【翻译】Complex Ratio Masking for Monaural Speech Separation
Complex Ratio Masking for Monaural Speech Separation
用于单声道语音分离的复数比掩蔽
机翻
Donald S. Williamson, Student Member, IEEE, Y uxuan Wang, and DeLiang Wang, Fellow, IEEE
摘要
语音分离系统通常对有噪声语音进行短时傅里叶变换(STFT),并仅增强幅度谱而保持相位谱不变。这样做是因为人们相信相位谱对于语音增强不重要。然而,最近的研究表明相位对感知质量很重要,导致一些研究人员考虑幅度和相位谱增强。我们提出了一种监督单声道语音分离方法,通过在复域中操作,同时增强幅度谱和相位谱。我们的方法使用深度神经网络来估计在复域中定义的理想比率掩码的实部和虚部分量。我们报告了所提出方法的分离结果,并将其与相关系统进行了比较。当用几个客观指标进行评估时,所提出的方法优于其他方法,包括语音质量的感知评估(PESQ)和听力测试,其中受试者以至少69%的比率偏好所提出的方式。
关键词 复数理想比率掩模,深度神经网络,语音质量,语音分离。
这里有许多语音应用,其中感兴趣的信号被加性背景噪声破坏。去除这些混合信号中的噪声被认为是语音处理领域最具挑战性的研究课题之一。在只有一个麦克风捕捉信号的单声道情况下,这个问题变得更加具有挑战性。虽然单声道语音分离已经有了很多改进,但仍有强烈的需求来产生高质量的分离语音。
典型的语音分离系统通过增强幅度响应并保持相位响应不变而在时频(T-F)域中工作,部分原因是[1]、[2]中的发现。在[1]中,进行了一系列实验,以确定相位和幅度分量在语音质量方面的相对重要性。Wang和Lim根据特定信噪比(SNR)下的噪声语音计算傅里叶变换幅度响应,然后通过将其与在另一SNR下生成的傅里叶转换相位响应相结合来重构测试信号。然后,收听者将每个重构信号与已知SNR的未经处理的噪声语音进行比较,并指示哪个信号听起来最好。相位和幅度谱的相对重要性用等效SNR来量化,等效SNR是以50%的速率分别选择重构语音和噪声语音的SNR。结果表明,当使用比幅度响应高得多的信噪比重建相位响应时,等效信噪比没有得到显著改善。这些结果与先前研究的结果一致[3]。Ephraim和Malah[2]使用最小均方误差(MMSE)将语音与噪声分离,以估计干净频谱,该频谱包括幅度响应的MMSE估计和相位响应的复指数。他们表明,噪声相位的复数指数是清洁相位复数指数的MMSE估计。然后,干净频谱的MMSE估计是干净幅度谱的MMSE估算与噪声相位的复指数的乘积,这意味着相位对于信号重建是不变的。
然而,Paliwal等人[4]最近的一项研究表明,当只增强相位谱而保持噪声幅度谱不变时,感知质量的改善是可能的。Paliwal等人将噪声幅值响应与oracle(即清洁)相位、非oracle(即噪声)相位和增强相位相结合,其中不匹配的短时傅里叶变换(STFT)分析窗口用于提取幅值和相位谱。客观的和主观的(如听力研究)语音质量测量被用来评估改善。听力评估涉及一对信号之间的偏好选择。结果表明,当将oracle相位谱应用于噪声量级谱时,语音质量得到了显著的改善,而使用非oracle相位时,语音质量得到了适度的改善。当清洁震级谱的MMSE估计结合甲骨文和非甲骨文相位响应时,结果是相似的。此外,当清洁幅度谱的MMSE估计与增强相位响应相结合时,可获得较高的偏好分数。
Paliwal等人的工作导致一些研究人员开发用于语音分离的相位增强算法[5]–[7]。在给定相应的估计STFT幅度响应的情况下,在[5]中提出的系统使用多个输入频谱图反演(MISI)来迭代地估计混合物中的时域源信号。频谱图反演通过迭代恢复丢失的相位信息来估计信号,同时约束幅度响应。MISI使用混合和估计源之和之间的平均总误差来更新每次迭代的源估计。在[6]中,Mowlaee等人执行MMSE相位估计,其中通过最小化平方误差来估计混合物中两个源的相位。这种最小化导致几个相位候选,但是最终选择具有最低群延迟的相位对。然后用它们的幅度响应和估计的相位重建源。科劳兹克和格克曼[7]在给定基频估计的情况下,通过重构频率和时间上的谐波分量之间的相位来增强有声语音帧的相位。无声帧保持不变。[5]-[7]中的方法都显示了当阶段增强时客观的质量改进。但是,它们没有解决幅度响应问题。
促使我们研究相位估计的另一个因素是,监督掩模估计最近被证明可以在非常嘈杂的条件下提高人类语音的可懂度[8],[9]。对于负信噪比,噪声语音的相位比目标语音的相位更能反映背景噪声的相位。结果,在增强语音的重建中使用噪声语音的相位变得比在更高SNR条件下更成问题[10]。因此,在某种程度上,幅度估计在极低信噪比下的成功提高了在这些信噪比水平下进行相位估计的需要。
促使我们研究相位估计的另一个因素是,监督掩模估计最近被证明可以在非常嘈杂的条件下提高人类语音的可懂度[8],[9]。对于负信噪比,噪声语音的相位比目标语音的相位更能反映背景噪声的相位。结果,在增强语音的重建中使用噪声语音的相位变得比在更高SNR条件下更成问题[10]。因此,在某种程度上,幅度估计在极低信噪比下的成功提高了在这些信噪比水平下进行相位估计的需要。
本文定义了复理想比掩模(cIRM)并训练了一个DNN来联合估计实部和虚部。通过在复数域中操作,cIRM能够同时增强噪声语音的幅度和相位响应。来自听力研究的客观结果和偏好分数表明,cIRM估计比相关方法产生更高质量的语音。
本文定义了复理想比掩模(cIRM)并训练了一个DNN来联合估计实部和虚部。通过在复数域中操作,cIRM能够同时增强噪声语音的幅度和相位响应。来自听力研究的客观结果和偏好分数表明,cIRM估计比相关方法产生更高质量的语音。、

