推荐算法(十)——阿里深度兴趣进化网络 DIEN
目录
-
- 1 介绍
- 2 原理
-
- 2.1 Behavior Layer
- 2.2 Interest Extractor Layer
- 2.3 Interest Evolving Layer
- 2.4 auxiliary loss
- 3 实验
- 4 总结
- 写在最后
1 介绍
本文为 推荐系统专栏 的第十篇文章,也是阿里三部曲 DIN、DIEN、DSIN中的第二篇。
上篇文章介绍的 DIN,通过引入 Attention Layer 赋予用户行为不同的重要性权重,但却忽略了行为发生的时间顺序。
本篇的深度兴趣进化网络 DIEN,就是针对行为的时间顺序进行建模,挖掘用户的兴趣及兴趣变化趋势。

论文传送门:Deep Interest Evolution Network for Click-Through Rate Prediction
2 原理
跟 DIN 相同,DIEN 的创新主要集中在用户行为序列的建模上。模型结构如下:

模型结构复杂,下面将三种 Layer 拆开来讲。
2.1 Behavior Layer
嵌入层,对行为序列中的每个 item 进行嵌入,得到稠密向量表示 e(i)。除此之外,其他三组特征:候选item、上下文特征、用户画像特征,同样需要进行嵌入,不做过多解释。
2.2 Interest Extractor Layer
兴趣提取层,该层使用 GRU 来挖掘行为被点击的时序信息,输入为嵌入之后的行为序列 e(i),每时刻都会输出一个隐状态 h(i),表示 i 时刻用户的兴趣表示。
GRU 单元的计算公式如下,不是本文介绍的重点,不做过多解释。
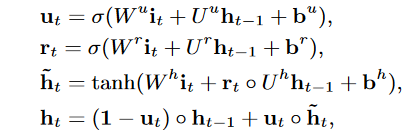
使用 GRU 能够挖掘到时序信息,但又丢弃了 DIN 引入的注意力机制,所以 DIEN 又加了第二层 GRU,并将 Attention 融入其中。
2.3 Interest Evolving Layer
兴趣变化提取层,该层为 GRU + Attention 的组合层,输入来自上层 GRU 输出的隐状态序列,输出只有最后一个 GRU 单元的隐状态 h(T),表示的是从每时刻的用户兴趣中提取的兴趣变化趋势。
Attention 权重的计算公式:
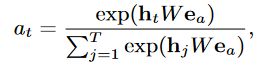
图中粉色区域的每个 Attention 单元输入包含两部分:h(i) 与 Target Ad 向量,即公式中的 h t h_{t} ht 和 e a e_{a} ea, W W W 为记忆矩阵,通过学习得到。
该单元采用内积注意力的方式,为每个时刻的 h(i) 计算得到一个权重 a i a_{i} ai,权重与 h(i) 结合的方式有三种,下面展开介绍:
1> GRU with attentional input (AIGRU)
![]()
直接将每时刻的隐状态 h t h_{t} ht 与对应的权重 a t a_{t} at 相乘,得到新的隐状态 i t ′ i_{t}^{'} it′,然后再输入 GRU 单元。该方式比较简单,无需修改 GRU 单元的结构。
2> Attention based GRU(AGRU)
![]()
用权重 a t a_{t} at 替换 GRU 单元中的更新门 u t u_{t} ut,权重越大,当前时刻隐状态保留的信息就越多,之前的信息遗忘的也越多,该方式需要修改 GRU 单元内部的计算方式。
3> GRU with attentional update gate (AUGRU)

将权重 a t a_{t} at 乘到更新门 u t u_{t} ut 上,然后再用更新门控制当前信息与历史信息保留的比例。该方式同样需要修改 GRU 单元的计算方式。
以上三种方式都达到了同一个目的:给与权重大的隐状态更多的关注。
2.4 auxiliary loss
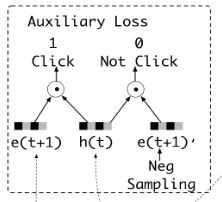
GRU 层存在两个问题,一是在长序列场景中难以充分训练,二是 hidden states 缺少监督,只有最后时刻的隐状态上会产生 loss。
针对这两个问题,文中提出了辅助 loss 计算方法,并将其应用在了第一层 GRU 上。如上图所示,e(t+1) 是在 t+1 时刻用户点击的 item,h(t) 是 t 时刻 GRU 输出的隐状态,e(t+1)’ 是负采样得到的没有被点击的 item。
这样就转换成了判断是否点击的二分类问题,按照下式计算 loss 即可。

模型整体的 loss 如下, α \alpha α 为超参数,模型要想降低整体的 loss,就会把第一层 GRU 拟合的更好一些。
![]()
3 实验
与其他经典模型的对比实验:

三种融合方式的对比实验:
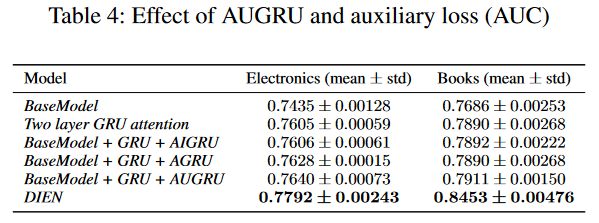
4 总结
优点:
- 引入 GRU 层,挖掘用户兴趣的同时,引入了行为发生的时序信息;
- 引入 GRU 与 Attention 融合层,挖掘用户的兴趣变化趋势。
缺点:
- GRU 层难以训练充分,模型并行性较差,给模型上线带来压力;
- 模型训练复杂度随着行为序列长度的增加而增长。
写在最后
下一篇预告: 推荐算法(十一)——阿里深度会话兴趣网络 DSIN
推荐算法Github 仓库:
Recommend-System-tf2.0
希望看完此文的你,能够有所收获!