百分点认知智能实验室:关于预训练模型的介绍
最近要学生学习下预训练模型的使用和发展 写了一篇学习笔记
编者按:自然语言处理(NLP)是AI领域中的一项重要技术,它可以使机器模仿人类的思考方式,以具备阅读、解读且理解人类的语言,从而完成文本分类、情感分析、语音识别等一系列任务。
因此,构建一个NLP应用程序,语言模型是非常关键的,但从头来构建一个复杂的NLP语言模型是一个非常繁琐的任务。如果每次进行一个具体任务前都要重复这一过程,对于个人和企业都是难以接受的。这些问题的存在,也使得AI开发人员和研究人员开始来发展预训练模型(pre-train model),即预先训练一个模型,保留相关的权重参数使其具备一定的先天能力。在面对其他特定任务时,无需从头开始学习,只需要对其进行微调(fine-tune)。从而节省了大量时间和计算资源以构建新的语言模型。
本文主要介绍自然语言处理中的预训练模型的相关概念和基本原理。
本文作者:百分点实习生 邓良聪
1. 背景介绍
自然语言处理(NLP)最早起源于1950年代,艾伦.图灵发表了”Computing Machinery and Intelligence”的文章,并提出了现代称为图灵测试的智能标准。在经历了近70年的发展,NLP经历了基于规则和基于统计的发展阶段,而到了2008年之后,随着深度学习(Deep Learning)的不断发展,各种神经网络也开始广泛应用于解决NLP的任务之中,如卷积神经网络(CNN),递归神经网络(RNN),基于图的神经网络(GNN)等等。
预训练模型一开始是在计算机视觉(CV)领域开始的。而在NLP领域中发展较晚,主要是大多数监督型NLP任务的数据量比较小,深度神经网络通常具有大量参数,很可能导致在这类数据集上产生过拟合,难以推广实践。因此早期NLP的神经模型相对较浅,而在最近,基于大型语料库的预训练模型可以很好的学习语言的通用表达,对于相关的NLP下游任务起到了很大的提升,也避免了从头开始训练语言模型的问题。
最初的预训练模型如Word2vec和Glove等模型,可以完成良好的词嵌入,但这种方式无法捕获到上下文的词义以及句法结构等,在一个句子中,每一个token都是孤立的状态。而随着计算能力的增强和Transformer的出现,当前的预训练模型开始专注于获取上下文的词嵌入,如ELMo、BERT等模型,目前在各类NLP任务也开始得到了广泛的应用并取得了很大的突破。因此,了解这类模型以及其原理是一项非常重要的工作。
2. 何为预训练模型
对于自然语言,我们首先要构建一套语言模型,可以去理解语言或者说是表征语言,但是学习一套语言的表达的最好方式并不是首先掌握某种特定任务的知识和先验。那些文本中的语言规则、常识知识、句法结构等等才是最应该学习的。就像人类一样,我们从小都会从文字本身和语法结构开始去掌握,具备一种通用的语言使用和识别能力,这个时候我们再针对性的学习某些特定领域的知识如考古、音乐等等,效果会更好。
而早期的预训练的思想方法来自于Word2vec和Glove等模型,即将每一个token转化为向量,但是其最大的缺陷无法考虑到上下文对token的影响,如“他喜欢吃肉”和“这个英雄很肉”两个句子中,“肉”就会被转化成同一个向量,但在实际中,我们知道这种转化是不合理的,因为它并没有考虑上下文的影响。
因此,基于情景化的词嵌入的训练方法开始出现,这类模型主要是基于LSTM、self-attention layer来构建一个seq2seq的模型。也可以考虑使用基于树的模型,但由于效果比较一般,因此还并不流行。为了不断提升该模型的效果,使用的模型参数也在不断增加,甚至是达到了上亿级别,而这类模型也只有大公司才可能完成训练。但目前,我们也可以应用很多模型压缩方面的技术,减小模型体积但最大限度地不损失模型的精度,如ALBERT、Tiny BERT和Q8BERT等,仍然能取得不错的效果。
3. 如何微调
当我们有了一个预训练模型后,加入一个特定任务层后,就可以将其应用到其他的一些特定NLP任务中。
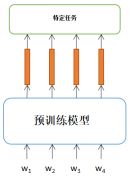
3.1输入和输出
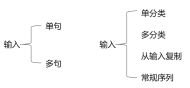
而NLP任务根据输入和输出可以分为以下几类:
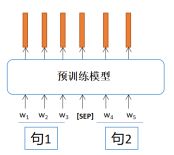
对于输入,如果只有一个句子,直接输入即可。如果输入有多个句子,需要加入一个[SEP]作为分隔符将两个句子合并成一个句子再输入。
对于输出,如果只有一个类别,可在输入的开头加一个叫做[CLS],然后在这个[CLS]对应的输出的向量后面加一个head,也就是比较浅的神经网络,可以是一层全连接,然后输出想要的类别数量;此外,还可以把所有token的输入都输入到一个head中去,然后输出想要的类别数量。
如果每个token都要做分类,则需要在模型的后面加一个seq2seq的head。
如果任务是基于抽取式的问答,则输入有问题和文档两个,所以需要加入一个[SEP]的分隔符,然后输出是找出文档中的哪个token为答案的开头,哪个token为答案的结尾。因此,我们需要两个额外的向量去分别和文档中每个token的输出做点积运算,然后和开头向量最相关的token就是开头 token,和结尾向量最相关的token就是结尾token。
如果模型输出是一个序列时,比较理想的做法是把预训练的模型当作解码器。即需要我们在输入的后面加入一个[SEP]的分隔符,然后把这个符号的输出放到一个自定义的head中去,输出一个token,然后把这个token作为输入,不断重复,直至输出。
3.2微调