图一。(彩色在线)干净语音信号的示例幅度(左上)和相位(右上)频谱图,以及实部(左下)和虚部(右下)频谱图。实部和虚部频谱图显示了时间和频谱结构,并且类似于幅度频谱图。在相位谱图中显示出很少的结构。
二 短时傅立叶变换 内 结构
当增强噪声语音的STFT时,通常使用极坐标(即,幅度和相位),如(1)中所定义的

其中 ∣ S t , f ∣ |S_{t,f }| ∣St,f∣表示STFT在时间t和频率f 下的幅度响应, θ S t , f θ_{S_{t,f }} θSt,f表示相位响应,STFT表示中的每个T-F单位都是具有实部和虚部的复数。幅度和相位响应直接从实部和虚部计算得出,分别如下所示。

图1示出了干净语音信号的幅度(左上)和相位(右上)响应的例子。幅度响应显示出清晰的时间和频谱结构,而相位响应看起来相当随机。这通常归因于相位值在[-π,π]范围内的回绕。当使用学习算法将特征映射到训练目标时,映射函数中有结构是很重要的。图1示出了使用DNNs来直接预测干净的相位响应不太可能有效,尽管DNNs成功地从噪声幅度谱中学习干净的幅度谱。事实上,我们已经广泛地尝试训练DNNs来从噪声语音中估计干净相位,但是没有成功。
作为使用极坐标的替代,可以使用复指数的展开在笛卡尔坐标中表达(1)中的STFT的定义。对 STFT 实部虚部定义如下

图1的下部示出了干净语音的实(左下)和虚(右下)频谱的对数压缩绝对值。实部和虚部都显示出清晰的结构,类似于幅度谱,因此易于监督学习。这些光谱图看起来几乎一样,因为三角余函数相同:正弦函数与余弦函数相同,相移为π/2弧度。等式(2)和(3)表明,幅度和相位响应可以直接从STFT的实部和虚部计算,因此增强实部和虚部会导致幅度和相位频谱增强。
基于这种结构,一个简单的想法是使用dnn来预测STFT的复杂成分。然而,我们最近的研究表明,直接预测幅度谱可能不如预测理想的T-F掩模[11]。因此,我们建议预测复理想比掩模的实分量和虚分量,这将在下一节中描述。
复数理想比值掩蔽 及其估计
A 数学推导
传统的理想比率掩码是在幅度域中定义的,在本节中我们定义复域中的理想比率掩码。我们的目标是推导出一个复比例掩码,当应用于噪声语音的STFT时,产生干净语音的STFT。也就是说,给定噪声语音的复谱Yt,f,我们得到干净语音的复谱St,f,如下:

