间,在每次对话中,这些策略都会建议一项操作,并且所有建议都将汇总为最终措施,由BCM策略采取。
Cuayáhuitl等(2016年)开发了另一种相关技术,称为NDQN-DQN网络,其中,每个DQN都经过专门技能培训,可以在特定的子对话中进行交流。元策略控制着如何在这些DQN之间进行切换,也可以使用(深度)强化学习进行优化。
最近,Papangelis等人。 (2018a)研究了另一种方法,其中可以通过描述一个域的一组功能来共享针对不同域优化的策略。它被证明能够处理看不见的领域,从而减少了领域知识设计本体的需要。


4.4.5规划与学习的整合
如第二节所述。 4.2,优化针对人类的面向任务的对话的策略是昂贵的,因为它需要对话系统与人类之间的许多交互(图4.7的左图)。模拟用户为基于RL的策略优化提供了一种廉价的替代方法(图4.7的中间面板),但可能不是真实真实的人类用户近似值。
在这里,我们关注的是使用用户模型来生成更多数据,以改善优化对话系统时的样本复杂性。 Peng等人从Dyna-Q框架(Sutton,1990)中得到启发。 (4.7)提出了Deep Dyna-Q(DDQ)来处理深度学习模型的大规模问题,如图4.7右图所示。直观地,DDQ允许与人类用户和模拟用户进行交互。 DDQ的培训包括三个部分:
•直接强化学习:对话系统与真实用户互动,收集真实对话,并通过模仿学习或强化学习来改善政策;
•世界模型学习:使用直接强化学习收集的真实对话来完善世界模型(用户模拟器);
•计划:通过强化学习来改善针对模拟用户的对话策略。
在环实验表明,DDQ能够通过与真实用户进行交互来有效地改善对话策略,这对于在实践中部署对话系统非常重要。
DDQ的挑战之一是平衡来自真实用户(直接强化学习)和模拟用户(计划)的样本。 Peng等。 (2018)使用了一种启发式方法,当更多实际用户交互可用时,该方法可减少DDQ后期的计划步骤。相反,Su等。 (b)(2018b)提出了基于生成对抗网络的Discriminative Deep Dyna-Q(D3Q)。具体来说,它包含一个鉴别器,该鉴别器经过训练可以区分模拟用户的体验和真实用户的体验。在计划步骤中,仅根据区分项,模拟体验只有在它看起来是真实用户体验时才用于策略培训。
4.4.6奖励功能学习
对话策略通常经过优化,以在与用户互动时最大化长期奖励。因此,奖励功能对于创建高质量的对话系统至关重要。一种可能性是让用户在对话过程中或对话结束时提供反馈以对质量进行评分,但是这样的反馈是侵入性的且代价高昂的。通常,易于测量的数量(例如经过时间)用于计算奖励函数。不幸的是,实际上,设计适当的奖励功能并不总是很明显,并且需要大量的领域知识(第4.1节)。这激发了使用机器学习从数据中找到良好的奖励功能的能力(Walker等,2000; Rieser和Lemon,2008; Rieser等,2010; El Asri等,2012),它可以更好地与用户相关满意度(Rieser和Lemon,2011年),或更符合专家的论证(Li等,2014年)。
Su等。 (2015)提出用两个神经网络模型,即递归网络和卷积网络来评价对话的成功率。与使用用户目标先验知识的基准相比,发现他们的方法可以产生竞争性的对话政策。但是,这些模型假设以(对话,成功与否)对的形式提供标记数据的可用性,其中获得用户提供的成功与否反馈可能是昂贵的。为了降低标签成本,Su等人。 (2016a; 2018a)研究了一种基于高斯过程的主动学习方法,旨在在与人类用户互动的同时学习奖励功能和政策。
Ultes等。 (2017a)认为,对话的成功只能衡量对话政策质量的一个方面。针对信息搜索任务,作者提出了一种基于交互质量的新的奖励估算器,该交互器平衡了对话策略的多个方面。后来,Ultes等人。 (2017b)使用多目标RL来自动学习如何在奖励函数的定义中线性组合多个关注指标。
最后,在深度学习的对抗训练的启发下,Liu和Lane(2018)提出将奖励功能视为区分人和对话政策所产生的对话的区分器。因此,在他们的方法中有两个学习过程:奖励函数作为鉴别器,以及优化了对话策略以最大化奖励函数。作者表明,这种对抗性学习的奖励功能比手工设计的奖励功能可以带来更好的对话策略。
4.5自然语言生成
自然语言生成(NLG)负责将对话管理器选择的交流目标转换为自然语言形式。它是影响对话系统的自然性并影响用户体验的重要组件。
存在多种语言生成方法。在实践中,最常见的可能是基于模板或基于规则的模板,其中领域专家设计一组模板或规则,并通过手工启发法选择合适的候选词来生成句子。即使机器学习可以用来训练这些系统的某些部分(Langkilde和Knight,1998; Stent等,2004; Walker等,2007),但是编写和维护模板和规则的成本却导致了适应性挑战。新域或不同的用户群。此外,这些NLG系统的质量受到手工制作的模板和规则的质量的限制。
这些挑战推动了对更多数据驱动方法的研究,这些方法被称为基于语料库的方法,旨在优化语料库的生成模块(Oh和Rudnicky,2002; Angeli等,2010; Kondadadi等,2013)。 ; Mairesse and Young,2014年)。大多数此类方法基于监督学习,而Rieser和Lemon(2010)则采用决策理论观点,并使用强化学习在句子长度和所显示的信息之间进行权衡。3
近年来,人们对神经生成语言的方法越来越感兴趣。一个优雅的模型,称为语义控制的LSTM(SC-LSTM)(Wen等,2015),是LSTM的一种变体(Hochreiter and Schmidhuber,1997),具有一个额外的组件,可以对语言生成结果进行语义控制。 。如图4.8所示,一个基本的SC-LSTM单元有两个部分:一个典型的LSTM单元(图中的上部)和一个用于语义控制的句子计划单元(下部)。


其中ht-1是隐藏层,W⋆是可训练参数,g(·)是S型函数。 就像在标准LSTM单元中一样,ft和ot分别是输入,忘记和输出门。 引入SC-LSTM的额外组件是读取门rt,用于从原始对话动作d0开始计算一系列对话动作{dt}。 该顺序是为了确保所产生的话语表示预期的含义,并且读取门将控制要保留的信息以供将来使用。 从这个意义上说,rt扮演着句子计划的角色(Wen等,2015)。 最后,给定隐藏层ht,输出分布由softmax函数给出:

Wen等。 (2015年)提出了对基本SC-LSTM体系结构的一些改进。 一种是通过在图4.8的结构顶部堆叠多个LSTM单元来使模型更深。 另一个是话语重新排序:他们在反向输入序列上训练了另一个SC-LSTM实例,类似于双向递归网络,然后将这两个实例组合在一起以完成重新排序。
上面概述的基本方法可以几种方式扩展。 例如,Wen等。 Su等人(2016)研究了使用多域学习来减少训练神经语言生成器的数据量。 (2018c)提出了一种分层方法,该方法利用语言模式来进一步改善生成结果。 语言生成仍然是活跃的研究领域。 下一章将介绍更多有关聊天交流的最新作品,其中许多技术在面向任务的对话系统中也很有用。
4.6端到端学习
传统上,大多数对话系统中的组件是单独优化的。这种模块化方法提供了灵活性,允许以相对独立的方式构建和优化每个模块。但是,这通常会导致系统设计更加复杂,单个模块的改进并不一定会转化为整个对话系统的改进。相反,Lemon(2011)争论并在强化学习框架内通过经验证明了共同优化对话管理和自然语言生成的好处。最近,随着神经模型的日益普及,人们对联合优化多个组件甚至是对话系统的端到端学习的兴趣日益浓厚。
神经模型的好处之一是它们通常是可区分的,可以通过基于梯度的方法(例如反向传播)进行优化(Goodfellow等人,2016)。除了前面各节介绍的语言理解,状态跟踪和策略学习之外,还可以通过神经模型和反向传播学习语音识别和合成(用于口语对话系统),以实现最新技术性能(Hinton等,2012; van den Oord等,2016; Wen等,2015)。在极端情况下,如果面向任务的对话系统中的所有组件(图4.1)都是可区分的,则整个系统将成为一个更大的可区分系统,可以通过反向传播对量化整个系统总体质量的度量进行优化。与分别优化单个组件的传统方法相比,这是一个潜在的优势。建立端对端对话系统的方法一般有两种:
监督学习。首先是基于监督学习,首先收集所需的系统响应,然后将其用于训练对话系统的多个组件,以最大程度地提高预测准确性(Bordes等,2017; Wen等,2017; Yang等人,2017b; Eric等人,2017; Madotto等人,2018; Wu等人,2018)。
Wen等。 (2017)引入了模块化的神经对话系统,其中大多数模块都由神经网络表示。但是,他们的方法依赖于不可区分的知识库查找运算符,因此对组件的培训是在有监督的方式下进行的。 Dhingra等人解决了这一挑战。 (2017)提出“软”知识库查找;见第二节3.5了解更多详情。
Bordes等。 (2017)将对话系统学习视为学习从对话历史到系统响应的映射的问题。它们显示出在许多模拟对话任务上,内存网络和有监督的嵌入模型均优于标准基线。 Madotto等人采用了类似的方法。 (2018)在他们的Mem2Seq模型中。该模型使用了指针网络的机制(Vinyals等人,2015a),以便整合知识库中的外部信息。
最后,埃里克等。 (2017)提出了一种端到端可训练的键值检索网络,该网络在知识库条目上配备了基于注意力的键值检索机制,可以学习从知识库中提取相关信息。
强化学习。虽然监督学习方法可以产生令人鼓舞的结果,但它们需要获得可能昂贵的训练数据。此外,这种方法不允许对话系统探索不同的政策,而这些政策可能比产生针对有监督培训的响应的专家政策更好。这激发了使用强化学习来优化端到端对话系统的另一项工作(Zhao和Eskénazi,2016; Williams和Zweig,2016; Dhingra等,2017; Li等,2017d; Braunschweiler和Papangelis ,2018; Strub等,2017; Liu和Lane,2017; Liu等,2018a)。
Zhao和Eskénazi(2016)提出了一个以用户话语为输入并输出语义系统动作的模型。他们的模型是基于LSTM的DQN的递归变体,该模型学习压缩用户话语序列以推断对话的内部状态。与经典方法相比,该方法能够联合优化策略,语言理解和状态跟踪,超越标准的监督学习。
Williams等人采用的另一种方法。 (2017),是使用LSTM避免状态跟踪工程的繁琐步骤,并共同优化状态跟踪器和策略。他们的模型称为混合代码网络(HCN),也使工程师可以通过软件和操作模板轻松整合业务规则和其他先验知识。他们表明HCN可以进行端到端的培训,这表明它比几种端到端技术要快得多。
Strub等。 (2017)应用了策略梯度,以优化GuessWhat?中基于视觉的任务导向型对话。以端到端的方式进行游戏。在游戏中,用户和对话系统都可以访问图像。用户秘密地选择图像中的对象,并且对话系统通过询问用户是-否问题来定位该对象。
最后,可以在端到端的可培训系统中结合监督学习和强化学习。刘等。 (2018a)提出了这种混合方法。首先,他们利用人与人对话的监督学习对政策进行了预训练。其次,他们使用了一种称为DAgger的模仿学习算法(Ross等,2011),以与可以建议正确对话动作的人类老师进行协调。在最后一步中,强化学习用于通过在线用户反馈继续进行政策学习。
4.7进一步说明
在本章中,我们对面向任务的对话系统的最新神经方法进行了调查,重点研究了空位填充问题。这是一个具有许多令人兴奋的研究机会的新领域。尽管不能涵盖所有较一般的对话问题和所有研究方向,但仍不在本文讨论范围之内,我们仅简要介绍其中的一小部分以结束本章。
除了老虎机对话之外。实际上,面向任务的对话比填补空缺的对话更加多样化和复杂。寻求信息或导航对话是另一个在不同环境中提到的流行示例(例如Dhingra等人(2017),Papangelis等人(2018b)和第3.5节)。另一个方向是丰富对话环境。我们的日常对话通常是多模式的,而不是纯文本或仅语音的对话,并且涉及视觉等语言和非语言输入(Bohus等人,2014; DeVault等人,2014; de Vries等人,2017; Zhang et al。,2018a)。诸如如何组合来自多种方式的信息以做出决策之类的挑战自然而然地出现了。
到目前为止,我们已经研究了涉及两方的对话-用户和对话代理,后者是为前者提供帮助。一般而言,任务可能会更加复杂,例如混合发起对话(Horvitz,1999)和谈判(Barlier等,2015; Lewis等,2017)。一般而言,对话中可能涉及多个参与者,转弯变得更具挑战性(Bohus和Horvitz,2009,2011)。在这种情况下,采取博弈论的观点比单代理决策中的MDP观点更为笼统是有帮助的。
学习信号较弱。在文献中,可以通过监督学习,模仿学习或强化学习来优化对话系统。有些需要专家标签/演示,而有些则需要来自(模拟)用户的奖励信号。还有其他一些较弱的学习信号形式,可以促进大规模的对话管理。一个有前途的方向是考虑优先输入:而不是对政策质量有绝对的判断(以标签或奖励的形式),只需要一个优先输入即可表明两个对话中哪一个更好。这种可比的反馈通常更容易获得且更便宜,并且比绝对反馈更可靠。
相关领域。评价仍然是主要的研究挑战。尽管用户模拟可能是有用的(第4.2.2节),但更有吸引力且更可靠的解决方案是直接使用真实的人与人对话语料库进行评估。不幸的是,这个问题在RL文献中被称为非政策评估,在当前的众多研究工作中都具有挑战性(Precup等,2000; Jiang和Li,2016; Thomas和Brunskill,2016; Liu等,2018c) 。在评估和优化对话系统中,这种非政策性技术可以找到重要的用途。
另一相关研究领域是应用于文本游戏的深度强化学习(Narasimhan等人,2015; Coˆté等人,2018),在很多方面与对话类似,只是场景是由游戏设计师预先定义的。解决文字游戏的最新进展,例如处理自然语言动作(Narasimhan等人,2015; He等人,2016; Coté等人,2018)和可解释的政策(Chen等人,2017c)可能会激发灵感类似的算法,对于面向任务的对话很有用。
Chapter 5
Fully Data-Driven Conversation Models and Social Bots
研究人员最近开始探索完全数据驱动和端到端(E2E)的方法来生成对话响应,例如在序列到序列(seq2seq)框架内(Hochreiter和Schmidhuber,1997; Sutskever等人) (2014年)。这些模型完全由数据训练而成,而无需借助任何专家知识,这意味着它们不依赖于第4章中提到的对话系统的四个传统组成部分。这种端到端模型在社交机器人(chitchat)上尤其成功在这种情况下,社交机器人很少需要与用户环境进行交互,并且缺少诸如API调用之类的外部依赖项,从而简化了端到端培训。相比之下,任务完成方案通常需要例如知识库访问形式的API。该框架在chitchat上取得成功的另一个原因是,它可以轻松扩展到大型的自由格式和开放域数据集,这意味着用户通常可以在自己喜欢的任何话题上聊天。尽管社交机器人在促进人类及其设备之间的流畅交互方面具有至关重要的意义,但最近的工作也集中在超越建议的场景上,例如推荐。
5.1端到端对话模型
大多数最早的端到端(E2E)对话模型均受统计机器翻译(SMT)的启发(Koehn等,2003; Och和Ney,2004),包括神经机器翻译(Kalchbrenner和Blunsom)。 ,2013; Cho等,2014a; Bahdanau等,2015)。转换会话响应生成任务(即根据先前的对话转弯Ti-1预测响应Ti)是SMT问题,这是相对自然的问题,因为可以将转弯Ti-1视为“外来句子” ”,然后将Ti设为其“翻译”。这意味着可以将任何现成的SMT算法应用于会话数据集,以构建响应生成系统。这是最初在完全数据驱动的对话式AI的第一批作品(Ritter等,2011)中提出的想法,该论文将基于短语的翻译方法(Koehn等,2003)应用于从Twit中提取的对话数据集。 -ter(Serban et al。,2015)。 (Jafarpour et al。,2010)提出了一种不同的E2E方法,但是它依赖于基于IR的方法,而不是机器翻译。
尽管与早期的对话工作相比,这两篇论文构成了范式转变,但它们有一些局限性。它们最大的局限性在于它们将数据表示为(查询,响应)对,这阻碍了它们生成适合上下文的响应的能力。这是一个严重的局限性,因为在座谈会上对话的时间通常很短(例如,一些话语,例如“真的吗?”),在这种情况下,会话模型迫切需要更长的上下文才能产生合理的响应。这种局限性激发了Sordoni等人的工作。 (2015b),提出了一种基于RNN的会话响应生成方法(类似于图2.2),该方法利用了更长的上下文。连同同期工作(Shang等人,2015; Vinyals和Le,2015),这些论文提出了首个完全E2E对话建模的神经方法。尽管这三篇论文具有一些不同的属性,但它们都是基于RNN架构的,如今,它们通常使用长短期记忆(LSTM)模型进行建模(Hochreiter和Schmidhuber,1997; Sutskever等人,2014)。
5.1.1 LSTM模型
我们在这里概述基于LSTM的响应生成,因为LSTM可以说是最受欢迎的seq2seq模型,尽管诸如GRU(Cho等人,2014b)之类的替代模型通常同样有效。 LSTM是图2.2中表示的RNN模型的扩展,并且在利用长期上下文方面通常更有效。 基于LSTM的响应生成系统通常按以下方式建模(Vinyals和Le,2015; Li等,2016a):给定对话历史,表示为一系列单词S = {s1,s2,...,sNs} (S代表源),LSTM将每个时间步k与输入,存储器和输出门相关联,分别表示为ik,fk和ok。 Ns是源S.1中的单词数。然后,对于每个时间步k,LSTM的隐藏状态hk如下计算:

其中矩阵Wi,Wf,Wo,Wl属于Rd×2d,◦表示按元素乘积。 由于它是响应生成任务,因此每个会话上下文S与一系列输出单词配对以进行预测:T = {t1,t2,...,tNt} .2 LSTM模型定义了预测下一个令牌的概率 使用softmax函数:3

5.1.2 HRED模型
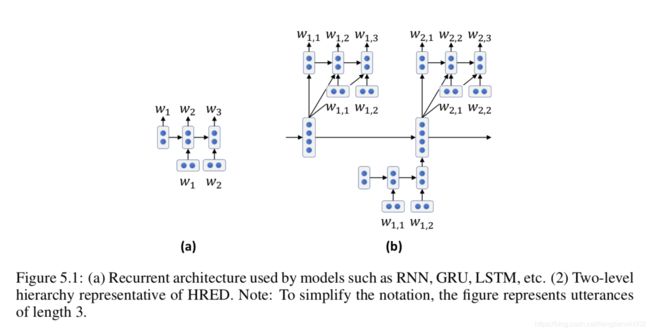
尽管已证明LSTM模型可以有效地编码多达500个单词的文本上下文(Khandelwal等人,2018),但对话历史往往很长,有时需要利用长期上下文。分层模型旨在通过捕获更长的上下文来解决此限制(Yao等,2015; Serban等,2016,2017; Xing等,2018)。一种流行的方法是分层递归编码器-解码器(HRED)模型,该模型最初在(Sordoni等,2015a)中提出,用于查询建议,并在(Serban等,2016)中用于响应生成。
HRED体系结构如图5.1所示,在此处将其与标准RNN体系结构进行了比较。 HRED使用包含两个RNN的两级层次结构对对话进行建模:一个在单词级别,一个在对话回合级别。这种体系结构模拟了对话历史由一系列转弯组成的事实,每个转弯由一系列记号组成。该模型引入了一个时间结构,该结构使当前对话的隐藏状态直接取决于先前对话的隐藏状态,有效地使信息在更长的时间跨度内流动,并有助于减少消失的梯度问题(Hochreiter,1991)。 ,这是一个限制RNN(包括LSTM)建模非常长的单词序列的能力的问题。请注意,在此特定工作中,使用GRU(Cho等人,2014b)而非LSTM实现了RNN隐藏状态。
5.1.3注意模型
seq2seq框架在文本生成任务(例如机器翻译)中非常成功,但是将整个源序列编码为固定大小的向量具有一定的局限性,特别是在处理长源序列时。基于注意力的模型(Bahdanau等人,2015; Vaswani等人,2017)通过允许模型在源句中与预测下一个目标单词相关的部分进行搜索和条件调整来减轻此限制,从而远离一个仅将单个序列表示为单个固定大小矢量的框架。虽然注意力模型和变体(Bahdanau等人,2015; Luong等人,2015等)在翻译的最新技术(Wu等人,2016)中取得了重大进展,并且非常如今,注意力模型在E2E对话建模中的有效性有所降低。注意模型可以有效地尝试“联合翻译和对齐”(Bahdanau等人,2015),这可以解释这一事实,这是机器翻译的理想目标,因为源序列(外来句)中的每个信息片段通常需要在目标(翻译)中只传达一次,但这在对话数据中不太正确。的确,在对话中使用印第安语进行对话的软资源可能无法映射到目标和副词上,反之亦然。4一些特定的对话注意模型已被证明是有用的(Yao等,2015; Mei等,2017; Shao等,2017),例如,避免单词重复(在第5.2节中进一步讨论)。
5.1.4指针网络模型
seq2seq框架的多个模型扩展(Gu等,2016; He等,2017a)提高了模型在对话上下文和响应之间“复制和粘贴”单词的能力。与其他任务(例如翻译)相比,此功能在对话中尤其重要,因为响应通常会重复输入的范围(例如,“早安”响应“早安”)或使用诸如专有名词之类的稀有单词,该模型将难以使用标准RNN生成。这些模型最初是由Pointer Network模型(Vinyals等,2015a)启发而来的,该模型产生了一个由输入序列中的元素组成的输出序列,这些模型假设目标词是从固定大小的词汇表(类似于A seq2seq模型)或使用关注机制从源序列(类似于指针网络)中选择。该模型的一个实例是CopyNet(Gu et al。,2016),由于其能够重复输入的专有名词和其他单词的能力,它被证明比RNN有了显着改进。
5.2挑战与补救
响应生成任务面临着对话建模特有的挑战。最近的许多研究旨在解决以下问题。
5.2.1反应淡淡
神经反应产生系统产生的言语通常是平淡无奇的。虽然在其他任务(例如图像字幕)中已经注意到了这个问题(Mao等人,2015),但是在端到端响应生成中,这个问题尤为严重,因为常用的模型(例如seq2seq)往往会产生非信息性的响应,例如“我不要”不知道”或“我很好”。 Li等。 (2016a)认为这是由于他们的训练目标,根据p(T | S)优化了训练数据的可能性,其中S是来源(对话历史),T是目标反应。目标p(T | S)在T和S中是不对称的,这导致训练有素的系统更喜欢无条件享有高概率的响应T,即与上下文S无关。例如,此类系统通常会响应“ I don “不知道” S是否是一个问题,因为对于几乎所有问题,“我不知道”的回答都是合理的。 Li等。 (2016a)建议将条件概率p(T | S)替换为
互信息p(T,S)为目标,因为后一个公式在S和T中是对称的,因此p(T)p(S)
因此,除非学习数据本身出现这种偏差,否则它不会鼓励学习者将响应T偏向平淡无奇和偏斜。虽然这个论点在总体上可能是正确的,但优化互信息目标(也称为最大互信息或MMI(Huang等,2001))可能具有挑战性,因此Li等。 (2016a)在推断时使用了该目标。更具体地说,给定对话历史记录S,推断时的目标是根据以下条件找到最佳的T:5

引入超参数λ来控制惩罚通用响应的程度,
配方:6

因此,该加权的MMI目标函数可以视为代表给定目标(即p(S | T))的源和给定目标源(即p(T | S))之间的折衷,这也是响应之间的折衷适当和缺乏冷淡。注意,尽管如此,Li等人。 (2016a)并没有完全解决平淡性问题,因为该目标仅用于推理,而不用于训练时间。该方法首先根据p(T | S)生成N个最佳列表,然后使用MMI重新对其进行评分。由于基于p(T | S)推断标准(波束搜索),这样的N个最佳列表通常总体上相对平淡,因此MMI评分通常可以缓解而不是完全消除平淡问题。
最近,研究人员(Li等,2017c; Xu等,2017; Zhang等,2018e)使用了广告训练和生成对抗网络(Goodfellow等,2014),这经常是有减少乏味的作用。直观上,GAN对乏味的影响可以理解为:对抗训练将生成器和判别器使用极小极大目标彼此相对(因此称为“对抗”术语),并且每个目标的目的都是使它们的对应物成为最不有效。生成器是要部署的响应生成系统,而鉴别器的目标是能够识别给定的响应是由人类生成(即从训练数据中生成)还是生成器的输出。然后,如果生成器始终响应“我不知道”或其他偏向响应,则在大多数情况下,鉴别器将其与人为响应区分开来几乎没有问题,因为大多数人不响应“我不知道” “ 每时每刻。因此,为了欺骗鉴别器,生成器逐渐避开了这种可预测的响应。更正式地说,当假设分布与预言分布匹配时,就可以实现GAN的最优性,从而鼓励生成的响应扩展以反映真实响应的真实多样性。为了促进更多的多样性,Zhang等人。 (2018e)明确优化查询和响应之间的成对相互信息的变异下界,以鼓励在训练期间生成更多的信息性响应。

