java使用minist手写数据集,用滴滴云Notebook快速上手PyTorch-MINIST手写体
在本教程中,您将学习如何快速使用PyTorch训练一个神经网络学习如何识别手写数字。
本文使用滴滴云Notebook作为开发环境,滴滴云Notebook服务集成了CUDA、CuDNN、Python、TensorFlow、Pytorch、MxNet、Keras等深度学习框架,无需用户自己安装。
Part.1
1,购买Notebook服务
注册滴滴云并实名认证后可购买Notebook服务
注册步骤:
2,进入控制台Notebook页面单击创建Notebook实例按钮
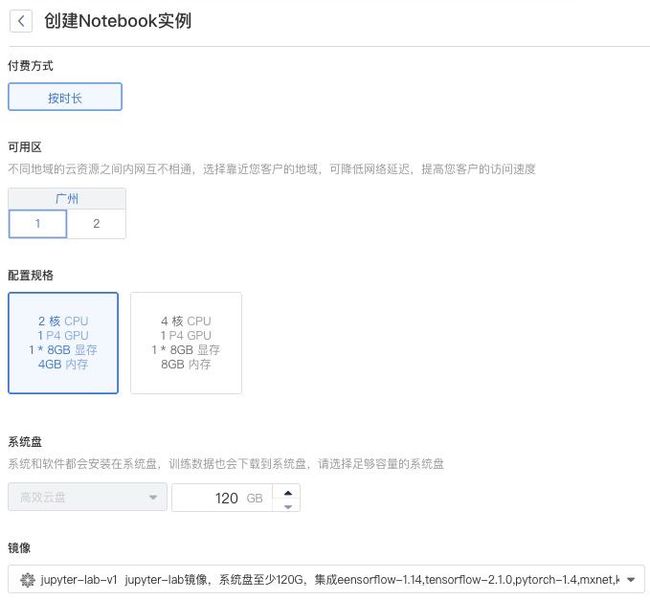
3,选择基础配置:
选择 付费方式:当前仅支持按时长。
选择 可用区:选择靠近您客户的地域,包括广州1、2区。
选择 配置规格:根据需要的CPU、GPU、显卡和内存,选择相关配置。
选择 镜像:提供了Jupyter Notebook镜像和Jupyter Lab镜像,这里选择>jupyter-lab-v1。
设置 系统盘:根据需求选择系统盘的大小,设置范围为80GB - 500GB。
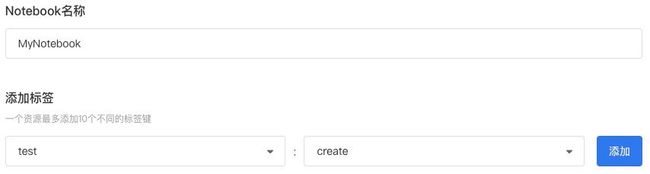
4,名称和标签
输入 Notebook名称。
输入 标签键以及键值,单击添加按钮,可添加多个标签。
5,访问Notebook
进入我的Notebook页面,在操作列单击打开Notebook。
进入Notebook详情页面,单击打开Notebook。

Part.2
构建MNIST手写体数字识别程序
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
下载经典的MNIST数据集
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 训练集Dataloader
train_loader = torch.utils.data.DataLoader(
datasets.MNIST(root='.', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])), batch_size=64, shuffle=True, num_workers=4)
# 测试集Dataloader
test_loader = torch.utils.data.DataLoader(
datasets.MNIST(root='.', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])), batch_size=64, shuffle=True, num_workers=4)
这里我们使用一个4层CNN(卷积神经网络),网络结构:Conv-Conv-FC-FC
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
# Perform the usual forward pass
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2(x), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
model = Net().to(device)
现在我们使用SGD(随机梯度下降)算法来训练模型,以有监督的方式学习分类任务
optimizer = optim.SGD(model.parameters(), lr=0.01)
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 1 == 0:
print('\rTrain Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()), end='')
def test():
with torch.no_grad():
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target).item()
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'
.format(test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
开始训练,每训练一个epoch测试一次模型,在20个epoch内,模型准确率可以达到98.7%
epochs = 20
for epoch in range(1, epochs + 1):
train(epoch)
test()
Train Epoch: 1 [29984/60000 (100%)] Loss: 0.130790
Test set: Average loss: 0.0033, Accuracy: 9370/10000 (94%)
Train Epoch: 2 [29984/60000 (100%)] Loss: 0.212607
Test set: Average loss: 0.0020, Accuracy: 9594/10000 (96%)
Train Epoch: 3 [29984/60000 (100%)] Loss: 0.054339
Test set: Average loss: 0.0016, Accuracy: 9673/10000 (97%)
Train Epoch: 4 [29984/60000 (100%)] Loss: 0.085429
Test set: Average loss: 0.0012, Accuracy: 9766/10000 (98%)
Train Epoch: 5 [29984/60000 (100%)] Loss: 0.084620
Test set: Average loss: 0.0010, Accuracy: 9800/10000 (98%)
Train Epoch: 6 [29984/60000 (100%)] Loss: 0.053965
Test set: Average loss: 0.0009, Accuracy: 9826/10000 (98%)
Train Epoch: 7 [29984/60000 (100%)] Loss: 0.098088
Test set: Average loss: 0.0008, Accuracy: 9826/10000 (98%)
Train Epoch: 8 [29184/60000 (49%)] Loss: 0.008589
滴滴云小程序上线啦!微信搜索“滴滴云助手”快来体验吧!