其中’ * '表示复数乘法,Mt,f是cIRM。注意Yt,f, St,f和Mt,f是复数,可以写成矩形形式:

下标r和I分别表示实分量和虚分量。为方便起见,时间和频率的下标没有显示出来,但给出了每个T-F单位的定义。根据这些定义,式(7)可展开为:

由此我们可以得出结论,洁净言语的实成分和虚成分分别为
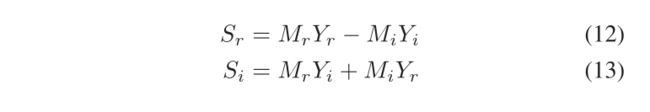
用方程式。(12)和(13),定义M的实分量和虚分量为

给出了复理想比值掩模的定义

请注意,复理想比掩码的这个定义与维纳滤波器密切相关,维纳滤波器是干净和噪声语音的交叉功率谱与噪声语音[14]的功率谱的复比。
值得一提的是,Sr, Si, Yr和Yi∈R,意味着Mr和Mi∈R,因此,复掩码可能具有较大的实分量和虚分量,其值在(−∞,∞)的范围内。回想一下,IRM的取值范围为[0,1],这有利于使用dnn进行监督学习。较大的取值范围可能使cIRM估计复杂化。因此,我们用下面的双曲正切压缩cIRM

其中x为r或i,表示实分量和虚分量。这种压缩产生掩码值在[−K, K]以内,C控制其陡度。对K和C的几个值进行了评估,K = 10和C = 0.1在经验上表现最好,并用于训练DNN。在测试期间,我们对DNN输出Ox使用以下反函数来恢复未压缩掩码的估计值:

图2显示了cIRM的一个例子,以及干净的、噪声的、cIRM分离的和irm分离的语音的频谱图。每个信号的复STFT的实部在图的顶部,虚部在图的底部。噪声语音是由清洁语音信号与工厂噪声在0 dB信噪比下结合产生的。对于本例,生成的cIRM为K = 1 in(17)。去噪后的语音信号通过取cIRM和噪声语音的乘积来计算。注意,与干净的语音信号相比,去噪后的信号得到了有效的重构。另一方面,irm分离语音去除了大部分噪声,但它不能像cirm分离语音那样重建干净语音信号的真实和虚构成分。

图2所示。干净语音、噪声语音、复理想比掩码、复理想比掩码分离语音的实(上)和虚(下)STFT分量谱图。
B.基于DNN的cIRM估计
用于估计cIRM的DNN如图3所示。正如之前的研究[11],[15]所做的,dnn有三个隐藏层,每个隐藏层都有相同数量的单位。输入层被赋予以下一组从64通道伽matone滤波器组中提取的互补特征:振幅调制谱图(AMS)、相对谱变换和感知线性预测(RASTA-PLP)、mel频率倒谱系数(MFCC)和耳蜗谱响应及其增量。使用的特性与[11]中相同。这些特征的组合已被证明对语音分离[16]是有效的。我们还评估了其他特征,包括噪声幅值、噪声幅值和相位,以及噪声STFT的实分量和虚分量,但它们不如互补集。有用的信息是跨时间帧传输的,因此使用滑动上下文窗口将相邻的帧拼接成每个时间帧[11],[17]的单个特征向量。这用于DNN的输入和输出。换句话说,DNN将互补特征的窗口帧映射到每个时间帧的cIRM的窗口帧。**注意输出层被分成两个子层,一个用于cIRM的实分量,另一个用于cIRM的虚分量。这种输出层的y形网络结构通常用于联合估计相关目标[18],**在这种情况下,它有助于确保从相同的输入特征联合估计实分量和虚分量。

图3。利用DNN结构估计复杂理想比掩码。
针对这种网络结构,反向传播算法使用复杂数据的均方误差(MSE)函数来更新DNN的权值。这个代价函数是来自真实数据的MSE和来自虚数据的MSE的总和,如下图所示:

其中N表示输入的时间帧数,Or(t, f)和Oi(t, f)表示DNN以t - f为单位的实输出和虚输出,Mr(t, f)和Mi(t, f)分别对应cIRM的实分量和虚分量。
具体来说,每个DNN隐藏层有1024个单位[11]。整流线性(ReLU)[19]激活函数用于隐藏单元,而线性单元用于输出层,因为cIRM不在0和1之间有界。采用带动量项的自适应梯度下降[20]进行优化。动量速率在前5个周期被设置为0.5,之后在剩下的75个周期(总共80个周期),速率改变为0.9。
四、结果
A.数据集和系统设置
该系统在IEEE数据库[21]上进行了评估,该数据库由一个男性说话者的720个话语组成。测试集由60个被下采样到16千赫的纯净话语组成。每个测试话语在信噪比为−6、−3、0、3和6 dB的情况下混合语音形噪声(SSN)、自助餐厅(Cafe)、语音杂音(babble)和工厂地板噪声(factory),产生1200个(60个信号×4噪声×5 SNRs)混合物。SSN是一个平稳噪声,而其他噪声是非平稳的,每个信号大约4分钟长。从每个噪音最后2分钟的随机剪辑与每个测试话语混合,创建测试混合物。使用来自IEEE语料库的500个与测试语料不同的词训练估计cIRM的DNN。从每个噪音的前2分钟截取10个随机片段与每个训练发音混合,生成训练集。DNN的混合物在−3、0和3 dB信噪比下生成,在训练集中产生60000(500信号×4噪声×10随机切割×3 SNRs)混合物。注意,测试混合物的- 6和6db信噪比在训练过程中DNN是看不到的。将噪声分成两半可以确保在训练过程中不可见测试噪声片段。此外,开发集确定DNN和STFT的参数值。该开发集是由50个不同的清晰的IEEE语音生成的,这些语音混合了上述4个噪声的前2分钟的随机剪切,信噪比为−3,0,and 3d B。
此外,我们使用TIMIT语料库[22],它由许多男性和女性说话者的话语组成。通过将500个话语(来自50个扬声器的10个话语)与上述信噪比为−3、0和3db的噪声混合来训练DNN。训练话语来自35名男性和15名女性。60个不同的话语(来自6个新的说话者的10个话语)被用于测试。测试话语来自4名男性和2名女性。
如第III-B节所述,提供了一个由四个特征组成的互补集作为DNN的输入。一旦从有噪声的语音中计算出互补特征,这些特征被归一化,使其在每个频率通道上的平均值和单位方差为零。[23]中已经表明,对输入特征应用自回归移动平均(ARMA)滤波可以提高自动语音识别的性能,因为ARMA滤波跨时间平滑每个特征维度,以减少来自背景噪声的干扰。此外,ARMA滤波器提高了语音分离结果[24]。因此,我们对均值和方差归一化后的互补特征集进行ARMA滤波。arma滤波后的当前时间帧特征向量是通过当前帧前两个滤波后的特征向量与当前帧和当前帧后两个未滤波的特征向量的平均值来计算的。一个跨越五帧(前后两帧)的上下文窗口将经过arma筛选的特征拼接到一个输入特征向量中。
训练DNN来估计每种训练混合的cIRM,其中cIRM由(16)和(17)中所述的噪声语音和干净语音的stft生成。通过将时域信号分割成40毫秒(640个样本)重叠帧,使用相邻帧之间50%的重叠来生成stft。使用Hann窗口,以及640长度的FFT。三帧上下文窗口为输出层增加了cIRM的每一帧,这意味着DNN为每个输入特征向量估计了三帧。
方法比较
我们比较了cIRM估计与IRM估计[11]、相敏屏蔽(PSM)[12]、时域信号重构(TDR)[13]和复域非负矩阵分解(CMF)[25] -[27]。与IRM估计的比较有助于确定在复杂领域的处理是否比在幅度领域的处理提供改进,而其他比较确定与这些最近的监督方法(包含一定程度的相位)相比,复杂比率掩蔽的性能如何。
