Don’t Forget the I/O When Allocating Your LLC ISCA 2021
目录
- Abstract
- Introduction
- background
-
- A. Managing LLC in Modern Server CPU
- A. 在现代服务器 CPU 中管理 LLC
- B. 数据直接 I/O 技术
- C. 虚拟化服务器中的租户-设备交互
- 动机:I/O 对 LLC 的影响
-
- A. DMA 泄漏问题
- B. 潜在竞争者问题
Abstract
In modern server CPUs, last-level cache (LLC) is a critical hardware resource that exerts significant influence on the performance of the workloads, and how to manage LLC is a key to the performance isolation and QoS in the cloud with multi-tenancy. In this paper, we argue that in addition to CPU cores, high-speed I/O is also important for LLC management. This is because of an Intel architectural innovation – Data Direct I/O (DDIO) – that directly injects the inbound I/O traffic to (part of) the LLC instead of the main memory. We summarize two problems caused by DDIO and show that
(1) the default DDIO configuration may not always achieve optimal performance,
(2) DDIO can decrease the performance of non-I/O workloads that share LLC with it by as high as 32%.
We then present, the first LLC management mechanism that treats the I/O as the first-class citizen. Iat monitors and analyzes the performance of the core/LLC/DDIO using CPU’s hardware performance counters and adaptively adjusts the number of LLC ways for DDIO or the tenants that demand more LLC capacity. In addition, Iat dynamically chooses the tenants that share its LLC resource with DDIO to minimize the performance interference by both the tenants and the I/O. Our experiments with multiple microbenchmarks and real-world applications demonstrate that with minimal overhead, Iat can effectively and stably reduce the performance degradation caused by DDIO.
在现代服务器 CPU 中,最后一级缓存 (LLC) 是一种关键的硬件资源,对工作负载的性能产生重大影响,如何管理 LLC 是多租户云中性能隔离和 QoS 的关键。在本文中,我们认为除了 CPU 内核之外,高速 I/O 对于 LLC 管理也很重要。这是因为英特尔架构创新——数据直接 I/O (DDIO)——直接将入站 I/O 流量注入(部分)LLC 而不是主内存。我们总结了 DDIO 引起的两个问题,并表明
(1) 默认的 DDIO 配置可能无法始终达到最佳性能,
(2) DDIO 可以将与其共享 LLC 的非 I/O 工作负载的性能降低高达 32% .
然后我们介绍,第一个将 I/O 视为一等公民的 LLC 管理机制。Iat 使用 CPU 的硬件性能计数器来监控和分析 core/LLC/DDIO 的性能,并为 DDIO 或需要更多 LLC 容量的租户自适应地调整 LLC 方式的数量。此外,Iat 动态选择与 DDIO 共享其 LLC 资源的租户,以最大限度地减少租户和 I/O 对性能的干扰。我们在多个微基准测试和实际应用中的实验表明,Iat 可以以最小的开销有效且稳定地减少 DDIO 导致的性能下降。此外,Iat 动态选择与 DDIO 共享其 LLC 资源的租户,以最大限度地减少租户和 I/O 对性能的干扰。我们在多个微基准测试和实际应用中的实验表明,Iat 可以以最小的开销有效且稳定地减少 DDIO 导致的性能下降。此外,Iat 动态选择与 DDIO 共享其 LLC 资源的租户,以最大限度地减少租户和 I/O 对性能的干扰。我们在多个微基准测试和实际应用中的实验表明,Iat 可以以最小的开销有效且稳定地减少 DDIO 导致的性能下降。
Introduction
The world has seen the dominance of Infrastructure-as-a-Service (IaaS) in cloud data centers. IaaS hides the underlying hardware from the upper-level tenants and allows multiple tenants to share the same physical platform with virtualization technologies such as virtual machine (VM) and container (i.e., workload collocation) [46], [59]. This not only facilitates the operation and management of the cloud but also achieves high efficiency and hardware utilization.
