手写中文数字识别PyTorch实现(全连接&卷积神经网络)
尝试一下手写汉字的数字识别,分别采用全连接神经网络和卷积神经网络
这次准备的数据集有15000张图片,每张图片大小为64*64

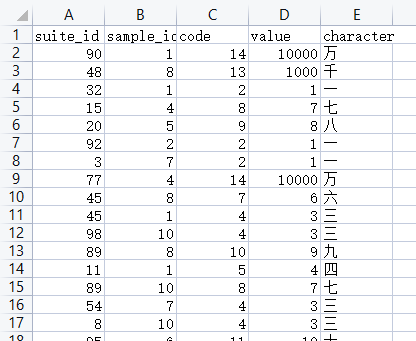
训练集10500张图片,测试集4500张图片
全连接神经网络
我们先用上次手写数字识别的全连接神经网络尝试一下
Dataset代码:
from torch.utils.data import Dataset
import torch
import cv2
class CN_MNIST(Dataset):
def __init__(self, index_csv):
self.index_csv = index_csv
self.dictionary = {'零': 0, '一': 1, '二': 2, '三': 3, '四': 4, '五': 5, '六': 6, '七': 7, '八': 8, '九': 9, '十': 10, '百': 11, '千': 12, '万': 13, '亿': 14}
def __getitem__(self, index):
sample = self.index_csv.iloc[index]
label = self.dictionary[str(sample['character'])]
suite_id = sample['suite_id']
sample_id = sample['sample_id']
code = sample['code']
file_name = 'images/input_' + str(suite_id) + '_' + str(sample_id) + '_' + str(code) + '.jpg'
image = cv2.imread(file_name)
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) / 255
return torch.Tensor(image), torch.Tensor([label]).squeeze().long()
def __len__(self):
return len(self.index_csv['code'])
模型以及训练测试代码:
import torch
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from CMINISTdataset import CN_MNIST
import torch.optim as optim
import torch.optim.lr_scheduler as lr_scheduler
import numpy as np
import torch.nn.functional as F
import pandas as pd
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 1 准备数据集
batch_size = 512
train_dataset = CN_MNIST(pd.read_csv('train_set.csv').sample(frac=1))
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size, num_workers=0)
test_dataset = CN_MNIST(pd.read_csv('test_set.csv').sample(frac=1))
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size, num_workers=0) # 测试集不需要打乱
# 2 设计模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(4096, 2048)
self.l2 = torch.nn.Linear(2048, 2048)
self.l3 = torch.nn.Linear(2048, 1024)
self.l4 = torch.nn.Linear(1024, 1024)
self.l5 = torch.nn.Linear(1024, 128)
self.l6 = torch.nn.Linear(128, 15)
self.dropout = torch.nn.Dropout(p=0.5)
self.norm = torch.nn.BatchNorm1d(128)
def forward(self, x):
x = x.view(-1, 4096) # 将批量输入的图像展平,-1表示自动计算行数
x = F.relu(self.l1(x))
x = F.relu(self.l2(x)) + x
x = F.relu(self.l3(x))
x = F.relu(self.l4(x)) + x
x = F.relu(self.norm(self.l5(x)))
return self.dropout(self.l6(x)) # 最后一层不做激活
model = Net()
model.to(device)
# 3 构建损失和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max=20, eta_min=1e-9)
# 4 训练
correct_list2 = []
def train(epoch):
total = 0
correct = 0
running_loss = 0
for i, data in enumerate(train_loader, 0):
inputs, target = data # 输入和标签
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
# scheduler.step()
running_loss += loss.item()
predicted = torch.argmax(outputs.data, dim=1) # 返回最大值下标
total += target.size(0)
correct += (predicted == target).sum().item()
print('[%d] loss:%.3f' % (epoch + 1, running_loss))
running_loss = 0.0
rate = 100 * correct / total
print('训练集的准确率为: {:.2f}'.format(rate))
correct_list2.append(rate)
correct_list = []
# 5 测试
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
# 取每一行最大值为预测结果
_, predicted = torch.max(outputs.data, dim=1) # 返回最大值和下标,下划线为占位符,无意义
