SegNet论文理解
Segnet:A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
文章来源:2016 TPAMI
SegNet论文地址:https://arxiv.org/abs/1511.00561
一、背景
SegNet网络是在部分FCN的基础之上进行改进的。但是SegNet和FCN的目标不同。FCN是将语义分割分类等级提升到像素级别的开山之作。SegNet主要是将针对实时应用的场景来进行分割,例如自动驾驶和室内的AR应用等。SegNet的目标就是设计一种快速、存储空间较小的适应用于实时应用的深度网络模型。
一般对解码-编码的语义分割网络改进有两个方面。一是减少编码阶段的位置信息的丢失。二是在解码阶段更多的恢复原图像的信息。我们可以看到SegNet网络就是从第二种思路进行改进的(下面介绍)。
二、SegNet提出的创新点
主要创新点有一个:Maxpooling index,即在编码阶段Maxpooling的时候进行两个操作,一是记录max值(maxpooling操作);二是记录max值所在的位置(maxpooling index)。

写到这里我有点想法想表达下,我觉得抛开存储问题和计算时间问题,是不是在解码阶段记录的位置信息越多(以供解码阶段恢复使用),这样子在解码阶段恢复的时候会更加逼近原图象呢?为什么我会这样认为呢,因为我们在传统图像分割的时候会认为一定数量像素值差值比较大的地方(噪声点另考虑)可以认为两个物体的边界。基于这个思想我猜想:是否作者的思路来源是这样(纯属个人观点,可在评论区理性讨论)?但是细节设计我没有太多想法。比如为什么只记录max值就够(池化窗口2*2大小的时候只记录max值就够了?或者记录太多值的时候计算效率下降和SegNet的定位不相匹配?还是其他?)?
三、SegNet的网络结构
SegNet网络编码阶段用的是训练好的VGG16网络的模型。通过卷积和池化的操作获得更多的语义信息,VGG中特定的maxpooling的操作会将图像的分辨率不断地减少(每次缩小一半,详细可看VGG网络)。整个编码的过程可以得到更多的语义信息,但是同时会丢失位置信息。

为了恢复原图像,就需要在解码阶段考虑了。解码阶段应该考虑两个问题,一个是尽可能多的还原在编码阶段减少的位置信息,另一个是恢复图像分辨率。
SegNet解码阶段和编码阶段是一一对应的。解码阶段采用上池化(UNpool)操作。上池化结合编码阶段的maxpooling index信息,先将图像大小和max值恢复,其他位置用0填满。然在和卷积层进行卷积操作,进行五次这样的操作最后输入到softmax层中对像素进行分类。
这里写出几点注意点:
1、FCN解码阶段和SegNet解码阶段的比较
FCN是采用反卷积或者叫转置卷积(Deconvolution)进行上采样操作的。FCN论文理解请点击这里。SegNet是采用上池化(UNpooling)操作的。下面会提到两者区别。如图中所示UNpooling操作简单明了。只恢复max值,其他位置用0填充,完了之后在和卷积层进行卷积操作。如下图所示。

