EMNLP 2022 | 预训练语言模型的时空效率优化

©PaperWeekly 原创 · 作者 | 申博文
单位 | 中国科学院信息工程研究所
研究方向 | 自然语言处理

论文标题:
COST-EFF: Collaborative Optimization of Spatial and Temporal Efficiency with Slenderized Multi-exit Language Models
收录会议:
EMNLP 2022
论文链接:
https://arxiv.org/abs/2210.15523
代码链接:
https://github.com/sbwww/cost-eff

动机
众多基于 Transformer 的预训练语言模型(Pre-trained Language Models,PLMs)不断刷新着各项任务的性能,却存在体积大、推断慢等效率问题。对于资源受限的设备和应用场景,需要一种在空间和时间上高效,且在任务推断上准确的模型。
为了得到这样的模型,现有一些研究对 PLM 进行静态压缩 [1]。然而,单纯地进行静态压缩难以得到一个合适的模型,因为压缩后的模型很可能对简单样本而言仍有冗余,对复杂样本而言能力不足。为了使模型意识到输入样本的复杂性差异,Xin et al [2],Liu et al [3] 等将 PLM 修改为多出口模型(即模型的多个部位都具有输出分类器),并使用动态提前退出方法进行推断加速。
我们发现,使用动态提前退出方法来加速小容量的压缩模型推断会造成较大的性能损失,其原因在于,多出口模型的浅层与深层在目标上存在不一致性。具体来说,浅层模块需兼顾做出预测和提取更深层所需的信息两个目标,而深层更多关注做出预测。这种不一致性在多出口模型中普遍存在,大容量模型有较好的能力缓解该问题,但小容量的压缩模型难以做出权衡。
为了解决上述问题,我们提出了 COST-EFF 来整合静态模型压缩和动态推断加速,实现空间和时间上的协同优化。具体来说,我们
1. 将 PLM 的宽度细化,而深度保持不变,保留模型提取深层知识的能力 [4]。同时,使用逐层的动态提前退出来减小模型深度带来的推断开销,根据样本复杂性动态地控制模型计算量,加速推理。
2.提出了一种联合训练方法,能够校正 PLM 的细化过程和压缩后的恢复训练过程,缓解在压缩的多出口模型上,浅层和深层目标不一致带来的权衡问题,提升协同优化模型的性能。

▲ 图1 COST-EFF示意图,Emb为嵌入层,Tfm为Transformer层,Clf指输出分类器

方法
COST-EFF 主要针对 Transformer 结构的预训练语言模型进行效率优化,优化方法包括:
1. 静态模型细化
词嵌入(Word embedding)矩阵的分解
多头自注意力(Multi-Head Attention,MHA)和前馈网络(Feed-Forward Network,FFN)的结构化剪枝
2. 动态推断加速
多出口网络的推断
多出口网络的训练
3. 联合训练流程
具体的,COST-EFF 结构和流程如下图所示,接下来将逐步介绍其细节。

