pytorch l2正则化_权重衰减和L2正则化是一个意思吗?它们只是在某些条件下等价...
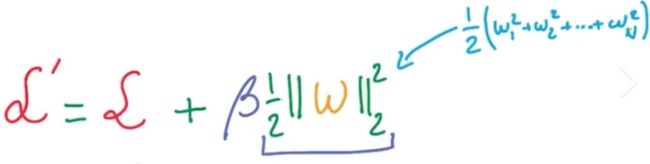
神经网络是很好的函数逼近器和特征提取器,但有时它们的权值过于专门化而导致过度拟合。这就是正则化概念出现的地方,我们将讨论这一概念,以及被错误地认为相同的两种主要权重正则化技术之间的细微差异。
1943年,沃伦·麦卡洛克(Warren McCulloch)和沃尔特·皮茨(Walter Pitts)首次提出了神经网络,但它并不受欢迎,因为它们需要大量的数据和计算能力,而这在当时是不可行的。但随着上述约束条件的可行性,以及参数初始化和更好的激活函数等其他训练进步,它们再次开始在各种竞争中占据主导地位,并在各种人类辅助技术中找到了应用。

介绍
今天,神经网络已经成为许多著名应用的主干,如自动驾驶汽车、谷歌翻译、面部识别系统等,并应用于几乎所有人类进化中使用的技术。
神经网络非常擅长于逼近线性或非线性函数,在从输入数据中提取特征时也非常出色。这种能力使他们在计算机视觉领域或语言建模的大范围任务中执行奇迹。但是我们都听过这句名言:
“能力越大,责任越大”。
这句话也适用于无所不能的神经网络。它们强大的函数逼近功能有时会导致它们对数据集过度拟合,因为它们逼近了一个函数,这个函数在它所训练的数据上表现得非常好,但在测试一个它从未见过的数据时却惨败。更有技术性的是,神经网络学习的权重更专门于给定的数据,而不能学习的特征,可以推广。
为了解决过拟合问题,我们采用了一种叫做正则化的技术来降低模型的复杂性和约束权重,从而迫使神经网络学习可归纳的特征。
正则化
正则化可以定义为我们对训练算法所做的任何改变,以减少泛化误差,而不是训练误差。有许多正则化策略。有的对模型进行了额外的约束,如对参数值进行约束;有的对目标函数进行了额外的约束,可以认为是对参数值进行了间接约束或软约束。如果我们小心地使用这些技术,就可以提高测试集的性能。
在深度学习环境中,大多数正则化技术都是基于正则化估计器的。在对估计值进行正则化的同时,我们必须进行权衡,选择偏差增大、方差减小的模型。一个有效的调节者是一个能使交易获利的人,在不过度增加偏差的同时显著地减少偏差。
在实践中使用的主要正则化技术有:
- L2 Regularization
- L1 Regularization
- Data Augmentation
- Dropout
- Early Stopping
在这篇文章中,我们主要关注L2正则化,并讨论是否可以将L2正则化和权重衰减看作是同一枚硬币的两面。
L2正则化
让我们考虑一下,交叉熵代价函数的定义如下所示。
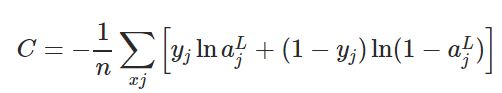
Figure 1. Cross-Entropy loss function
为了将L2正则化应用于任何具有交叉熵损失的网络,我们将正则化项添加到代价函数中,其中的正则化项如图2所示。
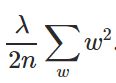
Figure 2. L2 norm or Euclidean Norm
在图2λ是正则化参数,直接与正则化应用的数量成正比。如果λ= 0,然后不应用正则化,当λ= 1网络应用最大的正则化。
λ是hyper-parameter这意味着它不是训练期间学到的,而是由用户手动调整或使用一些hyperparameter调优技术如随机搜索。
现在让我们把这些放在一起,形成L2正则化的最终方程,应用于图3所示的交叉熵损失函数。
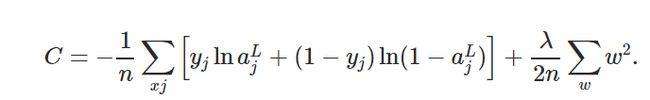
Figure 3.Final L2 Regularized Cost Function
上面的例子展示了L2正则化应用于交叉熵损失函数,但这个概念可以推广到所有可用的成本函数。图4给出了L2正则化更一般的公式,其中Co为非正则化代价函数,C为正则化代价函数,并加入正则化项。
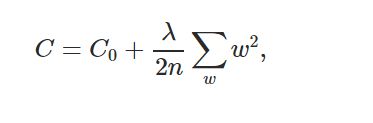
Figure 4. General Form of L2 Regularization for any cost function
注:我们在对网络进行正则化时没有考虑网络的偏置,原因如下:
- 与权重相比,偏置通常需要更少的数据来精确匹配。每个权重指定了两个变量如何相互作用(w和x),因此要很好地拟合权重,就需要在各种条件下观察两个变量,而每个偏置只控制一个变量(b)。因此,我们没有引入太多的方差,留下偏置非正则化。
- 使偏置正则化会引入大量的欠拟合。
为什么L2正则化有效?
让我们试着理解基于代价函数梯度的L2正则化的工作原理。
如果对图4i所示的方程求偏导数或梯度。∂C/∂w和∂C/∂b是关于网络中所有的权重和偏差的。
求偏导得到:

