mooc_python数据分析及展示笔记_numpy|pandas|matplotlib基本使用
本文是在观看mooc课堂上的python数据分析展示课堂上记录的笔记,可供学习参考。
1、numpy基础
numpy数组的创建与变换
一维数据:由对等关系的有序或无序数据构成,采用线性方式组织。 例如:列表和集合
数组:数据类型是相同的。
二维数据:由多个一维数据构成,是一维数据的组合形式。 例如:列表嵌套列表
高维数据:仅利用最基本的二元关系展示数据间的复杂结构。 例如:json的键值对数据结构,字典类型。xml,yaml
-
数组的创建方法
1. 从python的列表、元组以及二者混合类型创建 np.array([xxx]) 2. 使用numpy的函数创建ndarray数组 np.arange(n) :类似range()函数,返回ndarray类型,元素从0到n-1 np.ones(shape) :生成一个全1的数组,shape是一个元组类型 np.zeros(shape) :根据shape生成一个全0数组,shape是元组类型 np.full(shape,val) :根据shape生成一个数组,每个元素都是val np.eye(n) :创建一个正方的n*n的单位矩阵,对角线为1,其余为0
import numpy as np
np.arange(20)
》》》array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19])
np.full((5,5),6) #生成5行5列全为6,整数型
》》》array([[6, 6, 6, 6, 6],
[6, 6, 6, 6, 6],
[6, 6, 6, 6, 6],
[6, 6, 6, 6, 6],
[6, 6, 6, 6, 6]])
np.ones((5,5)) #生成的是浮点型
》》》array([[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]])
np.zeros((5,5))#生成的是浮点型
》》》array([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])
#生成单位矩阵
np.eye(5)#生成的是浮点型
》》》array([[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1.]])
指定数据类型dtype = np.int32
np.empty([2,3])
》》》array([[0., 0., 0.],
[0., 0., 0.]])
np.eye(5,dtype = np.int32)#生成的是整数型
》》》array([[1, 0, 0, 0, 0],
[0, 1, 0, 0, 0],
[0, 0, 1, 0, 0],
[0, 0, 0, 1, 0],
[0, 0, 0, 0, 1]])
也可以生成多维数组
np.ones((2,3,4))
》》》array([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]])
生成等差数列
np.linspace(1,50,endpoint = True)# endpoint是指终止值包含
》》》array([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12., 13.,
14., 15., 16., 17., 18., 19., 20., 21., 22., 23., 24., 25., 26.,
27., 28., 29., 30., 31., 32., 33., 34., 35., 36., 37., 38., 39.,
40., 41., 42., 43., 44., 45., 46., 47., 48., 49., 50.])
#等比数列
np.logspace(1,100)
》》》array([1.00000000e+001, 1.04811313e+003, 1.09854114e+005, 1.15139540e+007,
1.20679264e+009, 1.26485522e+011, 1.32571137e+013, 1.38949549e+015,
1.45634848e+017, 1.52641797e+019, 1.59985872e+021, 1.67683294e+023,
1.75751062e+025, 1.84206997e+027, 1.93069773e+029, 2.02358965e+031,
2.12095089e+033, 2.22299648e+035, 2.32995181e+037, 2.44205309e+039,
2.55954792e+041, 2.68269580e+043, 2.81176870e+045, 2.94705170e+047,
3.08884360e+049, 3.23745754e+051, 3.39322177e+053, 3.55648031e+055,
3.72759372e+057, 3.90693994e+059, 4.09491506e+061, 4.29193426e+063,
4.49843267e+065, 4.71486636e+067, 4.94171336e+069, 5.17947468e+071,
5.42867544e+073, 5.68986603e+075, 5.96362332e+077, 6.25055193e+079,
6.55128557e+081, 6.86648845e+083, 7.19685673e+085, 7.54312006e+087,
7.90604321e+089, 8.28642773e+091, 8.68511374e+093, 9.10298178e+095,
9.54095476e+097, 1.00000000e+100])```
```python
#创建一个数值范围在0到1的随机数
#权重初始化方式
r = np.random.random([3,3])
print(r)
》》》array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19])
"""
numpy.random.rand(d0,d1,…,dn)
rand函数根据给定维度生成[0,1)之间的数据,包含0,不包含1
dn表格每个维度
返回值为指定维度的array
numpy.random.randn(d0,d1,…,dn)
randn函数返回一个或一组样本,具有标准正态分布。
dn表格每个维度
返回值为指定维度的array"""
#随机值是按照标准正态分布创建的
np.random.seed(0)
r = np.random.randn(3,3)
r = np.random.randn(3,3)
# print(help(np.random.rand)) #查看帮助
print(r)
》》》 [[ 0.4105985 0.14404357 1.45427351]
[ 0.76103773 0.12167502 0.44386323]
[ 0.33367433 1.49407907 -0.20515826]]
函数创建数组
1. np.ones_like(a) :根据数组a的形状生成一个全1数组
2. np.zeros_like(a) :根据数组a的形状生成一个全0数组