世界已经见证了基础设施即服务 (IaaS) 在云数据中心的主导地位。IaaS 对上层租户隐藏了底层硬件,并允许多个租户使用虚拟机(VM)和容器(即工作负载搭配)等虚拟化技术共享同一个物理平台[46]、[59]。这不仅方便了云的运营和管理,而且实现了高效率和硬件利用率。
However, the benefits of the workload collocation in the multi-tenant cloud do not come for free. Different tenants may contend with each other for the shared hardware resources, which often incurs severe performance interference [37], [61]. Hence, we need to carefully allocate and isolate hardware resources for tenants. Among these resources, the CPU’s last-level cache (LLC), with much higher access speed than the DRAM-based memory and limited capacity (e.g., tens of MB), is a critical one [65], [78].
然而,多租户云中工作负载搭配的好处并不是免费的。不同的租户可能会为共享的硬件资源相互竞争,这往往会导致严重的性能干扰[37],[61]。因此,我们需要为租户仔细分配和隔离硬件资源。在这些资源中,CPU 的最后一级缓存 (LLC) 具有比基于 DRAM 的内存更高的访问速度和有限的容量(例如,数十 MB),是至关重要的[65]、[78]。
There have been a handful of proposals on how to partition LLC for different CPU cores (and thus tenants) with hardware or software methods [13], [39], [42], [62], [71], [72], [76]. Recently, Intel® Resource Director Technology (RDT) enables LLC partitioning and monitoring on commodity hardware in cache way granularity [22]. This spurs the innovation of LLC management mechanisms in the real world for multi-tenancy and workload collocation [11], [57], [61], [66], [73], [74]. However, the role and impact of high-speed I/O by Intel’s Data Direct I/O (DDIO) technology [31] has not been well considered.
关于如何使用硬件或软件方法为不同的 CPU 内核(以及租户)划分 LLC 的建议有一些[13]、[39]、[42]、[62]、[71]、[72]、[76]。最近,英特尔®资源管理器技术 (RDT) 支持以缓存方式粒度对商品硬件进行 LLC 分区和监控[22]。这刺激了现实世界中多租户和工作负载搭配的 LLC 管理机制的创新[11]、[57]、[61]、[66]、[73]、[74]。然而,英特尔的数据直接 I/O (DDIO) 技术[31]的高速 I/O 的作用和影响尚未得到充分考虑。
Traditionally, inbound data from (PCIe-based) I/O devices is delivered to the main memory, and the CPU core will fetch and process it later. However, such a scheme is inefficient w.r.t. data access latency and memory bandwidth consumption. Especially with the advent of I/O devices with extremely high bandwidth (e.g., 100Gb network device and NVMe-based storage device) – to the memory, CPU is not able to process all inbound traffic in time. As a result, Rx/Tx buffers will overflow, and packet loss occurs. DDIO, instead, directly steers the inbound data to (part of) the LLC and thus significantly relieves the burden of the memory (see Sec. II-B), which results in low processing latency and high throughput from the core. In other words, DDIO lets the I/O share LLC’s ownership with the core (i.e., I/O can also read/write cachelines), which is especially meaningful for I/O-intensive platforms.
传统上,来自(基于 PCIe 的)I/O 设备的入站数据被传送到主内存,CPU 内核稍后会提取和处理它。然而,这样的方案在数据访问延迟和内存带宽消耗方面效率低下。特别是随着具有极高带宽的 I/O 设备(例如,100Gb 网络设备和基于 NVMe 的存储设备)的出现,对于内存而言,CPU 无法及时处理所有入站流量。结果,Rx/Tx 缓冲区将溢出,并发生数据包丢失。相反,DDIO 直接将入站数据引导至(部分)LLC,从而显着减轻了内存负担(参见第 II-B 节)),这导致内核的低处理延迟和高吞吐量。换句话说,DDIO 让 I/O 与核心共享 LLC 的所有权(即I/O 也可以读/写缓存行),这对于 I/O 密集型平台尤其有意义。
Typically, DDIO is completely transparent to the OS and applications. However, this may lead to sub-optimal performance since (1) the network traffic fluctuates over time, and so does the workload of each tenant, and (2) I/O devices can contend with the cores for the LLC resource. Previously, researchers [18], [54], [56], [69] have identified the “Leaky DMA” problem, i.e., the device Rx ring buffer size can exceed the LLC capacity for DDIO, making data move back and forth between the LLC and main memory. While ResQ [69] proposed a simple solution for this by properly sizing the Rx buffer, our experiment shows that it often undesirably impacts the performance (see Sec. III-A). On the other hand, we also identify another DDIO-related inefficiency, the “Latent Contender” problem (see Sec. III-B). That is, without DDIO awareness, the CPU core is assigned with the same LLC ways that the DDIO is using, which incurs inefficient LLC utilization. Our experiment shows that this problem can incur 32% performance degradation even for non-I/O workloads. These two problems indicate the deficiency of pure core-oriented LLC management mechanisms and necessitate the configurability and awareness of DDIO for extreme I/O performance.
