NeRF总结
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
NeRF 的思想比较简单,就是通过输入视角的图像每个像素的射线对于密度(不透明度)积分进行体素渲染,然后通过该像素渲染的 RGB 值与真值进行对比作为 Loss。
任务介绍:
给定2D图像,源姿态(相机坐标转换为世界坐标的变换矩阵,也就是内外参矩阵,这里提供的是从相机坐标系转换到世界坐标系的矩阵,同时也会提供内参矩阵,供相机坐标系转换到像素坐标系,内参矩阵通常对于一个相机来说是固定的,所以通常储存在intrinsics中,另外还有图像的视角d)在具体训练采用向量形式来表达,这个工作可以用slam来代替,以及目标姿态,渲染(根据得到的(c,σ))生成对应的图片(在测试时给一个训练集没有的相机矩阵)。
工作创新点:
-
提出5D神经辐射场来表达复杂的几何和材料连续场景的方法,并利用MLP网络进行参数优化
-
提出基于经典提速渲染改进的可渲染方法,能够通过可微渲染得到RGB图像,并将此作为优化目标。与原采样不同的是,该部分采用分层采样的加速策略,来讲MLP的容量分配到可见的内容区域(基于概率)。
-
提出位置编码的方法将5D坐标映射到更高维的空间,实验中会对比(拓展三维与拓展五维的区别),由于神经网络更适合检测低频特征,通过这种方法将优化神经辐射场更好地表达高频细节。
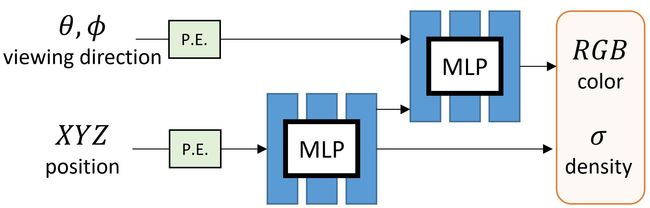
基于神经(Neural)辐射(Radiance)场(Field)的场景表示
NeRF是将场景将表示成一个函数形式,通过训练函数参数来获取结果,然后进行建图。
具体的函数映射表示为:FΘ:(x,d)→(c,σ),通过优化其中的网络参数Θ来学习得到这样的一个5D坐标输入到对应颜色和密度输出的映射。
-
函数输入:参数3D位置信息(x, y, z),2D视角信息(θ,ϕ),也就是内外参矩阵
-
函数输出:三维像素体的颜色(R, G ,B)以及体积密度(不透明度)σ
-
在传入网络时,并不是将原始参数传入到网络中,而是将其转换到统一的世界坐标系下,这就诠释了神经辐射场的概念。
在这里介绍一下坐标变换的知识