3. np.full_like(a,val) :根据数组a的形状生成一个数组,每个元素值都是val
4. np.linspace() :根据起止数据等间距地填充数据,形成数组
5. np.concatenate() :将两个或多个数组合并成一个新的数组
数组的维度变换
1. .reshape() :不改变数组元素,返回一个shape形状的数组,原数组不变
2. .resize() :与.reshape()功能一致,但修改原数组
3. .swapaxes(ax1,ax2) :将数组n各维度中两个维度进行调换
4. .flatten() :对数组进行降维,返回折叠后的一维数组,原数组不变
a = np.ones((2,3,4))
a
》》》array([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]])
a.reshape((3,8)) #不改变原数组,会返回一个新的,而resize会更改原数组
b = a.flatten()
b
ndarray 数组的类型转换
new_a = a.astype(new_type)
astype一定会创建新的数组(原始数组的一个拷贝),即使两个类型一致
a = np.ones((2,3,4),dtype = np.int)
a
b = a.astype(np.float)
b
数组向列表的转换
ls = a.tolist()
a = np.full((2,3,4),25,dtype = np.int32)
a
a.tolist()
对数组的操作
1. 索引:获取数组中特定位置元素的过程
1. 一维数组的索引和切片与python类似
2. 切片:获取数组元素子集的过程
# 一维数组索引
a = np.array([9,8,7,6,5])
a[2]
#一维数组切片
a[ 1 : 4 : 2] #1是起始,4是终止,2是步长
np.random的统计函数
1. sum(a,axis = none) :根据给定轴axis计算数组a相关元素之和,axis整数或元组
2. mean(a.axis = none) :根据给定轴axis计算数组a相关元素的期望,axis整数或元组
3. average(a.axis = None,weights = None) :根据给定轴axis计算数组a相关元素的加权平均值
4. std(a,axis = None) :根据给定轴axis计算数组a相关元素的标准差
5. var(a.axis = None) :根据给定轴axis计算数组a相关元素方差
import numpy as np
a = np.arange(15).reshape(3,5)
a
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
# sum,对基本元素进行求和运算
np.sum(a)
105
#mean,对数组而言,最外层的维度是0,内层的维度是1,axis = 1,表示的是对数组的第二维度进行平均数计算
np.mean(a,axis = 1) #对同一行各列计算
np.mean(a,axis = 0) #对第一维度,同一列各行计算
array([5., 6., 7., 8., 9.])
#average
np.average(a,axis = 0,weights = [10,5,1]) #4.1875 = 2*10 + 7*5 + 12*1/(10+5+1)
array([2.1875, 3.1875, 4.1875, 5.1875, 6.1875])
#std
np.std(a)
4.320493798938574
#var
np.var(a)
18.666666666666668
np.random的统计函数1
1. min(a)\max(a) :计算数组a中元素的最小值和最大值
2. argmin(a)\argmax(a) :计算数组a中元素的最小值和最大值的降一维后下标
3. unravel_index(index,shape) :根据shape将一维下标index转换成多维下标
4. ptp(a) :计算数组a中元素的最大值和最小值的差
5. median(a) :计算数组a中元素的中位数
import numpy as np
a = np.arange(15,0,-1).reshape(3,5)
a
array([[15, 14, 13, 12, 11],
[10, 9, 8, 7, 6],
[ 5, 4, 3, 2, 1]])
#max
np.max(a)
15
#argmax
np.argmax(a) #扁平化下标
0
#unravel_index
np.unravel_index(np.argmax(a),a.shape) #重塑成多为下标
(0, 0)
# ptp
np.ptp(a)
14
# median
np.median(a)
8.0
np.random的梯度函数
1. np.gradient(f) :计算数组f中的元素的梯度,当f为多维时,返回每个维度梯度
梯度:连续值之间的变化率,即斜率
XY坐标轴连续三个X坐标对应的Y轴值为:a,b,c,其中,b的梯度是:(c-a)/2
斜率是表示一条直线(或曲线的切线)关于(横)坐标轴倾斜程度的量。它通常用直线(或曲线的切线)与(横)坐标轴夹角的正切,或两点的纵坐标之差与横坐标之差的比来表示
import numpy as np
a = np.random.randint(0,20,(5))
a
array([15, 9, 6, 8, 14])
np.gradient(a) #第二个元素的梯度值 = (第三个元素-第一个元素)/2 ##最后一个元素的梯度值 = (自身 -前一个元素)/1
array([-6. , -4.5, -0.5, 4. , 6. ])
b = np.random.randint(0,20,(5))
b
array([ 5, 5, 16, 2, 15])
np.gradient(b)
array([ 0. , 5.5, -1.5, -0.5, 13. ])
a = np.random.randint(0,50,(3,5))
a
array([[19, 25, 29, 35, 10],
[ 6, 49, 21, 21, 29],
[23, 1, 20, 29, 45]])
np.gradient(a)
#会返回两个数组结果,第一个是最外层维度的梯度,其次是第二层维度的梯度
#梯度反映了数据的变化率,在进行图像处理声音处理的时候可以发挥很大的作用
[array([[-13. , 24. , -8. , -14. , 19. ],
[ 2. , -12. , -4.5, -3. , 17.5],
[ 17. , -48. , -1. , 8. , 16. ]]),
array([[ 6. , 5. , 5. , -9.5, -25. ],
[ 43. , 7.5, -14. , 4. , 8. ],
[-22. , -1.5, 14. , 12.5, 16. ]])]
a = np.random.randint(0,50,(3,3,5))
a
array([[[11, 21, 32, 34, 37],
[45, 18, 21, 8, 15],
[19, 18, 4, 9, 3]],
[[18, 14, 2, 47, 27],
[ 9, 38, 4, 7, 22],
[12, 22, 3, 48, 9]],
[[10, 2, 36, 35, 33],
[19, 2, 2, 39, 41],
[ 1, 29, 24, 15, 33]]])
np.gradient(a)
