面向大尺度的小目标检测《Towards Large-Scale Small Object Detection: Survey and Benchmarks》阅读笔记
论文地址:https://arxiv.org/pdf/2207.14096.pdf
1 引言
- 目标检测是对图像/视频中感兴趣的对象进行分类和定位的重要任务。目标检测取得了显著成就。
- 小目标检测(SOD)作为通用目标检测的子领域,在监控、无人机场景分析、行人检测、自动驾驶交通标志检测等各种场景中具有重要的理论和现实意义。
- 虽然在通用目标检测方面取得了实质性的进展,但小目标检测的研究进展相对较缓慢。检测小型和正常大小的物体方面仍然存在巨大的性能差距。
- 性能下降原因:
- 从有限和扭曲的小对象信息中学习适当特征表示的固有困难;
- 用于小目标检测的大规模数据集的稀缺性。
1.0.1 特征表示问题
小目标特征的低质量特征表示原因:(1)本身大小。(2)一般的特征提取方法。
具体表现:
- 目前流行的特征提取器对特征图进行降采样,减少空间冗余,学习高维特征,但却消除了微小物体的表征。
- 卷积过程中小物体的特征容易受到背景等实例的污染,使得网络很难捕获后续任务的关键鉴别信息。
解决特征表示问题的6类方法:
- 数据操作方法(data-manipulation)
- 尺度感知方法(scale-aware methods)
- 特征融合方法( feature-fusion methods)
- 超分辨率方法(super-resolution methods)
- 上下文建模方法( context-modeling methods)
1.0.2 数据集稀缺性问题
- 为了缓解数据的稀缺性,人们提出了一些针对小目标检测的数据集,如SOD [28]和TinyPerson [7]。
- 然而,这些小规模的数据集不能满足需求,因为训练有监督的cnn算法需要大量有标签数据。
- 此外,一些公共数据集包含有一定数量的小物体,如WiderFace[8]、SeaPerson[29]和DOTA [30]等。但有如下不足:
- 为相对确定模式的单类别检测任务(人脸检测、行人检测)而设计的。
- 微小对象只分布在几个类别中(DOTA数据集中的小型车辆)。
总之:
- 现有小目标检测数据集不能支持专门的基于CNN的小目标检测模型的训练。
- 不能作为评判多类别SOD的基准。
而PASCAL VOC[31]、ImageNet[32]、COCO[6]、DOTA[30]等大规模数据集对学术界和企业界有重要意义,促进了相关领域目标检测的发展。提出大规模SOD的数据集的重要性的发问。
分别基于驾驶场景和飞行器场景,提出两个大规模的小目标检测数据集SODA-D、SODA-A:
- SODA-D基于MVD的头部数据和我们的数据,MVD头部是街景的像素级理解,我们的数据基于板载摄像机和移动电话。24704个高质量和精挑的驾驶场景。用水平box标注了277596个实例,9个类别。
- SODA-A飞行器场景的小目标检测基准,有800203个水平矩形框的实例,涵盖9个类别。从谷歌地图中提取2510个高像素图像。
1.1 和先前的survey比较
两个方面不同于先前的survey。
- 跨域多个领域的专注于小目标检测的理解和适当时间的回顾。
- 提出了两个针对小目标检测定制的大规模基准测试集,并对几种具有代表性的检测算法进行了深入的评价和分析。
1.2 Scope(本文内容评估)
- 传统目标检测方法使用手工特征和机器学习。
- 小目标检测中因为应对尺度变化的能力有限,效果差。
- 2012年后,深度学习的强大学习能力给目标检测带来了巨大的提升。深度网络在尺度变化方面的突出建模能力和强大的信息抽取能力,使小目标检测获得巨大改进。
- 综述重点是基于深度学习的SOD的主要发展。
- 这篇文章的主要贡献有以下3点:
- 回顾了深度学习小目标检测的发展,提供了一个该领域最新进展的系统性调查。分为6类方法:数据操纵、尺度感知、特征融合、超分辨率、上下文方法。并分析优利弊。回顾了多个领域的十几个数据集。
- 发布两个小目标检测的大规模基准数据集。
- 研究了几种代表性目标检测方法在SODA上的性能,根据定量和定性的结果进行深入的分析,有利于后续小目标检测的算法设计。
2 小目标检测的回顾
2.1 问题定义
小目标通过一个面积阈值和长度阈值定义。下面的内容的小目标定义遵循原paper里面的定义,可能在我们提出的基准中有矛盾。
2.2 主要挑战
通用目标检测的一些常见挑战:类内变化、不准确定位、遮挡目标检测。
SOD(小目标检测)任务中存在的典型问题:对象信息丢失、噪声特征表示和边框扰动的低容忍度。
Information loss(信息损失)
通用目标检测范式:一个主干网络加一些检测头。
通用特征提取器利用下采样滤除噪声激活,减少特征图的空间像素,不可避免损失目标信息,几乎不损害大中物体的检测性能。但对于小目标来说不友好,因为检测头很难在高度结构化的表示之上给出准确的预测,小物体的微弱信号几乎消失了。
Noisy feature representation(噪声特征表示)
可区分性强的特征对于定位和分类都很重要。
- 小目标物体通常有低像素、低质量外观的特点,因此从它们扭曲的结构中学习有辨别力的特征是非常困难的。
- 小目标的原始特征倾向于被背景和其他实例污染,在学习到的特征中进一步引入噪声。
Low tolerance for bounding box perturbation(边框扰动的低容忍度)

图1:不同大小的GT框与预测框移动相同的像素距离下,IOU的不同变化。小目标的IOU变化更大,大目标的IOU变化更小。
预测框的微小变化会度小目标的IOU产生非常大的影响。
这证明了小目标物体相比大物体对边框定位扰动具有更低的容忍度,恶化了回归分支。
2.3 小目标物体检测方法的回顾
介绍了两阶段检测和一阶段检测,以及anchor-free检测方法的主要特点和流程。
小目标检测方法在通用目标检测框架上被精心设计。
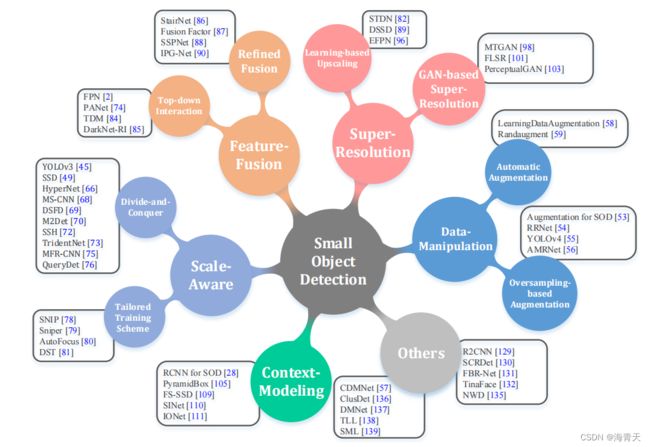
2.3.1 Data-manipulation methods(数据处理方法)
可以归为2类:基于过采样的数据增强、自动增强方案。
Oversampling-based augmentation strategy
随机复制粘贴:复制一个小目标的区域并随机粘贴到同一图像上的不同区域。
AdaResampling:基于复制粘贴,主要区别在于使用预先分割图来指导采样过程中粘贴有效位置的确定;对粘贴对象的比例变换进一步减少了比例差异。
Mosaic:连接4张图片产生新的图片样本。这个操作使得原本的目标变少了,提升了小目标物体的数量。
Automatic augmentation scheme
Zoph认为借助现有的分类任务的数据增强方法对于检测没有提升。他们对数据增强过程建模为一个离散的优化问题,寻找预置增强操作的最佳组合。使用强化学习去学习最优参数。但巨大的搜索空间会带来巨大计算成本。
Cubuk在只有单个失真量级的情况下,联合优化了所有的操作,同时保持概率参数均匀。
总结:
- 增加小目标实例数量可以解决数据稀缺的问题,这增加了正样本,让检测器更好地优化小物体。
- 不同体量的数据集之间的性能提升不一致,且可转移性也较差。
- 总之通过基于数据操作的方法所获得的性能增益是依赖于数据集的。
2.3.2 Scale-aware methods(尺度感知方法)
解决问题:交通场景图像和遥感图像的尺度变化很严重,导致了检测困难。
先前的检测方法使用带有滑动窗口的图像金字塔来解决问题。然而,这种限制表示容量的手工特征方法,在小目标上效果很差。
