【无标题】
语音情感识别研究综述
高庆吉 , 赵志华 ![]()
![]() , 徐达 , 邢志伟
, 徐达 , 邢志伟
摘要:针对语音情感识别研究体系进行综述。这一体系包括情感描述模型、情感语音数据库、特征提取与降维、情感分类与回归算法4个方面的内容。本文总结离散情感模型、维度情感模型和两模型间单向映射的情感描述方法;归纳出情感语音数据库选择的依据;细化了语音情感特征分类并列出了常用特征提取工具;最后对特征提取和情感分类与回归的常用算法特点进行凝练并总结深度学习研究进展,并提出情感语音识别领域需要解决的新问题、预测了发展趋势。
关键词:深度学习 情感语音数据库 情感描述模型 语音情感特征 特征提取 特征降维 情感分类 情感回归
Review on speech emotion recognition research
GAO Qingji , ZHAO Zhihua ![]()
![]() , XU Da , XING Zhiwei
, XU Da , XING Zhiwei
Abstract: In this paper, the research system of speech emotion recognition is summarized. The system includes four aspects: emotion description models, emotion speech database, feature extraction and dimensionality reduction, sentiment classification and regression algorithms. Firstly, we sum up the emotional description method of discrete emotion model, dimensional emotion model and one-way mapping between two models, then conclude the basis of emotional speech database selection, and then refine the classification of speech emotion features and list common tools for extracting the characteristics, and finally, extract the features of common algorithms, such as feature extraction, emotion classification and regression, and make a conclusion of the progress made in deep-learning research. In addition, we also propose some problems that need to be solved in this field and predict development trend.
Key words: deep learning sentiment speech databases sentiment description models acoustic sentiment features feature extraction feature reduction sentiment classification sentiment regression
语音情感计算包括语音情感识别、表达和合成等内容,近年受到广泛关注。其中,语音情感识别应用广泛,具有不可替代的作用。如结合驾驶员的语音[1]、表情[2-3]和行为[4]信息检测其精神状态,提醒驾驶员控制情绪、安全驾驶;依据可穿戴设备采集病人的语音信号实时检测其异常情感状态[5-6],提高治疗效率;结合语音情感信息和自动翻译结果来帮助各方发言者顺畅交流[7]等。