[array([[[ 7. , -7. , -30. , 13. , -10. ],
[-36. , 20. , -17. , -1. , 7. ],
[ -7. , 4. , -1. , 39. , 6. ]],
[[ -0.5, -9.5, 2. , 0.5, -2. ],
[-13. , -8. , -9.5, 15.5, 13. ],
[ -9. , 5.5, 10. , 3. , 15. ]],
[[ -8. , -12. , 34. , -12. , 6. ],
[ 10. , -36. , -2. , 32. , 19. ],
[-11. , 7. , 21. , -33. , 24. ]]]),
array([[[ 34. , -3. , -11. , -26. , -22. ],
[ 4. , -1.5, -14. , -12.5, -17. ],
[-26. , 0. , -17. , 1. , -12. ]],
[[ -9. , 24. , 2. , -40. , -5. ],
[ -3. , 4. , 0.5, 0.5, -9. ],
[ 3. , -16. , -1. , 41. , -13. ]],
[[ 9. , 0. , -34. , 4. , 8. ],
[ -4.5, 13.5, -6. , -10. , 0. ],
[-18. , 27. , 22. , -24. , -8. ]]]),
array([[[ 10. , 10.5, 6.5, 2.5, 3. ],
[-27. , -12. , -5. , -3. , 7. ],
[ -1. , -7.5, -4.5, -0.5, -6. ]],
[[ -4. , -8. , 16.5, 12.5, -20. ],
[ 29. , -2.5, -15.5, 9. , 15. ],
[ 10. , -4.5, 13. , 3. , -39. ]],
[[ -8. , 13. , 16.5, -1.5, -2. ],
[-17. , -8.5, 18.5, 19.5, 2. ],
[ 28. , 11.5, -7. , 4.5, 18. ]]])]
图像的数组表示
1. 由RGB色彩模式,取值范围是0-255
2. 处理图像的库:PIL;python image library
a. import PIL
b. pip install pillow
c. from PIL import Image:一个图像代表一个image的实例
3. 图像是一个由像素组成的二维矩阵,每个像素都是一个RGB值
from PIL import Image as image
import numpy as np
im = np.array(image.open("D:/pick/20170211061910157.jpg"))
print(im.shape,im.dtype)
#图像时一个三维数组,维度分别是高度,宽度和像素RGB值,而在第三维度RGB上有三个元素,分别由uint8类型表示
(660, 990, 3) uint8
# print(im)
图像的变换
1. 读入图像后,获得像素的RGB值,修改后保存为新的文件
from PIL import Image as image
import numpy as np
im = np.array(image.open("D:/pick/20170211061910157.jpg")) #将图像变成数组
print(im.shape,im.dtype)
b = [255,255,255] -im
n_im = image.fromarray(b.astype('uint8')) #将数组b重新生成一个图像
n_im.save("D:/pick/2020-03-31.jpg") #保存
(660, 990, 3) uint8
灰度处理
from PIL import Image as image
import numpy as np
im = np.array(image.open("D:/pick/20170211061910157.jpg").convert("L")) #将图像变成数组.convert("L")是指将图像变成一个灰度图像,生成的数组不再是三维,而是二维的,像素中的值对应的不再是RGB的值,而是灰度值
print(im.shape,im.dtype)
b = 255 -im
n_im = image.fromarray(b.astype('uint8')) #将数组b重新生成一个图像
n_im.save("D:/pick/2020-03-31-1.jpg") #保存
(660, 990) uint8
from PIL import Image as image
import numpy as np
im = np.array(image.open("D:/pick/20170211061910157.jpg").convert("L")) #将图像变成数组.convert("L")是指将图像变成一个灰度图像,生成的数组不再是三维,而是二维的,像素中的值对应的不再是RGB的值,而是灰度值
print(im.shape,im.dtype)
b = (100/255)*im + 150 #区间变换
n_im = image.fromarray(b.astype('uint8')) #将数组b重新生成一个图像
n_im.save("D:/pick/2020-03-31-2.jpg") #保存
(660, 990) uint8
from PIL import Image as image
import numpy as np
im = np.array(image.open("D:/pick/20170211061910157.jpg").convert("L")) #将图像变成数组.convert("L")是指将图像变成一个灰度图像,生成的数组不再是三维,而是二维的,像素中的值对应的不再是RGB的值,而是灰度值
print(im.shape,im.dtype)
b = 255 * (im/255)**2 #像素平方
n_im = image.fromarray(b.astype('uint8')) #将数组b重新生成一个图像
n_im.save("D:/pick/2020-03-31-3.jpg") #保存
(660, 990) uint8
图像的手绘效果
1. 黑白灰色系
2. 边界线条较重
3. 相同或相近色彩趋于白色
4. 略有光源效果
1. 利用像素之间的梯度值和虚拟深度值对图像进行重构,根据灰度变化来模拟人类视觉的明暗晨读
import numpy as np
from PIL import Image as image
a = np.array(image.open("D:/pick/20170211061910157.jpg").convert("L")).astype("float")
depth = 10. #预设虚拟深度为10 ,取值范围时(0-100)
grad = np.gradient(a) #取图像灰度的梯度值,梯度值时表示的灰度的变化率,通过改变梯度值来间接改变图像的明暗程度
grad_x,grad_y = grad #分别取横x纵y图像梯度值
grad_x = grad_x *depth/100
grad_y = grad_y *depth/100 #根据深度调整x和y方向的梯度值,立体效果通过增加虚拟深度值来实现
A = np.sqrt(grad_x **2 + grad_y **2 +1.)