其中对于二维视角表示的信息如下

- 由于最终我们要得到的是一个三维结果,也就表明了我们最终可以从任意角度观察生成的物体,因此我们为了让网络学习到多视角如何表示,我们有两个较合理的假设:
- 体积密度(不透明度) σ 只与三维位置 x 有关而与视角方向 d 无关。物体不同位置的密度应该和观察角度无关,这一点比较显然。可以理解为该像素体无论从哪个角度观察,其本身性质是不变的。
- 颜色 c 与三维位置x 和视角方向 d 都相关。由于光照等影响,各个角度观察同一个东西肯定颜色不同。
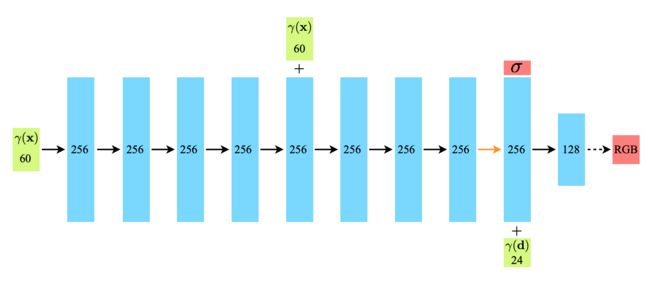
从最上面的网络流程图以及两个假设我们能够看出,通过网络训练出的参数中预测体积密度σ 的网络部分输入仅仅是输入位置x,而预测颜色c 的网络输入是视角和方向 d。在具体实现上:
-
MLP 网络 FΘ 首先用 8 层的全连接层(使用 ReLU 激活函数,每层有 256 个通道),处理 3D 坐标 x,得到σ 和一个 256 维的特征向量。
-
对于通道数的理解:在于我们想要同过卷积核后提取多少个特征
-
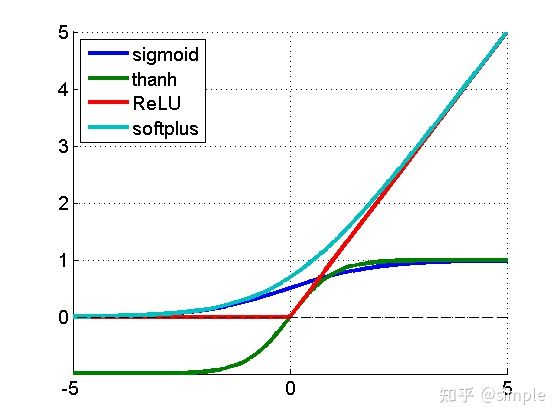
Relu激活函数的理解:神经网络中的每个神经元节点接受上一层神经元的输出值作为本神经元的输入值,并将输入值传递给下一层,输入层神经元节点会将输入属性值直接传递给下一层(隐层或输出层)。在多层神经网络中,上层节点的输出和下层节点的输入之间具有一个函数关系,这个函数称为激活函数。至于为何引入激活函数,如果没有激活函数,那么曾与曾都是线性连接,没有隐藏层效果,这就是最基础的感知,如果引入ReLU,那么网络不再单单是线性组合,在负半轴区域,输出为0,增加了网络的稀疏性。
-
将该 256 维的特征向量与视角方向 \mathbf{d}d 与视角方向一起拼接起来,喂给另一个全连接层(使用 ReLU 激活函数,每层有 128 个通道),输出方向相关的 RGB 颜色。
-
-
实验中对比了如果没有视角参与,那么将无法得到一些信息,如下图,缺少高光效果。
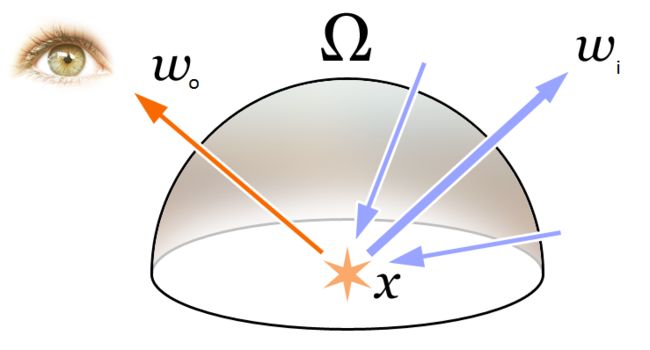
基于辐射场的体素渲染
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7cGjrrAM-1669260362401)(学习/图片/image-20221123103108072.png)]
上面中最重要的就是:可见光的颜色 RGB 就是不同频率的光辐射作用于相机的结果。因此在 NeRF 中认为辐射场就是对于颜色的近似建模。
于是引出NeRF中的体素渲染方法,下面是体素渲染的方程:
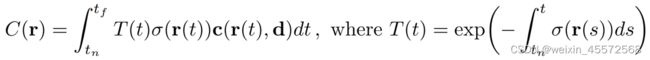
其中r(t):r(t)=o+td
从视角 o 发出的方向为 t 时刻到达点为r(t),也就是说表达的是位置信息
T(t):从tn(近点)到t的累计透明度,也就是没有截至的概率
具体公式推理看下图:由T(t+dt)=T(t)*(1-dtσ(t))
体素密度σ(x):可以将其理解为非牛顿流体的密度,遇强则强
这里面的c(r(t),d)color,不知道是不是要学习的参数,
可微即可学习

由于计算机时间断点计算,所以我们不能够对射线上的点进行连续积分,因此我们采用离散点的方式,并且引入同质媒介,以及透射率时乘法(俩段之间相互独立)

这个方程也就是基于下面要讲的基于分类采样的方程
基于分段采样近似的体素渲染方法:
由于在计算机中不能连续积分,于是我们采用连续积分,通过采用分层采样的方式对[tn,tf]划分成均匀分布的小区间,对每个区间均匀采样,于是就有了上面的方程,同时我们还能够降采样