通常,DDIO 对操作系统和应用程序是完全透明的。然而,这可能会导致性能欠佳,因为 (1) 网络流量会随着时间的推移而波动,每个租户的工作负载也是如此,以及 (2) I/O 设备可能会与核心竞争 LLC 资源。此前,研究人员[18]、[54]、[56]、[69]已经确定了“ Leaky DMA ”问题,即设备 Rx 环形缓冲区大小可以超过 DDIO 的 LLC 容量,使得数据在它们之间来回移动LLC 和主存储器。虽然 ResQ [69]通过适当调整 Rx 缓冲区的大小为此提出了一个简单的解决方案,我们的实验表明它通常会影响性能(参见第 III-A 节)。另一方面,我们还发现了另一个与 DDIO 相关的低效率问题,即“潜在竞争者”问题(参见第 III-B 节)。也就是说,在没有 DDIO 感知的情况下,CPU 内核被分配与 DDIO 使用的 LLC 方式相同的方式,这会导致 LLC 利用率低下。我们的实验表明,即使对于非 I/O 工作负载,这个问题也会导致 32% 的性能下降。这两个问题表明纯面向内核的 LLC 管理机制的不足,需要 DDIO 的可配置性和意识来实现极端的 I/O 性能。
To this end, we propose Iat, the first, to the best of our knowledge, I/O-aware LLC management mechanism. Iat periodically collects statistics of the core, LLC, and I/O activities using CPU’s hardware performance counters. Based on the statistics, Iat determines the current system state with a finite state machine (FSM), identifies whether the contention comes from the core or the I/O, and then adaptively allocates the LLC ways for either cores or DDIO. This helps alleviate the impact of the Leaky DMA problem. Besides, Iat sorts and selects the least memory-intensive tenant(s) to share LLC ways with DDIO by shuffling the LLC ways allocation, so that the performance interference between the core and I/O (i.e., the Latent Contender problem) can be reduced.
为此,我们首先提出 Iat,据我们所知,I/O-aware LLC 管理机制。Iat 使用 CPU 的硬件性能计数器定期收集核心、LLC 和 I/O 活动的统计信息。Iat根据统计数据,通过有限状态机(FSM)判断当前系统状态,识别争用来自内核还是I/O,然后自适应地为内核或DDIO分配LLC方式。这有助于减轻 Leaky DMA 问题的影响。此外,Iat 通过对 LLC 路分配进行混洗,排序并选择内存密集程度最低的租户与 DDIO 共享 LLC 路,从而可以避免内核和 I/O 之间的性能干扰(即潜在竞争者问题)减少。
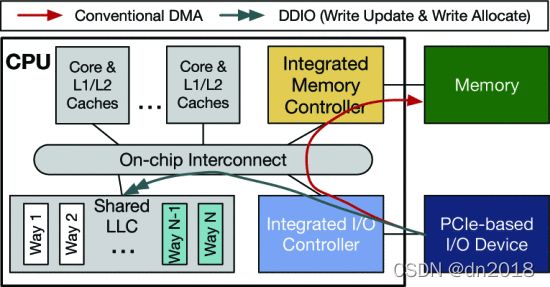
Fig 1
Typical cache organization in modern server CPU, conventional DMA path, and DDIO for I/O device.