2、上池化、上采样、反卷积(不是太清楚,主要搬运下面所提到的博主文章)
注意上池化(UNpooling)、上采样(UNSampling)、反卷积或者转置卷积(Deconvolution)下面展示了三者的大致操作过程,详细可参考该博文:反卷积(Deconvolution)、上采样(UNSampling)与上池化(UnPooling)加入自己的思考(pytorch函数)(二)_镜中隐的博客-CSDN博客_pytorch 反池化
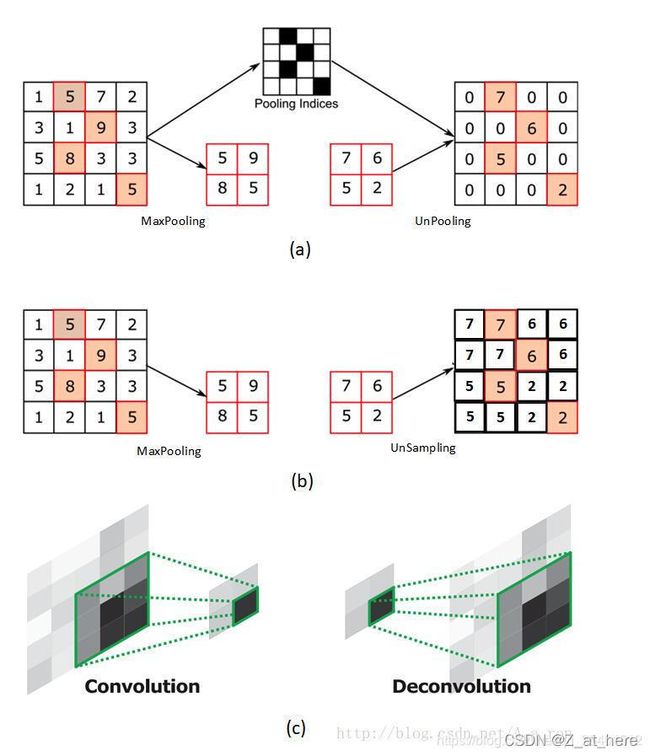

图(a)是输入层;图(b)是14*14反卷积的结果;图(c)是28*28的UnPooling结果;图(d)是28*28的反卷积结果;图(e)是56*56的Unpooling结果;图(f)是56*56反卷积的结果;图(g)是112*112 UnPooling的结果;图(h)是112*112的反卷积的结果;图(i)和图(j)分别是224*224的UnPooling和反卷积的结果。
3、批规则化batch normalization
个人对规则化的简单理解是通过一定的线性或者非线性关系,使得不同大小的数据落入一定大小的区间范围,方便后面计算。比如要处理两个批数据,第一批数据在10的5次方级别,另一批数据在10的-5次方级别。通过一定的方法使两者落入0-10内会更加方便处理。
批规则化的理解不是很深刻,先占个位置,后面了解深刻了再来填写。
四、实验相关
1、评价指标
global accuracy (G):数据集中正确分类的像素的百分比
class average accuracy (C):所有类别预测准确率的平均值
mean intersection over union (mIoU):比类平均准确率更严格,因为它惩罚FP预测;然而mIoU并不是损类别平衡cross-entropy损失函数的优化目标(其优化目标是准确率最大化)
boundary F1-measure (BF):涉及计算边界像素的F1指标。给定一个像素容错距离,计算预测值和ground truth类别边界之间的精确度和召回率。作者使用图像对角线的0.75%作为容错距离。与mIoU相比,BF的评判结果更符合人类对语义分割效果的判定
2、数据集
CamVid road scene segmentation(对自动驾驶有实际意义)、
SUN RGB-D indoor scene segmentation(对AR有实际意义)、
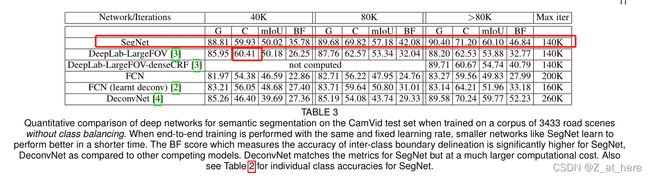
3、在Camvid上的结果
定量分析
定性分析

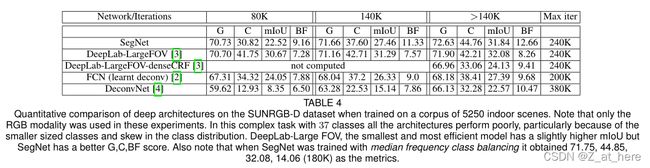
4、在SUNRGB-D的结果
定量分析
定性分析

四、评价
a.资源消耗和结果准确性上取得较好平衡(网络设计定位)
b.使用maxpooling index改善了边界划分清晰度
c.减少了训练量
总体来说还是比较简易的一个网络,同时还分为基础版(SegNet Basic)和贝叶斯版本(Bayesian SegNet)。