论文笔记 | Attention-based LSTM for Aspect-level Sentiment Classification
作者:刘锁阵
单位:燕山大学
论文地址:https://www.aclweb.org/anthology/D16-1058.pdf
发布时间:2016
前言
最近在初步学习如何将注意力机制应用到文本分类领域,所以读了几篇相关的论文,在此记录一下。
文章目录
- 前言
- 背景介绍
- 模型设计
-
- 1. LSTM with Aspect Embedding(AE-LSTM)
- 2. Attention-based LSTM (AT-LSTM)
- 3. Attention-based LSTM with Aspect Embedding (ATAE-LSTM)
- 实验结果
- 总结
背景介绍
Aspect-level的情感分类在情感分析中是一个比较细粒度的工作。在本篇论文中,作者说明一个句子的情感分类结果不仅由内容决定,而且还和所关注的方面有关。
作者举了一个例子:“The appetizers are ok, but the service is slow.”,对于菜的味道而言,顾客的情感是正面的、积极的;而对于服务而言,顾客的情感是负面的。
因此,为了解决这个问题,作者提出了构建基于注意力机制的模型来解决aspect-level的情感分类任务。
论文的主要贡献:
- 提出了基于注意力机制的LSTM模型。当关注不同的aspect时,模型可以关注句子中的不同部分。
- 设计了两种方式来在计算注意力时,将aspect信息考虑在内:
- 对词进行向量表示时,将aspect embeddings附加到输入向量后面。
- 计算注意力权重时,将aspect embeddings和句子的隐藏层输出做concat,一起计算注意力权重。 - 实验结果显示,该方法与几个基线模型相比,效果有着不错的提高。并且更多的例子也表明注意力机制对于aspect-level的情感分类任务效果是非常不错的。
模型设计
1. LSTM with Aspect Embedding(AE-LSTM)
为每个aspect,学习一个embedding向量。
向量 v a i ∈ R d a v_{ai} \in \mathbb{R}^{d_a} vai∈Rda 表示aspect i i i的embedding向量。 d a d_a da是aspect embedding的维度。 A ∈ R d a × ∣ A ∣ A\in \mathbb{R}^{d_a\times |A|} A∈Rda×∣A∣由所有aspect embedding组成。
2. Attention-based LSTM (AT-LSTM)

H ∈ R d × N H\in \mathbb{R}^{d\times N} H∈Rd×N是由隐藏向量 [ h 1 , … , h N ] [h_1, \dots, h_N] [h1,…,hN]组成的矩阵。 d d d是隐藏层的大小, N N N是给定句子的长度。
v a v_a va表示aspect的embedding向量。注意力机制将会产生一个注意力权重向量 α \alpha α和一个带权重的隐藏层表示 r r r:
M = t a n h ( [ W h H W v v a ⊗ e N ] ) (7) M = tanh(\begin{bmatrix} W_h H \\ W_v v_a \otimes e_N \end{bmatrix}) \tag{7} M=tanh([WhHWvva⊗eN])(7)
α = s o f t m a x ( w T M ) (8) \alpha = softmax(w^T M) \tag{8} α=softmax(wTM)(8)
r = H α T (9) r = H \alpha^T \tag{9} r=HαT(9)
M ∈ R ( d + d a ) × N M \in \mathbb{R}^{(d + d_a)\times N} M∈R(d+da)×N, α ∈ R N \alpha \in \mathbb{R}^N α∈RN, r ∈ R d r \in \mathbb{R}^d r∈Rd.
W h ∈ R d × d W_h \in \mathbb{R}^{d\times d} Wh∈Rd×d, W v ∈ R d a × d a W_v \in \mathbb{R}^{d_a\times d_a} Wv∈Rda×da w ∈ R d + d a w\in \mathbb{R}^{d+d_a} w∈Rd+da是要学习的参数。
α \alpha α 是一个由注意力权重组成的向量, r r r是一个句子带权重的表示(with aspect)。
最终的句子表示:
h ∗ = t a n h ( W p r + W x h N ) (10) h^* = tanh(W_p r + W_x h_N) \tag{10} h∗=tanh(Wpr+WxhN)(10)
h ∗ h^* h∗作为给定aspect时,一个数据句子的特征表示。之后可以添加一个全连接层分类,并使用Softmax做分类预测。
3. Attention-based LSTM with Aspect Embedding (ATAE-LSTM)

在句子的输入表示中添加了aspect embedding。
实验结果
所有的词向量被使用GloVec初始化。其它参数使用uniform distribution初始化。词向量、aspect embeddings、隐藏层大小都设置为300。注意力权重的长度和句子长度相同。batch_size为25,0.9的 momentum、0.001的L2正则化权重,初始学习率0.01。
数据集:
SemEval 2014 Task4 (Pontiki et al., 2014). 数据集包含客户评论。每个评论包含一个关注列表,每个关注方向都由对应的情感分类结果。
aspect-level分类:
分为5类food, price, service, ambience, anecdotes/miscellaneous:

准确度:
注意力可视化:

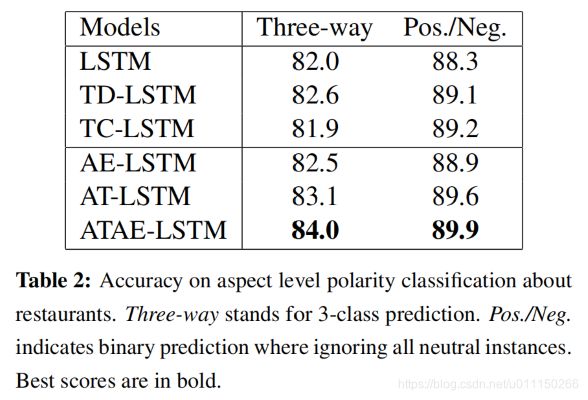
与基线方法比较:

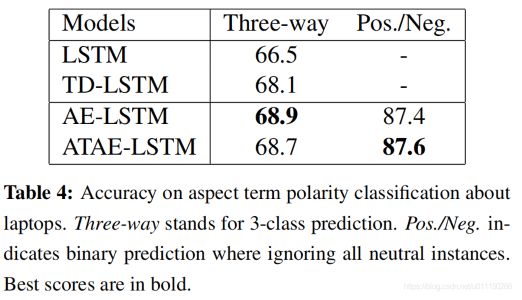
总结
在本篇文章中,作者提出了基于注意力机制的LSTM用于aspect-level的情感分类。创新点在于提出了设计aspect embeddings,并且让aspects参与到计算注意力权重的过程中。结果显示,AE-LSTM和ATAE-LSTM相比于基线模型有着更好的效果。