微调的方法主要有两种。第一种,可以把预训练模型的权重都固定住,然后只去训练最后自定义加上去的head。第二种,可以直接训练整个模型,虽然整个模型很大,但大部分的权重是预训练过的,所以训练起来不会坏掉。实际经验也是第二种方法要优于第一种,但这样做的话,不同的任务我们都需要来训练一个不同的模型,但这样的模型一般都非常大,这会很浪费计算资源,所以Adaptor就出现了。Adaptor即是在预训练模型里去加一些层数,然后训练的时候就训练这些层数和最后的head。这样预训练模型还是不动的。实验证明,Adaptor可以让模型调很少的参数,却达到微调整个模型的效果。但是,这个Adaptor如何添加,还需要深入研究。
由于预训练模型往往都很大,不同层得到的特征所代表的含义也不同,所以也可以把各层的特征抽出来加权后输入到head中,加权的权重可以是模型自己学习。
4.如何预训练
最早的一种预训练方法就是利用翻译的任务去训练一个编码器和解码器,而这个编码就是我们需要的预训练模型。因为,在翻译任务,翻译是需要考虑上下文的信息,所以每个token对应的输出也是考虑了上下文的。然后将这些输出放入解码器之后可以得到正确的翻译说明了这些输出特征包含了每个token的语义。但是,由于我们并没有这么多已经标记整理好的数据,这个数据的整理成本将非常大。
因此,我们需要有一种不需要标注数据的方法去进行预训练,这种方法也称作是self-supervised learning。该方法,也属于是unsupervised learning。但是从严格意义上来说,其本质是用输入的一部分去预测输入的另一部分,其还是有监督的,因此也可以称作为自监督学习。

4.1 Predict next token
由上方的示意图可以看出,我们的目标就是要将一个句子x改造成x’和x”。最常见的一种做法就是预测下一个token。比如我们输入w1希望模型预测出w2 。然后再输入w2希望模型预测出w3 ,以此类推,只要注意在设计模型的时候,不要让模型看到它不应该看到的答案就可以了。把这个输入wi输出hi的模型基于LSTM去设计,就可以得到我们的ELMo模型。如果是基于self-attention去做,就有GPT,Megatron和Turing NLG。这个模型也就是language model。
但还有一种方式,就是我们在预测w2 的时候,把除了w2 的部分都去看一遍,再来预测。而ELMO就用了两个LSTM分别从头开始看和从尾开始看,比如看了w1到w4再去预测w5,然后看了w7到w5去预测w4 ,最后根据这两个的特征几个处理可得到最终w4所应对应的特征。
4.2 Mask Input
ELMO的做法有一个问题就是两个LSTM是互相独立的,它们之间没有信息的交流。BERT则完美的解决了这个问题,BERT只要设计好一个MASK,然后盖住模型要预测的那个token就可以了,这就是self-attention相比于LSTM的优势。
但只盖住一个token,模型可能无法学到一些较远的东西,只要依赖于附近的几个词进行猜测。所以,有人提出先对句子做实体识别然后盖实体或者短语,即ERNIE。
还有一种叫做SpanBert的方法,就是随机去盖一排token,盖住的token的长度满足一个分布,这个分布是盖的越长概率越小的一个分布。
4.3 seq2seq的预训练模型
BERT在训练的时候是看整个句子去预测的,因此不太适用于生成的任务,就是给一段句子,去预测后面的部分。因为Bert都是给个mask然后去预测mask的内容的。
seq2seq的预训练模型是如下图所示:
即输入一串tokens,经过一个编码和解码之后,希望得到同样的一串tokens。但直接这么做的话由于形式太简单,模型很难学到东西,所以,一般会对输入的一些序列做一些破坏。
Bart尝试了几种方式,第一种是随机给一个token加mask;第二种是删除某些输入;第三种是对tokens做permutation;第四种是对tokens做rotation;第五中是在没有token的地方插入mask,然后盖住某些token,盖住的部分可能有两个token。其中效果最好的是最后的一种。第三和第四种效果最差。
还有一种叫做UniLM模型,是既可以像BERT那样训练,又可以像GPT那样训练,还可以像BART那样训练。
4.4 ELECTRA
ELECTRA的模型,用一个更简单的任务去预训练模型。它把输入中的某个token用另一个token替换调之后,输入模型,让模型去预测各个token有没有被替换过。这样一方面使得任务更为简单,另一方面也可以监督到每一个token的对应输出。
但如果随意替换的话,很容易就会被模型找出来了,很难学到东西。所以还需要用一个额外的small BERT来生成这个要被替换掉的位置的token。这个BERT不能太准,也不能太不准。太准的话就会直接预测出原来的token了,太差的话和随机选差别不大。这种做法和GAN有些相似。
4.5 Sentence Embedding
还有些时候,我们希望得到的并不是每个token的向量,而是一个可以表示整个句子的向量。这种训练模型主要有两种方法,一种叫做skip Thought,就是给定一个句子,让模型去预测它的下一句话是什么,这样的生成任务很难;另一种叫做Quick Thought,在编码部分分别输入句子1和句子2,编码器会分别输出特征1和特征2,如果这两个句子是相邻的,那么我们希望特征1和特征2很相似。
Bert的做法是NSP(Next sentence prediction),就是输入两个句子,在两个句子之间加一个[SEP]的分隔符,然后用[CLS]这个token的输出来预测这两个句子是相邻的,还是不是相邻的。
NSP的这种做法的实际效果并不好,于是就有人提出了SOP(Sentence order prediction)。就是让两个句子来自于同一篇文章,如果这两个相邻的句子反了,那么它也是输出的No,只有在既相邻,顺序又对的情况下输出Yes。