图1 现代服务器 CPU 中的典型缓存组织、传统 DMA 路径和 I/O 设备的 DDIO
We develop Iat as a user-space daemon in Linux and evaluate it on a commodity server with high-bandwidth NICs. Our results with both microbenchmarks and real applications show that compared to a case running a single workload, applying Iat in co-running scenarios can restrict the performance degradation of both networking and non-networking applications to less than 10%, while without Iat, such degradation can be as high as ~30%.
我们将 Iat 开发为 Linux 中的用户空间守护进程,并在具有高带宽 NIC 的商品服务器上对其进行评估。我们对微基准测试和实际应用程序的结果表明,与运行单个工作负载的情况相比,在联合运行场景中应用 Iat 可以将联网和非联网应用程序的性能下降限制在 10% 以下,而没有 Iat,例如降解率可高达~30%。
为了促进未来与 DDIO 相关的研究,我们在https://github.com/FAST-UIUC/iat-pqos 上公开了具有 DDIO 功能的增强型 RDT 库 (pqos) 。
background
A. Managing LLC in Modern Server CPU
As studied by prior research [39], [49], sharing LLC can cause performance interference among the collocated VM/containers. This motivates the practice of LLC monitoring and partitioning on modern server CPUs. Since the Xeon® E5 v3 generation, Intel began to provide RDT [28] for resource management in the memory hierarchy. In RDT, Cache Monitoring Technology (CMT) provides the ability to monitor the LLC utilization by different cores; Cache Allocation Technology (CAT) can assign LLC ways to different cores (and thus different tenants) [22]1. Programmers can leverage these techniques by simply accessing corresponding Model-Specific Registers (MSRs) or using high-level libraries [32]. Furthermore, dynamic mechanisms can be built atop RDT [11], [42], [57], [61], [66], [73], [74].
A. 在现代服务器 CPU 中管理 LLC
正如之前的研究[39]、[49]所研究的那样,共享 LLC 会导致并置的 VM/容器之间的性能干扰。这激发了在现代服务器 CPU 上进行 LLC 监控和分区的做法。从至强® E5 v3 代开始,英特尔开始提供 RDT [28]用于内存层次结构中的资源管理。在 RDT 中,缓存监控技术 (CMT) 提供了监控不同内核对 LLC 利用率的能力;缓存分配技术 (CAT) 可以将 LLC 方式分配给不同的内核(以及不同的租户)[22] 1。程序员可以通过简单地访问相应的模型特定寄存器 (MSR) 或使用高级库来利用这些技术[32]. 此外,动态机制可以建立在 RDT [11]、[42]、[57]、[61]、[66]、[73]、[74]之上。
[39] H. Kasture and D. Sanchez, “Ubik: Efficient cache sharing with strict QoS for latency-critical workloads,” ASPLOS’14
[49] J. Mars, L. Tang, R. Hundt, K. Skadron, and M. L. Soffa,“Bubble-up: Increasing utilization in modern warehouse scale computers via sensible co-locations,” in Proceedings of the
44th IEEE/ACM International Symposium on Microarchitecture
(MICRO’11), Porto Alegre, Brazil, Dec. 2011.
[11] KPart: A hybrid cache partitioning-sharing technique for commodity multicores HPCA’18
[42] CuttleSys:Data-driven resource management for interactive services
on reconfigurable multicores,” in Proceedings of the 53rd IEEE/ACM International Symposium on Microarchitecture (MICRO’20), Virtual Event, Oct. 2020.
[57] J. Park, S. Park, and W. Baek, “CoPart: Coordinated partitioning of last-level cache and memory bandwidth for fairness-aware workload consolidation on commodity servers,
EuroSys’19
[61] FIRM: An intelligent fine-grained resource management framework for SLO-oriented microservices, OSDI’20
[66] Application clustering policies to address system fairness with Intel’s cache allocation technology,” in Proceedings of the 26th International Conference on Parallel Architectures and
Compilation Techniques (PACT’17), Portland, OR, Nov. 2017.