▲ 图2 COST-EFF 结构(上半部分)和各部分对应的优化方法(下半部分)
2.1 静态模型细化
2.1.1 词嵌入矩阵的分解
由于默认的词表较大,BERT 的词嵌入矩阵有高于 23M(百万)的参数,占据模型约 1/5 的参数量。对词嵌入矩阵 的细化选用截断式奇异值分解(Truncated Singular Value Decomposition,TSVD),将 分解为两个小矩阵 和 的乘积形式,分解的具体过程如下:
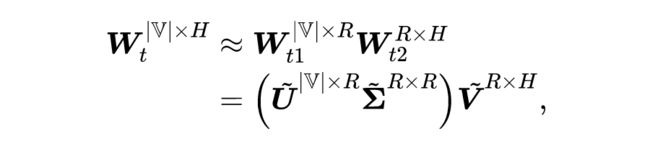
其中 为词表大小(BERT 默认为 30522), 为隐藏状态大小(BERT 默认为 768), 为 TSVD 分解的中间维度,也即图 2 中 和 间的红色维度。
2.1.2 MHA 和 FFN 的结构化剪枝
Transformer 结构的主要参数量在 MHA 和 FFN 中,剪枝是对其进行压缩的有效方式。剪枝可以分为结构化剪枝和非结构化剪枝。非结构化的剪枝以变换矩阵中的单个参数为粒度,可以实现更高的压缩率,但暂时还不能直接应用在通用计算设备上。因此,我们选择结构化剪枝,对 MHA 和 FFN 的剪枝粒度分别是注意力头和 FFN 中间维度。反映在变换矩阵上,则是将某些行或列丢弃,从而实现参数量和浮点数运算次数的减少。
以 BERT 为例,MHA 的默认设置为 12 个注意力头,每个注意力头的大小是 64,因此总计大小与隐藏状态大小相同,为 768。FFN 的中间维度为 3072,即隐藏维度 768 的 4 倍。
在 COST-EFF 的剪枝过程中,每个注意力头的大小保持不变,仅减少注意力头的个数。因此,MHA 中的变换矩阵 ,, 的输出维度和 的输入维度被压缩为 ;FFN 中的变换矩阵 的输出维度和 的输入维度被压缩为 。
在剪枝时,需要剪去的部分根据其重要性来确定。重要性可以定义为“剪去该部分后,模型的损失变化程度”,若损失变化不太大,则可以视为不甚重要。重要性的形式化表示如下:
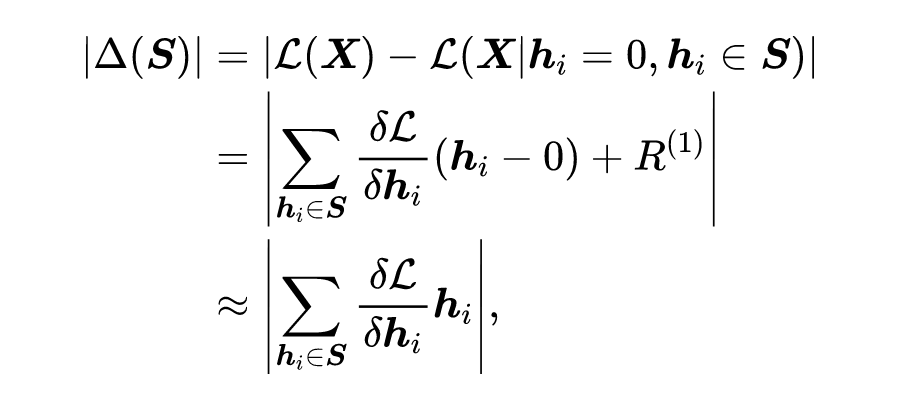
其中, 为剪去结构 后损失函数 的变化, 为损失函数对参数 的梯度, 为对 在 处一阶泰勒展开的余项。
2.2 动态推断加速
2.2.1 多出口网络的推断
多出口网络允许模型在足够置信的情况下提前退出并输出结果,对于较简单的输入样本,无需完整地通过整个模型。目前,提前退出的判断主要有基于熵 [2]、基于耐心 [5] 和基于学习的方法。基于学习的方法较为复杂且会引入额外开销,本文暂不使用。