total += labels.size(0)
correct += (predicted == labels).sum().item()
rate = 100 * correct / total
correct_list.append(rate)
print('测试集的准确率为: {:.2f}'.format(rate))
print('-------------------------')
if __name__ == '__main__':
for epoch in range(50):
model.train()
train(epoch)
model.eval()
test()
# 绘制Epoch-Loss曲线
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('accuracy%')
plt.plot(np.arange(0, 50, 1), np.array(correct_list))
plt.plot(np.arange(0, 50, 1), np.array(correct_list2))
plt.show()
运行结果:
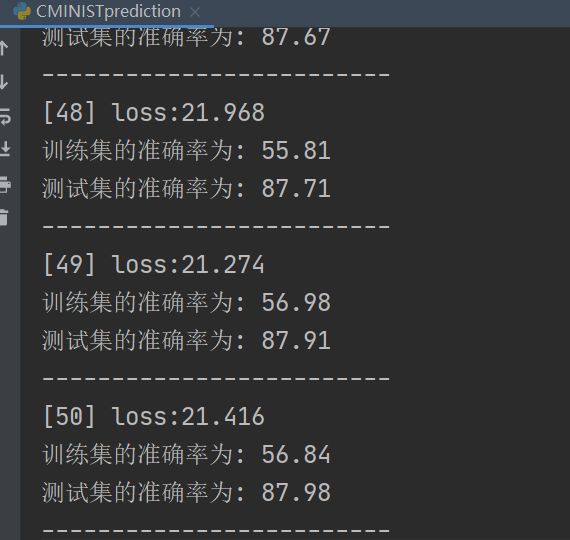
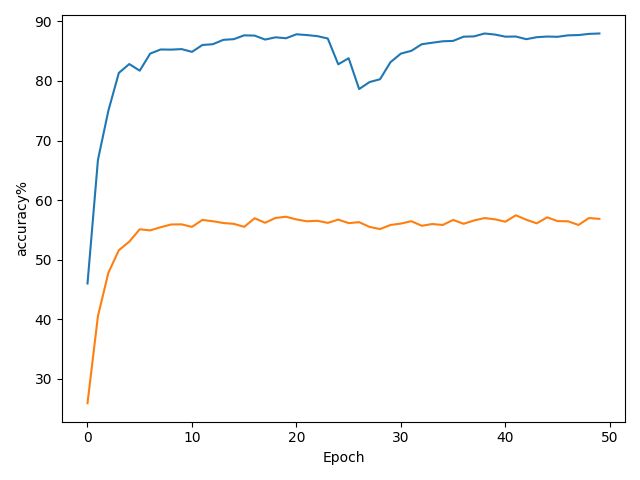
蓝线是测试集准确率,红线是训练集准确率,二者基本稳定在56%和87%左右波动
卷积神经网络
import torch
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import torch.nn as nn
from CMINISTdataset import CN_MNIST
import torch.optim as optim
import torch.optim.lr_scheduler as lr_scheduler
import numpy as np
import torch.nn.functional as F
import pandas as pd
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 1 准备数据集
batch_size = 512
train_dataset = CN_MNIST(pd.read_csv('train_set.csv').sample(frac=1))
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size, num_workers=0)
test_dataset = CN_MNIST(pd.read_csv('test_set.csv').sample(frac=1))
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size, num_workers=0) # 测试集不需要打乱
# 2 设计模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.pooling = nn.MaxPool2d(2)
self.fc = nn.Linear(320, 15)
def forward(self, x):
size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(size, -1)
x = self.fc(x)
return x
model = Net()
model.to(device)
# 3 构建损失和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# scheduler = lr_scheduler.CosineAnnealingLR(optimizer, T_max=20, eta_min=1e-9)
# 4 训练
correct_list2 = []
def train(epoch):
total = 0
correct = 0
running_loss = 0
for i, data in enumerate(train_loader, 0):
inputs, target = data # 输入和标签
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
# scheduler.step()
running_loss += loss.item()
predicted = torch.argmax(outputs.data, dim=1) # 返回最大值下标
total += target.size(0)
correct += (predicted == target).sum().item()
print('[%d] loss:%.3f' % (epoch + 1, running_loss))
running_loss = 0.0
rate = 100 * correct / total
print('训练集的准确率为: {:.2f}'.format(rate))
correct_list2.append(rate)
correct_list = []
# 5 测试
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
# 取每一行最大值为预测结果
_, predicted = torch.max(outputs.data, dim=1) # 返回最大值和下标,下划线为占位符,无意义
total += labels.size(0)
correct += (predicted == labels).sum().item()
rate = 100 * correct / total
correct_list.append(rate)
print('测试集的准确率为: {:.2f}'.format(rate))
print('-------------------------')
if __name__ == '__main__':
for epoch in range(200):
model.train()
train(epoch)
model.eval()
test()
# 绘制Epoch-Loss曲线
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('accuracy%')
plt.plot(np.arange(0, 200, 1), np.array(correct_list))
plt.plot(np.arange(0, 200, 1), np.array(correct_list2))
plt.show()
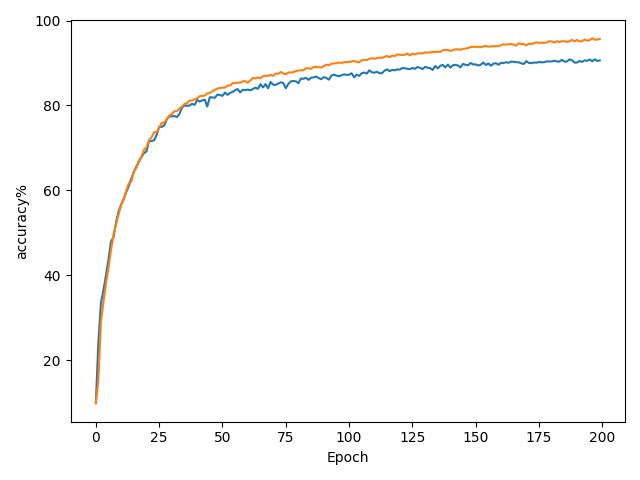
运行结果如下:蓝线是测试集准确率,红线是训练集准确率,二者基本稳定在95%和90%左右波动