[73] DCAPS: Dynamic cache allocation with partial sharing,(EuroSys’18),
[74] dCat: Dynamic cache management for efficient, performance sensitive infrastructure-as-a-service,(EuroSys’18)
B. 数据直接 I/O 技术
Conventionally, direct memory access (DMA) operations from a PCIe device use memory as the destination. That is, when being transferred from the device to the host, the data will be written to the memory with addresses designated by the device driver, as demonstrated in Fig. 1. Later, when the CPU core has been informed about the completed transfer, it will fetch the data from the memory to the cache hierarchy for future processing. However, due to the dramatic bandwidth increase of the I/O devices over the past decades, two drawbacks of such a DMA scheme became salient: (1) Accessing memory is relatively time-consuming, which can potentially limit the performance of data processing. Suppose we have 100Gb inbound network traffic. For a 64B packet with 20B Ethernet overhead, the packet arrival rate is 148.8 Mpps. This means any component on the I/O path, like I/O controller or core, has to spend no more than 6.7ns on each packet, or packet loss will occur. (2) It consumes much memory bandwidth. Again with 100Gb inbound traffic, for each packet, it will be written to and read from memory at least once, which easily leads to 100Gb/s×2=25GB/s memory bandwidth consumption.
通常,来自 PCIe 设备的直接内存访问 (DMA) 操作使用内存作为目的地。也就是说,当从设备传输到主机时,数据将写入设备驱动程序指定地址的内存中,如图1所示. 稍后,当 CPU 内核被告知传输完成时,它会将数据从内存中提取到缓存层次结构中以备将来处理。然而,由于过去几十年 I/O 设备的带宽急剧增加,这种 DMA 方案的两个缺点变得突出:(1) 访问内存相对耗时,这可能会限制数据处理的性能。假设我们有 100Gb 的入站网络流量。对于具有 20B 以太网开销的 64B 数据包,数据包到达率为 148.8 Mpps。这意味着 I/O 路径上的任何组件,如 I/O 控制器或内核,必须在每个数据包上花费不超过 6.7ns,否则将发生数据包丢失。(2) 占用大量内存带宽。再次使用 100Gb 入站流量,对于每个数据包,它将至少写入和读取一次内存,Gb/s× 2=25 GB/s内存带宽消耗。
To relieve the burden of memory, Intel proposed Direct Cache Access (DCA) technique [23], allowing the device to write data directly to CPU’s LLC. In modern Intel® Xeon® CPUs, this has been implemented as Data Direct I/O Technology (DDIO) [31], which is transparent to the software. Specifically, as shown in Fig. 1, when the CPU receives data from the device, an LLC lookup will be performed to check if the cacheline with the corresponding address is present with a valid state. If so, this cacheline will be updated with the inbound data (i.e., write update). If not, the inbound data will be allocated to the LLC (i.e., write allocate), and dirty cachelines may be evicted to the memory. By default, DDIO can only perform write allocate on two LLC ways (i.e., Way N−1 and Way N in Fig. 1). Similarly, with DDIO, a device can directly read data from the LLC; if the data is not present, the device will read it from the memory but not allocate it in the LLC. Prior comprehensive studies [1], [36], [44] show that in most cases (except for those with persistent DIMM), compared to the DDIO-disabled system, enabling DDIO on the same system can improve the application performance by cutting the memory access latency and reducing memory bandwidth consumption. Note that even if DDIO is disabled, inbound data will still be in the cache at first (and immediately evicted to the memory). This is a performance consideration since after getting into the coherence domain (i.e., cache), read/write operations with no dependency can be performed out-of-order.
Although DDIO is Intel-specific, other CPUs may have similar concepts (e.g., ARM’s Cache Stashing [5]). Most discussions in this paper are also applicable to them.