IRM是通过取每个T-F单元[11]的语音能量与语音和噪声能量之和之比的平方根生成的。使用一个单独的DNN来估计IRM。输入特征和DNN参数与那些用于cIRM估计的参数匹配,唯一的例外是输出层对应于幅度,而不是实和虚分量。一旦IRM被估计出来,它就被应用到噪声量级响应中,它与噪声相位一起产生语音估计。PSM与IRM相似,不同之处是清洁语音和噪声语音量级谱之间的比值乘以清洁语音和噪声语音之间相差的余弦。理论上,这相当于只使用cIRM的实分量。TDR通过添加一个子网来执行IFFT,直接重构干净的时域信号。这个IFFT子网的输入由应用于混合幅度的T-F掩码子网(类似于比率掩码)的最后一个隐藏层的活动和噪声相位组成。PSM和TDR估计的输入特征和DNN结构与IRM估计相匹配
CMF是非负矩阵分解(NMF)的扩展,过程中包含了相位响应。更具体地说,NMF将信号分解为基和激活矩阵,其中基矩阵提供光谱结构,激活矩阵将基元素线性组合以近似给定信号。要求两个矩阵都非负。使用CMF,基和权值仍然是非负的,但是创建了一个相位矩阵,它乘以每个T-F单元,允许每个光谱基确定最适合混合物[26]的相位。我们使用[27]中实现的有监督CMF执行语音分离,其中两个源(语音和噪声)的矩阵分别从dnn使用的相同训练数据进行训练。语音和噪声基分别用100个基向量建模,并用一个跨越5帧的上下文窗口对其进行增强。
为了进行最后的比较,我们将不同的幅值谱与相谱结合起来,以评估增强幅值或相响应的方法。在相位估计方面,我们使用了一种最新的系统,该系统利用估计的基频重构浊语音的谱相位,增强了噪声语音[7]的相位响应。分析了相位谱,增强了沿时间相位和沿频率轴的间隔谐波。此外,我们使用了Griffin和Lim[28]的标准相位增强方法,该方法通过固定幅值响应并只允许相位响应更新,重复计算STFT和逆STFT。由于这些方法只增强相位响应,我们将它们与由估计IRM(表示为RM-K&G和RM-G&L)和噪声语音(表示为NSK&G和NS-G&L)分隔的语音的量级响应结合起来,如[7]所做的。这些幅度谱还与被估计的cIRM分离的语音相位响应相结合,分别记为RM-cRM和ns - crm
c .客观结果
利用语音质量感知评价(PESQ)[29]、短时客观可理解性(STOI)评分[30]和频率加权段信噪比(SNRfw)[31]三个客观指标对每种方法分离的语音信号进行评价。PESQ的计算方法是将分离的语音与相应的清洁语音进行比较,得到的分数在[−0.5,4.5]范围内,分数越高表示质量越好。STOI通过计算干净语音和分离语音之间的短时间时间包膜的相关性来衡量客观的可理解性,得到的分数在[0,1]的范围内,分数越高表示可理解性越好。SNRfw计算在每个时间帧和关键波段聚合的加权信噪比。研究表明,PESQ和SNRfw与人类语音质量评分[31]高度相关,而STOI与人类语音清晰度评分高度相关。
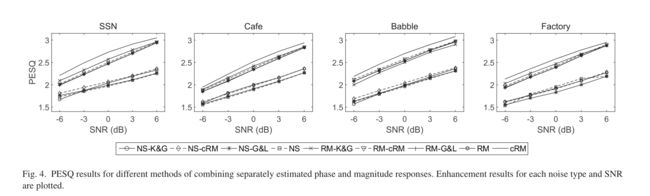
表I、II和III给出了使用IEEE话语的不同方法的客观结果,分别显示了混合信噪比为−3、0和3 dB时的结果。粗体表示在噪声类型中性能最好的系统。从表I开始,在PESQ方面,每种方法对每种噪声都提供了对噪声语音混合物的质量改进。CMF对每种噪声的性能都是一致的,但它对噪声语音的PESQ改进最小。估计的IRM(即RM)、估计的cIRM(即cRM)、PSM和TDR都比噪声语音和CMF产生了相当大的改进,其中cRM对SSN、Cafe和Factory噪声表现最好。从幅度域的比率掩蔽到复域的比率掩蔽提高了每个噪声的PESQ分数。在STOI方面,每种算法都对噪声语音产生了改进,其中CMF提供了最小的改进。估计的IRM、cIRM和PSM的STOI分数大致相同。在SNRfw方面,估计的cIRM对除Babble噪声(PSM产生最高评分)外的所有噪声都表现最好。
在信噪比为0 dB时的性能趋势与在−3 dB时的性能趋势相似,如表II所示,每种方法都提高了对未经处理的噪声语音的客观评分。与−3 dB时相比,0 dB时的CMF对PESQ和STOI的改善量大致相同。CMF的STOI得分也是最低的,这与基于nmf的方法往往不能提高语音可解性的普遍理解是一致的。CMF比噪声语音平均提高了1.5 dB的SNRfw。预测cIRM而不是IRM可以显著提高客观质量。除Babble外,cRM的PESQ评分均优于PSM和TDR。在所有噪声类型中,RM、cRM和PSM的客观可理解性得分大致相同。就SNRfw性能而言,PSM在每种噪声类型上的性能都略好。