近年来,研究者们就语音情感识别做了大量研究。韩文静等[8]从情感描述模型、情感语音数据库、特征提取和识别算法4个角度总结了2014年为止的语音情感识别的研究进展,并重点分析SVM、GMM等传统机器学习算法对离散情感的分类效果。随着深度学习技术逐步完善,在海量复杂数据建模上有很大优势,多用于解决数据分类。同时,部分研究者将其应用于语音特征的提取,取得了一定的成果。2018年,刘振焘等[9]介绍了语音情感特征提取和降维的方法,其中,重点描述了基于BN-DBN、CNN等深度学习方法的语音特征提取相关研究。
随着研究者深入探索,语音情感识别在以下几方面进展突出:维度情感和离散情感到维度情感的映射使情感描述更精确;情感语音数据库联合使用;采用深度学习方法进行特征提取和情感分类与回归;情感识别算法向更深层网络、多方法融合角度演变。
本文将从情感描述模型、情感语音数据库、特征提取与降维、情感分类与回归算法四个环节综述当前主流技术和前沿进展,然后总结深度学习研究的难点,指出未来的研究趋势。其中,着重分析深度学习算法在特征提取、情感分类与回归算法方面的研究进展。
1 情感描述模型
完整的语音情感识别包括采集语音片段、预处理、语音特征提取与降维、情感分类与回归等流程,如图1所示。
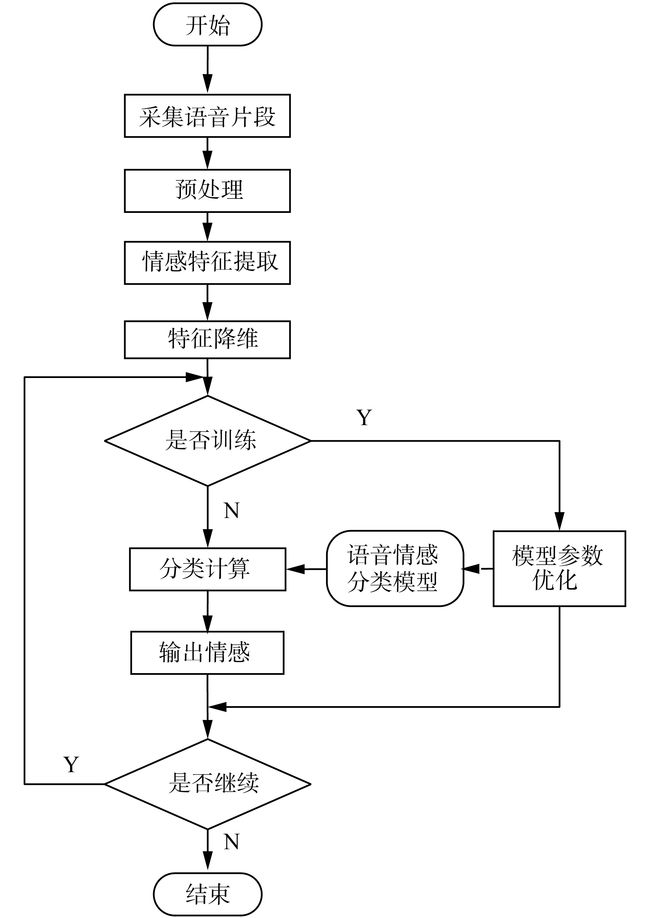 |
Download: JPG larger image |
|---|---|
| 图 1 语音情感识别流程图Fig. 1 Speech emotion recognition flow chart |
实现语音情感识别,首先需要定义情感。情感描述模型将情感表征为一组互斥的离散情感类别或数字维度组合[10](空间坐标值)。根据表征方式不同,分为离散情感模型和维度情感模型。
离散情感模型使用形容词标签表示情感。Mover简单地将离散情感分为痛苦、快乐两类基本情感[11];进一步,Ekman[12]将离散情感分成愤怒、厌恶、恐惧、快乐、悲伤和惊喜6种基本情感。目前常用10余种情感描述模型中,使用最广泛的是Ekman提出的6种基本情感和在此基础上加入中性的7种基本情感[13]。离散情感模型简单直观,运用广泛,但描述精确度不高、连续性不好,表征情感能力有限。为克服以上不足,学者们建立了维度情感模型。
维度情感模型可以在二维或多维空间中构造,用以描述连续情感。可利用效价−唤醒二维模型(valence-arousal, VA)描述情感的极性和度量情感程度,能够表示大部分情感;愉悦−唤醒−支配三维模型(pleasure-arousal-dominance, PAD)在VA模型上添加支配维,用以描述周围环境对自身的影响,如高支配度是一种主宰感,低支配度是一种软弱感[14],理论上可以表示无穷多种情感,但难以表述惊讶[15]。Fontaine等[16]研究表明,在PAD模型基础上添加期望维,度量个体对情感出现的准备性,可以描述惊讶。维度情感模型表征情感能力强(情感类别多、精确性高),可连续表征情感变化,但维度情感理解困难且操作复杂,目前研究者较少。
因此,为合理利用现有基于离散情感模型建立的数据库,研究者们开始关注离散情感和维度情感间的映射。Russell提出环形模型[17],将VA模型空间中的某些区域解释为28种离散情感。而后,Yik等[18]将维度情感聚类为8种基本离散情感,即情绪轮。再后,又将该模型聚类情感扩展到12种。Plutchik[19]引入更加复杂的混合情感模型,即情绪“沙漏”。目前,环形模型和情绪“沙漏”的关联性是大家关注的焦点,实用性有待研究[10]。
离散情感模型简单直接易搭建,但描述精度不足;维度情感模型描述精度高,情感表征能力强,但操作复杂,文献不多;离散情感和维度情感间的映射有研究价值,但实用性有待研究。故如何更好地将离散情感与维度情感结合来提升情感状态表征精度,受到广泛关注。
2 情感语音数据库与数据标注****2.1 情感语音数据库
研究情感分类与回归算法,需要数据库的支撑。目前情感语音数据库数量较多,但没有统一的划分标准。为方便理解,学者们从情感描述角度,将语音数据库划分为离散情感数据库和维度情感数据库两类。表1和表2从参与人数、语言、标注人数、离散情感种类数、样本量及激发方式6个方面分别分析常用离散和维度情感语音数据库。