为了减轻内存负担,Intel 提出了直接缓存访问 (DCA) 技术[23],允许设备直接将数据写入 CPU 的 LLC。在现代英特尔®至强® CPU 中,这已作为数据直接 I/O 技术 (DDIO) [31] 实现,这对软件是透明的。具体地,如图1所示,当CPU从设备接收数据时,将执行LLC查找以检查具有对应地址的cacheline是否存在且处于有效状态。如果是这样,这个缓存行将用入站数据更新(即,写更新 write update)。如果没有,入站数据将分配给 LLC(即,写分配 write allocate),脏的缓存行可能会被驱逐到内存中。
By default, DDIO can only perform write allocate on two LLC ways (i.e., Way N−1 and Way N in Fig. 1). 默认情况下,DDIO只能执行写分配 write allocate 在两个LLC way。
(同样,通过DDIO,设备可以直接从LLC读取数据;如果数据不存在,设备将从内存中读取它,但不会在 LLC 中分配它。先前的综合研究[1] , [36] , [44]表明在大多数情况下(除了那些具有持久性 DIMM 的情况),与禁用 DDIO 的系统相比,在同一系统上启用 DDIO 可以通过减少内存访问延迟和减少内存带宽消耗来提高应用程序性能。请注意,即使 DDIO 被禁用,入站数据最初仍将在缓存中(并立即被驱逐到内存中)。这是一个性能考虑,因为在进入一致性域(即缓存)之后,可以无序执行没有依赖性的读/写操作( read/write operations with no dependency can be performed out-of-order)。
尽管 DDIO 是 Intel 特定的,但其他 CPU 可能具有类似的概念(例如,ARM 的缓存存储[5])。本文中的大多数讨论也适用于它们。
[1] Data direct I/O characterization for future I/O systemexploration,” in Proceedings of the 2020 IEEE International Symposium on Performance Analysis of Systems and Software
(ISPASS’20), Virtual Event, Aug. 2020.
[36] Challenges and solutions for fast remote persistent memory access,” in Proceedings of the 11th ACM Symposium on Cloud Computing (SoCC’20), Virtual Event, Oct. 2020.
[44] M. Kurth, B. Gras, D. Andriesse, C. Giuffrida, H. Bos, and K. Razavi, “NetCAT: Practical cache attacks from the network,” in Proceedings of the 41st IEEE Symposium on Security and
Privacy (Oakland’20), Virtual Event, May 2020.
C. 虚拟化服务器中的租户-设备交互
Modern data centers adopt two popular models to organize the I/O devices in multi-tenant virtualized servers with different trade-offs. As shown in Fig. 2, the key difference is the way they interact with the physical device.
现代数据中心采用两种流行的模型来组织具有不同权衡的多租户虚拟化服务器中的 I/O 设备。如图2所示,主要区别在于它们与物理设备交互的方式。

在第一个模型中,为 I/O 设备交互部署了逻辑集中的软件堆栈。它可以在操作系统、管理程序甚至用户空间中运行。例如,已经为 NIC 开发了兼容 SDN 的虚拟交换机,例如 Open vSwitch (OVS) [60]和 VFP [15]。关于 SSD,SPDK [75]是一个高性能和可扩展的用户空间堆栈。如图2a 所示,软件堆栈控制物理设备并向其发送/接收数据包。租户通过 virtio [64]等接口连接到设备。由于此模型中的所有流量都需要经过软件堆栈,因此我们称此模型为“聚合”。
在第二个模型(图 2b)中,利用了基于硬件的单根输入/输出虚拟化 (SR-IOV) 技术[10]。使用 SR-IOV,可以将单个物理设备虚拟化为多个虚拟功能 (VF)。虽然物理功能 (PF) 仍然连接到主机操作系统/管理程序,但我们可以将 VF 直接绑定到租户(即主机旁路)。换句话说,基本的交换功能被卸载到硬件上,每个租户直接与物理设备对话以进行数据接收和传输。由于该模型将硬件资源进行分解,分配给不同的租户,因此也称为“切片”。请注意,许多用于多租户的硬件卸载解决方案[16]、[45], [52]本质上可以被视为切片模型。
[16] Azure accelerated networking: SmartNICs in the public cloud,(NSDI’18)
[45] FVM: FPGA-assisted virtual device emulation for fast, scalable, and flexible storage
virtualization, (OSDI’20),
[52] NETRONOME, “Agilio OVS software,” https://www.netronome.com/products/agilio-software/agilioovs-software/, accessed in 2021.