现在的深度模型常用多尺度特征来解决问题。有两种发展趋势:
- (1)采用多尺度特征,以 分治法 的方式检测不同大小的对象。
- (2)设计 定制方案 ,有效地训练多尺度物体。
Multi-scale detection in a divide-and-conquer fashion(以分治法处理多尺度检测)
思想:不同深度或层次的特征只负责检测相应尺度的物体。
- HyperNet 假设一个感兴趣区域(RoI)的信息可以分布在主干网络的所有层上,需要进行良好的组织。在此假设的基础上,他们连接并压缩从粗到细的特征,以获得保留小对象推理的超特征。
- Yang利用尺度依赖池化去选择一个适宜的特征层,以便后续进行小目标的池化操作。
- MS-CNN [68]在不同的中间层生成目标候选,每个中间层都专注于一定尺度范围内的对象,为小目标提供了最佳的感受野。
- Liu等人,[49]设计了单阶段多盒检测器(SSD),用于检测高分辨率特征图上的小物体。
- 根据这个路线图,DSFD [69]采用了由特征增强模块连接的两阶段检测器来检测不同尺度的人脸。
- YOLOv3 [45]通过添加并行分支来进行多尺度预测,其中高分辨率特征负责小对象。
- M2Det [70]构造了多级特征金字塔来检测对象。
- Li等人[71]建立了并行子网,其中专门学习小尺寸子网来检测小行人。
- SSH [72]结合了尺度变化的人脸检测器,每个探测器都经过一定尺度范围的训练,形成了一个强大的多尺度检测器来处理尺度变化极大的人脸。
- Trident-Net[73]构建了一个并行的多分支体系结构,其中每个分支都为拥有不同尺度的对象处理最佳的感受野。
- 受PANet [74]中区域级特征聚合的巨大成功启发,Zhang等[75]将多个深度的集合特征与全局特征连接起来,以获得对小交通对象更鲁棒和更有区别的表示。
- QueryDet [76]设计了级联查询策略,避免了对低级特征的冗余计算,使有效地检测高分辨率特征映射上的小对象成为可能。
Tailored training schemes(定制的训练方法)
- 基于通用的多尺度训练方案,Singh[78]等人[78]设计了一种新的训练范式——图像金字塔尺度归一化(SNIP)。它只考虑分辨率属于训练所需尺度范围的实例,其余部分简单忽略。小实例可以在最合理的尺度上处理小实例,而不影响对中到大对象的检测性能。
- Sniper [79]建议从一个多尺度的图像金字塔中取样chip,以进行有效的训练。
- Najibi等人[80]提出了一种检测小物体的从粗到细的管道。
- 考虑到[2]、[63]、[73]等方法没有探索数据准备与模型优化之间的协作,Chen等[81]设计了反馈驱动的训练范式,动态指导数据准备,进一步平衡小对象的训练损失。
- Yu等人[7]引入了一种基于统计的尺度一致性匹配策略。
然而,基于分治的方法将不同大小的对象映射到相应的尺度级别可能会混淆检测器,因为单层的信息不足以做出准确的预测。
另一方面,针对增强多尺度训练的定制机制通常会引入额外的计算量,阻碍了端到端优化。
2.3.3 Feature-fusion methods(特征融合方法)
基本概念:深度CNN架构在不同的空间分辨率下生成层次特征图,低级特征描述精细细节和定位线索,高级特征有丰富的语义信息。
问题:子采样操作可能会导致小目标细节在深层响应中消失。
解决办法和难点:可行方法是利用浅层特征去检测小目标。浅层特征图有利于定位,但在早期阶段易受光照、变形和物体姿态等变化的影响,使分类任务困难。为了克服这一困境,许多方法利用特征融合,整合不同层或分支的特征,以获得对小对象更好的特征表示。
Top-down information interaction(自顶而下的信息交互)
受手工工程特征[63]时代使用的金字塔结构的激励,开创性的作品[2],[84]构建自上而下的路径来加强浅层和深层之间的交互, 使高分辨率表示同时具有丰富的语义和小物体的精细定位。[84]等人引入了Top-Down调制(TDM)网络,其中自顶向下模块学习什么样的语义或上下文应该保留,横向模块转换低级特性以进行后续融合。Lin等人[2]提出了特征金字塔网络(FPN),其中具有高分辨率但低级语义的早期特征与具有低分辨率但高级语义的后期特征聚合。
这种简单而有效的设计已经成为特征提取器的一个重要组成部分。为了缓解单向金字塔结构中遇到的定位信号的不足,PANet [74]通过双向路径丰富了特征层次,通过精确的定位信号增强了更深层次的特征。Zand等人[85]在DarkNet-53[44]和跳过连接[10]的基础上构建了DarkNet-RI,生成不同尺度的高级语义特征图。
Refined feature fusion(精细特征融合)
尽管基本交互设计成功且受欢迎,但由于其固有的尺度级不一致,基本的尺度级不一致,基本的上采样和融合不能处理[74]。观察到这一点,以下方法旨在以适当的方式细化主干不同阶段的特征,或者通过动态控制不同层[87]、[88]之间的信息流来优化融合过程。
Woo等人[86]提出StairNet,利用反卷积扩大特征图,这种基于学习的上采样函数可以实现比基于 na¨ıve核的上采样更精细的特征,并允许不同金字塔层次的信息更有效地传播[89]。
Liu等人[90]引入了IPG-Net,将图像金字塔[63]获得的一组不同分辨率的图像输入到设计的IPG转换模块中,提取浅层特征,以补充空间信息和细节。
Gong等人设计了一个基于统计的融合因子来控制相邻层的信息流。
SSPNet [88]注意到基于FPN的方法中遇到的梯度不一致导致低级特征[91]的表示能力下降了,它突出了不同层的特定尺度特征,并利用FPN中相邻层的关系来实现适当的特征共享。
特征融合方法可以弥合低金字塔层次和高金字塔层次之间的空间和语义差距。然而,在当前的检测范式中,由于基于大小的金字塔分配策略,小物体通常被分配到最低的金字塔特征(最高的空间分辨率),这在实践中造成了计算负担和冗余表示。此外,网络内的信息流并不总是有利于小对象的表示。
我们的目标不仅是赋予低级别的特征更多的语义,而且还要防止小物体的原始响应被更深层次的信号所淹没。不幸的是,鱼与熊掌不可兼得(you can’t have a cake and eat it.),因此这个困境需要仔细解决。
2.3.4 Super-resolution methods(超分辨率方法)
一个直观的方法是通过双线性插值[92]和超分辨率网络[93]来提高输入图像的分辨率。然而,基于插值的方法,作为一个局部操作,通常不能捕捉全局理解,并遭受镶嵌效应[94]。对于那些尺寸极其有限的物体来说,这种情况可能会变得更糟。此外,我们希望尺度提升的操作可以恢复小物体的扭曲结构,而不是简单地放大它们的模糊外观。为此,一些试探性的方法通过借鉴超分辨率领域的现成技术来超分辨输入图像或特征。这些方法大多采用生成式对抗网络GANs来计算高质量的有利于小目标检测的表示,而其他方法则选择参数化的上采样操作来扩大特征。
Learning-based upscaling(基于学习的尺度提升)
在特征提取阶段[96],盲目地增加输入图像的尺度会导致性能饱和[78]和不可忽略的计算成本。为了克服这个困难,遵循这条线的方法更倾向于超分辨特征映射。它们通常利用基于学习的上采样操作来提高特征映射的分辨率和丰富结构。
在SSD [49]之上,DSSD [89]采用反卷积操作来获得专门用于小目标检测的高分辨率特征。Zhou等人[82]和Deng等人[96]探索亚像素卷积[97]进行有效上采样。