uni_x = grad_x/A
uni_y = grad_y/A
uni_z = 1./A
vec_el = np.pi/2.2 #光源的俯视角度,弧度值
vec_az = np.pi/4. #光源的方位角度,弧度值
dx = np.cos(vec_el)*np.cos(vec_az) #光源对x轴的影响
dy = np.cos(vec_el)*np.sin(vec_az) #光源对y轴的影响
dz = np.sin(vec_el) #光源对z轴的影响
b = 255 *(dx*uni_x + dy*uni_y +dz*uni_z) #光源归一化
b = b.clip(0,255)
im = image.fromarray(b.astype("uint8")) #重构图像
im.save("D:/pick/2020-03-31-4.jpg")
Matplotlib库的使用
1. matplotlib.pyplot是绘制各类可视化图形的命令子库,相当于快捷方式
2. from matplotlib.pyplot as plt
简单的折线图绘制及保存
# 简单的折线绘制1
import matplotlib.pyplot as plt
plt.plot([3,1,4,2,5]) #只有一行时,会被当作y轴,x轴是索引
plt.ylabel("grade")
plt.savefig("D:/pick/test",dpi = 600) #png文件,dpi是指每英寸里包含点的数量,600相对较高了,png是默认
plt.show()

# 简单的折线绘制2
import matplotlib.pyplot as plt
plt.plot([1,3,5,6,9],[5,8,3,12,21])
plt.xlabel("xaxis")
plt.ylabel("yaxis")
plt.subplot(3,3,4)
plt.show()

设定x轴和y轴的距离间隔
plt.axis([-1,10,0,6]) #表示 x轴起始于 -1到10,y轴起始于1到6
[-1, 10, 0, 6]

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QltBwujf-1585829729732)(output_69_1.png)]
多张图表绘制在一起
plt.subplot(nrows,ncols,plot_number)
在全局绘图区域中创建一个子分区体系,并定位到一个子绘图区域
plt.subplot(324)表示三行两列,当前图形在第4个子区域,也就是第二行第二列
import numpy as np
import matplotlib.pyplot as plt
def f(t): #能量衰减曲线
return np.exp(-t) * np.cos(2*np.pi*t)
a = np.arange(0.0,5.0,0.02)
plt.subplot(211)
plt.plot(a,f(a))
plt.subplot(2,1,2)
plt.plot(a, np.cos(2*np.pi*a),'r--')
plt.show()

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HRhqkm2w-1585829729732)(output_71_0.png)]
pyplot的plot函数 绘制多条曲线
plt.plot(x,y, format_string, **kwargs)
x: x轴数据,可以是列表或数组,可选
y:y轴数据,可以是列表或数组。
format_string: 控制曲线的格式字符串,可选
**kwargs:第二组或更多(x,y,formatz_string,**kwargs)
多条曲线绘制时,必须给出x
import matplotlib.pyplot as plt
import numpy as np
a = np.arange(10)
plt.plot(a,a*1.5,a,a*2.5,a,a*3.5,a,a*4.5,a,a*5.5,a,a*6.5,a,a*7.5,a,a*8.5,a,a*9.5,a,a*10.5,a,a*13.5,a,a*14.5,a,a*15.5,a,a*16.5,a,a*17.5,a,a*18.5)
plt.show()

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VskHMlFD-1585829729733)(output_73_0.png)]
format_string:控制曲线的的格式字符串,有颜色字符和风格字符以及标记字符组成
颜色字符: 线条: 数据点标记包括字符:.,<>^hH+xDd|sp*以及数字1234
'b' 蓝色 "-" 实线
'g' 绿色 "--" 破折线
'r' 红色 "-." 点划线
'e' 青色 ":" 虚线
'm' 洋红色 "" 无线条
'y' 黄色
'k' 黑色
0.8 灰度值字符串
”#008000“ RGB某颜色\
其他参数:
color:控制颜色,color = "green" 等价于 'g'
linestyle:控制线条 ,linestyle = "dashed"
marker:标记风格,marker = "o"
markerfacecolor :标记颜色,markerfacecolor = "blue"
markersize:标记尺寸,markersize = 20
import matplotlib.pyplot as plt
import numpy as np
a = np.arange(10)
plt.plot(a,a*1.5,"go-",a,a*2.5,"rH-",a,a*3.5,"b*:",a,a*4.5,"kd",a,a*5.5)
plt.show()

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0jemYswV-1585829729733)(output_75_0.png)]
py.plot默认的不支持中文显示
需要引入matploylib来修改字体
import matplotlib
matplotlib.rcParams["font.family"] = "SimHei" ;该属性是控制字体风格,将其卸载绘图的第一行
"font.family" :用于显示的字体的名字
"font.style": 字体风格,正常normal或者斜体italic
"font.size" :字体大小,整数字号,或者large x-small
#会改变所有的文本配置,不建议使用
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mat
def f(t): #能量衰减曲线
return np.exp(-t) * np.cos(2*np.pi*t)
mat.rcParams["font.family"]='STSong' #此类设置会改变所有的文本配置
mat.rcParams['font.size']=15
a = np.arange(0.0,5.0,0.02)
plt.subplot(211)
plt.xlabel("横轴:时间")
plt.ylabel("纵轴:振幅")
plt.plot(a,f(a))
plt.show()

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0yxkUwWc-1585829729734)(output_77_0.png)]
import numpy as np
import matplotlib.pyplot as plt
def f(t): #能量衰减曲线
return np.exp(-t) * np.cos(2*np.pi*t)
a = np.arange(0.0,5.0,0.02)
plt.xlabel("横轴:时间",fontproperties = "SimHei",fontsize = 15)