动机:I/O 对 LLC 的影响
Motivation: The Impact of I/O on LLC
A. DMA 泄漏问题
A. The Leaky DMA Problem
多篇论文[18]、[54]、[56]、[69]已经观察到“Leaky DMA”问题。也就是说,由于默认情况下,DDIO 的写分配只有两种 LLC ways,当入站数据速率(例如, NIC Rx rate) 高于 CPU 内核可以处理的速率,LLC 中等待处理的数据很可能 (1) 被新传入的数据驱逐到内存中,以及 (2) 稍后被带回当核心需要它时再次使用 LLC。这对于大数据包尤其重要,因为在传输中数据包数量相同的情况下,较大的数据包比较小的数据包消耗更多的缓存空间。因此,这会导致额外的内存读/写带宽消耗并增加每个数据包的处理延迟,最终导致性能下降。
The “Leaky DMA” problem has been observed by multiple papers [18], [54], [56], [69]. That is, since, by default, there are only two LLC ways for DDIO’s write allocate, when the inbound data rate (e.g., NIC Rx rate) is higher than the rate that CPU cores can process, the data in LLC waiting to be processed is likely to
(1) be evicted to the memory by the newly incoming data,
and (2) later be brought back to the LLC again when a core needs it.
This is especially significant for large packets as with the same in-flight packet count, larger packets consume more cache space than smaller packets. Hence, this incurs extra memory read/write bandwidth consumption and increases the processing latency of each packet, eventually leading to a performance drop.
[18] “Software data planes: You can’t always spin to win,” in Proceedings of the ACM Symposium on Cloud Computing (SoCC’19)
[54] “Understanding PCIe performance for end host networking,” (SIGCOMM’18)
[56] “Shenango: Achieving high CPU efficiency for latency-sensitive datacenter workloads,” (NSDI’19)
[69] ResQ: Enabling SLOs in network function virtualization (NSDI’18),
在 ResQ [69] 中,作者建议通过减少 Rx/Tx 缓冲区的大小来解决这个问题。但是,这种变通方法有缺点。在云环境中,数十甚至数百个虚拟机/容器可以通过虚拟化堆栈共享几个物理端口[24],[47]. 如果所有缓冲区中的条目总数保持在默认 DDIO 的 LLC 容量以下,则每个 VM/容器只会获得一个非常浅的缓冲区。例如,在 SR-IOV 设置中,我们有 20 个容器,每个容器都分配了一个虚拟功能来接收流量。为保证所有缓冲区都可以容纳在默认的 DDIO 的缓存容量(几 MB)中,每个缓冲区只能有少量的条目。浅 Rx/Tx 缓冲区会导致严重的丢包问题,尤其是当我们有突发流量时,这在现代云服务中无处不在[4]。因此,虽然此设置可能适用于静态平衡流量,但具有某些“重击者”容器的动态不平衡流量将导致性能下降。
In ResQ [69], the authors propose to solve this problem by reducing the size of the Rx/Tx buffers. However, this workaround has drawbacks. In a cloud environment, tens or even hundreds of VMs/containers can share a couple of physical ports through the virtualization stack [24], [47]. If the total count of entries in all buffers is maintained below the default DDIO’s LLC capacity, each VM/container only gets a very shallow buffer. For example, in an SR-IOV setup, we have 20 containers, each assigned a virtual function to receive traffic. To guarantee all buffers can be accommodated in the default DDIO’s cache capacity (several MB), each buffer can only have a small number of entries. A shallow Rx/Tx buffer can lead to severe packet drop issues, especially when we have bursty traffic, which is ubiquitous in modern cloud services [4]. Hence, while this setting may work with statically balanced traffic, dynamically imbalanced traffic with certain “heavy hitter” container(s) will incur a performance drop.