 |
表 1 常用离散情感语音数据库统计表Tab.1 Statistical table of the frequently used discrete emotion speech databases |
|---|---|
|
表 2 常用维度情感语音数据库统计表Tab.2 Statistical table of the frequently used dimensional emotion speech databases |
|---|---|
表1和表2根据激发方式将数据库分为自然型、表演型和引导型数据库。自然型数据库采集的语音样本最接近自然交流,但是其制作难度高,目前数量较少,常用FAU AIBO数据库[26]和VAM数据库[27];表演型数据库要求专业演员在安静环境中根据指定语料进行表演并采集语音样本;引导型数据库数量最多,常通过视频或对话诱导安静环境中的参与者表达相应情感以获取样本。进一步可看出,常见离散情感语音数据库多属于表演型,常见维度情感语音数据库多属于引导型。
此外,由表1和表2可知,多数数据库区分性别和语言种类。研究者可利用此信息度量不同性别、跨文化等语境特征对情感识别的影响并建立智能推理模型,为实现个性化人机交互提供可能[32]。
进一步,离散情感与维度情感联合建立数据库,便于研究者理解和使用,如FAU AIBO;结合面部表情、语音和姿态等[33]建立多模态数据库,拓展识别算法的信息维度,如SAVEE、IEMOCAP。而并且嘈杂环境最接近自然环境,在其中采集样本,数据库建立的难度较大,也对识别算法鲁棒性提出严峻挑战。
2.2 数据标注
离散情感数据库主要采用标注者投票判别情感种类和准确性[20,24],使用专业工具辅助判别较少。维度情感数据库借助SAM系统[34]或MAAT工具[35]量化PAD模型维度取值;FEELTRACE[30]量化VA模型维度取值;ANNEMO[36]一次仅标记一个维度,结果更精确[15]。
同时,情感标注也要求标注者有一定的经验,同时标注过程中精神高度集中。多数数据库采用对多标注者标注的数据进行插值、标准化等处理,以降低标注者自身因素对标注结果的干扰。
语音情感数据库不断丰富,情感描述能力不断提升的同时,对数据标注的新需求也不断扩充,如何通过模块设计等方法集成各优秀的数据标注工具的性能集成,是一个研究方向。此外,研究者开始探索弱标注,即采用半监督的方法提取无标注和有标注样本的公共信息,学习无标注的样本,充分利用数据库。
3 特征提取与降维
如何提取语音中的丰富情感信息并凝练,直接影响情感分类和回归算法的运算效率和准确性。因此,提取有代表性的语音情感特征并进行降维,便显得十分必要。
3.1 预处理
为消除人体语音器官和声音采集设备的差异、混叠、高次谐波失真等影响,在特征提取前需进行预处理。预处理包括:提取语音信号的起始点和终止点的端点检测、将语音信号转化为短时平稳分析帧的加窗分帧、对高频部分进行加重,增强分辨率的预加重等[37-38]。
3.2 特征提取
深度特征是深度学习提取的高级特征,在语音情感识别应用中表现突出[39],故将特征在原来4类[40]基础上拓展为声学、语言、语境、深度和混合共5类特征。
\1) 声学特征提取
声学特征分为3类:韵律学特征、基于谱的相关特征和声音质量特征,描述语音的音调、幅度、音色等信息。如共振峰、梅尔频率倒谱系数[41-45](Mel frequency cepstrum coefficient, MFCC)和抖动和谐波噪声比(harmonic to noise ratio, HNR)。常规提取方法,如自相关函数法和小波法,可参考文献[9]。
此外,为减少手工提取的复杂性和盲目性,学者们采用深度学习提取声学特征[46]。如分层稀疏编码[47]以无人监督的方式,自动挖掘情绪语音数据的非线性特征,语音情感区分特性更强;基于双层神经网络的域自适应方法[48]可共享源域和目标域中相关类的公共先验知识,实现源域和目标域的共享特征表示,可有效传递知识和提高分类性能。
\2) 语言、语境和混合特征提取