GAN-based super-resolution frameworks(基于GAN超分辨框架)
古德费勒等人[95]提出GAN通过跟踪生成器和鉴别器之间的双人极大极小博弈来生成视觉上真实的数据。不出所料,这种能力启发研究人员探索这种强大的生成高质量小物体表示的强大范式。然而,直接超分辨整个图像的特征提取器的负担。
为了减轻这种开销,MTGAN [98]通过生成器网络超分辨了roi的patch。
Bai等人[99]将该范式扩展到人脸检测任务,Na等人[100]将超分辨率方法应用于小的候选区域,以获得更好的性能。
虽然超分辨目标斑块可以部分重建小物体的模糊外观,但该方案忽略了在网络预测[101]、[102]中起重要作用的上下文线索。
为了解决这个问题,Li等人[103]设计了感知器来挖掘和利用小尺度和大型物体之间的内在相关性,其中生成器学习将小物体的弱表示映射到超分辨物体,以欺骗鉴别器。为了更进一步,Noh等人[101]对超分辨率程序引入了直接监督。
由于尺寸有限,小对象的信号在特征提取后不可避免地丢失,导致后续的RoI池化操作几乎无法计算结构表示。通过挖掘小尺度对象和大尺度对象之间的内在关联,7个超分辨率框架允许部分恢复小对象的详细表示。然而,无论是基于学习的尺度提升方法还是基于GAN的方法,都必须在繁重的计算和整体性能之间保持平衡。此外,基于gan的方法倾向于制造伪纹理和伪影,对检测产生负面影响。更糟糕的是,超分辨率体系结构的存在使端到端优化变得复杂。
2.3.5 Context-modeling methods(上下文建模方法)
我们人类可以有效地利用环境与对象之间的关系或对象之间的关系来促进对象和场景的识别[104],[105]。这种捕获语义或空间关联的先验知识被称为上下文,它传递了物体区域之外的证据或线索。上下文信息不仅在人类[102]、[104]的视觉系统中非常重要,而且在对象识别[106]、语义分割[107]和实例分割[108]等场景理解任务中也非常重要。有趣的是,信息上下文有时可以比对象本身提供更多的决策支持,特别是当涉及到识别[104]观看质量较差的对象时。为此,有几种方法利用上下文线索来提高对小物体的检测。
Chen等人[28]使用了上下文区域的表示,其中包含候选patch进行后续识别。
Hu等人[92]研究了如何有效地编码对象范围之外的区域,并以尺度不变的方式对局部上下文信息进行建模,以检测微小的人脸。
PyramidBox[105]充分利用上下文线索来寻找与背景难以区分的小而模糊的人脸。
图像中物体的内在相关性也可以看作是上下文。
FS-SSD [109]利用隐式的空间上下文信息,即类内和类间实例之间的距离,以低置信度重新检测对象。
假设原始的RoI池化操作将破坏小对象的结构,SINet [110]引入了一个上下文感知的RoI池化层来维护上下文信息。
IONet [111]通过两个四向IRNN结构[112]计算全局上下文特征,以便更好地检测小的和严重遮挡的物体。
从信息论的角度来看,考虑的特征类型越多,越可能获得的检测精度越高。受共识的启发,上下文启动已被广泛研究,以产生更具辨别性的特征,特别是对于线索不足的小物体,从而能够精确识别。
不幸的是,无论是整体上下文建模还是局部上下文启动,都混淆了哪些区域应该被编码为上下文。换句话说,当前的上下文建模机制以启发式和经验的方式确定上下文区域,这不能保证所构建的表示在检测中是足够可解释的。
2.3.6 其他方法
属于上述五类的方法可以涵盖促进小对象检测的大多数尝试,我们也补充了一些其他的解决方案,希望这些策略能够激励读者从其他有趣的角度来考虑这个具有挑战性的任务。
Attention-based methods(基于注意力机制的方法)
我们人类可以快速关注和区分对象而忽略这些不必要的部分通过在整个场景中的一系列粗略查看[118],[119],这惊人的能力在我们的感知系统通常被称为视觉注意机制,在我们的视觉系统扮演着至关重要的作用[120],[121]。毫不奇怪,这种强大的机制在之前的文献[122]、[123]、[124]、[125]、[126]中得到了广泛的研究,并在[5]、[9]、[127]、[128]等许多视觉领域中显示出了巨大的潜力。通过将特征映射的不同部分分配不同的权重,注意力建模确实强调了有价值的区域,同时抑制了那些可有可无的区域。自然地,我们可以使用这种优越的方案来突出显示在图像中倾向于由背景和噪声模式所主导的小物体。
Pang等人[129]采用全局注意块来抑制假警报,并有效地检测大规模遥感图像中的小物体。
SCRDet [130]设计了一种面向目标的检测器,以监督的方式训练像素注意和通道注意,以突出小的物体区域,同时消除噪声的干扰。
FBR-Net [131]扩展了 anchor-free检测器的FCOS [4],平衡了不同金字塔层次的特征,增强了在复杂情况下对小物体的学习能力。
Localization-driven optimization(定位驱动的优化)
定位作为检测的主要任务之一,在大多数检测范式[1]、[3]、[4]、[44]、[45]、[46]、[47]中被表述为一个回归问题。然而,当前主流方向的检测器采用的回归目标与评价指标IoU不能达到很好的结合效果。这种优化的不一致性将影响探测器的性能,特别是在微小物体上。
考虑到这一点,有几种方法旨在为定位分支配备IOU感知(IOU-awareness)或寻求适当的度量标准。
TinaFace [132]在RetinaNet[3]中增加了一个DIoU [133]分支,并最终获得了一个简单但强大的微小人脸检测基线。
Xu等人[134]观察到IoU会随微小物体的预测框的轻微偏差而急剧变化,因此提出了一种新的度量方法(Dot Distance)来缓解这种情况。
类似地,NWD [135]引入了==归一化瓦瑟斯坦距离(Normalized Wasserstein Distance)==来优化微小物体探测器的定位度量。
Density analysis guided detection(密度分析导引的检测)
高分辨率图像中的小对象往往分布不均匀、稀疏的[136],一般的划分再检测方案在这些空块上的计算过多,导致推理效率低下。我们能过滤掉那些没有目标的区域,从而减少无用的操作来提高检测能力吗?答案是肯定的!在这一领域的努力打破了处理高分辨率图像的通用管道链,他们首先抽象出包含目标的区域,然后对其进行检测。
Yang等人[136]提出了一种聚类检测网络(ClusDet),它充分利用对象之间的语义和空间信息来生成聚类簇然后进行检测。
根据这一模式,Duan等人[57]和Li等人[137]都利用像素级监督来进行密度估计,实现了更精确的密度图,从而很好地描述了物体的分布。
Other issues(其他问题)
一些试探性的策略采用了其他领域有趣的技术来更好地检测小物体。
Song等人[138]认为传统的标记方式会引入偏差和歧义,因此提出了一种新的行人拓扑标记,允许使用所提出的躯体拓扑线定位(TLL)在小规模实例上进行更精确的定位。
与超分辨率方法类似,Wu等人[139]使用了所提出的Mimic Loss来弥合小行人的区域表示和大规模行人的区域表示之间的差距。
Kim等人[140]受到人类视觉理解机制的记忆过程的启发,设计了一种基于记忆学习的小规模行人检测的新框架。
参考文献
[1] S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards realtime object detection with region proposal networks,” TPAMI,
vol. 39, no. 6, pp. 1137–1149, 2017.
