推荐系统之深度兴趣网络DIN
深度学习推荐模型演化
推荐系统和计算广告领域进入深度学习时代后,相比传统推荐模型在以下两方面取得了重大进展:
(1) 与传统机器学习相比,深度学习模型的表达能力更强,能够挖掘出更多数据中潜藏的模式。
(2) 深度学习的模型结构非常灵活,能够根据业务场景和数据特点,灵活调整模型结构,使模型与应用场景完美契合。
深度学习推荐模型的演化图谱如下所示,以多层感知机MLP为核心,通过改变神经网络的结构,构建特点各异的深度学习推荐模型。
p.s. 本图改自王喆大佬的《深度学习推荐系统》,虽然我第一时间拿到了书,翻了翻也不得不承认,“读书,你就OUT了”。王喆选取的模型标准是经典且在头部公司有成功应用,比如阿里的DIN、DIEN,但同为阿里的DSIN、TDM、ESMM却没入选,可能由于成书时间关系或尚未在实际中全量应用。CS的前沿动态还是在会议paper中,但顶会每年千余篇的paper着实令人眼花缭乱。
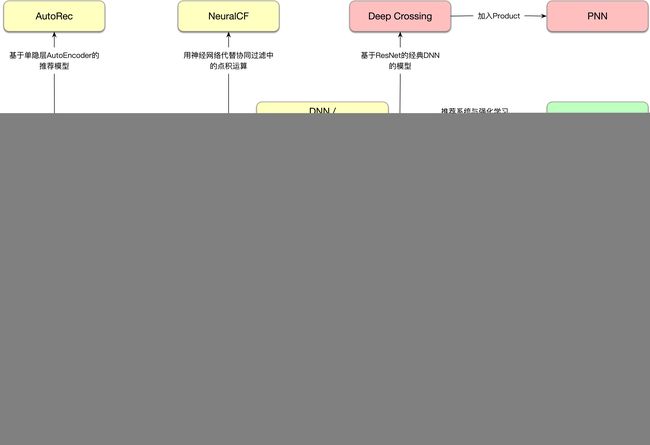
深度兴趣网络DIN
DIN 简介
深度兴趣网络(Deep Interest Network,DIN)是阿里妈妈精准定向广告团队在KDD 2018提出的针对电商场景下深入理解用户兴趣的CTR模型。DIN模型的核心在于将Attention机制与传统的Embedding&MLP模型结合起来,虽然Attention机制在CV和NLP领域取得了巨大成功,但成功将Attention机制引入CTR预估领域得力于阿里工程师对电商业务的精准理解。
通过对用户行为数据的分析,阿里发现用户兴趣具有两个重要的特性:
- Diversity : 一个用户可能多种品类的商品感兴趣
- Local Activation : 由于用户兴趣的多样性,只有部分历史数据会对当前商品的点击预测有帮助,而不是所有的历史数据。
传统Embedding&MLP范式如下:首先通过embedding layer将大规模的稀疏特征投影为低维连续的embedding vector,然后将这些向量concatenate后输入到一个全连接网络中,计算其最终的预估目标。在电商场景下,要做到精确的预估必须充分挖掘用户的历史行为来理解用户的兴趣。而一个用户会同时存在对不同的商品都有潜在的兴趣,这同样会反映在用户的历史行为里。传统的Embedding&MLP模型用一个固定的向量来表达一个用户,不足以刻画用户兴趣的多样性,即用户可能同时对多个商品感兴趣。
固定用户向量 V u V_u Vu的维度限制了整体模型解空间的秩,而向量的维度受算力以及泛化性的限制不可能无限扩充,因此阿里提出用一个根据预估目标动态变化的向量来表达用户。具体来说,预测一个用户 U s e r i User_i Useri对目标 I t e m i Item_i Itemi的点击率,并不需要 V u V_u Vu表达用户的所有兴趣,而只需要表达该用户和 I t e m i Item_i Itemi相关的兴趣。比如目标广告商品是键盘,用户的历史点击序列中有鼠标、洗面奶和T恤,从常识来看,鼠标对于预测键盘的点击率的重要性要大于后两者;从模型角度说,建模过程中鼠标特征的“注意力”应该大于后两者。
因此阿里通过引入Attention机制来捕捉针对不同商品时用户不同的兴趣状态,并用一个根据不同的预估商品目标来动态变换的 V u V_u Vu来表达用户与之相关的兴趣。
DIN 模型架构