语言特征通过对语义信息进行分析提取获得。研究者提出对语义按固定长度分段,比对码本将其转化为特征向量,如BoW(Bag of Words)[49],BoNG(Bag of N-grams)[50]、BoCNG(Bag of Character N-grams)[50]和小波特征[51]等。
语境特征主要描述不同说话者的性别和文化背景的差异[40]。区分性别能改善分类效果[52]。通过对比分析文化内、多元文化和跨文化情况下情感识别效果,其中,文化内、多元文化背景下情感识别效果最佳[53]。
混合特征融合两种及两种以上的特征。金琴等[49]为每个情感类构建一个情感词典,其中包含特定情绪的词汇和分配的权重,用以表明这种情感的倾向。然后,使用此情感词典为每个话语生成矢量特征表示即情感向量词汇特征。最后,融合声学特征、情感向量和BoW,提升情感识别准确率。Ashish等[52]以语境特征和声学特征为切入点,系统分析了区分和忽略性别信息对情感识别率的影响。实验结果表明,区分性别的情感识别更准确。
\3) 深度情感特征提取
因低级特征数量有限、提取耗资且不能完整描述语音信号,所以研究者尝试从低级特征中进一步提取高级特征或直接批量处理原始音频,自动提取高级特征,例如深度特征[39]。深度学习可从每层网络和网络层次结构中提取复杂特征—深度特征,常用方法有卷积神经网络(convolutional neural network, CNN)、深度信念网络(deep belief network, DBN)、深度神经网络(deep neural network, DNN)等。
王忠民等[43]采用CNN从语谱图中提取图像特征,改善MFCC丢失信息识别准确率不高的问题。但CNN无法准确捕捉语谱图中特征的空间信息,为此Wu等[54]采用两个循环连接的胶囊网络提取特征,增强时空敏感度。此外,Zhang等[40]以类似于RGB图像表示的3个对数梅尔光谱图作为DCNN的输入,然后通过ImageNet[55]预训练的AlexNet DCNN模型学习光谱图通道中的高级特征表示,最后将学习的特征由时间金字塔匹配(DTPM)策略聚合得到全局深度特征,进一步提升对有限样本特征提取的有效性。为有效描述情感连续性变化,Zhao等[56]采用局部特征学习块从log-mel谱图提取的局部特征,重构为时序形式后输入至长短期记忆网络(long and short term memory network, LSTM),以进一步提取全局上下文特征。
张丽等[57]采用贪婪算法进行无监督学习,通过BP神经网络反向微调,找到全局最优点,再将DBN算法的输出参数作为深度特征,并在此过程中,采用随机隐退思想防止过拟合。
进一步,为解决基于多样本库的源域和目标域中数据分布差异,Abdelwahab等[58]采用域对抗神经网络创建源域(USC-IEMOCAP和MSP-IMPROV数据库)和目标域(MSP-Podcast数据库)的共同特征表示——深度特征,然后通过梯度反转层将域分类器生成的梯度在传播回共享层时乘以负值,使训练集和测试集的特征收敛,提升泛化能力。同时使用t-SNE数据可视化技术[59],通过创建不同层的特征分布2D投影,直观检查模型学习特征表示的全过程。
此外,说话者无关训练(speaker-invariant training,SIT,模型的学习结果与说话者自身无关,即要求模型有较强的泛化能力)[60]通过对抗性学习减少声学建模过程中说话者差异的影响,再联合DNN,来提取与说话者无关且辨别力强的深度特征。
\4) 常用特征提取工具
目前Praat[61]和OpenSMILE[62]两种工具使用最广泛。Praat是一款语音学专业软件,其GUI界面简洁且指导手册持续更新,便于学习。可对语音文件进行特征提取、标注等工作,结果可导出。OpenSMILE使用命令行和GUI结合的方式进行使用。常用配置文件config/IS09/10/11/12/13 paraling. conf,分别提取384、1 582、4 368、6 125和6 373维特征。此外,在Tensorflow框架中,可以调用Librosa工具包提取频谱图、MFCC等特征,便于后续识别。表3整理了更多的提取工具可供学习。