根据 Liu et al [3] 的实验结果,基于熵的方法在多数任务上优于基于耐心的方法。因此,COST-EFF 选择基于熵的方法。具体地,每一层的分类器可以计算出分类概率的熵值 ,若 小于一给定阈值,即可视为置信度足够高,并提前退出模型计算。
2.2.2 多出口网络的训练
多出口网络与普通的单出口网络的区别在于,单出口网络的浅层部分只需提取更深层所需的信息,而多出口网络的浅层部分还具有做出预测的任务。因此,两者的训练方式也存在区别。
DeeBERT [2] 使用了两阶段的训练方法,即先单独训练模型主干,再训练各个出口分类器;PABEE [5] 将各个出口的损失按递增权重加权求和,并和模型主干一起训练;然而上述两种方法均不够理想,DeeBERT 冻结模型主干,仅对分类器单独训练很难达到理想性能,PABEE 为损失加权的方式对于浅层损失的重视程度不够。
Li et al [6] 提出一种梯度均衡方法,该方法于 2022 年应用在 ElasticBERT [3] 中,并被证实其在 PLM 上的正确性。梯度均衡不是对损失加权,而是在梯度反向传播时对梯度加权,其表示如下:
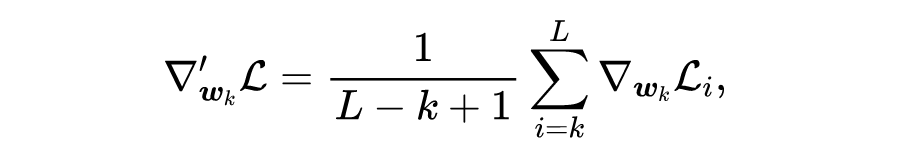
其中 是模型的层数, 是从第 层传播到第 层的原始梯度, 均衡后的梯度。
2.3 联合训练流程
除上述方法之外,更为重要的是如何将其整合,实现协同优化。
小容量的压缩模型很难只通过常规的精调恢复性能。而知识蒸馏可被用作一种补充,将知识从未压缩的教师模型转移到压缩后的学生模型。同时,由于多出口模型的浅层与深层间存在不一致性,且小容量的压缩模型难以权衡,简单地使用真实标签来训练压缩的多出口模型会导致显著的性能下降。
鉴于此,我们首先将原始模型蒸馏为一个多出口的 BERT 模型作为助教(Teaching Assistant,TA)模型。然后,将 TA 每一层出口分类器的输出概率分布作为 COST-EFF 中相应层的软标签,即有预测蒸馏损失:
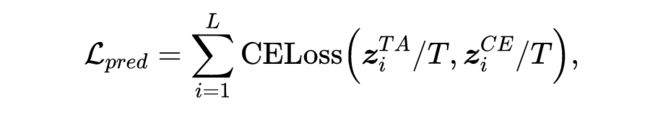
其中 和 分别是 TA 和 COST-EFF 在第 层的概率分布输出。 是温度系数,通常设置为 1。
为了有效地将 TA 学习到的语义表示转移到学生模型中,COST-EFF 还蒸馏模型的特征,即嵌入层和各层 Transformer 得到的隐藏状态。隐藏状态 ,包括嵌入输出 和每个 Transformer 层的输出,有如下的特征蒸馏损失:

COST-EFF 首先蒸馏普通的单出口模型,得到一个具有相同层数的多出口 TA 模型。这样的蒸馏可以兼容不同 PLM 的具体实现,同时也可以用一个较大较稳健的模型初步缓解了层间不一致性。然后,TA 模型被用作细化的模型主干和进一步知识蒸馏的教师模型。
在细化过程中,我们将多出口损失纳入结构重要性计算。多出口损失能够权衡结构对每个后续出口的贡献,而不是仅针对最后一层的贡献,以此来校正细化,避免加剧小容量模型中的层间不一致性。在细化之后进行恢复训练,即一个从 TA 到 COST-EFF 的逐层知识蒸馏,目标是最小化 和 的总和,这就缓解了细化的多出口模型上的真实标签训练的矛盾。

实验
3.1 实验设置
数据集:我们在 GLUE [7] 数据集中选择 SST-2、MRPC、QNLI 和 MNLI 进行实验

▲ 表1 数据集详情
对比方法:
不同大小的精调 BERT:BERT,BERT 和 BERT,这些 BERT 模型初始化自 Turc et al. [8] 公开的预训练模型
静态压缩模型:DistilBERT [9] 和 TinyBERT [1]
动态加速模型:DeeBERT [2],PABEE [5] 和 ElasticBERT [3]
模型设置:
由于参数量对性能有较大影响,我们设置了两个比较组,每组内的模型大小相似。
第一组中的模型参数较少,在 20M 以下,包括 BERT、TinyBERT、DeeBERT、PABEE 和 COST-EFF
第二组模型较大,参数在 50M 以上,包括 BERT、TinyBERT、DistilBERT、DeeBERT、PABEE和 COST-EFF。
模型的具体大小可参考下表,其中 为模型层数, 为隐藏状态大小, 为 MHA 大小(注意力头数 注意力头大小)、 为 FFN 中间维度大小,EE 表示是否使用动态提前退出
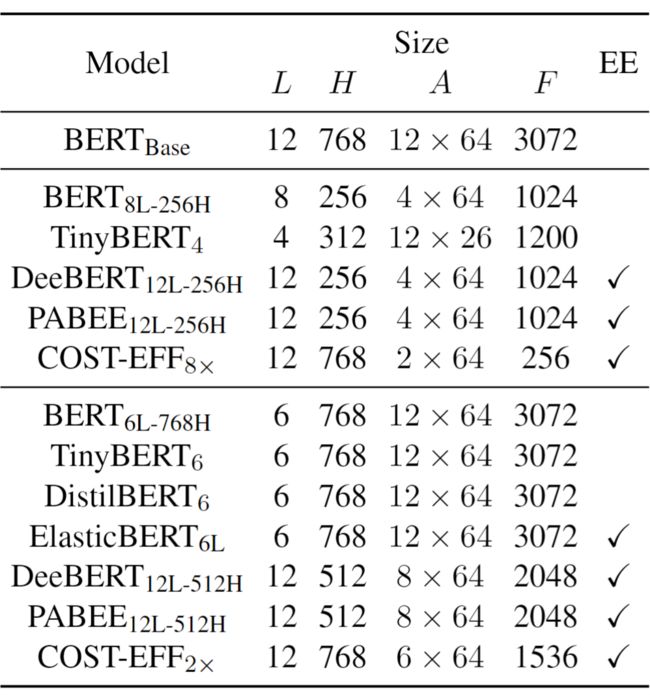
▲ 表2 模型设置
3.2 实验结果

▲ 图3 实验结果。加粗部分为最优效果,下划线部分为次优效果
在第一组中,模型被高度压缩和加速,COST-EFF的性能保持在大约 96.5%,远高于预训练+精调 BERT 或在压缩模型 BERT 上使用已有的动态提前退出方法。与强基准 TinyBERT 对比时,COST-EFF 在所有四个任务中都优于 TinyBERT,这表明细而深的模型优于宽而浅的模型。COST-EFF 的细化结构更有可能为困难的输入样本提取层级特征,同时利用动态提前退出迅速处理简单的输入样本。
对于较大的模型,具有 General Distillation(GD)[1] 过程的 TinyBERT比 COST-EFF 性能相近。同时,没有 GD 过程的 TinyBERT 在效率和性能上都被 COST-EFF 所支配,说明要想获得优于 COST-EFF 的 TinyBERT,必须经过 GD。
然而,GD 需要在规模庞大的语料上进行类似于预训练的过程,并且技能得到一个固定大小和计算量的模型。在计算量需求发生变化的情况下,TinyBERT 必须重新进行 GD,造成巨大的训练代价。与 TinyBERT 相比,COST-EFF 在性能和灵活推理方面都有优势。
为了证明动态推断加速的效果,我们根据经验从开发集中选择长度较短(低于长度中位数)的简单样本。简单样本上的结果显示了动态推断加速带来的改进,这在静态模型中是很难得到的。需要注意的是,长度较短并不总能表明样本的简单性。对于像 QNLI 这样的蕴含任务,较短的输入意味着较少的信息,可能会加剧语言模型的困惑。
此外,我们还绘制了 GLUE 分数-FLOPs 的性能曲线,如图 4 和 5 所示。性能曲线是二维的,显示了不同方法的帕累托最优性。为了关注计算量和性能都较小的模型,我们在图中用蓝色虚线绘制了帕累托前沿。