plt.ylabel("纵轴:振幅",fontproperties = "SimHei",fontsize = 15)
plt.plot(a,f(a))
[]

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qDPJnzmS-1585829729735)(output_78_1.png)]
pyplot的文本显示方法
1. plt.xlabel():对x轴增加文本标签
2. plt.ylabel():对y轴增加文本标签
3. plt.title():对图形整体增加文本标签
4. plt.text() :在任意位置增加文本
5. plt.annotate(s,xy=arrow_crd,xytext=text_crd,arrowprops=dict) :图形中增加带箭头的注解
正弦波实例
import numpy as np
import matplotlib.pyplot as plt
#绘图
a = np.arange(0.0,5.0,0.02)
plt.plot(a,np.cos(2*np.pi*a),"g--")
#调参
plt.xlabel("横轴:时间",fontproperties = "SimHei",fontsize = 15)
plt.ylabel("纵轴:振幅",fontproperties = "SimHei",fontsize = 15)
plt.title(r'正弦波实例 $y=cos(2\pi x)$',fontsize = 25,fontproperties = "SimHei")
plt.text(2,1,r'$\mu=100$',fontsize = 16)
plt.axis([-1,6,-2,2])
plt.grid(True)
plt.show()

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5RI3Rrro-1585829729735)(output_81_0.png)]
import numpy as np
import matplotlib.pyplot as plt
#绘图
a = np.arange(0.0,5.0,0.02)
plt.plot(a,np.cos(2*np.pi*a),"g--")
#调参
plt.xlabel("横轴:时间",fontproperties = "SimHei",fontsize = 15)
plt.ylabel("纵轴:振幅",fontproperties = "SimHei",fontsize = 15)
plt.title(r'正弦波实例 $y=cos(2\pi x)$',fontsize = 25,fontproperties = "SimHei")
plt.annotate(r'$\mu=100$',xy = (2,1),xytext = (3,1.5),
arrowprops = dict(facecolor = 'black',shrink = 0.1,width = 2))
plt.axis([-1,6,-2,2])
plt.grid(True)
plt.show()

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qWDIIeJA-1585829729736)(output_82_0.png)]
import numpy as np
from PIL import Image as image
a = image.open("D:/pick/20170211061910157.jpg")
a.show()
多图形绘制
1. plt.subplot2grid(GridSpec,CurSpec,colspan=1,rowspan=1)
理念:设定网格;选中网格,确定选中行列区域数量,编号从0开始
plt.subplot2grid((3,3),(1,0),colspan=2)
表示:总共为三行三列,其中选中在第二行和第一列开始,长度为3
但是每次都要对图形进行约束
2. GridSpec类
import matplotlib.gridspec as gridspec
gs = gridspec.GridSpec(3,3) # 总个数为三行三列
ax1 = plt.subplot(gs[0,:]) #表示(第一行)的(所有列)为一个图形区域
ax2 = plt.subplot(gs[1,:-1]) #表示(第二行)的(所有列但不包括最后一列)为一个图形区域
ax3 = plt.subplot(gs[1:,-1]) #表示(包括第二行之后的所有行)和(倒数第一列)的区域为一个图形区域
ax4 = plt.subplot(gs[2,0]) #表示第三行和第一列的区域为一个图形区域
ax5 = plt.subplot(gs[2,1]) #表示第三行和第二列的区域为一个图形区域
理解数据对应的含义以及展示这种含义的图形方法是很关键的。
基础图形绘制
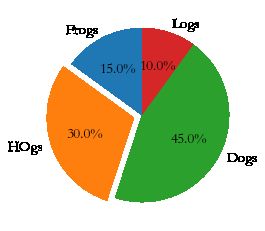
#饼图
import matplotlib.pyplot as plt
labels = "Frogs","HOgs","Dogs","Logs" #数据标签,与数据源顺序对应
sizes = [15,30,45,10] #数据源
explode = (0,0.1,0,0) #向外延申的比例,与数据源对应
plt.pie(sizes,explode = explode,labels = labels,autopct = "%1.1f%%",
shadow = False,startangle=90)
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fy2Ft4vk-1585829729736)(output_87_0.png)]
#饼图
import matplotlib.pyplot as plt
labels = "Frogs","HOgs","Dogs","Logs" #数据标签,与数据源顺序对应
sizes = [15,30,45,10] #数据源
explode = (0,0.1,0,0) #向外延申的比例,与数据源对应
plt.pie(sizes,explode = explode,labels = labels,autopct = "%1.1f%%",
shadow = False,startangle=90)
plt.axis("equal")
plt.show()

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Dys8dIUg-1585829729737)(output_88_0.png)]
#直方图
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0)
mu, sigma = 100,20 #均值和方差
a = np.random.normal(mu,sigma,size=100)
plt.hist(a,20,normed=0,histtype="stepfilled",facecolor = 'b',alpha = 0.75) #第二个参数(bin)是指直方图的个数;noemed=1是指将元素出现的频率,为0是指出现的个数
plt.title("Histogram")
plt.show()
C:\ProgramData\Anaconda3\lib\site-packages\ipykernel_launcher.py:8: MatplotlibDeprecationWarning:
The 'normed' kwarg was deprecated in Matplotlib 2.1 and will be removed in 3.1. Use 'density' instead.