|
表 3 常用语音特征提取工具统计表[63]Tab.3 Statistical table of common speech feature extraction tools |
|---|---|
3.3 特征降维
上述特征提取方法得到的语音情感特征一般维数较高,直接处理易导致维度灾难。为保障识别准确率和效率,采用主成分分析(principle component analysis, PCA)[64]、Fisher准则[38]、线性判别分析(linear discriminate analysis, LDA)[65]和FCBF(fast correlation-based filter solution) [66]等方法进行特征降维。如BP神经网络[67]可进行特征选择,检测冗余的同时,通过节点信号变化的敏感度挑选对网络贡献度大的特征得到组合特征。
声学特征因提取算法和提取工具丰富,使用广泛;深度学习框架环境日益发展,被更多研究者用于提取情感特征。此外,声学和语义是语音信号的两个主要部分。随着文本情感研究深入,从语义中提取的语言特征将会成为混合特征中的重要组成部分。故如何有效利用句子含义与转折词,精简语言特征并提升特征的有效性,将成为研究热点。
4 情感分类与回归
根据情感表征方式不同,将目前主流识别算法分为情感分类算法和情感回归算法两类。
4.1 情感分类算法
情感分类算法将测试集样本归类为不同离散情感类别,常使用支持向量机(support vector machines, SVM)、隐马尔可夫模型(hidden Markov model, HMM)和DCNN。
SVM[68-71]在求解非线性、小样本和高维模式识别等问题具有优越性,且泛化能力强,在情感分类中广泛使用[38]。半定规划多核SVM[72]来提高分类算法的鲁棒性。
Zheng等[73]采用DCNN对通过PCA白化处理的光谱图学习处理并进行情感分类,结果表明该方法优于SVM。进一步,Shahin等[74]级联高斯混合模型和深度神经网络(gaussian mixture model-deep neural network, GMM-DNN)构建混合分类器,其分类性能优于SVM、MLP(multi-layer perception)、GMM和DNN,并且在嘈杂谈话背景下,情感分类效果良好。
Sagha等[75]以OpenSMILE提取384个特征为基于核典型相关分析的域自适应方法的输入,在EMODB、SAVEE、EMOVO和Polish等4个不同语言的语音数据库上实现跨语料库迁移学习,学习速度快且有效克服过拟合,明显降低陷入局部最小值的风险。
以上算法均针对语音信号来提升情感分类准确性。此外,融合其他模态的特征,如面部表情[2]、姿态和生理信号[1],可提升情感分类的鲁棒性和可信度。陈师哲等[76]结合面部表情和语音模态,采用SVM和随机森林来减弱文化差异对情感分类的影响。刘颖等[77]结合面部表情和语音双模态,采用GMM,有效提升分类的准确性。
4.2 情感回归算法
情感回归算法将测试样本的连续维度情感值映射到二维或多维坐标空间。情感回归传统方法为SVR(support vector regression)[41,47]。
近年来,研究者将深度学习技术引入情感回归中,取得良好效果,如LSTM和DANN。Zhao等[56]采用二维CNN LSTM网络学习局部特征学习块和LSTM提取的局部特征和全局特征并在全连接层实现VA模型情感预测,改变DBN、CNN等算法模型只能学习一种深度特征的现状。在IEMOCAP数据库中,本方法在说话者相关和说话者无关中的识别正确率分别为89.16%和52.14%,远高于分别采用DBN和CNN获得的73.78%和40.02%的正确率。Abdelwahab等[58]在合并情感语音数据库中采用域对抗神经网络(domain adversarial neural network, DANN)根据提取的源域和目标域的共同特征表示,实现PAD模型下的情感回归,提升鲁棒性。