▲ 图4 第一组模型的性能曲线。水平虚线为 BERT 模型 95% 的性能,竖直虚线为 BERT 模型 5% 的运算量

▲ 图5 第二组模型的性能曲线。水平虚线为 BERT 模型 97% 的性能,竖直虚线为 BERT 模型 25% 的运算量
如图 4 和 5,COST-EFF 和 COST-EFF 的表现都超过了 DistilBERT、DeeBERT、PABEE 和 BERT 基线。与 TinyBERT 和 ElasticBERT 相比时,COST-EFF 通常是最优的。我们发现,使用多出口网络会降低 NLI 任务性能的上限,即 COST-EFF 和 ElasticBERT 在 QNLI 和 MNLI 任务上的最优性能均不如 TinyBERT。
这个问题可能源于 NLI 任务中的复杂样本依赖于高层语义,浅层应更多地为深层服务,而不是试图自己解决任务。然而,这个问题并不影响全局最优性,如图 4 所示,COST-EFF 在 QNLI 和 MNLI 上对 TinyBERT 的性能是非劣的。
在图 6 中,我们绘制了第一组模型的层级性能。与 DeeBERT 和 PABEE 相比,COST-EFF 实现了最优的性能。与 TinyBERT 相比,COST-EFF 可以在深层(第 7 层到第 12 层)取得更好的性能,进一步验证了我们的主张,即细而深的模型优于宽而浅的模型。
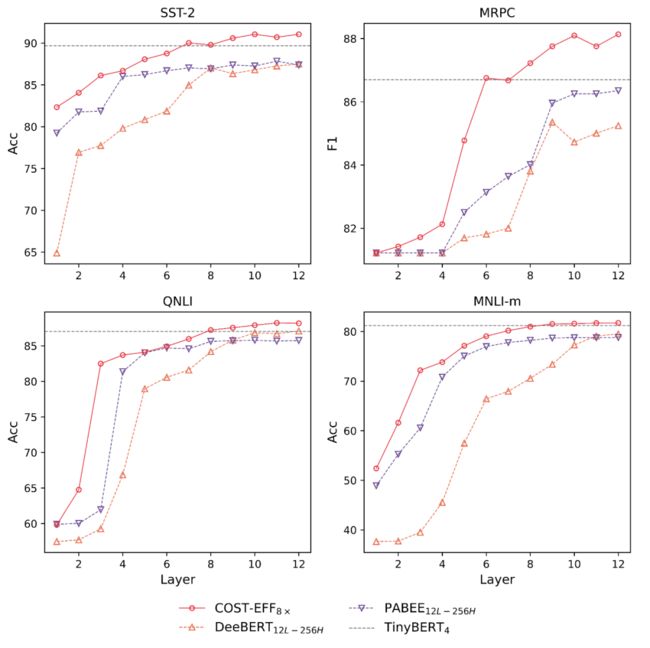
▲ 图6 第一组模型的层级性能。水平虚线为 TinyBERT 最后一层分类器的性能
3.3 消融实验
3.3.1 知识蒸馏的影响
蒸馏策略的消融实验旨在评估预测和特征蒸馏的有效性。在这项消融研究中,比较方法是:
消融特征蒸馏,仅使用预测蒸馏,即
使用真实标签代替预测蒸馏,即
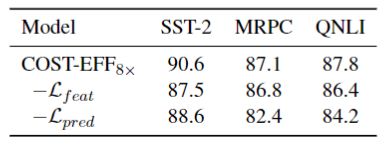
▲ 表3 蒸馏策略的消融实验结果
表 3 结果表明,这两个目标都很关键。由于对隐藏表征的模仿,COST-EFF 与没有特征蒸馏的训练相比,性能上有 1.6%的优势。如果没有预测蒸馏,性能下降超过 3.4%。先前的静态压缩工作,如 TinyBERT 和 CoFi,在 GLUE 任务中一般对预测蒸馏不敏感,因为单出口模型的输出分布一般与真实标签一致。然而,如果预测分布被消融,COST-EFF 的性能就会出现较大的下降。
这一结果表明,在浅层追求真实标签使深层的性能恶化。这种浅层和深层之间的不一致普遍存在于多出口模型中,在大容量模型中对性能影响较小,但尤其难以被小容量的压缩模型所权衡。因此,COST-EFF 引入了未压缩的 TA 模型来缓解浅层和深层的不一致,并通过预测蒸馏来转移 TA 模型学习到的权衡。
3.3.2 联合训练流程的影响
COST-EFF 中,我们提出了一种模型压缩和动态提前退出的联合训练方法,旨在校正浅层模块的细化,使其更能适应。为了验证训练流程的有效性,首先,我们像 DeeBERT 那样实现了两阶段的训练模式。此外,我们还在 COST-EFF 细化时消融了多出口损失。上述方法的逐层比较如图 7 所示。