18
[2] T. Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie,
“Feature pyramid networks for object detection,” in CVPR, 2017,
pp. 2117–2125.
[3] T. Lin, P. Goyal, R. Girshick, K. He, and P. Doll´ar, “Focal loss for
dense object detection,” TPAMI, vol. 42, no. 2, pp. 318–327, 2020.
[4] Z. Tian, C. Shen, H. Chen, and T. He, “Fcos: A simple and strong
anchor-free object detector,” TPAMI, vol. 44, no. 4, pp. 1922–1933,
2022.
[5] N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and
S. Zagoruyko, “End-to-end object detection with transformers,”
in ECCV, 2020, pp. 213–229.
[6] T. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan,
P. Doll´ar, and C. L. Zitnick, “Microsoft coco: Common objects in
context,” in ECCV, 2014, pp. 740–755.
[7] X. Yu, Y. Gong, N. Jiang, Q. Ye, and Z. Han, “Scale match for tiny
person detection,” in WACV, 2020, pp. 1257–1265.
[8] S. Yang, P. Luo, C. C. Loy, and X. Tang, “Wider face: A face
detection benchmark,” in CVPR, 2016, pp. 5525–5533.
[9] X. Dai, Y. Chen, B. Xiao, D. Chen, M. Liu, L. Yuan, and L. Zhang,
“Dynamic head: Unifying object detection heads with attentions,” in CVPR, 2021, pp. 7373–7382.
[10] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for
image recognition,” in CVPR, 2016, pp. 770–778.
[11] S. Xie, R. Girshick, P. Doll´ar, Z. Tu, and K. He, “Aggregated
residual transformations for deep neural networks,” in CVPR,
2017, pp. 1492–1500.
[12] S.-H. Gao, M.-M. Cheng, K. Zhao, X.-Y. Zhang, M.-H. Yang,
and P. Torr, “Res2net: A new multi-scale backbone architecture,”
TPAMI, vol. 43, no. 2, pp. 652–662, 2021.
[13] L. Liu, W. Ouyang, X. Wang, P. Fieguth, J. Chen, X. Liu, and
M. Pietik¨ainen, “Deep learning for generic object detection: A
survey,” IJCV, vol. 128, no. 2, pp. 261–318, 2020.
[14] Z.-Q. Zhao, P. Zheng, S.-t. Xu, and X. Wu, “Object detection with
deep learning: A review,” TNNLS, vol. 30, no. 11, pp. 3212–3232,
2019.
[15] D. Geronimo, A. M. Lopez, A. D. Sappa, and T. Graf, “Survey
of pedestrian detection for advanced driver assistance systems,”
TPAMI, vol. 32, no. 7, pp. 1239–1258, 2009.
[16] P. Dollar, C. Wojek, B. Schiele, and P. Perona, “Pedestrian detection: An evaluation of the state of the art,” TPAMI, vol. 34, no. 4,
pp. 743–761, 2011.
[17] J. Cao, Y. Pang, J. Xie, F. S. Khan, and L. Shao, “From handcrafted
to deep features for pedestrian detection: A survey,” TPAMI, pp.
1–1, 2021.
[18] Q. Ye and D. Doermann, “Text detection and recognition in
imagery: A survey,” TPAMI, vol. 37, no. 7, pp. 1480–1500, 2014.
[19] G. Cheng and J. Han, “A survey on object detection in optical
remote sensing images,” ISPRS J. Photogramm. Remote Sens., vol.
117, pp. 11–28, 2016.
[20] K. Li, G. Wan, G. Cheng, L. Meng, and J. Han, “Object detection in
optical remote sensing images: A survey and a new benchmark,”
ISPRS J. Photogramm. Remote Sens., vol. 159, pp. 296–307, 2020.
[21] M. B. Jensen, M. P. Philipsen, A. Møgelmose, T. B. Moeslund, and
M. M. Trivedi, “Vision for looking at traffic lights: Issues, survey,
and perspectives,” IEEE Trans. Intell. Transp. Syst., vol. 17, no. 7,
pp. 1800–1815, 2016.
[22] A. Boukerche and Z. Hou, “Object detection using deep learning
methods in traffic scenarios,” ACM Comput Surv, vol. 54, no. 2,
pp. 1–35, 2021.