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-grDBv66y-1585829729737)(output_89_1.png)]
#直方图
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0)
mu, sigma = 100,20
a = np.random.normal(mu,sigma,size=100)
plt.hist(a,40,normed=1,histtype="stepfilled",facecolor = 'b',alpha = 0.75)
plt.title("Histogram")
plt.show()
C:\ProgramData\Anaconda3\lib\site-packages\ipykernel_launcher.py:8: MatplotlibDeprecationWarning:
The 'normed' kwarg was deprecated in Matplotlib 2.1 and will be removed in 3.1. Use 'density' instead.

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8HgDpmXm-1585829729738)(output_90_1.png)]
#直方图
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(0)
mu, sigma = 100,20
a = np.random.normal(mu,sigma,size=100)
plt.hist(a,10,normed=1,histtype="stepfilled",facecolor = 'b',alpha = 0.75)
plt.title("Histogram")
plt.show()
C:\ProgramData\Anaconda3\lib\site-packages\ipykernel_launcher.py:8: MatplotlibDeprecationWarning:
The 'normed' kwarg was deprecated in Matplotlib 2.1 and will be removed in 3.1. Use 'density' instead.

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fTN9YP0L-1585829729738)(output_91_1.png)]
面向对象绘制极坐标
import numpy as np
import matplotlib.pyplot as plt
N = 20 #绘制坐标中数据的个数
theta = np.linspace(0.0,2*np.pi,N , endpoint = False)#从0到2pi也就是360°,分成20个不同的角度
radii = 10 * np.random.rand(N) #生成数值
width = np.pi / 4 * np.random.rand(N)
ax = plt.subplot(111,projection = "polar")
bars = ax.bar(theta, radii, width = width,bottom = 0.0) #参数对应 left,height,width
for i ,bar in zip(radii,bars):
bar.set_facecolor(plt.cm.viridis(i /10.))
bar.set_alpha(0.5)
plt.show()
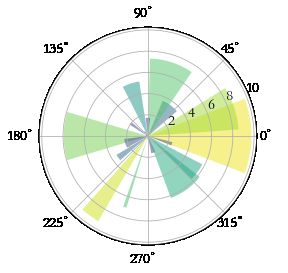
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xZ1m446F-1585829729739)(output_93_0.png)]
散点图绘制
import numpy as np
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.plot(10 * np.random.rand(100),10 * np.random.randn(100),'o')
ax.set_title("Simple Scatter")
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CiVDqc26-1585829729739)(output_95_0.png)]
import numpy as np
import matplotlib.pyplot as plt
N = 20 #绘制坐标中数据的个数
theta = np.linspace(0.0,2*np.pi,N , endpoint = False)#从0到2pi也就是360°,分成20个不同的角度
radii = np.random.rand(N)
radii
array([0.80619399, 0.70388858, 0.10022689, 0.91948261, 0.7142413 ,
0.99884701, 0.1494483 , 0.86812606, 0.16249293, 0.61555956,
0.12381998, 0.84800823, 0.80731896, 0.56910074, 0.4071833 ,
0.069167 , 0.69742877, 0.45354268, 0.7220556 , 0.86638233])
第三周导学 pandas,便于操作数据的数据类型及分析函数,基于numpy实现
series 相当于一维,由一组数据和相关的数据索引组成
dataframe 相当于二维到多维
import pandas as pd
a = pd.Series(range(20))
a #索引,数值
a.cumsum() #计算前N项之和
0 0
1 1
2 3
3 6
4 10
5 15
6 21
7 28
8 36
9 45
10 55
11 66
12 78
13 91
14 105
15 120
16 136
17 153
18 171
19 190
dtype: int64
a = pd.Series([1,2,3,4],index = ['a','b','c','d'])
#等价于 a = pd.Series([1,2,3,4], ['a','b','c','d'])
a
# a = pd.Series([[1,2,3,4],[2,3,4,5]],index = ['a','b'])
a
a 1
b 2
c 3
d 4
dtype: int64
生成和创建Series类型
从标量值创建:pd.Series(标量,index=["索引不能省略"])
从字典创建:pd.Series({key:value,key:value})# key会变成索引
pd.Series({key:value,key:value},index=[])#若再提供索引,则会从字典中选取对应的值,若index存在没有的数据,则默认为NaN
从ndarray类型创建:pd.Series(np.arange(5)) 生成从0-4的数值也可以给定索引 index =np.arange(9,4,-1)
从列表
Series的基本操作
a.index :获取所有index
a.values:获取所有value