▲ 图7 联合训练的消融实验结果。水平虚线为 TinyBERT 最后一层分类器的性能
直观地说,两阶段训练在最后一层比联合训练有优势,因为两阶段训练中没有将层间不一致性引入模型主干。然而,这种优势不存在于浅层中,使得两阶段训练的整体性能无法接受。与消融了多出口损失的细化方法相比,我们的方法有 1.1% 到 2.3% 的优势。
需要注意的是,消融了多出口损失的细化方法仍然可以达到与 COST-EFF 相似的浅层性能,这表明基于蒸馏的训练在恢复性能上是有效的。然而,消融了多出口损失的细化方法在深层表现出较差的性能,说明这种方法收到层间不一致性的影响,未能较好地做出权衡,证明了 COST-EFF 联合训练流程的有效性和必要性。

总结
本文提出了 COST-EFF,有效地结合了静态的模型细化和动态的推断加速,以实现高效地 PLM。特别地,我们提出了一种联合优化方法,使模型细化和推断加速互相增益。仅细化模型而不减少模型深度,使基于动态提前退出的推断加速能够更好地处理复杂输入,而不为简单输入引来额外开销。同时,动态提前退出引入的多出口损失也可以校正模型细化过程,进一步提高压缩模型的性能。GLUE 数据集上的实验证明了本文方法的有效性和高效性。
本文的方法还存在以下的优化方向。
1. 在动态提前退出模型的推断过程中,一般将批次大小设置为 1,以便根据单个输入样本调整计算。然而,较大的批次大小会减少实际运算时间,但一个批次内的输入样本复杂度可能会有很大的不同。可以考虑将具有相似期望复杂度的样本收集到一个批次中,同时控制具有不同复杂度的批次的优先级以实现并行性。
2. 遵循现有的基线方法 TinyBERT 和 ElasticBERT,我们选择自然语言理解任务来研究压缩和加速。然而,COST-EFF 的可扩展性还有待在自然语言生成、翻译等复杂任务上探索。目前,静态模型压缩已被证明在复杂的任务中是有效的 [10],我们正在尝试在其他任务上,使用具有迭代过程的模型(如 Transformer 的多层迭代)进行动态推理加速。

参考文献
[1] [jiao2020tinybert]: Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. 2020. TinyBERT: Distilling BERT for natural language understanding. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 4163–4174, Online. Association for Computational Linguistics.
[2] [xin2020deebert]: Ji Xin, Raphael Tang, Jaejun Lee, Yaoliang Yu, and Jimmy Lin. 2020. DeeBERT: Dynamic early exiting for accelerating BERT inference. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 2246–2251, Online. Association for Computational Linguistics.
[3] [liu2022towards]: Xiangyang Liu, Tianxiang Sun, Junliang He, Jiawen Wu, Lingling Wu, Xinyu Zhang, Hao Jiang, Zhao Cao, Xuanjing Huang, and Xipeng Qiu. 2022. Towards efficient NLP: A standard evaluation and a strong baseline. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3288–3303, Seattle, United States. Association for Computational Linguistics.
[4] [bengio2007scaling]: Yoshua Bengio, Yann LeCun, et al. 2007. Scaling learning algorithms towards ai. Large-scale kernel machines, 34(5):1–41.
[5] [zhou2020bert]: Wangchunshu Zhou, Canwen Xu, Tao Ge, Julian McAuley, Ke Xu, and Furu Wei. 2020. Bert loses patience: Fast and robust inference with early exit. Advances in Neural Information Processing Systems, 33:18330–18341.
[6] [li2019improved]: Hao Li, Hong Zhang, Xiaojuan Qi, Ruigang Yang, and Gao Huang. 2019. Improved techniques for training adaptive deep networks. In 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019, pages 1891–1900. IEEE.
[7] [wang2018glue]: Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2019. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net.
[8] [turc2019well]: Iulia Turc, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Well-read students learn better: The impact of student initialization on knowledge distillation. CoRR, abs/1908.08962.
[9] [sanh2019distilbert]: Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2020. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv:1910.01108 [cs]. ArXiv: 1910.01108.
[10] [gupta2022compression]: Manish Gupta and Puneet Agrawal. 2022. Compression of deep learning models for text: A survey. ACM Transactions on Knowledge Discovery from Data (TKDD), 16(4):1–55.
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·
