数据分析与机器学习学习笔记--聚类算法
1.引言
聚类算法分属与机器学习中的无监督学习类型,由于无监督学习大多是根据距离进行分类所以其准确性远不及有监督学习,但是聚类算法用于数据预处理还是有很大作用的。例如我们拿到一个数据集后通过聚类算法生成3个类别,在此基础上将第一次分类产生的标签用于接下来进一步的有监督学习(典型的Stacking模型思想),使用这个思路得到的模型效果往往要好一些。
此外,他还能进行数据摘要、数据降维与数据压缩。总之一句话,就我个人的一些理解,在现阶段而言聚类算法更应归属与数据分析与预处理之中(在之前聚类算法常用于分类等其他方向中),为什么后来换成其他的算法进行分类了呢?自然是因为精度不达标喽,比如下方图所示,我们一眼可以看出这明显属于两个类别的样本,但是使用K-MEANS算法时两个样本的颜色、阴影等一系列值十分相似,因此在使用该聚类算法时会将两个样本归为一类。。。。(人狗情未了)。本文主要介绍K-MEANS,DBSCN二种不同的聚类算法,分别是基于距离、密度二种方式提出的算法。

2.K-MEANS算法
K-MEANS算法目标是将相似的‘物品’分到同一组,其核心思想是两个物体的距离约接近它们二者的相似度越高,即根据距离来划分不同的种类从而达到聚类的目的,在这里距离有两种计算方式分别是欧几里得距离和余弦相似度,但是余弦相似度在数学推倒上没能证明出其收敛,所以我们采用欧几里得方式度量距离,如下图所示,使用K-MEANS算法在这个数据集中我们划分了8类。接下来我们来看一看K-MEANS的工作流程。
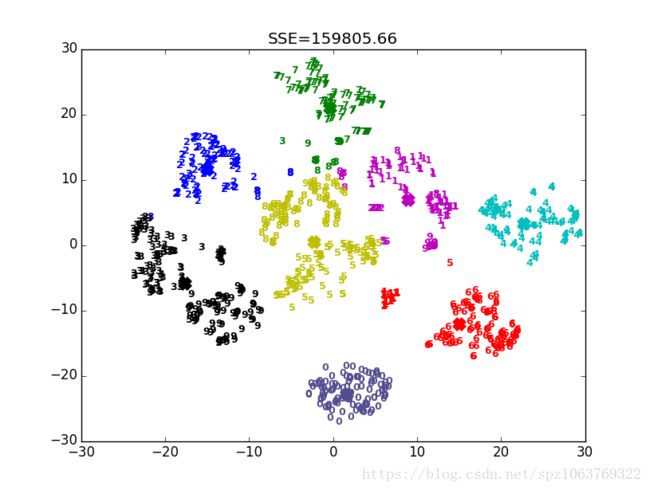
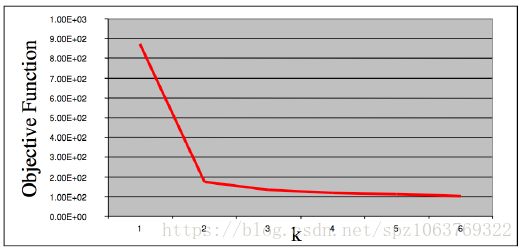
首先一点,如引言所说聚类算法用来分类,因此共有几个类别就是第一个要解决的问题,在K-MEANS算法中K的值(类别个数)需要我们自己指定,这也是相对来说很麻烦的一个问题,该算法的性能严重依赖于K值得指定,在确定K的过程中需要不断的试验,通过迭代的方式确定最佳的K值,如下图所示,在K值取2的时候该折线图处在一个‘肘点’,即该点是数值突变最大的点,因此我们的K值就应该选取这一点,通过可视化方式寻找最佳K值不失为一个好的方法比较直观。
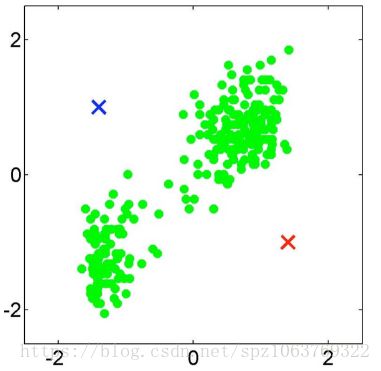
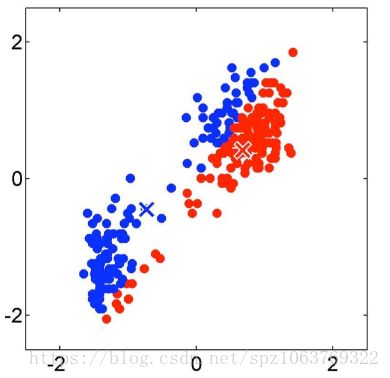
K值选取好后就要进行距离的计算,K-MEANS算法的执行过程是一个动态过程,如图1选择了左上与右下两个中心(质心)点,接下来选择一个点计算与两侧中心的距离,并将此点划分到距离近的那个点,更新划分后类内的中心;再重复上述步骤进行第二次计算,中心点不断变更(以划分的点有可能会重新进行划分),最终结果如图2所示完成一个二分类;同样的图3和图4是将初始中心点设置在左下和右上时的效果,对比两个结果可以清晰的发现第二种的分类效果更好一些,正是由于初始的中心点是随机选择的,所以K-MEANS算法充满了不确定性。如果将K值设成3会怎样呢?K-MEANS会强制分成3类(具体怎么分不清楚,因为初始点的动态选择造成的每次结果不同),从此就可看出该算法过于依赖对K值的选取。同时该算法适用于常规数据集,对于环形的数据集以及高维数据集表现效果不是特别好,对于以上两类数据集怎么聚类呢,这就是我们接下来要介绍的DBSCN聚类算法。