Serban等。 (2017)提出了一种潜在的可变层次递归编码器/解码器(VHRED)模型,该模型还旨在产生更少的乏味和更具体的响应。通过向目标添加高维随机潜在变量,它扩展了本章前面介绍的HRED模型。这个附加的潜在变量旨在解决与浅层生成过程相关的挑战。如(Serban et al。,2017)所述,从推理的角度来看,此过程存在问题,因为生成模型被迫在逐个单词的基础上产生高级结构(即整个响应)。在VHRED模型中,此生成过程变得更容易,因为该模型利用了确定响应的高级方面(主题,名称,动词等)的高维潜在变量,因此该模型的其他部分可以专注于发电的较低层面,例如确保流利。如(Serban et al。,2017)的样本输出所建议的,VHRED模型顺便帮助减少了乏味。实际上,由于响应的内容以潜在变量为条件,因此,如果潜在变量确定响应应如此,则生成的响应仅是乏味的且没有语义内容。最近,Zhang等。 (2018b)提出了一个模型,该模型还引入了一个额外的变量(使用高斯核层进行建模),该变量被添加以控制响应的特异性水平,从平淡到非常具体。
虽然本章前面调查的大多数响应生成系统都是基于生成的(即逐字生成新句子),但缓解这种乏味的更为保守的解决方案是将基于生成的模型替换为基于检索的模型以生成响应( Jafarpour et al。,2010; Lu and Li,2014; Inaba and Takahashi,2016; Al-Rfou et al。,2016; Yan et al。,2016),其中预先建立了可能的反应池(例如,预先存在的人类反应)。这些方法以降低灵活性为代价:在生成时,可能的响应集的词数呈指数增长,但是检索系统的响应集是固定的,因此此类检索系统通常没有任何适当的响应用于许多对话输入。尽管有此限制,但检索系统已在流行的商业系统中广泛使用,我们将在第6章中对其进行调查。
5.2.2扬声器一致性
研究表明,流行的seq2seq方法通常会产生不连贯的对话(Li等,2016b),例如该系统可能与上一回合(有时甚至是同一回合)所说的相矛盾。 )。虽然这种效果中的一些可以归因于学习算法的局限性,但Li等人。 (2016b)表明,这种不一致的主要原因可能是由于训练数据本身。确实,对话数据集(请参阅第5.5节)具有多个发言人,他们通常具有不同或相冲突的角色和背景。例如,对于问题“您几岁?”,seq2seq模型可以给出有效的响应,例如“ 23”,“ 27”或“ 40”,所有这些都在训练数据中表示。这将响应生成任务与更传统的NLP任务区分开来:虽然针对其他任务(例如机器翻译)的模型是在语义上大多为一对一的数据上训练的,但是对话数据通常是一对多或多对多的7就像任何一种学习算法一样,要做到一对多训练,所以需要一种更具表现力的模型,该模型可以利用更丰富的输入来更好地评估此类多样化的响应。 Li等。 (2016b)使用基于角色的响应生成系统做到了这一点,该系统是Sec的LSTM模型的扩展。 5.1.1除了单词嵌入外,还使用说话人嵌入。直观地讲,这两种类型的嵌入类似地工作:虽然单词嵌入形成了一个潜在空间,在该潜在空间中,空间接近度(即低欧几里得距离)意味着两个单词在语义上或功能上都接近,而说话者嵌入也构成了一个潜在空间,其中两个附近的讲话者倾向于以相同的方式交谈,例如具有相似的说话风格(例如,英式英语)或经常谈论相同的话题(例如,运动)。像单词嵌入一样,说话者嵌入参数与模型的所有其他参数共同从其一键表示中学习。在推论时,只需要指定所需说话者的一键编码即可产生反映她说话风格的响应。图5.2显示了模型的整体架构,该图显示了每个目标隐藏状态不仅取决于先前的隐藏状态和当前单词嵌入(例如,“ England”),而且还取决于说话者的嵌入(例如, ,“ Rob”)。该模型不仅有助于生成更多的个性化响应,而且还可以减轻前面提到的一对多建模问题。
其他方法也利用个性化信息。例如,Al-Rfou等。 (2016年)提出了基于角色的响应生成模型,但适用于使用包含21亿个响应的超大型数据集进行检索。使用深度神经网络将其检索模型实现为二进制分类器(即响应良好与否)。他们模型的显着特征是多损失目标,它增加了响应R,输入I,说话人(“作者”)A和情境C的单损失模型p(R | I,A,C),通过添加辅助损失,例如,模拟给定作者p(R | A)的响应概率。事实证明,这种多重损失模型非常有帮助(Al-Rfou等人,2016年),因为多重损失有助于应对以下事实:作者的某些特质经常与情境或投入相关,这使得它很难学习好的演讲者嵌入表示。通过增加p(R | A)的损失,该模型能够为作者学习更具特色的说话者嵌入表示。
最近,Luan等人。 (2017)提出了Li等人的说话人嵌入模型的扩展。 (2016b),它将在会话数据集上训练的seq2seq模型与在非会话数据上训练的自动编码器结合在一起,其中seq2seq和自动编码器组合在多任务学习设置中(Caruana,1998)。捆绑seq2seq和自动编码器的解码器参数可启用Luan等。 (2017)训练一个给定角色的响应生成系统,而实际上并不需要该角色的任何对话数据。这是他们方法的优势,因为给定用户或角色的对话数据可能并不总是可用。在(Bhatia et al。,2017)中,(Li et al。,2016b)的概念被扩展到社交图嵌入模型。
虽然(Serban等人,2017)本身不是基于角色的响应生成模型,但他们的工作与诸如(Li等人,2016b)的发言人嵌入模型有一些相似之处。确实,Li等人。 (2016b)和Serban等。 (2017)在模型的目标端引入了一个连续的高维变量,以使响应偏向于矢量中编码的信息。在(Serban et al。,2017)的情况下,该变量是潜在的,并且通过最大化对数似然概率的变化下界来训练。在(Li et al。,2016b)的情况下,变量(即说话人嵌入)在技术上也是潜在的,尽管它是说话人一键式表示的直接函数。 (Li et al。,2016b)可能适用于发话级别信息(例如,说话者ID或主题)。另一方面(Serban et al。,2017)的优势在于,它学习的潜变量可以最好地``解释''数据,并且可以根据严格的演讲者或主题信息来学习比最优的表示形式。 。
5.2.3单词重复
单词或内容重复是除机器翻译以外的神经生成任务的常见问题,正如响应生成,图像字幕,视觉故事生成和通用语言建模等任务所指出的那样(Shao等,2017; Huang等) (2018年; Holtzman等人,2018年)。机器翻译是相对一对一的任务,其中源中的每条信息(例如名称)通常在目标中只传递一次,而其他任务(如对话或故事生成)的约束要少得多,并且源中给定的单词或短语可以映射到目标中的零个或多个单词或短语。这有效地使响应生成任务更具挑战性,因为生成给定的单词或短语并不能完全排除再次生成同一单词或短语的需要。注意模型(Bahdanau等,2015)有助于防止机器翻译中的重复错误,因为该任务是一对一的8,最初为机器翻译设计的注意模型(Bahdanau等,2015; Luong等) (例如,2015年),通常无助于减少对话中的单词重复。
鉴于上述限制,邵等人。 (2017)提出了一种新模型,该模型增加了解码器的自注意力,旨在改善更长和连贯响应的生成,同时顺便缓解单词重复问题。目标方的注意力可以帮助模型更轻松地跟踪到目前为止在输出中已生成的信息9,从而使模型可以更轻松地区分不必要的单词或短语重复。
5.2.4进一步的挑战
以上问题是重要的问题,仅能部分解决,需要进一步研究。然而,这些端到端系统面临的更大挑战是响应的适当性。如第1章所述,与传统的对话系统相比,早期的E2E系统最鲜明的特征之一是它们缺乏基础。当被问及“明天的天气预报是什么?”时,E2E系统可能会产生诸如“晴天”和“多雨”的响应,而没有选择一个或另一个响应的原则基础,因为上下文或输入可能甚至不会指定地理位置。 Ghazvininejad等。 (2018)认为seq2seq和类似模型通常非常擅长产生具有合理整体结构的响应,但是由于缺乏基础,在生成与现实世界相关的名称和事实时经常会遇到困难。换句话说,响应通常在语用上是正确的(例如,一个问题通常会跟一个答案,而道歉则是轻描淡写),但是响应的语义内容通常是不合适的。因此,最近的E2E对话研究越来越集中在设计扎根的神经对话模型上,我们将在下面进行调查。
5.3地面会话模型
与面向任务的对话系统不同,大多数E2E对话模型都不是建立在现实世界中的,这会阻止这些系统有效地与用户环境相关的任何事物进行对话。这种局限性也源于机器翻译,机器模型和需求都没有基础。产生神经反应的最新方法是通过将说话者或收件人的角色中的接地系统(Li等人,2016b; Al-Rfou等人,2016),文本知识来源(例如Foursquare)(Ghazvininejad等人, (2018),用户或代理人的视觉环境(Das等,2017a; Mostafazadeh等,2017),以及用户的情感或情感(Huber等,2018; Winata等,2017; Xu等) 。,2018)。从较高的角度来看,这些作品中的大多数都具有共同的想法,即增强上下文编码器以不仅代表对话历史记录,而且还代表从用户环境中提取的一些其他输入,例如图像(Das等,2017a; Mostafazadeh等人,2017)或文字信息(Ghazvininejad等人,2018)。
作为这种基础模型的说明性示例,我们简要概述了Ghazvininejad等人。 (2018),其基本模型如图5.3所示。该模型主要由两个编码器和一个解码器组成。解码器和对话编码器与标准seq2seq模型的相似。额外的编码器称为事实编码器,它会输入模型中
与对话历史记录相关的事实信息或所谓的事实,例如与在对话历史记录中提及的餐馆(例如,“ Kusakabe”)有关的餐馆评论(例如,“令人惊奇的寿司品尝”)。尽管本文的模型是通过Foursquare评论进行训练和评估的,但这种方法并没有特别假设接地点包括评论,或者触发词是餐馆(实际上,某些触发词是例如酒店和博物馆) 。为了找到与对话有关的事实,他们的系统使用IR系统,使用从对话上下文中提取的搜索词,从大量事实或世界事实(例如,几个大城市的所有Foursquare评论)中检索文本。虽然该模型的对话编码器是标准的LSTM,但事实编码器是Chen等人的内存网络的一个实例。 (2016b),它使用关联记忆对与特定问题相关的事实进行建模,在这种情况下,这是对话中提到的一家餐馆。
这种方法和其他类似的基于会话对话建模的工作有两个主要好处。首先,该方法将E2E系统的输入分为两个部分:来自用户的输入和来自其环境的输入。这种分离至关重要,因为它解决了早期E2E(例如seq2seq)模型的局限性,该模型始终对同一查询(例如,“明天的天气预报是什么?”)做出确定性的响应。通过将输入分为两个来源(用户和环境),系统可以根据现实世界中发生的变化有效地对同一用户输入生成不同的响应,而无需重新培训整个系统。其次,与标准seq2seq方法相比,该方法的采样效率更高。对于一个没有基础的系统来产生如图5.3所示的响应,该系统将要求在对话训练数据中可以看到任何用户可能会谈论的每个实体(例如,“ Kusakabe”餐厅),这是不现实的,不切实际的假设。虽然语言建模数据(即非对话数据)的数量丰富并且可以用于训练基础的对话系统(例如,使用Wikipedia,Foursquare),但可用的对话数据的数量通常受到更多限制。扎实的会话模型没有这个限制,例如,Ghazvininejad等人的系统。 (2018)可以就会话培训数据中甚至未提及的场所进行交谈。

