PyTorch深度学习实践概论笔记5-用pytorch实现线性回归
上一讲PyTorch深度学习实践概论笔记4-反向传播介绍了反向传播算法。现在来看第5讲:用pytorch实现线性回归。主要会介绍nn.Module,如何构造自己的神经网络;如何构造loss函数;以及如何构造sgd优化器。

0 Revision
回顾之前的课程,解决问题的步骤是构造模型、损失函数和优化器。
1 PyTorch Fashion
1.1 pytorch版本流程
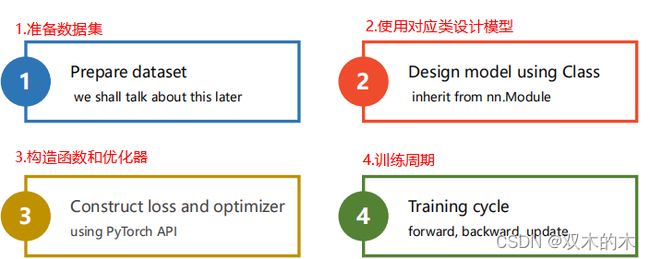
pytorch框架下的深度学习流程主要为以下四步:
- 准备数据集
- 设计模型
- 构造函数和优化器
- 训练周期
1.2 Example
1.2.1 Linear Regression-1.prepare dataset
在这个数据集要使用mini-batch的风格,因为只有3个数据,所以都放进去。模型是y=w*x+b。

由于X和Y必须是矩阵,构造代码如下:
import torch
#构建数据集
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])1.2.2 Linear Regression-2.design model
之前我们的重点是定义Loss函数,现在的重点是构造计算图。把z=w*x+b称为线性单元(Linear unit)。

注意:对于loss而言必须是标量,所以需要求和,是否求均值视情况而定(如果是向量,无法使用backward)。
代码分析:
#我们的模型类继承于nn.Module
class LinearModel(torch.nn.Module):
def __init__(self):#构造函数,初始化对象时默认调用的函数
#重写了__init__,要继承父类的构造
super(LinearModel, self).__init__() #调用父类的构造,直接写
#nn.Linear类包含两个成员张量:weight和bias
#Linear类也是继承自Module,可以自动进行反向传播
self.linear = torch.nn.Linear(1, 1) #类后面加括号-构造对象
def forward(self, x):
y_pred = self.linear(x)#对象后面加括号-实现了一个__call__(),可调用的对象
return y_pred
#创建一个LinearModel实例
model = LinearModel() #注意这个model是可调用的,callable。python里的Functions也是一个类。
查看Linear源码

上述self.linear = torch.nn.Linear(1, 1)的(1,1)就是对于参数in_features和out_features:

注意一个细节:y_pred = self.linear(x),在对象后面加括号实现一个可调用对象。

在Module类的__call__()就是调用forward()。
1.2.3 Linear Regression-3.Construct Loss and Optimizer
第3步是构造损失函数和优化器。
损失函数:

优化器:

代码如下:
criterion = torch.nn.MSELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) #SGD类的实例化torch.nn.MSELoss类也继承于nn.Module类,参数有size_average=True(是否求均值,当N大小一样时,如果大家都不求,效果是一样的)和reduce=True(最终是否要进行降维,就是是否要求和)。
1.2.4 Linear Regression-4.Training Cycle
for epoch in range(100):
y_pred = model(x_data)#forward:预测
loss = criterion(y_pred, y_data)#forward:loss
print(epoch, loss) #打印loss时会自动调用__str__()函数,不会产生计算图,这是安全的
optimizer.zero_grad()#注意.backward()时梯度会被累计,注意所有的权重设为0
loss.backward()#反向传播:autograd
optimizer.step()#update,根据梯度和设好的学习率进行更新训练过程完成了forward(算y hat和loss),backward和update。
1.2.5 Linear Regression-Test Model