DIN的模型结构如图所示,通过一个兴趣激活模块(Activation Unit),用预估目标Candidate Ad的信息来激活用户的历史点击商品,以此提取用户与当前预估目标相关的兴趣。权重高的历史行为表明这部分兴趣与当前广告相关,权重低的则是和广告无关的“兴趣噪声”。通过将激活的商品和激活权重相乘,然后累加起来作为当前预估目标Ad的兴趣状态表达。最后将相关的用户兴趣表达、用户静态特征和上下文相关特征,以及Ad相关的特征拼接起来,输入到后续的多层DNN网络,最后预测得到用户对当前目标Ad的点击概率。
Attention 机制
Attention机制简单的理解就是对于不同的特征有不同的权重,这样某些特征就会主导这一次的预测,就好像模型对某些特征pay attention。但是,DIN中并不能直接用attention机制。因为对于不同的候选广告,用户兴趣表示(embedding vector)应该是不同的。
用户的兴趣不再是一个点,而是一个多峰的函数。一个峰就表示一个兴趣,峰值的大小表示兴趣强度。那么针对不同的候选广告,用户的兴趣强度是不同的,也就是说随着候选广告的变化,用户的兴趣强度不断在变化。
在DIN模型中,针对不同Candidate Ad需要自适应地调整User Representation,也就是在Embedding Layer -> Pooling Layer得到用户的兴趣表示的时候,赋予不同的历史行为不同的权重,实现局部激活。从最终反向训练的角度看,就是根据当前的Candidate Ad,来反向激活用户历史的兴趣爱好,赋予不同的历史行为不同的权重。从在数学形式上来看,注意力机制只是将过去的平均操作或加和操作替换成加权和或者加权平均操作。
DIN中兴趣激活模块根据预估目标对历史行为预测的相关权重,黄色能量条的长度越长表明其激活权重越高,和预估目标更相关。可以看到直观上和此次的预估目标羽绒服相关的商品都获得了相对较高的权重。
Dice激活函数
PRelu又叫Leaky Relu,和Relu激活函数都是一个阶跃函数,存在的相同问题是分割点都是0,意味着面对不同的输入这个变化点是不变的,而实际中神经元的输出分布是不同的,分割点应该由数据决定。因此阿里提出Dice(Data Adaptive Activation Function)激活函数,通过统计神经元输出的均值和方差来描述数据的分布。Dice的控制器会根据数据的分布自适应地调整,整体的学习和表达能力都会得到提高。

DIN 可视化

上图展示了用户兴趣分布:颜色越暖表示用户兴趣越高,可以看到用户的兴趣分布有多个峰。
总结
- 用户的兴趣具有Diversity,点击了多个商品/店铺后,通过Pooling对Embedding Vector求和或者平均会损失很多信息,因此引入Attention机制,通过Local Activation针对不同的behavior ID赋予不同的权重,这个权重是由当前behavior ID和Candidate Ad共同决定的。
- DIN使用Activation Unit来捕获Local Activation的特征,使用Weighted Sum Pooling来捕获Diversity的结构。
- 在模型优化上,DIN提出了Dice激活函数以及自适应正则,显著提升了模型性能和收敛速度。
Reference
- CTR预估–阿里Deep Interest Network
- 探秘阿里之深度兴趣网络(DIN)浅析及实现
- 深度兴趣网络(DIN)
- CCF-GAIR 2017 全球人工智能与机器人峰会