[23] K. Oksuz, B. C. Cam, S. Kalkan, and E. Akbas, “Imbalance
problems in object detection: A review,” TPAMI, vol. 43, no. 10,
pp. 3388–3415, 2020.
[24] D. Zhang, J. Han, G. Cheng, and M.-H. Yang, “Weakly supervised
object localization and detection: A survey,” TPAMI, pp. 1–1,
2021.
[25] K. Tong, Y. Wu, and F. Zhou, “Recent advances in small object
detection based on deep learning: A review,” Image Vis Comput,
vol. 97, p. 103910, 2020.
[26] Y. Liu, P. Sun, N. Wergeles, and Y. Shang, “A survey and performance evaluation of deep learning methods for small object
detection,” Expert Syst. Appl., vol. 172, p. 114602, 2021.
[27] G. Chen, H. Wang, K. Chen, Z. Li, Z. Song, Y. Liu, W. Chen,
and A. Knoll, “A survey of the four pillars for small object detection: Multiscale representation, contextual information, superresolution, and region proposal,” IEEE Trans. Syst., Man, Cybern.
Syst., vol. 52, no. 2, pp. 936–953, 2022.
[28] C. Chen, M.-Y. Liu, O. Tuzel, and J. Xiao, “R-cnn for small object
detection,” in ACCV, 2016, pp. 214–230.
[29] X. Yu, P. Chen, D. Wu, N. Hassan, G. Li, J. Yan, H. Shi, Q. Ye, and
Z. Han, “Object localization under single coarse point supervision,” in CVPR, 2022, pp. 4868–4877.
[30] J. Ding, N. Xue, G.-S. Xia, X. Bai, W. Yang, M. Yang, S. Belongie,
J. Luo, M. Datcu, M. Pelillo, and L. Zhang, “Object detection in
aerial images: A large-scale benchmark and challenges,” TPAMI,
pp. 1–1, 2021.
[31] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and
A. Zisserman, “The pascal visual object classes (voc) challenge,”
IJCV, vol. 88, no. 2, pp. 303–338, 2010.
[32] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei,
“Imagenet: A large-scale hierarchical image database,” in CVPR,
2009, pp. 248–255.
[33] G. Neuhold, T. Ollmann, S. R. Bul`o, and P. Kontschieder, “The
mapillary vistas dataset for semantic understanding of street
scenes,” in ICCV, 2017, pp. 5000–5009.
[34] D. G. Lowe, “Distinctive image features from scale-invariant
keypoints,” IJCV, vol. 60, no. 2, pp. 91–110, 2004.
[35] N. Dalal and B. Triggs, “Histograms of oriented gradients for
human detection,” in CVPR, 2005, pp. 886–893.
[36] H. Bay, A. Ess, T. Tuytelaars, and L. Van Gool, “Speeded-up
robust features (surf),” Comput Vis Image Underst, vol. 110, no. 3,
pp. 346–359, 2008.
[37] C. Cortes and V. Vapnik, “Support-vector networks,” Mach Learn,
vol. 20, no. 3, pp. 273–297, 1995.
[38] T. K. Ho, “Random decision forests,” in ICDAR, 1995, pp. 278–
282.
[39] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classi-
fication with deep convolutional neural networks,” in NeurIPS,
2012, pp. 1097–1105.
[40] R. Girshick, J. Donahue, T. Darrell, and J. Malik, “Region-based
convolutional networks for accurate object detection and segmentation,” TPAMI, vol. 38, no. 1, pp. 142–158, 2015.
[41] H. Noh, S. Hong, and B. Han, “Learning deconvolution network
for semantic segmentation,” in ICCV, 2015, pp. 1520–1528.
[42] L. Chen, H. Zheng, Z. Yan, and Y. Li, “Discriminative region
mining for object detection,” TMM, vol. 23, pp. 4297–4310, 2021.
[43] Z. Qin, Z. Li, Z. Zhang, Y. Bao, G. Yu, Y. Peng, and J. Sun,
“Thundernet: Towards real-time generic object detection on mobile devices,” in ICCV, 2019, pp. 6717–6726.
[44] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only
look once: Unified, real-time object detection,” in CVPR, 2016,
pp. 779–788.
[45] J. Redmon and A. Farhadi, “Yolov3: An incremental improvement,” arXiv preprint arXiv:1804.02767, 2018.
[46] R. Girshick, “Fast r-cnn,” in ICCV, 2015, pp. 1440–1448.
[47] X. Zhou, D. Wang, and P. Kr¨ahenb¨uhl, “Objects as points,” arXiv
preprint arXiv:1904.07850, 2019.
[48] K. He, X. Zhang, S. Ren, and J. Sun, “Spatial pyramid pooling
in deep convolutional networks for visual recognition,” TPAMI,
vol. 37, no. 9, pp. 1904–1916, 2015.
[49] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, and
A. C. Berg, “Ssd: Single shot multibox detector,” in ECCV, 2016,
pp. 21–37.
[50] K. Duan, S. Bai, L. Xie, H. Qi, Q. Huang, and Q. Tian, “Centernet:
Keypoint triplets for object detection,” in ICCV, 2019, pp. 6569–
6578.
[51] H. Law and J. Deng, “Cornernet: Detecting objects as paired
keypoints,” in ECCV, 2018, pp. 734–750.
[52] X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable
detr: Deformable transformers for end-to-end object detection,”
in ICLR, 2020.
[53] M. Kisantal, Z. Wojna, J. Murawski, J. Naruniec, and K. Cho,
“Augmentation for small object detection,” arXiv preprint
arXiv:1902.07296, 2019.
[54] C. Chen, Y. Zhang, Q. Lv, S. Wei, X. Wang, X. Sun, and J. Dong,
“Rrnet: A hybrid detector for object detection in drone-captured
images,” in ICCVW, 2019, pp. 100–108.
[55] A. Bochkovskiy, C.-Y. Wang, and H.-Y. M. Liao, “Yolov4: Optimal speed and accuracy of object detection,” arXiv preprint
arXiv:2004.10934, 2020.
[56] Z. Wei, C. Duan, X. Song, Y. Tian, and H. Wang, “Amrnet: Chips
augmentation in aerial images object detection,” arXiv preprint
arXiv:2009.07168, 2020.
[57] C. Duan, Z. Wei, C. Zhang, S. Qu, and H. Wang, “Coarse-grained
density map guided object detection in aerial images,” in ICCVW,
2021, pp. 2789–2798.
[58] B. Zoph, E. D. Cubuk, G. Ghiasi, T.-Y. Lin, J. Shlens, and Q. V. Le,
“Learning data augmentation strategies for object detection,” in
ECCV, 2020, pp. 566–583.
[59] B. Zoph and Q. V. Le, “Neural architecture search with reinforcement learning,” arXiv preprint arXiv:1611.01578, 2016.
[60] E. D. Cubuk, B. Zoph, J. Shlens, and Q. V. Le, “Randaugment:
Practical automated data augmentation with a reduced search
space,” in CVPRW, 2020, pp. 3008–3017.