表III显示了在3 dB时的分离性能,相对于−3和0 dB时的分离性能更容易。一般来说,估计的cIRM在PESQ方面表现最好,而RM、cRM和PSM之间的STOI得分大致相等。PSM产生的SNRfw评分最高。CMF对噪声语音的改进是一致的,但它的性能比其他方法差。上述基于屏蔽方法的结果是在不可见噪声(即−3、0和3 dB)下对dnn进行训练和测试时产生的。为了确定是否知道信噪比会影响性能,我们还使用训练期间看不到的信噪比(即−3和6 dB)对这些系统进行了评估。表IV显示了−6和6 dB时的平均性能。−6 dB和6 dB的PESQ结果对于SSN、Cafe和工厂噪声的估计cIRM是最高的,而PSM对于Babble是最高的。对于估计的cIRM、IRM和PSM, STOI结果大致相同。在SNRfw方面,PSM的性能最好。
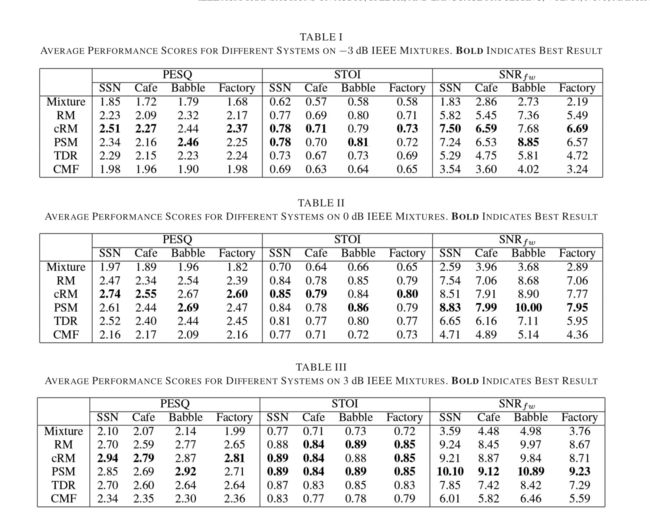
为了进一步分析我们的方法,我们使用TIMIT语料库评估每个系统(CMF除外)的PESQ性能,如第IV -A节所述。表五显示了每种噪声的平均结果,类似于上面的单扬声器情况,cRM在SSN、Cafe和Factory噪声方面优于每种方法,而PSM在Babble噪声方面最好。图4为分别增强的幅值和相位响应相结合重建语音时的PESQ结果。图中显示了每种系统在所有信噪比和噪声类型下的结果。回想一下,量级响应是从有噪声的语音或被估计的IRM分离的语音中计算出来的,而相位响应是从被估计的cIRM或[7]、[28]中的方法分离出来的语音中计算出来的。未处理的噪声语音的结果,估计的cIRM和估计的IRM是从表I到表IV中复制的,并显示在每种情况下。当使用噪声幅值响应时(每个图的下半部分),不同相位估计器之间的客观质量结果在不同噪声类型和信噪比下接近。更具体地说,对于咖啡馆和工厂噪声,NS-K&G和NS-cRM的结果是相同的,而NS-G&L的表现略差。当信噪比大于0 dB时,SSN也会出现这种趋势。当用估计的IRM掩盖震级响应时,每个相位估计器产生相似的PESQ分数,可以得到类似的结果。这些结果还表明,当这些相位估计器应用于未处理和IRM增强的幅度响应时,有时可以获得较小的客观语音质量改善,这可以通过将相位增强信号与未处理的噪声语音和被估计的IRM分离的语音进行比较看到。这一比较表明,分别加强幅度和相位响应不是最佳的。另一方面,从结果中可以明显看出,联合估计cIRM的实分量和虚分量比其他方法在噪声类型和信噪比条件下的PESQ性能有所提高。
结果
除了客观结果之外,我们还进行了一项听力研究,让人类受试者比较成对的信号。这个任务使用IEEE话语。听力学习的第一部分比较了复合比率掩蔽与比率掩蔽、CMF以及分别增强幅度和相位的方法。听力研究的第二部分将cIRM估计与对相位敏感的PSM和TDR进行比较。在研究过程中,受试者选择他们在质量方面更喜欢的信号,使用偏好评级方法进行质量比较[32],[33]。对于每一对信号,参与者被指示从三个选项中选择一个:信号A是首选,信号B是首选,或者信号的质量大致相同。听者被要求至少播放一次每个信号。首选方法的评分为+1,另一种方法的评分为−1。如果选择了第三个选项,每个方法都得到0分。如果受试者选择了前两个选项中的一个,那么他们会提供一个改善分数,从0到4表示质量更高的信号。改进分数为1、2、3和4,分别表明首选信号的质量比其他信号稍好、较好、较好和非常好(见[33])。此外,如果其中一个信号是首选的,参与者会指出他们选择背后的原因,他们可以指出语音质量、噪声抑制或两者都帮助他们做出了决定。