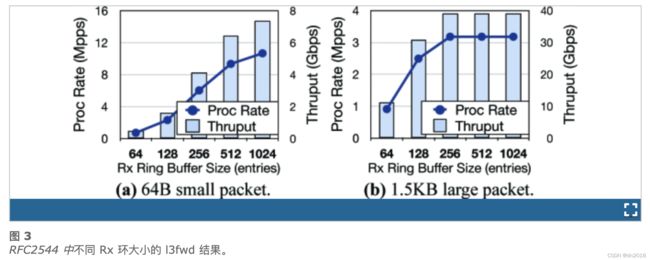
在这里,我们运行了一个简单的实验来证明这种低效率(有关我们设置的详细信息,请参见第 VI-A 节)。我们在测试台的单个核心上设置了 DPDK l3fwd应用程序以进行流量路由。它根据 1M 流的流表(以模拟实际流量)查看每个网络数据包的标头。如果找到匹配项,则转发数据包。我们从具有小 (64B) 或大 (1.5KB) 数据包的流量生成器机器运行 RFC2544 测试[53](即,测量零丢包时的最大吞吐量)。从图3的结果中,我们观察到对于大数据包的情况(图 3b),缩小 Rx 缓冲区大小可能不是问题——吞吐量不会下降,直到大小为典型值的 1/8。然而,小数据包的情况则完全不同(图 3a)——通过将缓冲区大小减少一半(从 1024 到 512),最大吞吐量可以下降 13%。如果我们使用 64 个条目的小缓冲区,吞吐量不到原始吞吐量的 10%。在这两种情况之间,关键因素是数据包处理速率。使用更高的速率,小数据包流量往往会更密集地压迫 CPU 内核(即更少的空闲和忙碌轮询时间)。结果,任何倾斜都会导致Rx缓冲区中的生产者-消费者不平衡,浅缓冲区更容易溢出(即,丢包)。因此,调整缓冲区大小并不是解决现实世界中复合和动态变化的流量的灵丹妙药。这促使我们不仅要调整缓冲区的大小,还要自适应地调整 DDIO 的 LLC 容量。
Here we run a simple experiment to demonstrate such inefficiency (see Sec. VI-A for details of our setup). We set up DPDK l3fwd application on a single core of the testbed for traffic routing. It looks at the header of each network packet up against a flow table of 1M flows (to emulate real traffic). The packet is forwarded if a match is found. We run an RFC2544 test [53] (i.e., measure the maximum throughput when there is zero packet drop) from a traffic generator machine with small (64B) or large (1.5KB) packets. From the results in Fig. 3, we observe that for the large-packet case (Fig. 3b), shrinking Rx buffer size may not be a problem – the throughput does not drop until the size is 1/8 of the typical value. However, the small-packet case is in a totally different situation (Fig. 3a) – by cutting half the buffer size (from 1024 to 512), the maximum throughput can drop by 13%. If we use a small buffer of 64 entries, the throughput is less than 10% of the original throughput. Between these two cases, the key factor is the packet processing rate. With a higher rate, small-packet traffic tends to press the CPU core more intensively (i.e., less idle and busy polling time). As a result, any skew will lead to a producer-consumer imbalance in the Rx buffer, and a shallow buffer is easier to overflow (i.e., packet drop). Hence, sizing the buffer is not a panacea for compound and dynamically changing traffic in the real world. This motivates us not merely to size the buffer but also to tune the DDIO’s LLC capacity adaptively.
B. 潜在竞争者问题
我们确定了由 DDIO 引起的第二个问题——“潜在竞争者”问题。也就是说,由于大多数当前的 LLC 管理机制是 I/O-unaware,当使用 CAT 为不同的内核分配 LLC 方式时,它们可能会无意识地将 DDIO 的 LLC 方式分配给某些运行 LLC 敏感工作负载的内核。这意味着,即使这些 LLC 方式从核心的角度来看是完全隔离的,但 DDIO 实际上仍在与核心竞争容量。
我们运行另一个实验来进一步证明这个问题。在这个实验中,我们首先设置了一个容器,绑定到一个 CPU 内核、两种 LLC 方式(即方式 0 - 1)和一个 NIC VF。该容器正在运行 DPDK l3fwd,流量为 40Gb。然后我们设置另一个容器,它在另一个核心上运行。