看到100次迭代时,w和b没有到达最理想值,说明训练还没收敛。于是进行1000次迭代,效果更好。
下面是测试代码详解:
#输出权重w和偏差b
print('w = ', model.linear.weight.item()) #打印时选item,不然w是一个矩阵
print('b = ', model.linear.bias.item())
# 测试模型
x_test = torch.Tensor([[4.0]]) #输入1*1矩阵
y_test = model(x_test) #输出1*1矩阵
print('y_pred = ', y_test.data)总结整个过程:
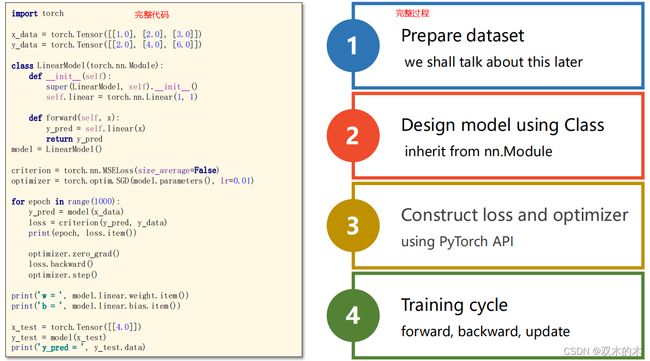
完整代码:
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = self.linear(x)
return y_pred
model = LinearModel()
criterion = torch.nn.MSELoss(size_average=False)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(1000):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print("epoch:",epoch,"loss:",loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("**************test***************")
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
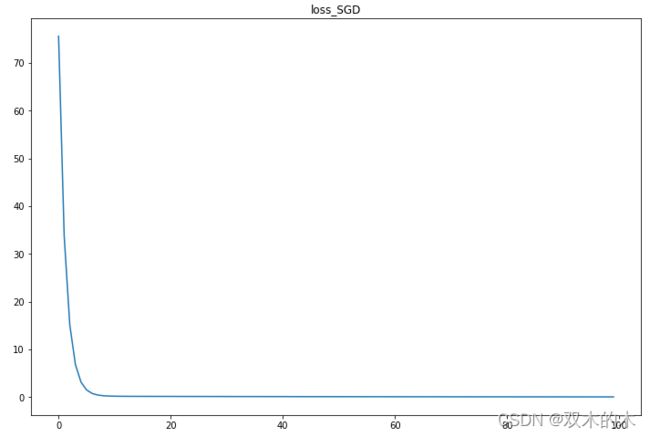
print('when x = 4, y_pred = ',y_test.data)我自己运行的结果如下:

我的结果和老师的略有不同。画迭代过程的loss图如下:
2 Exercise
2.1Try different optimizer in linear regression
在线性回归尝试不同的优化器
• torch.optim.Adagrad
• torch.optim.Adam
• torch.optim.Adamax
• torch.optim.ASGD
• torch.optim.LBFGS #error,解决中
• torch.optim.RMSprop
• torch.optim.Rprop
• torch.optim.SGD
不同优化器得到的损失,画个图,进行比较。先随意选取SGD和Adagrad的对比图(迭代2000次):
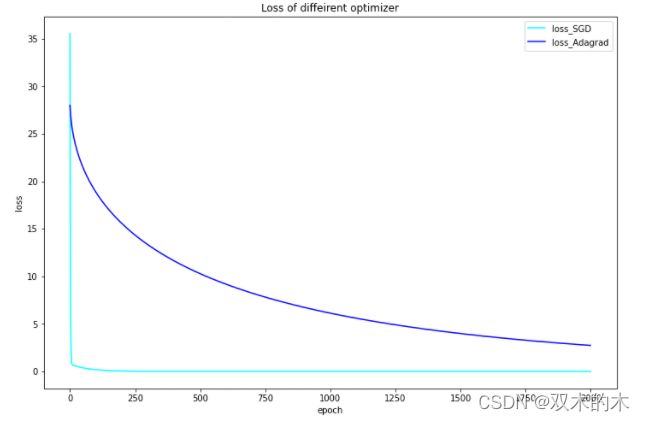
上图我们发现SGD很快收敛,而Adagrad迭代2000次之后都没有收敛,下面增加迭代次数,迭代5000次。
接下来针对不同的优化器的对比图如下(迭代5000次):