3.DBSCN
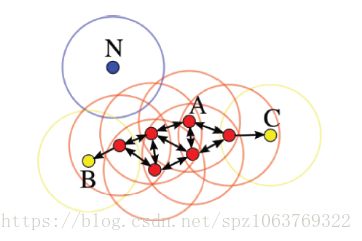
相比于K-MEANS算法依赖距离进行分类,DBSCN采用的是根据密度进行分类的思想,例如在某个数据点的半径为r的圆内包含的A类点个数超过我们设定的阈值时就将该点划分到A类内,接下来阐述几个相关概念(参考左图进行理解):
r临域的距离阈值:人为设定的半径,用来统计以r为半径的临域内不同类点个数,用以分类。
直接密度可达:某点p在以q为核心的r临域内,且q是核心点,则称p为直接密度可达。
密度可达:存在一个序列,q0->q1,q1->q2,q2->q3.......,以上->表示直接密度可达,在此表达式下我们称q3为q0的密度可达(q0与q3不是直接密度可达)。
密度相连:从以q为核心点出发,p和k都是直接密度可达的,我们称p和k为密度相连。
边界点:属于某一类的非核心点,不能继续向下发展,也就是在其临域内的所有直接密度可达点的阈值不达标,不能分到该类中。
噪声点:没有划分到任何一类中,如左图的点N。
右图为使用DBSCN进行聚类的一个实际结果,相对于K-MEANS算法DBSCN对于复杂条件下的聚类更优秀,如果对该数据集使用K-MEANS算法进行聚类他只能强制进行线性分类(类似于一分为二),中间图中绿色为核心点,蓝色为边界点,红色为离群点。DBSCN计算过程如下,首先选择一个点作为核心点,框选出以r为临域的范围,计算该临域内某类的直接密度可达点个数,当超过我们设定的阈值时将该核心点归为此类;接着选取上一步临域内的直接密度可达点作为新的核心点,重复进行上述计算过程,直到找到边界点位置并且所有点遍历完成,将剩下的点归为噪声点。DBSCN算法相比于K-MEANS算法不需要初始时认为设定K值,通过算法自己生成K值,该算法可以发现任意形状的簇,擅长检测噪声点;但是此算法计算量较大,对于高维数据不建议使用(可以对降维后的数据使用),并且效率不高。


4.总结
对于聚类算法总在使用,就目前而言聚类不太可能单独拉出来作为一个机器学习算法来实现某一功能,更多的是作用于数据预处理模块,结合各种降维算法使用,但是不是说作用于数据处理模块聚类算法就不重要,还是最开始我提及的部分,数据处理往往与一个算法实现效果的好坏具有最直观的联系。基于以上思想,此篇对于算法的推导过程没有详细解释,如果有需要可以网上阅读其他文章,网络存在大量的推导过程,一定能满足你的需要。(着急下班陪老大球球玩去喽,拜拜)