一般情感回归主要解决维度情感问题,为有效利用仅标注离散情感的语音数据库,Ma等[78]采用SVM分类,通过离散情感和维度情感间的单向映射,实现PAD模型下的情感回归;Eyben等[70]将离散情感映射至VA模型中对应维度情感坐标,拓展情感描述能力。基于此,表4描述了数据库特定离散情感类别至VA模型中维度情感间的映射。
| [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OCON7CKC-1655396344440)(https://xingqiu-tuchuang-1256524210.cos.ap-shanghai.myqcloud.com/1120/table-icon.gif)] | 表 4 数据库离散情感到VA模型中的维度情感的映射统计表[70]Tab.4 Mapping statistical table of dataset specific emotion categories to dimensional emotions in VA models |
|---|---|
离散情感简单易理解,可用于训练的数据库较多,受众广,其中,基于声学特征的情感分类研究成果丰硕而情感回归实现维度情感识别有待加强。
5 对比与分析
本部分首先总结当前研究者们在语音情感识别的研究过程,然后对比分析各特征提取和情感分类与回归算法的优缺点,最后重点评析深度学习的研究近况。
近年来,研究者们在语音情感特征、特征提取方法、降维或融合方法、数据库、情感类别和情感分类与回归算法等影响情感识别的方面做了不懈努力,取得了较好成就。故从这6个方面总结近年语音情感识别相关研究,如表5所示。由于不同文献所使用的数据库、特征和使用的情感类别等方面都不尽相同,暂不比较各分类与回归算法准确率。
|
表 5 语音情感识别过程总结统计表Tab.5 Summary statistical table of speech emotion recognition’s whole process |
|---|---|
此外,表6概要分析了典型特征提取和情感分类与回归算法的特点。DNN、CNN和DBN等深度学习算法因表征能力好、学习能力强,能有效提取情感特征,但参数调整直接影响提取效果。情感分类与回归算法中,SVM等传统算法简单并能有效解决小样本、高维、非线性等问题,但对缺失数据问题敏感且无法处理大样本;各类深度学习算法优点较多,如:KNN处理大样本能力强;RNN、LSTM适合处理样本序列;ELM计算复杂但泛化能力强,对训练数据依赖性大,处理大样本耗时。鉴于算法特点的差异,采用前需全面分析。
|
表 6 特征提取和情感分类与回归算法特点统计表Tab.6 Statistical table of the feature extraction and sentiment classification and regression algorithms |
|---|---|
总体而言,深度学习因其有着比传统机器学习方法更优越的性能,近期在特征提取和情感分类与回归中受到广泛关注。但是在不断研究和处理中,研究者也发现深度学习主要存在以下3个方面的不足:1)作为典型的“黑箱”算法,不易描述网络具体实现且解释能力弱;2)以输入为导向的神经网络算法仅根据现有样本进行学习,但自身无法验证输入样本的代表性和正确性;3)隐藏层中节点个数设置缺乏客观性,主要凭借经验设置。
为此,研究者们主要做了如下努力:1)采用数据可视化技术,如t-SNE[59],从各个层次理解数据分布,有助于模型敏感性分析,提升模型可解释性;2)采用弱标注、无监督[86]或半监督[87]方法,在现有数据库基础上,尽可能利用无标签数据,提取域共同特征表示,拓展模型泛化能力[79]。3)在隐藏层数、节点和超参数调整时根据算法性能反馈设置实时优化设置[89],如通过LSTM等类深度学习算法获取时序信息[90]和通过采用多个模型检测隐藏变量。
鉴于上述分析,概要深度学习在语音情感识别领域中的发展趋势:
1)当前机器缺乏理论推理是因为没有常识,故张䥽院士提出将感知和认知投射到语义向量空间(特征向量空间和符号向量投射到一个空间,该空间称之为语义向量空间),从而为感知和认知建立统一的理论框架,统一处理,解决理解问题。