[61] P. Doll´ar, R. Appel, S. Belongie, and P. Perona, “Fast feature
pyramids for object detection,” TPAMI, vol. 36, no. 8, pp. 1532–
1545, 2014.
[62] P. F. Felzenszwalb, R. B. Girshick, D. McAllester, and D. Ramanan, “Object detection with discriminatively trained partbased models,” TPAMI, vol. 32, no. 9, pp. 1627–1645, 2010.
[63] E. H. Adelson, C. H. Anderson, J. R. Bergen, P. J. Burt, and J. M.
Ogden, “Pyramid methods in image processing,” RCA engineer,
vol. 29, no. 6, pp. 33–41, 1984.
[64] B. Hariharan, P. Arbelaez, R. Girshick, and J. Malik, “Object
instance segmentation and fine-grained localization using hypercolumns,” TPAMI, vol. 39, no. 4, pp. 627–639, 2016.
[65] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid scene parsing
network,” in CVPR, 2017, pp. 6230–6239.
[66] T. Kong, A. Yao, Y. Chen, and F. Sun, “Hypernet: Towards
accurate region proposal generation and joint object detection,”
in CVPR, 2016, pp. 845–853.
[67] F. Yang, W. Choi, and Y. Lin, “Exploit all the layers: Fast and
accurate cnn object detector with scale dependent pooling and
cascaded rejection classifiers,” in CVPR, 2016, pp. 2129–2137.
[68] Z. Cai, Q. Fan, R. S. Feris, and N. Vasconcelos, “A unified
multi-scale deep convolutional neural network for fast object
detection,” in ECCV, 2016, pp. 354–370.
[69] J. Li, Y. Wang, C. Wang, Y. Tai, J. Qian, J. Yang, C. Wang, J. Li,
and F. Huang, “Dsfd: Dual shot face detector,” in CVPR, 2019,
pp. 5055–5064.
[70] Q. Zhao, T. Sheng, Y. Wang, Z. Tang, Y. Chen, L. Cai, and H. Ling,
“M2det: A single-shot object detector based on multi-level feature
pyramid network,” in AAAI, 2019, pp. 9259–9266.
[71] J. Li, X. Liang, S. Shen, T. Xu, J. Feng, and S. Yan, “Scale-aware fast
r-cnn for pedestrian detection,” TMM, vol. 20, no. 4, pp. 985–996,
2017.
[72] M. Najibi, P. Samangouei, R. Chellappa, and L. S. Davis, “Ssh:
Single stage headless face detector,” in ICCV, 2017, pp. 4885–4894.
[73] Y. Li, Y. Chen, N. Wang, and Z.-X. Zhang, “Scale-aware trident
networks for object detection,” in ICCV, 2019, pp. 6053–6062.
[74] S. Liu, L. Qi, H. Qin, J. Shi, and J. Jia, “Path aggregation network
for instance segmentation,” in CVPR, 2018, pp. 8759–8768.
[75] H. Zhang, K. Wang, Y. Tian, C. Gou, and F.-Y. Wang, “Mfrcnn: Incorporating multi-scale features and global information
for traffic object detection,” IEEE Trans. Veh. Technol., vol. 67, no. 9,
pp. 8019–8030, 2018.
[76] C. Yang, Z. Huang, and N. Wang, “Querydet: Cascaded sparse
query for accelerating high-resolution small object detection,” in
CVPR, 2022, pp. 13 668–13 677.
[77] J. Huang et al., “Speed/accuracy trade-offs for modern convolutional object detectors,” in CVPR, 2017, pp. 3296–3297.
[78] B. Singh and L. S. Davis, “An analysis of scale invariance in object
detection-snip,” in CVPR, 2018, pp. 3578–3587.
[79] B. Singh, M. Najibi, and L. S. Davis, “Sniper: Efficient multi-scale
training,” in NeurIPS, vol. 31, 2018.
[80] M. Najibi, B. Singh, and L. Davis, “Autofocus: Efficient multiscale inference,” in ICCV, 2019, pp. 9745–9755.
[81] Y. Chen, P. Zhang, Z. Li, Y. Li, X. Zhang, L. Qi, J. Sun, and
J. Jia, “Dynamic scale training for object detection,” arXiv preprint
arXiv:2004.12432, 2020.
[82] P. Zhou, B. Ni, C. Geng, J. Hu, and Y. Xu, “Scale-transferrable
object detection,” in CVPR, 2018, pp. 528–537.
[83] J. Wang, Y. Yuan, and G. Yu, “Face attention network: An
effective face detector for the occluded faces,” arXiv preprint
arXiv:1711.07246, 2017.
[84] A. Shrivastava, R. Sukthankar, J. Malik, and A. Gupta, “Beyond
skip connections: Top-down modulation for object detection,”
arXiv preprint arXiv:1612.06851, 2016.
[85] M. Zand, A. Etemad, and M. Greenspan, “Oriented bounding
boxes for small and freely rotated objects,” IEEE Trans. Geosci.
Remote Sens., vol. 60, pp. 1–15, 2021.
[86] S. Woo, S. Hwang, and I. S. Kweon, “Stairnet: Top-down semantic
aggregation for accurate one shot detection,” in WACV, 2018, pp.
1093–1102.
[87] Y. Gong, X. Yu, Y. Ding, X. Peng, J. Zhao, and Z. Han, “Effective
fusion factor in fpn for tiny object detection,” in WACV, 2021, pp.
1159–1167.
[88] M. Hong, S. Li, Y. Yang, F. Zhu, Q. Zhao, and L. Lu, “Sspnet:
Scale selection pyramid network for tiny person detection from
uav images,” IEEE Geosci. Remote. Sens. Lett., vol. 19, pp. 1–5,
2021.
[89] C.-Y. Fu, W. Liu, A. Ranga, A. Tyagi, and A. C. Berg,
“Dssd: Deconvolutional single shot detector,” arXiv preprint
arXiv:1701.06659, 2017.
[90] Z. Liu, G. Gao, L. Sun, and L. Fang, “Ipg-net: Image pyramid
guidance network for small object detection,” in CVPRW, 2020,
pp. 4422–4430.
[91] S. Liu, D. Huang, and Y. Wang, “Learning spatial fusion for
single-shot object detection,” arXiv preprint arXiv:1911.09516,
2019.
[92] P. Hu and D. Ramanan, “Finding tiny faces,” in CVPR, 2017, pp.
1522–1530.
[93] M. Haris, G. Shakhnarovich, and N. Ukita, “Task-driven super resolution: Object detection in low-resolution images,” in
NeurIPS, 2021, pp. 387–395.
[94] J. Wang, K. Chen, R. Xu, Z. Liu, C. C. Loy, and D. Lin, “Carafe:
Content-aware reassembly of features,” in ICCV, 2019, pp. 3007–
3016.
[95] I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. WardeFarley, S. Ozair, A. C. Courville, and Y. Bengio, “Generative
adversarial nets,” in NeurIPS, 2014, pp. 2672–2680.