a['key'] :自定义索引获取值 #两种都可以用,但是不能混用
a[1] :获取值
Series类型本身是索引加数值的类型,那么对它进行的索引和切片生成的也都是Series类型,若只选中一个值,则返回的是值而不是Series类型
a.index
a.values
a['a'] #输出key为a的value
a[2] #输出第三个
a[:3] #输出前三个
a[a > a.median()] #输出大于中位数的
import numpy as np
np.exp(a) #进行e的x次方运算
'c' in a #判断c是否在a的自定义索引中,不会判断自动索引
a.get('g',200) #a里不含有g,理论上应该返回NaN,但是因为有第二个参数,索引会返回后面的值
a
a 1
b 2
c 3
d 4
dtype: int64
Series的对齐操作
基于索引的运算
Series + Series :会取两个Series的并集,(自定义)索引相同的进行相加,不同的返回NaN
a = pd.Series([1,2,3,4],index = ['a','b','c','d'])
b = pd.Series([10,20,30,40,50],index = ['w','b','d','v','f'])
a + b
a NaN
b 22.0
c NaN
d 34.0
f NaN
v NaN
w NaN
dtype: float64
Series的name属性
Series对象和索引都可以有一个名字,存储在属性.name中
b = pd.Series([10,20,30,40,50],index = ['w','b','d','v','f'])
b.name
b.name = "Series对象"
b.index.name = "索引列"
b
b.name
'Series对象'
Series的修改
随时修改,即时生效
b = pd.Series([10,20,30,40,50],index = ['w','b','d','v','f'])
b['b'] = 22
b.name
b.name = "Series对象"
b.name
b.name = "Series对象1"
b
b['w','b'] = 111
b
w 111
b 111
d 30
v 40
f 50
Name: Series对象1, dtype: int64
dataframe的数据类型
是由共用相同索引的一组列组成的多列数据
纵向操作axis = 0,横向操作axis = 1
创建方式
二维的ndarray对象
一维的adarray和列表和字典和元组和Series构成的字典
Series类型
其他dataframe类型
#从二维ndarray创建
import numpy as np
import pandas as pd
a = pd.DataFrame(np.arange(10).reshape(5,2))
a #就是原始的数据增加了横向和纵向的索引
| 0 | 1 | |
|---|---|---|
| 0 | 0 | 1 |
| 1 | 2 | 3 |
| 2 | 4 | 5 |
| 3 | 6 | 7 |
| 4 | 8 | 9 |
#从一维ndarray对象字典创建
import pandas as pd
dt = {"one":pd.Series([1,2,3],index = ['a','b','c']),
"two":pd.Series([4,5,6,7],index = ['a','b','c','d'])} #先是创建两个Series分别为1列的,然后存储在字典里,在利用dataframe是就会将字典的key当作列名进行变换
a = pd.DataFrame(dt)
a
pd.DataFrame(dt,index = ['b','c','d'],columns = ['two','three']) #对要制作的DataFrame进行数据选择,分别是纵向选择三行,横向选择两列,若字典中不包含列索引,则为空
| one | two | |
|---|---|---|
| a | 1.0 | 4 |
| b | 2.0 | 5 |
| c | 3.0 | 6 |
| d | NaN | 7 |
#从列表创建
import pandas as pd
a = {'one':[1,2,3,4],"two":[9,8,7,6]}
b = pd.DataFrame(a,index = ['a','b','c','d'])
b
| one | two | |
|---|---|---|
| a | 1 | 9 |
| b | 2 | 8 |
| c | 3 | 7 |
| d | 4 | 6 |
b['one'] #索引列
a 1
b 2
c 3
d 4
Name: one, dtype: int64
b.loc['a'] #索引行
one 1
two 9
Name: a, dtype: int64
b['one']['a']
1
b["one"]['a']
1
pandas的数据操作
.reindex() 能够改变或重排Series和DataFrame索引
import pandas as pd
a = {'one':[1,2,3,4],"two":[9,8,7,6]}
b = pd.DataFrame(a,index = ['a','b','c','d'])
b
| one | two | |
|---|---|---|
| a | 1 | 9 |
| b | 2 | 8 |
| c | 3 | 7 |
| d | 4 | 6 |
b = b.reindex(index = ['aa','bb','cc','dd'])
b
| one | two | |
|---|---|---|
| aa | NaN | NaN |
| bb | NaN | NaN |
| cc | NaN | NaN |
| dd | NaN | NaN |
b = b.reindex(columns = ["two",'one'])
b
| two | one | |
|---|---|---|
| a | 9 | 1 |
| b | 8 | 2 |
| c | 7 | 3 |
| d | 6 | 4 |
import pandas as pd
a = {'one':[1,2,3,4],"two":[9,8,7,6]}
b = pd.DataFrame(a,index = ['a','b','c','d'])
c = b.columns.insert(2,'three') ##新增列
c
Index(['one', 'two', 'three'], dtype='object')
import pandas as pd
a = {'one':[1,2,3,4],"two":[9,8,7,6]}
b = pd.DataFrame(a,index = ['a','b','c','d'])
d = b.reindex(columns = c,fill_value = 100) ##新增列添加数值
d
| one | two | three | |
|---|---|---|---|
| a | 1 | 9 | 100 |
| b | 2 | 8 | 100 |
| c | 3 | 7 | 100 |
| d | 4 | 6 | 100 |
##获取行0和列1索引
import pandas as pd
a = {'one':[1,2,3,4],"two":[9,8,7,6]}
b = pd.DataFrame(a,index = ['a','b','c','d'])