5.4 Beyond Supervised Learning
会话训练数据(人与人)与设想的在线方案(人机)之间常常存在很大的脱节。这使得难以针对特定目标优化对话模型,例如通过减少乏味来最大化参与度。监督学习设置的另一个局限性是他们倾向于立即获得奖励(即一次响应一次)而不是长期获得奖励的优化趋势。这也部分地解释了为什么他们的回复通常很平淡,从而无法促进长期的用户参与。为了解决这些局限性,一些研究人员探索了E2E系统的强化学习(RL)(Li等,2016c),可以通过人在环境体系结构进行增强(Li等,2017a,b)。与RL面向任务的对话不同,E2E系统面临的主要挑战是缺乏明确的成功指标(即奖励功能),部分原因是它们必须处理非正式的流派,例如用户的闲聊没有明确指定目标。
Li等。 (2016c)构成了在完全E2E方法中使用RL进行会话响应生成的首次尝试。 Li等人的系统没有像(Sordoni等人,2015b; Vinyals and Le,2015)的监督设置那样在人与人之间的对话中训练系统。 (2016c)是通过与模仿人类用户行为的用户模拟器进行对话来进行训练的。如图5.4所示,人类用户必须替换为用户模拟器,因为使用成千上万次真实用户对话来训练RL系统非常昂贵。在这项工作中,标准的seq2seq模型用作用户模拟器。该系统使用策略梯度进行了培训(第2.3节)。目的是在由用户模拟器和要学习的代理生成的对话中最大化预期的总奖励。更正式地说,目标是
![]()
其中R(。)是奖励函数,而Ti是对话转弯。 可以通过使用梯度下降法来优化上述目标,方法是将对话的对数概率和聚集的奖励考虑在内,这与模型参数无关:

其中p(Ti | Ti-1)的参数化方法与Sec的标准seq2seq模型相同。 5.1.1,不同之处在于此处的模型是使用RL优化的。上面的梯度通常是使用采样来近似的,Li等人。 (2016c)对每个参数更新都使用了一个采样的会话。虽然以上策略梯度设置在RL中相对普遍,但是学习对话模型的主要挑战是如何设计有效的奖励功能。 Li等。 (2016c)使用了三个奖励函数的组合,这些函数旨在缓解监督的seq2seq模型的问题,该模型在其工作中用作初始化参数。三种奖励功能是:
•-p(Dull Response | Ti):Li等。 (2016c)创建了一个简短的沉闷响应列表,例如从训练数据中选择的“我不知道”。该奖励功能对可能导致任何这些迟钝响应的那些匝数Ti进行惩罚。这被称为“易于回答奖励”,因为它促进了不太难于回应的对话转折,从而使用户参与到对话中。例如,奖励功能对响应为“我不知道”的转弯给予非常低的奖励,因为这种回避的响应表明上一转弯很难响应,最终可能终止对话。
•− log Sigmoid cos(Ti-1,Ti):此信息流奖励函数可确保Ti-1和Ti的相交匝数彼此之间不太相似(例如,“您好吗?”后跟“如何?你?”),如李等人。 (2016c)认为,很少有新信息的对话通常不会参与,因此更有可能被终止。
•log p(Ti-1 | Ti)+ log p(Ti | Ti-1):引入这种有意义的奖励功能是为了抵消上述两个奖励。例如,另外两个奖励功能更喜欢对话类型,这些对话不断地引入新信息并频繁地更改主题,以至于用户难以追随。为了避免这种情况,意义奖励功能鼓励对话会话中的连续轮流彼此相关。
5.5资料
Serban等。 (2015年)提出了对现有数据集的全面调查,这些数据集除了E2E和社交机器人研究之外还有用。端到端对话建模与其他NLP和对话任务的不同之处在于,数据的可用量非常大,这在一定程度上要归功于社交媒体(例如Twitter和Reddit)。另一方面,大多数社交媒体数据既不能重新分发,也不能通过语言资源组织(例如语言数据联盟)获得,这意味着仍然没有建立的公共数据集(使用Twitter或Reddit)来训练和测试响应发电系统。尽管这些社交媒体公司提供了API访问权限,使研究人员可以下载相对少量的社交媒体帖子,然后从它们重建对话,但是这些公司指定的严格的法律服务条款不可避免地会影响研究的可重复性。最值得注意的是,Twitter通过API无法使用某些tweet(例如,撤回的tweet或来自暂停用户的tweet),并要求删除任何此类先前下载的tweets。因此,很难建立任何标准的训练或测试数据集,而将其浪费掉。10因此,在本章中引用的大多数论文中,他们的作者创建了自己的(子集)对话数据进行训练和测试,然后针对这些系统的基准和竞争系统进行了评估。固定数据集。道奇等。 (2016年)使用现有的数据集定义标准的训练和测试集,但规模相对较小。一些最著名的端到端和聊天集数据集包括:
•Twitter:Twitter数据自第一个数据驱动的响应生成系统(Ritter等,2011)以来使用,提供了几乎无限制的大量对话数据,因为Twitter每天产生的新数据比大多数系统开发人员所能提供的更多handle.11虽然可以通过Twitter API将数据本身作为单独的推文进行访问,但其元数据可以轻松地构建对话历史记录,例如,两个用户之间的对话历史记录。该数据集构成了2017年DSTC Task 2竞赛的基础(Hori和Hori,2017)。
•Reddit:Reddit是一种社交媒体资源,实际上也不受限制,截至2018年7月,对话次数约为32亿次。例如,Al-Rfou等人使用过。 (2016年)建立了大规模的响应检索系统。 Reddit数据是按主题(即“ subreddits”)组织的,其响应与Twitter相比没有字符限制。
•OpenSubtitles:此数据集由可在opensubtitles.org网站上提供的字幕组成,该网站提供许多不同语言的商业电影的字幕。截至2011年,该数据集包含约80亿个单词,采用多种语言(Tiedemann,2012年)。
•Ubuntu:Ubuntu数据集(Lowe等,2015)也已广泛用于E2E对话建模。 它与其他数据集(如Twitter)的不同之处在于,它较少关注聊天,而更注重目标,因为它包含许多特定于Ubuntu操作系统的对话。
•Persona-Chat数据集:开发此众包数据集(Zhang等人,2018c)是为了满足对话显示不同用户角色的对话数据的需求。 在收集“角色聊天”时,要求每个工作人员模仿使用五个事实描述的给定角色。 然后,那个工人试图保持性格,参加了对话。 所得数据集包含约16万个语音。
5.6评估
评估是诸如计算机翻译和摘要之类的生成任务的长期研究课题。端到端对话也是如此。虽然通常使用人工评估者来评估响应生成系统(Ritter等,2011; Sordoni等,2015b; Shang等,2015等),但是这种类型的评估通常很昂贵,研究人员经常不得不借助自动指标来量化日常进度并执行自动系统优化。端到端对话研究主要使用机器翻译和摘要中的那些指标,使用字符串和n元语法匹配指标,例如BLEU(Papineni等人,2002)和ROUGE(Lin,2004)。最近提出的METEOR(Banerjee和Lavie,2005年)旨在通过识别系统输出和人类参考之间的同义词和释义来改善BLEU,并已被用于评估对话。 deltaBLEU(Galley等人,2015)是BLEU的扩展,它利用了与会话响应相关的数字评分。
关于这种自动度量标准是否实际上适合评估会话响应生成系统,已经有很多争论。例如,刘等。 (2016)指出,这些机器翻译指标大多数与人类判断之间的关联性很差,因此认为它们不合适。然而,他们的相关性分析是在句子级别上进行的,但是长期以来,即使对于机器翻译,也很难实现体面的句子级别相关性(Callison-Burch等,2009; Graham等,2015)。 [12]特别是,BLEU(Papineni et al。,2002)从一开始就被设计为语料库级别而非句子级别的指标,因为基于n元语法匹配的评估在单个句子上计算时比较脆弱。确实,Koehn(2004)的经验研究表明,BLEU在包含少于600个句子的测试集上并不可靠。 Koehn(2004)的研究是关于翻译的,这项任务可以说比响应生成更简单,因此在对话中超越句级关联的需求可能甚至变得更为关键。在语料库或系统级别进行度量时,相关性通常远高于句子级别(Przybocki等,2009),例如,对于WMT翻译任务的最佳指标,Spearmanρ高于0.95(Graham和Baldwin) ,2014).13在对话的情况下,Galley等人。 (2015年)表明,基于字符串的度量标准(BLEU和deltaBLEU)的相关性随着度量单位大于句子而显着增加。具体来说,当对每个100个响应的语料库进行相关性测量时,他们的Spearman的ρ系数从句子级别的0.1(基本上没有相关性)提高到接近0.5。
最近,Lowe等人。 (2017)提出了一种用于端到端对话评估的机器学习指标。他们提出了VHRED模型的一种变体(Serban等,2017),该模型以上下文,用户输入,黄金和系统响应作为输入,并在1到5之间产生定性得分。由于VHRED对于建模对话非常有效,因此Lowe等等(2017)在句子水平上获得了令人印象深刻的Spearman的ρ相关系数0.42。另一方面,该指标可训练的事实会导致其他潜在问题,例如过拟合和“衡量指标的博弈”(Albrecht和Hwa,2007年)14,这也许可以解释为什么先前提出了机器学习的评估指标(Corston- Oliver等人,2001; Kulesza和Shieber,2004; Lita等人,2005; Albrecht和Hwa,2007;Giménez和Ma`rquez,2008; Pado等人,2009;Stanojević和Sima'an,2014等)在官方机器翻译基准中并不常用。 “可衡量指标”的问题可能很严重,例如,在经常将自动评估指标直接用作培训目标的情况下(Och,2003; Ranzato等,2015),因为系统开发人员可能不了解意外的“游戏”。如果直接根据可训练的指标对生成系统进行了优化,则该系统和指标将类似于GAN中的对抗对(Goodfellow等,2014),生成系统(Generator)的唯一目标就是愚弄指标(判别器)。可以说,相比于像BLEU这样的相对无参数的度量标准,这种尝试通常具有数千或数百万个参数,而这种可训练的度量标准通常包含数千或数百万个参数,而BLEU被认为对这种利用相当健壮,并且被证明是直接优化的最佳度量标准(Cer等人,2010年)以及其他基于字符串的指标。为了防止使用机器学习的度量标准,需要像GAN中那样迭代训练“生成器”和“鉴别器”,但是文献中大多数可训练的度量标准都没有利用这种迭代过程。建议用于对话和相关任务的对抗设置(Kannan和Vinyals,2016; Li等,2017c; Holtzman等,2018)提供了解决此问题的解决方案,但众所周知,此类设置具有不稳定性(Sal -imans等人,2016年),原因在于GANs minimax公式的性质。这种脆弱性可能会带来麻烦,因为自动评估的结果在理想情况下应该是稳定的(Cer等人,2010),并且随着时间的推移是可重现的,例如,跟踪多年来E2E对话研究的进展。所有这些都表明,自动评估E2E对话还远没有解决问题
例如,在WMT共同任务的正式报告中,Callison-Burch等人。 (2009年,第6.2节)计算了流行指标与句子等级上的人类排名相符的时间百分比,但是对于句子层次研究而言,结果并不理想:“许多指标未能达到[随机]基线(包括英语以外的大多数指标)。这表明机器翻译质量的句子级评估非常困难。”
13在迄今为止规模最大的系统级相关性研究之一中,Graham和Baldwin(2014)发现,BLEU与最近提出的大多数翻译指标相比具有相对的竞争力,因为它们表明“目前没有足够的证据表明有很大比例的指标需要得出他们的表现胜过BLEU”。进行对话需要进行如此大规模的研究。
14在讨论机器学习的评估指标的潜在陷阱时,Albrecht和Hwa(2007)举例说,“谨慎地防范系统可能会利用其功能的子集。”在深度学习的情况下,这种游戏让人想起对输入进行非随机扰动,从而极大地改变网络的预测,例如,通过(Szegedy等人,2013)中的图像来展示如何轻松地欺骗深度学习模型。但是,如果要将机器学习的度量标准变成标准评估,则很难防止此类游戏,并且这大概需要模型参数可公开获得。
5.7开放基准
开放式基准测试是在许多AI任务(例如语音识别,信息检索和机器翻译)中取得进展的关键。尽管端到端对话式AI是一个相对新生的研究问题,但已经开发了一些开放基准:
•对话系统技术挑战(DSTC):2017年,DSTC首次提出了“端对端对话建模”轨道15,该轨道要求系统使用Twitter数据完全由数据驱动。后续挑战(DSTC7)中的两项任务集中在扎实的对话场景上。一种侧重于视听场景感知对话,另一种侧重于基于外部知识(例如Foursquare和Wikipedia)的响应生成,其对话摘自Reddit.16
•ConvAI竞赛:这是NIPS竞赛,迄今为止已在两个会议上进行过介绍。它以Amazon Mechanical Turk资金的形式提供奖品。竞赛旨在“针对非目标对话系统的培训和评估模型”,并在2018年使用Persona-Chat数据集(Zhang等人,2018c)以及其他数据集。
•NTCIR STC:该基准测试侧重于“通过短文本”进行对话。第一个基准测试针对基于检索的方法,并于2017年扩展到评估基于生成的方法。
•Alexa奖:2017年,亚马逊组织了一场公开比赛,以构建“社交机器人”,该机器人可以在一系列时事和主题上与人类对话。竞赛使参与者能够与真实用户(Alexa用户)一起测试他们的系统,并提供一种间接监督的形式,因为要求用户对与每个Alexa奖系统的每次对话进行评分。首届奖项由15个学术团队组成(Ram等,2018).17
•JD对话挑战:18这是公司(JD.com)组织的又一项挑战。像Alexa奖一样,JD挑战赛也为获奖者提供了可观的奖金,并授予参与者访问真实用户和客户数据的权限。
Chapter 6
Conversational AI in Industry
本章描述了行业对话系统的概况,包括面向任务的系统(例如,个人助理),质量保证系统和聊天机器人。
6.1问答系统
包括Google,Microsoft和Baidu在内的搜索引擎公司已将多回合质量检查功能纳入其搜索引擎,以使用户体验更多的对话性,这对于移动设备尤其有吸引力。 由于公众对这些系统的内部结构知之甚少(例如Google和百度),因此本节介绍了一些示例性商业QA系统,其体系结构至少已在公共资源中得到了部分描述,包括Bing QA,Satori QA和客户支持 代理商。
6.1.1 Bing质量检查
Bing QA是Web级文本QA代理的一个示例。它是Microsoft Bing Web搜索引擎的扩展。如图6.1所示,Bing QA不会返回十个蓝色链接,而是通过使用MRC模型读取Bing Web搜索引擎检索的段落来生成对用户查询的直接答案。
Bing QA处理的Web QA任务比第3章中描述的大多数MRC学术任务更具挑战性。例如,Web QA和SQuAD的不同之处在于:
•文本集合的规模和质量。 SQuAD假定答案是段落中的文本范围,该段落是Wikipedia页面上的纯文本部分。 Web质量检查需要从数十亿个Web文档中找出答案,这些Web文档由数万亿个嘈杂的段落组成,由于Web内容的动态性质,这些段落通常包含矛盾,错误,过时的信息。
•运行时延迟。在学术环境中,MRC模型可能需要几秒钟才能读取和重新读取文档以生成答案,而在Web质量检查设置中,要求MRC部分(例如在Bing质量检查中)添加的时间不得超过10毫秒。整个服务堆栈。
• 用户体验。虽然SQuAD MRC模型提供文本范围作为答案,但是Web QA需要根据显示答案的不同设备提供不同的用户体验,例如,移动设备中的语音答案或搜索引擎结果中的丰富答案。页面(SERP)。图6.1(右)显示了“迪斯尼是哪一年购买了lucasfilms?”问题的SERP示例,其中Bing QA不仅以高亮度文本跨度显示答案,还提供各种支持证据和相关的Web搜索与答案一致的结果(即,检索到的文档的标题,段落,音频和视频)。
结果,诸如Bing QA之类的商业Web QA代理通常在其Web搜索引擎堆栈顶部将MRC模块作为后Web组件合并。 Bing QA代理的概述如图6.1(左)所示。考虑到“迪士尼在哪一年购买了lucasfilms?”这个问题,通过快速的主排名器从Web Index检索了一组候选文档。然后,在“文档排名”模块中,使用基于增强树的复杂文档排名(Wu等,2010)来为这些文档分配相关性得分。排名最高的相关文档以SERP的形式显示,其标题由“以查询为焦点的”字幕模块生成,如图6.1(右)所示。 “通道分块”模块将顶级文档划分为一组候选通道,然后由“通道排名”模块根据另一个通道级别的增强树分级器对其进行排名(Wu等人,2010)。最后,MRC模块从排名最高的段落中识别出答案范围“ 2012”。
尽管将Bing质量检查变成了Sec的会话质量检查代理。 3.8要求集成其他组件,例如对话管理器,这是一项艰巨的持续工程工作,Bing QA已经可以使用对话查询理解(CQU)模块来处理对话查询(例如,跟进问题)(Ren等人。,2018a)。如图6.2中的示例所示,CQU分两个步骤将会话查询重新构造为对搜索引擎友好的查询:(1)确定查询是否依赖于同一搜索会话中的上下文(即先前的查询和答案),并且( 2)如果是这样,则重写该查询以包括必要的上下文,例如,在图6.2中用“加利福尼亚”替换“它”,并在图5中的Q5中添加“斯坦福”。