[96] C. Deng, M. Wang, L. Liu, Y. Liu, and Y. Jiang, “Extended feature
pyramid network for small object detection,” TMM, vol. 24, pp.
1968–1979, 2021.
[97] W. Shi, J. Caballero, F. Husz´ar, J. Totz, A. P. Aitken, R. Bishop,
D. Rueckert, and Z. Wang, “Real-time single image and video
super-resolution using an efficient sub-pixel convolutional neural
network,” in CVPR, 2016, pp. 1874–1883.
[98] Y. Bai, Y. Zhang, M. Ding, and B. Ghanem, “Sod-mtgan: Small
object detection via multi-task generative adversarial network,”
in ECCV, 2018, pp. 210–226.
[99] ——, “Finding tiny faces in the wild with generative adversarial
network,” in CVPR, 2018, pp. 21–30.
[100] B. Na and G. C. Fox, “Object detection by a super-resolution
method and a convolutional neural networks,” in BigData, 2018,
pp. 2263–2269.
[101] J. Noh, W. Bae, W. Lee, J. Seo, and G. Kim, “Better to follow,
follow to be better: Towards precise supervision of feature superresolution for small object detection,” in ICCV, 2019, pp. 9724–
9733.
[102] S. K. Divvala, D. Hoiem, J. H. Hays, A. A. Efros, and M. Hebert,
“An empirical study of context in object detection,” in CVPR,
2009, pp. 1271–1278.
[103] J. Li, X. Liang, Y. Wei, T. Xu, J. Feng, and S. Yan, “Perceptual
generative adversarial networks for small object detection,” in
CVPR, 2017, pp. 1951–1959.
[104] A. Torralba, “Contextual priming for object detection,” IJCV,
vol. 53, no. 2, pp. 169–191, 2003.
[105] X. Tang, D. K. Du, Z. He, and J. Liu, “Pyramidbox: A contextassisted single shot face detector,” in ECCV, 2018, pp. 812–828.
[106] D. Parikh, C. L. Zitnick, and T. Chen, “Exploring tiny images: The
roles of appearance and contextual information for machine and
human object recognition,” TPAMI, vol. 34, no. 10, pp. 1978–1991,
2011.
[107] H. Zhang, K. Dana, J. Shi, Z. Zhang, X. Wang, A. Tyagi, and
A. Agrawal, “Context encoding for semantic segmentation,” in
CVPR, 2018, pp. 7151–7160.
[108] K. Chen, J. Pang, J. Wang, Y. Xiong, X. Li, S. Sun, W. Feng,
Z. Liu, J. Shi, W. Ouyang et al., “Hybrid task cascade for instance
segmentation,” in CVPR, 2019, pp. 4969–4978.
[109] X. Liang, J. Zhang, L. Zhuo, Y. Li, and Q. Tian, “Small object
detection in unmanned aerial vehicle images using feature fusion and scaling-based single shot detector with spatial context
analysis,” TCSVT, vol. 30, no. 6, pp. 1758–1770, 2020.
[110] X. Hu, X. Xu, Y. Xiao, H. Chen, S. He, J. Qin, and P.-A. Heng,
“Sinet: A scale-insensitive convolutional neural network for fast
vehicle detection,” IEEE Trans. Intell. Transp. Syst., vol. 20, no. 3,
pp. 1010–1019, 2019.
[111] S. Bell, C. L. Zitnick, K. Bala, and R. Girshick, “Inside-outside
net: Detecting objects in context with skip pooling and recurrent
neural networks,” in CVPR, 2016, pp. 2874–2883.
[112] Q. V. Le, N. Jaitly, and G. E. Hinton, “A simple way to initialize recurrent networks of rectified linear units,” arXiv preprint
arXiv:1504.00941, 2015.
[113] M. Braun, S. Krebs, F. Flohr, and D. M. Gavrila, “Eurocity persons: A novel benchmark for person detection in traffic scenes,”
TPAMI, vol. 41, no. 8, pp. 1844–1861, 2019.
[114] S. Zhang, Y. Xie, J. Wan, H. Xia, S. Z. Li, and G. Guo, “Widerperson: A diverse dataset for dense pedestrian detection in the
wild,” TMM, vol. 22, no. 2, pp. 380–393, 2020.
[115] Z. Zhu, D. Liang, S. Zhang, X. Huang, B. Li, and S. Hu, “Trafficsign detection and classification in the wild,” in CVPR, 2016, pp.
2110–2118.
[116] J. Wang, W. Yang, H. Guo, R. Zhang, and G.-S. Xia, “Tiny object
detection in aerial images,” in ICPR, 2021, pp. 3791–3798.
[117] Q. Wang, J. Gao, W. Lin, and X. Li, “Nwpu-crowd: A large-scale
benchmark for crowd counting and localization,” TPAMI, vol. 43,
no. 6, pp. 2141–2149, 2021.
[118] A. Borji and L. Itti, “State-of-the-art in visual attention modeling,”
TPAMI, vol. 35, no. 1, pp. 185–207, 2012.
[119] W. Wang, J. Shen, X. Lu, S. C. H. Hoi, and H. Ling, “Paying
attention to video object pattern understanding,” TPAMI, vol. 43,
no. 7, pp. 2413–2428, 2021.
[120] L. Itti, C. Koch, and E. Niebur, “A model of saliency-based visual
attention for rapid scene analysis,” TPAMI, vol. 20, no. 11, pp.
1254–1259, 1998.
[121] M. Corbetta and G. L. Shulman, “Control of goal-directed and
stimulus-driven attention in the brain,” Nat. Rev. Neurosci, vol. 3,
no. 3, pp. 201–215, 2002.
[122] X. Wang, R. Girshick, A. Gupta, and K. He, “Non-local neural
networks,” in CVPR, 2018, pp. 7794–7803.
[123] S. Woo, J. Park, J.-Y. Lee, and I. S. Kweon, “Cbam: Convolutional
block attention module,” in ECCV, 2018, pp. 3–19.
[124] J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,”
in CVPR, 2018, pp. 7132–7141.
[125] M. Jaderberg, K. Simonyan, A. Zisserman et al., “Spatial transformer networks,” in NeurIPS, 2015, pp. 2017–2025.
[126] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N.
Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”
in NeurIPS, 2017, pp. 6000–6010.
[127] C. Feng, Y. Zhong, Y. Gao, M. R. Scott, and W. Huang, “Tood:
Task-aligned one-stage object detection,” in ICCV, 2021, pp. 3490–
3499.
[128] Z. Huang, X. Wang, L. Huang, C. Huang, Y. Wei, and W. Liu, “Ccnet: Criss-cross attention for semantic segmentation,” in ICCV,
2019, pp. 603–612.
[129] J. Pang, C. Li, J. Shi, Z. Xu, and H. Feng, “R2
-cnn: Fast tiny
object detection in large-scale remote sensing images,” IEEE
Trans. Geosci. Remote Sens., vol. 57, no. 8, pp. 5512–5524, 2019.