上图表明:迭代5000次之后,除了Adagrad优化器,其他优化方法均收敛,loss无限接近0。接着,为了看清楚前期的对比图,迭代1000次:

上图只能明显区分Adagrad。接着,为了看清楚前期的对比图,迭代200次:
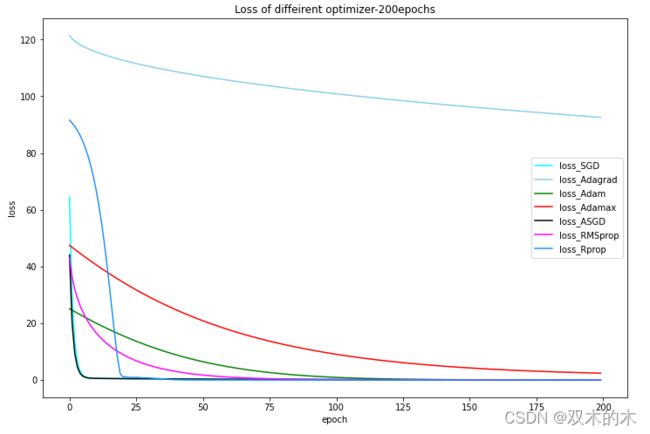
上图只能明显区分Adagrad和Adamax。接着,为了看清楚前期的对比图,继续迭代50次:
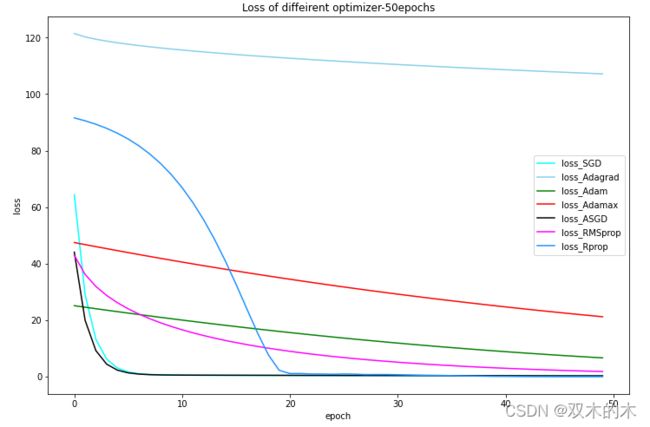
50次迭代的结果就比较清晰了。上图表明:通过50次迭代,ASGD的起始loss50不到,而且很快的收敛到0。同样,SGD也很快收敛到0。RMSprop的起始点和ASGD差不多,不过收敛速度慢一些,50次没有但200次收敛。
上图50次的画图代码如下:
import matplotlib.pyplot as plt
import numpy as np
fig = plt.figure(figsize=(12, 8))
x = np.arange(50)
plt.plot(x,loss_SGD[:50],color = 'cyan',label="loss_SGD")
plt.plot(x,loss_Adagrad[:50],color = 'skyblue',label="loss_Adagrad")
plt.plot(x,loss_Adam[:50],color = 'green',label="loss_Adam")
plt.plot(x,loss_Adamax[:50],color = 'red',label="loss_Adamax")
plt.plot(x,loss_ASGD[:50],color = 'black',label="loss_ASGD")
# plt.plot(x,loss_LBFGS,color = 'yellow',label="loss_LBFGS")
plt.plot(x,loss_RMSprop[:50],color = 'magenta',label="loss_RMSprop")
plt.plot(x,loss_Rprop[:50],color = 'dodgerblue',label="loss_Rprop")
plt.legend()#加上图例,显示上面的label
plt.title("Loss of diffeirent optimizer-50epochs")
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()其中,调用 torch.optim.LBFGS优化器报错,解决中。

2.2 Read more example from official tutorial
从官方教程看更多的例子
ref:https://pytorch.org/tutorials/beginner/pytorch_with_examples.html

说明:记录学习笔记,如果错误欢迎指正!写文章不易,转载请联系我。