6.1.2 Satori质量检查
Satori QA是KB-QA代理的一个示例,如Sec。 3.1–3.5。 Satori是Microsoft的知识图,由Freebase植入,现在比Freebase大几个数量级。 Satori QA是同时使用神经方法和符号方法的混合系统。 它为事实问题提供答案。
与Web QA相似,Satori QA必须处理有关可伸缩性,嘈杂的内容,速度等问题。提高系统的鲁棒性和运行时效率的一种常用设计策略是将一个复杂的问题分解为一系列更简单的问题,这可以 Web规模的KB-QA系统可以更轻松地回答问题,并通过重组答案序列来计算最终答案,如图6.3所示(Talmor and Berant,2018)。
6.1.3客户支持代理
包括Microsoft和Salesforce在内的多家IT公司已经开发了各种客户支持代理。 这些代理是多回合会话KB-QA代理,如3.5中所述。
给定用户对问题的描述,例如“无法更新我的帐户的个人信息”,代理商需要推荐预编译的解决方案或请人工代理商提供帮助。 对话通常由多个回合组成,因为代理要求用户在浏览知识库以查找解决方案时阐明问题。 这些代理通常将文本和语音作为输入。


6.2面向任务的对话系统(虚拟助手)
如今,面向商业任务的对话系统通常驻留在智能电话,智能扬声器和个人计算机中。 他们可以为用户执行一系列任务或服务,有时也称为虚拟助手或智能个人助手。 一些示例服务正在提供天气信息,设置警报和呼叫中心支持。 在美国,使用最广泛的系统包括Apple的Siri,Google Assistant,Amazon Alexa和Microsoft Cortana等。 用户可以通过语音,文本或图像与他们自然互动。 要使用语音激活虚拟助手,可以使用一个唤醒词,例如“ OK Google”。

还有许多快速增长的工具可用于促进虚拟助手的开发,包括亚马逊的Alexa Skills Kit1,IBM的Watson Assistant2以及Microsoft和Google的类似产品。全面的调查不属于本节的范围,并且并非所有此类工具的信息都可以公开获得。在这里,我们将对其中的示例进行高级描述:
•Microsoft的任务完成平台(TCP)(Crook等,2016)是用于创建多域对话系统的平台。如图6.4所示,TCP遵循与图4.1相似的结构,其中包含语言理解,状态跟踪和策略。 TCP的一项有用功能是任务配置语言TaskForm,它使单个任务的定义与平台的总体对话策略脱钩。 TCP用于支持Cortana个人助理支持的许多多回合对话。
•Microsoft的另一种工具是LUIS,这是一种用于了解自然语言的基于云的API服务3。它提供了一套预先构建的领域和意图,以及方便非专业人员使用机器学习通过提供训练示例来获得NLU模型的界面。一旦开发人员创建并发布了LUIS应用程序,该应用程序就可以被客户端对话系统用作NLU黑盒模块:客户端向应用程序发送文本语音,该语言将以JSON格式返回语言理解结果,如图所示。图6.5。
•虽然LUIS专注于语言理解,但是Azure Bot Service4允许开发人员在一个地方构建,测试,部署和管理对话系统。它可以利用一系列智能服务的优势,包括LUIS,图像字幕,语音到文本功能等。
•DialogFlow是Google的开发套件,用于在网站,移动设备和IoT设备上创建对话系统。5与上述工具类似,它提供了促进对话系统各个模块开发的机制,包括语言理解和多轮交流信息。此外,它可以将对话系统部署为用户可以通过Google Assistant调用的动作。