Optimizing a Neural Radiance Field (优化一个神经辐射场)
在之前的已经讲述了已经达到了重建的任务吗,总体来说就是通过输入位姿以及2维图像(用于计算损失),得到3D的体素和不同方向的RGB
但是仍然存在训练细节不够精细,训练速度慢等原因,为了进一步提升重建的精度和速度,引入了如下两个策略:
- 位置编码(Positional Encoding):使得MLP学习到的函数nerf能更好的表示高频信息,从而丰富细节信息
- 金字塔采样方案(Hierarchical Sampling Procedure):通过这一策略,能使训练过程更高效地采样高频信息
位置编码
最早在 NLP 中采用,可以理解为给不同位置的坐标加一个不同的值作为先验。NeRF 及其后续的方法发现 MLP 的输入中加入位置编码能提高性能,更容易拟合高频域的函数。
例子:两个像素点,太相似了,无法辨别,我把他分成了R G B三个通道,好区分,另外现在MIP NERF提出了综合位置编码,来解决远处模糊的问题
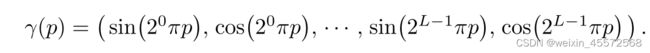
对于位置信息x(归一化到 [-1, 1]),L取10,对于方向信息d,L取4
那就是先编码在转换到向量吗?
分层采样策略(PDF)
分层采样方案来自于经典渲染算法的加速工作,在前述的体素渲染 (Volume Rendering) 方法中,对于射线上的点如何采样会影响最终的效率,如果采样点过多计算效率太低,采样点过少又不能很好地近似。那么一个很自然的想法就是希望对于颜色贡献大的点附近采样密集,贡献小的点附近采样稀疏,这样就可以解决问题。基于这一想法,NeRF 很自然地提出由粗到细的分层采样方案(Coarse to Fine)。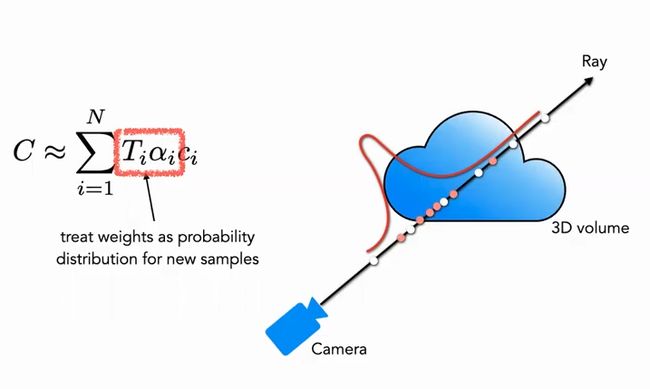
实验步骤:
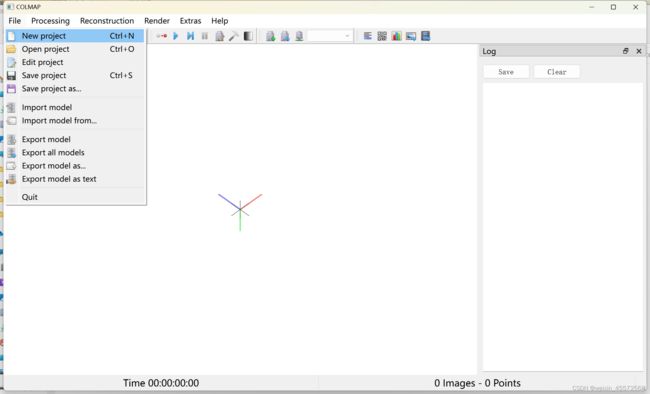
- 收集数据集:导入COLMAP,设置文件保存路径
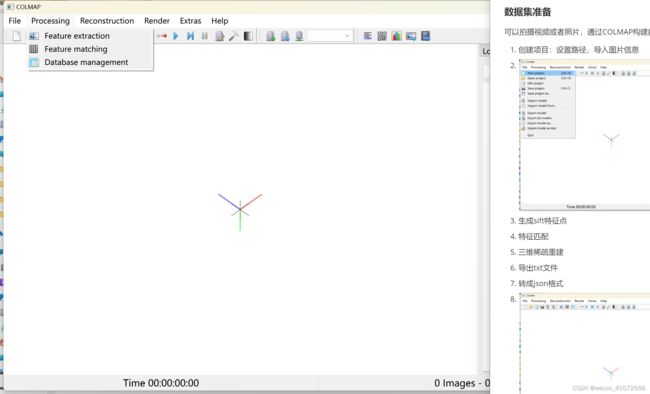
- 提取特征点,特征匹配,重构系数地图
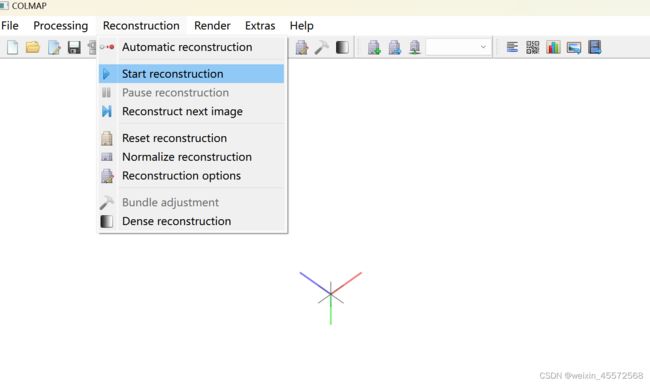
- 导出相机位姿信息

- 转成nerf所需要的格式,开始训练