对于听力研究的第一部分,通过IV-B生成的信号和方法如第三部分所述,包括估计的cIRM、估计的IRM、CMF、NSK&G和未处理的噪声语音。在0和3 dB信噪比下,用SSN、Factory和Babble噪声组合处理的信号进行评估。其他信噪比和噪声组合并不用于确保处理后的信号对听者完全可理解,因为我们的目标是感知质量评估,而不是可理解性。每个主题测试包括三个阶段:实践、培训和正式评估阶段,其中,实践阶段使受试者熟悉信号的类型,培训阶段使受试者熟悉评估过程。每个相位的信号都是不同的。在正式评估阶段,参与者进行120次比较,其中对以下每组进行30次比较:(1)嘈杂语音与估计的cIRM, (2) NS-K&G与估计的cIRM,(3)估计的IRM与估计的cIRM, (4) CMF与估计的cIRM。30次比较相当于每组信噪比(0和3 dB)和噪声(SSN, Factory和Babble)的组合的5组。研究中使用的话语是从测试信号中随机选择的,每对话语的呈现顺序是随机生成的,而听者事先并不知道产生信号的算法。这些信号通过Sennheiser HD 265耳机使用个人电脑进行单听演示,每个信号都被标准化为具有相同的声级。受试者坐在一个隔音的房间里。10名受试者(6名男性和4名女性),年龄在23到38岁之间,自称听力正常,参加了这项研究。所有的研究对象都以英语为母语,他们都是从俄亥俄州立大学招募来的。每位参与者都因参与而获得金钱奖励。
在估计的cIRM和IRM之间进行重要的比较,因为这表明复域估计是否有用。在这一比较中,参与者以89%的比例更喜欢估计的cIRM而不是IRM,其中对估计的IRM和相等分别选择了1.67%和9.33%的偏好率。估计的cIRM和CMF之间的比较产生了类似的结果,估计的cIRM、CMF和相等的选择率分别为86%、9%和5%。每次比较的改进分数如图5(b)所示。该图显示,平均而言,用户表示估计的cIRM比比较方法大约好1.75分,这意味着根据我们的改进评分表,估计的cIRM被认为更好。不同比较的推理结果如图5( c)所示。参与者表示,当将估计的cIRM与NS、NS- k&g和CMF进行比较时,噪声抑制是他们选择的主要原因。当将估计的cIRM与估计的IRM进行比较时,用户表示听力学习第一部分的听力学习结果如图5(a) - ( c)所示。偏好得分如图5(a)所示,图5(a)显示了每次两两比较的平均偏好结果。当将估计的cIRM与噪声语音(即NS)进行比较时,用户偏好估计的cIRM的比例为87%,而偏好噪声语音的比例为7.67%。两个信号的质量在5.33%的时间是相等的。与NS-K&G的比较结果相似,cRM、NS-K&G和平等偏好率分别为91%、4.33%和4.67%。最语音质量是其选择的原因,其率为81%,降噪率为49%。
听力研究的第二部分招募了不同的受试者。共有5名母语为英语的受试者(3名女性和2名男性),年龄在32岁到69岁之间,每个人自述听力正常,参与了研究。一名受试者也参与了研究的第一部分。cRM、TDR和PSM信号经SSN、Factory、Babble和Cafe噪声组合处理后,在0 dB信噪比下进行评估。每个参与者进行40次比较,其中20次是cRM和TDR信号之间的比较,20次是cRM和PSM信号之间的比较。对于这两种情况下的20个比较中的每一个,分别使用4种噪声类型中的5个信号。这些话语是从测试信号中随机选择的,听者对用来产生信号的算法并不知情。当比较cIRM估计与PSM和TDR估计时,受试者只提供信号偏好。
听力研究第二部分的结果如图5(d)所示。平均而言,cRM信号优先于PSM信号,优先率为69%,而PSM信号优先率为11%。听众感觉cRM和PSM信号的质量是相同的,比例为20%。受试者对cRM信号和TDR信号的偏好率分别为85%和4%,对TDR信号的偏好率为11%。
五、讨论与结论
一个有趣的问题是,当在复杂领域中操作时,合适的训练目标应该是什么。虽然我们已经展示了以cIRM为训练目标的结果,但我们还对另外两个训练目标进行了额外的实验,即对干净语音STFT(简称为STFT)的实分量和虚分量的直接估计和对复杂理想比例掩码的另一种定义。对于cIRM的另一种定义,称为cir麦芽,将复掩码的实部应用于噪声语音STFT的实部,并同样应用于虚部。掩模和分离方法定义如下:

在每个T-F单元进行分离。III和IV节中定义的数据、特征、目标压缩和DNN结构也被用于这两个目标的DNN,除了STFT,我们发现用双曲切线压缩可以提高PESQ得分,但它严重损害了STOI和SNRfw。STFT训练目标因此是不压缩的。我们还发现,复杂谱的噪声实分量和虚分量作为STFT估计的特征效果更好。在所有信噪比(−6到6 dB,增加3 dB)和噪声类型下,这些目标和估计的cIRM的平均性能结果如表VI所示。结果表明,估计的cIRM和估计的cIRMalt之间的性能差异很小,但直接估计STFT的实部和虚部是无效的。

在本研究中,我们定义了复杂理想比例掩码,并证明了利用深度神经网络可以有效地估计它。客观指标和人体受试者都表明,估计的cIRM优于估计的IRM、PSM、TDR、CMF、未处理的噪声语音和用最近相位增强方法处理的噪声语音。对IRM和PSM的改进主要归功于在复杂域内同时增强了噪声语音的幅度和相位响应。阶段的重要性已经在[4]中得到了证明,我们的结果提供了进一步的支持。结果还表明,作为NMF的扩展,CMF与NMF存在同样的缺陷,即假设一个语音模型可以线性组合来近似有噪声语音中的语音,而一个噪声模型可以缩放来估计噪声部分。从这些结果和之前[34]、[15]的研究可以看出,在低信噪比和非平稳噪声的情况下,这一假设并不成立。在CMF中使用相位信息进行分离不足以克服这一缺点。听力研究表明,估计的cIRM可以保持人类语音的自然性,在噪声语音中存在,同时去除大部分噪声。
一个有趣的现象是,当一个噪声语音信号从分别估计的幅度和相位响应(即RM-K&G, RM-G&L和RM-cRM)增强时,其性能不如在复域的联合估计。第四节还展示了用于cIRM估计的DNN结构推广到不可见的信噪比和扬声器。结果还显示了客观指标和听力评估之间的差距。虽然听力评估表明对估计的cIRM有明显的偏好,但这种偏好在PESQ和SNRfw(尤其是后者)的质量指标中并不明显。这可能是由于在计算分数[35]时忽略了阶段的客观度量的性质。据我们所知,这是第一个利用深度学习解决复杂领域语音分离问题的研究。未来可能还有改进的空间。例如,应该系统地检查这种任务的有效功能,可能需要开发新的功能。此外,在深度神经网络中可能需要引入在复杂领域更有效的新激活函数。