[130] X. Yang, J. Yang, J. Yan, Y. Zhang, T. Zhang, Z. Guo, X. Sun, and
K. Fu, “Scrdet: Towards more robust detection for small, cluttered
and rotated objects,” in ICCV, 2019, pp. 8231–8240.
[131] J. Fu, X. Sun, Z. Wang, and K. Fu, “An anchor-free method based
on feature balancing and refinement network for multiscale ship
detection in sar images,” IEEE Trans. Geosci. Remote Sens., vol. 59,
no. 2, pp. 1331–1344, 2021.
[132] Y. Zhu, H. Cai, S. Zhang, C. Wang, and Y. Xiong, “Tinaface:
Strong but simple baseline for face detection,” arXiv preprint
arXiv:2011.13183, 2020.
[133] Z. Zheng, P. Wang, W. Liu, J. Li, R. Ye, and D. Ren, “Distance-iou
loss: Faster and better learning for bounding box regression,” in
AAAI, 2020, pp. 12 993–13 000.
[134] C. Xu, J. Wang, W. Yang, and L. Yu, “Dot distance for tiny object
detection in aerial images,” in CVPRW, 2021, pp. 1192–1201.
[135] J. Wang, C. Xu, W. Yang, and L. Yu, “A normalized gaussian
wasserstein distance for tiny object detection,” arXiv preprint
arXiv:2110.13389, 2021.
[136] F. Yang, H. Fan, P. Chu, E. Blasch, and H. Ling, “Clustered object
detection in aerial images,” in ICCV, 2019, pp. 8311–8320.
[137] C. Li, T. Yang, S. Zhu, C. Chen, and S. Guan, “Density map
guided object detection in aerial images,” in CVPRW, 2020, pp.
737–746.
[138] T. Song, L. Sun, D. Xie, H. Sun, and S. Pu, “Small-scale pedestrian
detection based on topological line localization and temporal
feature aggregation,” in ECCV, 2018, pp. 536–551.
[139] J. Wu, C. Zhou, Q. Zhang, M. Yang, and J. Yuan, “Self-mimic
learning for small-scale pedestrian detection,” in ACM MM, 2020,
pp. 2012–2020.
[140] J. U. Kim, S. Park, and Y. M. Ro, “Robust small-scale pedestrian
detection with cued recall via memory learning,” in ICCV, 2021,
pp. 3030–3039.
[141] G. Cheng, J. Wang, K. Li, X. Xie, C. Lang, Y. Yao, and J. Han,
“Anchor-free oriented proposal generator for object detection,”
IEEE Trans. Geosci. Remote Sens., vol. 60, pp. 1–11, 2022.
[142] Y. Pang, J. Cao, Y. Li, J. Xie, H. Sun, and J. Gong, “Tju-dhd: A
diverse high-resolution dataset for object detection,” TIP, vol. 30,
pp. 207–219, 2021.
[143] J. Han, X. Liang, H. Xu, K. Chen, L. Hong, J. Mao, C. Ye,
W. Zhang, Z. Li, X. Liang et al., “Soda10m: A large-scale 2d
self/semi-supervised object detection dataset for autonomous
driving,” arXiv preprint arXiv:2106.11118, 2021.
[144] M.-R. Hsieh, Y.-L. Lin, and W. H. Hsu, “Drone-based object
counting by spatially regularized regional proposal network,” in
ICCV, 2017, pp. 4165–4173.
[145] P. Zhu, L. Wen, D. Du, X. Bian, H. Fan, Q. Hu, and H. Ling,
“Detection and tracking meet drones challenge,” TPAMI, pp. 1–1,
2021.
[146] D.-P. Fan, G.-P. Ji, M.-M. Cheng, and L. Shao, “Concealed object
detection,” TPAMI, pp. 1–1, 2021.
[147] W. Wang, J. Shen, F. Guo, M.-M. Cheng, and A. Borji, “Revisiting
video saliency: A large-scale benchmark and a new model,” in
CVPR, 2018, pp. 4894–4903.
[148] H. Yu, G. Li, W. Zhang, Q. Huang, D. Du, Q. Tian, and N. Sebe,
“The unmanned aerial vehicle benchmark: Object detection,
tracking and baseline,” IJCV, vol. 128, no. 5, pp. 1141–1159, 2020.
[149] Z. Cai and N. Vasconcelos, “Cascade r-cnn: High quality object
detection and instance segmentation,” TPAMI, vol. 43, no. 5, pp.
1483–1498, 2021.
[150] D. Lam, R. Kuzma, K. McGee, S. Dooley, M. Laielli, M. Klaric,
Y. Bulatov, and B. McCord, “xview: Objects in context in overhead
imagery,” arXiv preprint arXiv:1802.07856, 2018.
[151] Z. Yang, S. Liu, H. Hu, L. Wang, and S. Lin, “Reppoints: Point
set representation for object detection,” in ICCV, 2019, pp. 9656–
9665.
[152] S. Zhang, C. Chi, Y. Yao, Z. Lei, and S. Z. Li, “Bridging the gap
between anchor-based and anchor-free detection via adaptive
training sample selection,” in CVPR, 2020, pp. 9759–9768.
[153] P. Sun, R. Zhang, Y. Jiang, T. Kong, C. Xu, W. Zhan, M. Tomizuka,
L. Li, Z. Yuan, C. Wang, and P. Luo, “Sparse r-cnn: End-to-end
object detection with learnable proposals,” in CVPR, 2021, pp.
14 449–14 458.
[154] K. Chen et al., “MMDetection: Open mmlab detection toolbox
and benchmark,” arXiv preprint arXiv:1906.07155, 2019.
[155] Y. Zhou et al., “Mmrotate: A rotated object detection benchmark
using pytorch,” arXiv preprint arXiv:2204.13317, 2022.
[156] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo,
“Swin transformer: Hierarchical vision transformer using shifted
windows,” in ICCV, 2021, pp. 9992–10 002.
[157] J. Ding, N. Xue, Y. Long, G.-S. Xia, and Q. Lu, “Learning roi
transformer for oriented object detection in aerial images,” in
CVPR, 2019, pp. 2844–2853.
[158] Y. Xu, M. Fu, Q. Wang, Y. Wang, K. Chen, G.-S. Xia, and
X. Bai, “Gliding vertex on the horizontal bounding box for multioriented object detection,” TPAMI, vol. 43, no. 4, pp. 1452–1459,
2021.
[159] X. Xie, G. Cheng, J. Wang, X. Yao, and J. Han, “Oriented r-cnn for
object detection,” in ICCV, 2021, pp. 3520–3529.
[160] J. Han, J. Ding, J. Li, and G.-S. Xia, “Align deep features for oriented object detection,” IEEE Trans. Geosci. Remote Sens., vol. 60,
pp. 1–11, 2022.
[161] G. Cheng, Y. Yao, S. Li, K. Li, X. Xie, J. Wang, X. Yao, and J. Han,
“Dual-aligned oriented detector,” IEEE Trans. Geosci. Remote Sens.,
vol. 60, pp. 1–11, 2022.