6.3聊天机器人
几十年来,一直存在可公开使用的对话系统(Weizenbaum,1966; Colby,1975)。但是,今天的聊天机器人系统的这些前身在很大程度上依赖于手工制定的规则,与第5章中讨论的数据驱动的对话式AI系统的种类几乎没有共通之处。相比之下,当今的公共和商业聊天机器人系统通常是统计方法和手工制作的组件,其中统计方法为会话系统提供了鲁棒性(例如,通过意图分类器),而基于规则的组件仍经常在实践中使用,例如,处理常见的聊天查询(例如,“告诉我”笑话”)。此类系统的示例包括诸如亚马逊的Alexa,Google助手,Facebook M和微软的Cortana之类的私人助理,这些私人助理除了具有个人助理技能外,还可以处理闲聊的用户输入。其他商业系统,例如XiaoIce,6 Replika,(Fedorenko等人,2017)
Zo,7和Ruuh8几乎完全专注于闲聊。由于公众对主要商业系统(Alexa,Google Assistant等)内部的了解相对较少,因此本节的其余部分着重于其体系结构在某些公共资源中至少已部分描述的商业系统。
最早的此类系统之一是XiaoIce,该系统于2014年首次发布。XiaoIce被设计为具有情感联系的AI伴侣,可以满足人类对沟通,情感和社会归属感的需求(Zhou等人,2018)。 XiaoIce的总体架构如图6.7所示。它由三层组成。
•用户体验层:它将XiaoIce连接到流行的聊天平台(例如,微信,QQ),并以两种通信模式处理对话。全双工模块处理基于语音流的对话,用户和XiaoIce可以同时进行对话。另一个模块处理基于消息的对话,用户和XiaoIce必须轮流交谈。
•对话引擎层:在每个对话回合中,首先使用状态跟踪器更新对话状态,然后通过对话策略选择核心聊天(和主题)或对话技巧以生成响应。 XiaoIce的独特组件是移情计算模块,该模块不仅可以理解用户输入的内容(例如主题),还可以理解对话和用户的移情方面(例如情感,意图,对主题的看法,以及用户的背景和总体兴趣),并确保生成适合小冰的角色的移情反应。核心聊天是XiaoIce的另一个核心模块。它结合了神经生成技术(第5.1节)和基于检索的方法(Zhou等,2018)。如图6.6所示,XiaoIce能够产生具有社会吸引力的回应(例如,具有幽默感,安慰感等),并且可以确定例如在对话中是否推动对话(“推动”)有点停滞不前,或者用户参与时是否进行主动聆听9。
•数据层:它由一组数据库组成,这些数据库存储收集的人类对话数据(以文本对或文本-图像对的形式),用于核心聊天和技能的非对话数据和知识图,XiaoIce的配置文件以及所有进行经验计算的注册用户。

用于chitchat的Replika系统(Fedorenko等,2017)结合了基于神经生成和基于检索的方法,并且能够像(Mostafazadeh等,2017)一样在图像上调节响应。 Replika的神经生成组件是基于角色的(Li等,2016b),因为它经过训练可以模仿特定角色。虽然Replika是一家公司,但Replika系统已经开源10,因此可以用作未来研究的基准。
Alexa奖赏系统(Ram等,2018)是面向真实用户的社交聊天机器人,因此拥有Alexa设备的任何人都可以与这些社交机器人进行交互并为其评分。这种互动是通过“ Alexa,让我们聊天”命令触发的,该命令随后触发有关用户或系统选择的任何主题的自由形式的对话。这些系统不仅具有完全由数据驱动的方法,还具有更多经过工程设计和模块化的方法。例如,2017年比赛的获胜系统(Sounding Board11)包含一个会议讨论部分以及个人“小技巧”,使该系统能够处理不同的任务(例如,质量检查)和主题(例如,新闻,体育)。由于Alexa奖中系统的多样性,因此在本次调查中概述这些系统是不切实际的,相反,我们将感兴趣的读者推荐给Alexa奖在线活动(Ram等人,2018)。
Chapter 7
Conclusions and Research Trends
会话式人工智能是一个快速发展的领域。本文调查了最近开发的神经方法。其中一些已经广泛用于商业系统。
•
可以使用最佳决策过程的统一数学框架来概念化用于问答,任务完成,选择和推荐等的对话系统。过去几年中开发的用于AI的神经方法,利用了RL和DL的最新突破,可以显着提高跨各种任务和领域的对话代理的性能。
许多商业对话系统允许用户通过对话轻松访问各种服务和信息。这些系统大多数使用混合方法,这些方法结合了符号方法和神经模型的优势。
质量检查代理有两种类型。 KB-QA代理使用户可以通过会话查询大规模的知识库,而无需编写复杂的类似SQL的查询。配备了神经MRC模型的Text-QA代理比传统的搜索引擎(例如Bing和Google)更受欢迎,因为它们要求用户提供简洁明了的直接答案。
传统的面向任务的系统使用手工制作的对话管理器模块或浅层的机器学习模型来分别优化模块。最近,研究人员开始探索DL和RL,以更全面的方式优化系统,减少领域知识,并在不断变化的环境中自动优化系统,以使它们可以有效地适应不同的任务,领域和用户行为。
聊天机器人对于促进人类与其电子设备之间的顺畅自然互动至关重要。较新的工作侧重于选择之外的场景,例如推荐。大多数最新的聊天机器人在神经机器翻译的框架内使用完全数据驱动的和端到端的会话响应生成。
我们有
代理,面向任务的对话机器人和聊天机器人。
讨论了对话式AI的一些主要挑战,这是Question Answer-
•建立统一的对话建模框架:第1章提供了统一的视图,其中将开放域对话表述为最佳决策过程。 尽管该视图提供了有用的设计原理,但仍有待证明具有用于系统开发的统一建模框架的有效性。 微软XiaoIce最初设计为基于检索引擎的聊天系统,现已使用基于共情计算和RL的统一建模框架逐步整合了许多ML组件和技能,包括QA,任务完成和推荐,旨在最大程度地提高用户参与度。 长期而言,以每次会话的预期会话轮换衡量。 我们计划在以后的出版物中介绍XiaoIce的设计和开发。 McCann等。 (2018)介绍了开发统一模型以处理各种任务的平台工作,这些任务包括QA,对话和聊天。
•建立完整的端到端对话系统:最近的工作将面向任务的对话的好处与更多的端到端功能相结合。在基础部分中讨论的接地模型。 5.3代表了朝着面向目标的对话迈出的一步,因为与用户环境进行交互的能力是大多数面向目标的对话系统的关键要求。本文讨论的基础对话建模仍是初步的,未来的挑战包括在完全数据驱动的管道中启用API调用。
•处理异构数据:会话数据通常是异构的。例如,聊天数据很多,但与面向目标的系统并不直接相关,而面向目标的会话数据集通常很小。未来的研究将需要应对如何利用两者的挑战,例如在类似于Luan等人的多任务设置中。 (2017)。另一个研究方向是赵等人的工作。 (2017年),该研究利用“数据增强”技术在选择题和面向任务的数据之间产生了协同作用。他们产生的系统不仅能够处理闲聊,而且对于面向目标的对话也更加强大。另一个挑战是在对话系统培训中更好地利用非对话数据(例如Wikipedia)(Ghazvininejad等人,2018)。
•将EQ(或同理心)纳入对话:这对于聊天机器人和质量检查机器人都非常有用。例如,XiaoIce集成了一个EQ模块,以便提供更易理解的响应或建议(如(Shum等人,2018年的3.1)。冯等。 (2016)将同情模块嵌入对话代理,以使用多模式识别用户的情感,并生成情感感知响应。
•针对面向任务的对话的可扩展培训:快速更新对话代理以处理不断变化的环境非常重要。例如,Lipton等。 (2018)提出了一种有效的探索方法来应对域扩展设置,其中可以逐步引入新的时隙。 Chen等。 (2016b)提出了针对未见意图的零镜头学习,以便在一个域中训练的对话代理可以检测新域中的未见意图,而无需手动标记数据且无需重新训练。
•常识知识对于任何对话主体都至关重要。这具有挑战性,因为常识知识通常未明确存储在现有知识库中。开发了一些新的数据集以促进对常识推理的研究,例如具有常识推理数据集的阅读理解(ReCoRD)(Zhang等人,2018d),Winograd Schema Challenge(WSC)(Morgenstern and Ortiz,2015)和Choice Of可行替代方案(COPA)(Roemmele等,2011)。
•模型的可解释性:在某些情况下,不仅需要对话代理提供建议或答案,还需要提供解释。 例如,在业务场景中,这是非常重要的,因为在这种情况下,用户无法在没有正当理由的情况下做出业务决策。 沉等。 (2018); 熊等。 (2017); Das等。 (2017b)结合了符号方法的可解释性和神经方法的鲁棒性,并在知识库上开发了一种推理算法,该算法不仅可以提高回答问题的准确性,还可以解释产生答案的原因,即知识库中的路径 导致答案节点。