b.index
b.columns
Index(['one', 'two'], dtype='object')
索引类型的常用方法
.append(idx) :链接另一个index对象,产生新的index对象
.diff(idx) :计算差集,产生新的index对象
.intersection(idx) :计算交集
.union(idx) :计算并集
.delete(loc) :删除loc位置处的元素
.insert(loc,e) :在loc位置添加一个元素
.drop(index,axis = 0/1) #删除指定的行或列索引和对应的数据,default:axis=0
## pandas的数据类型运算
import numpy as np
import pandas as pd
a = pd.DataFrame(np.arange(12).reshape(3,4))
a
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 |
| 1 | 4 | 5 | 6 | 7 |
| 2 | 8 | 9 | 10 | 11 |
b = pd.DataFrame(np.arange(20).reshape(4,5))
b
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 | 4 |
| 1 | 5 | 6 | 7 | 8 | 9 |
| 2 | 10 | 11 | 12 | 13 | 14 |
| 3 | 15 | 16 | 17 | 18 | 19 |
a + b #自动补齐,缺项为NaN
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 0.0 | 2.0 | 4.0 | 6.0 | NaN |
| 1 | 9.0 | 11.0 | 13.0 | 15.0 | NaN |
| 2 | 18.0 | 20.0 | 22.0 | 24.0 | NaN |
| 3 | NaN | NaN | NaN | NaN | NaN |
a * b
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 0.0 | 1.0 | 4.0 | 9.0 | NaN |
| 1 | 20.0 | 30.0 | 42.0 | 56.0 | NaN |
| 2 | 80.0 | 99.0 | 120.0 | 143.0 | NaN |
| 3 | NaN | NaN | NaN | NaN | NaN |
b.add(a,fill_value = 100)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 0.0 | 2.0 | 4.0 | 6.0 | 104.0 |
| 1 | 9.0 | 11.0 | 13.0 | 15.0 | 109.0 |
| 2 | 18.0 | 20.0 | 22.0 | 24.0 | 114.0 |
| 3 | 115.0 | 116.0 | 117.0 | 118.0 | 119.0 |
b.mul(a,fill_value = 0)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 0.0 | 1.0 | 4.0 | 9.0 | 0.0 |
| 1 | 20.0 | 30.0 | 42.0 | 56.0 | 0.0 |
| 2 | 80.0 | 99.0 | 120.0 | 143.0 | 0.0 |
| 3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
不同维度间为广播运算,一维Series默认在轴1参与运算
比较运算只能比较同索引的元素,不进行补齐
二维和一维,一维和零维之间为广播运算
采用> < >= <= == != 进行的二元运算产生布尔对象
import numpy as np
import pandas as pd
a = pd.Series(np.arange(6))
b = pd.DataFrame(np.arange(20).reshape(4,5))
a + b # 将一维的行作用于二维的列,缺项为NaN
| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 0 | 0 | 2 | 4 | 6 | 8 | NaN |
| 1 | 5 | 7 | 9 | 11 | 13 | NaN |
| 2 | 10 | 12 | 14 | 16 | 18 | NaN |
| 3 | 15 | 17 | 19 | 21 | 23 | NaN |
b.add(a,axis = 0) #设置运算作用于行
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 |
| 1 | 6.0 | 7.0 | 8.0 | 9.0 | 10.0 |
| 2 | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 |
| 3 | 18.0 | 19.0 | 20.0 | 21.0 | 22.0 |
| 4 | NaN | NaN | NaN | NaN | NaN |
| 5 | NaN | NaN | NaN | NaN | NaN |
a >0
0 False
1 True
2 True
3 True
4 True
5 True
dtype: bool
a <b
| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 0 | False | False | False | False | False | False |
| 1 | True | True | True | True | True | False |
| 2 | True | True | True | True | True | False |
| 3 | True | True | True | True | True | False |
数据的排序
空值排序放在末尾
.sort_index()
.sort_value()
b.sort_values(2,ascending = False)
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 3 | 15 | 16 | 17 | 18 | 19 |
| 2 | 10 | 11 | 12 | 13 | 14 |
| 1 | 5 | 6 | 7 | 8 | 9 |
| 0 | 0 | 1 | 2 | 3 | 4 |
数据的基本统计分析
.sum()
.count()
.mean() .median()
.var() .std()
.min() .max()
.argmin() .argmax() 适用于Series计算最大值和最小值所在位置的索引位置,自动索引
.idxmin() .idmax() 适用于Series计算最大值和最小值所在位置的索引位置,自定义索引
.descreibe() :对数据进行所有统计信息汇总,二维的数据根据0轴进行运算
.descreibe()['count]
相关分析函数
.cov() :协方差矩阵
.corr() :计算相关系数矩阵,Person、Spearman、Kendall等系数
可以不用了解公式是如何计算的,如何调用即可