2)鉴于当前深度学习存在需要大量的数据集、知识无法积累等问题,可采用迁移学习或基于度量、模型和优化的元学习方法,实现小样本学习,在一定程度上实现知识积累。
3)使用更高算力的设备。如清华大学团队在《自然》上介绍的天机芯片,灵活使用类脑计算和深度学习算法[91],使语音情感识别运算结果尽可能达到模型理论推导的预期结果。
6 应用与发展趋势
语音情感识别源于简单、交互直观,应用广泛。商务谈判中,提取语音和表情进行情感计算并利用云计算远程存储,实时获取情感信息,辅助用户决策[91];远程教育系统对学员的语音、姿态和表情进行分析,及时反馈学习状态,调整教学计划,实现个性化培养;可穿戴设备监测用户情感状态、通过语音交互,辅助医生进行精神分裂症患者[92]、情绪障碍患者[84]、自闭症儿童的状态监测和治疗[93]。公共服务中,呼叫中心根据语音情感值筛选紧急电话[85]。机器人通过语音情感识别,提升了人机交互[94]的针对性和准确性,为实现机器情感仿生奠定了基础。
语音情感识别显示出广阔的应用前景。研究者对语音情感识别深入探索,推进了其理论研究和实际应用。目前已基本实现安静环境下的语音情感识别。而嘈杂环境下的语音情感识别尚有待深入;此外,现有情感语音数据库总体语料不足,特别是自然型数据库。同时标注离散情感和维度情感的语音数据库数量较少,如何对数据库同时标注,尚未形成广泛认可的体系;标注方法较少、典型特征近期没有得到重大突破、语音情感识别理论需进一步完善。综上所述,语音情感识别尚未达到成熟阶段,需进行语料库的丰富、理论的加强和方法的创新。尚待解决的问题和未来发展趋势包括:
1)数据库不足且缺少广泛认可的数据库。目前数据库多在实验室环境中采集,而情感在现实世界中比实验室环境中表达方式更复杂,自然型数据库可有效解决这一难题,但其语料目前较少,需进一步丰富。可考虑采用跨语音库、合并语音库等方法扩充语料或基于当前数据自动生成样本填充数据库,如GAN。此外,建立广泛认可的数据库,如图像处理领域中的ImageNet,进一步集结科研力量,推动深入研究。
2)标注多样化。同时对数据库标注维度情感和离散情感,二者互为补充,相互验证。促进从离散情感研究转向更精确的维度情感研究,为人机高级交互奠定基础。此外,目前广泛使用的标注方法和专业辅助工具较少,需进一步丰富。
3)特征挖掘是可提升的方向。语音情感识别领域中,情感特征丰富,但是现有典型特征较少,多为声学特征,且近期没有提出类似或更优的特征,故特征挖掘需要进一步加强。
4)特征提取方法需改良。语音情感数据样本有限,而语音识别语料数量庞大,如何采用无监督或半监督方式,自动学习无标签语料提取有效情感特征,是一个难题。此外,基于深度学习的特征提取依赖所搭建网络的具体结构,对比点云领域的PointNet和目标检测领域的YOLO,目前情感识别领域缺乏对语音情感特征敏感且被广泛认可的网络结构,如何搭建一个擅于提取情感特征的专用网络结构已成为新的研究热点。
5)情感识别算法需深入研究。如何使用跨领域算法微调,获取更优的初始化参数,提升识别收敛性与准确性,将成为新的研究热点;同时,区分性别、文化差异等来优化识别效果,是研究的一个方向。目前实时连续语音识别很少成功,可通过模拟复杂背景环境、提升算法的鲁棒性、提高模型运算效率和改善资源分配等方法解决。此外,高级语音情感识别应能模拟人对语音信息的处理,实现机器情感仿生,这些功能目前暂未实现。该课题需神经学、脑科学等多学科支持,值得深入研究。
7 结束语
本文从情感描述模型、情感语音数据库、特征提取与降维、情感分类与回归算法4个环节对语音情感识别进行综述,并着重分析深度学习算法在特征提取、情感分类与回归算法方面的研究进展。总体而言,语音情感识别研究体系较为完整,深度学习因其优越的性能也在特征提取和情感分类与回归中受到了广泛关注、显示出广阔的应用前景。最后总结了语音情感识别领域中语音情感数据库、标注方法和专业辅助工具、语音情感特征挖掘、语音情感特征提取、情感识别算法5个方面的尚待解决的问题,预测了未来的发展趋势。