Figure 5. The gradient of the cost function with respect to weights and biases.
我们可以使用反向传播算法计算∂C0/∂w和∂C0/∂b在上述方程中提到的项。
偏差参数将不变的部分推导不应用正则化项,而重量参数将包含额外的((λ/ n) * w)正则化项。
因此,偏差和权重的学习规则为:
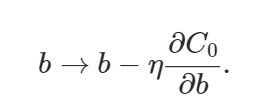
Figure 6. Gradient Descent Learning Rule for Bias Parameter
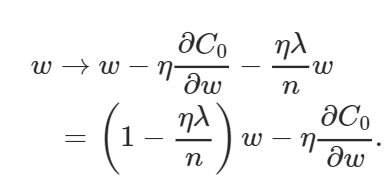
Figure 7. Gradient Descent Learning Rule for Weight Parameter
上面的权重方程类似于通常的梯度下降学习规则,除了现在我们首先重新调节权重w(1−(η*λ)/ n)。
这一术语是L2正则化经常被称为权重衰减的原因,因为它使权重更小。因此,您可以看到为什么正则化工作,它使网络的权重更小。权值的小意味着如果我们在这里和那里改变一些随机输入,网络行为不会有太大的改变,这反过来又使正则化网络难以学习数据中的局部噪声。这迫使网络只学习那些经常在训练集中出现的特征。
简单地从成本函数优化的角度来考虑L2正则化,当我们在成本函数中加入正则化项时,实际上是增加了成本函数的成本。因此,如果权重变大,它也会使成本上升,而训练算法会通过惩罚权重来降低权重,迫使它们取更小的值,从而使网络正规化。
L2正则化和权重衰减是一样的吗?
L2正则化和权值衰减不是一回事,但可以通过基于学习率的权值衰减因子的重新参数化使SGD等效。困惑吗?让我给你详细解释一下。
权重衰变方程给出下面λ是衰减系数。

Figure 8: Weight Decay in Neural Networks
L2正则化可被证明为SGD情况下的权值衰减,证明如下:
让我们首先考虑下图9所示的L2正则化方程。我们的目标是重新参数化它,使其等价于图8中给出的权重衰减方程。
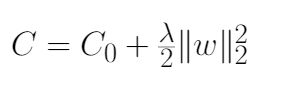
Figure 9. L2 Regularization in Neural Networks
首先,我们求出L2正则化代价函数关于参数w的偏导数(梯度),如图10所示。

Figure 10. Partial Derivative of Loss Function C with respect to w

Note: Both the Notations in the figure means the same thing.
在得到代价函数偏导数的结果(图10)后,我们将结果代入梯度下降学习规则中,如图11所示。代入后,我们打开括号,重新排列这些项,使其等价于权重衰减方程(图8),并有一定的假设。
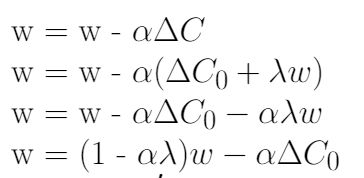
Figure 11. Substituting the Gradient of Cost Function in the Gradient Descent Rule and Rearranging terms.
你可以注意到,最后重新安排L2正规化的唯一区别方程(图11)和权重(图8)是α衰变方程(学习速率)乘以λ(正则化项)。
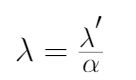
Figure 12. Condition of Equivalence of L2 Regularization and Weight Decay
后替换λλ′,L2正规化方程reparametrized和现在相当于体重衰变方程(图8),如图13所示。

Figure 13. Reparametrized L2 Regularization equation
从上面的证明,你必须理解为什么L2正则化被认为等同于SGD情况下的权值衰减,但它不是其他优化算法的情况,如Adam, AdaGrad等是基于自适应梯度。特别地,当与自适应梯度相结合时,L2正则化导致具有较大历史参数和/或梯度振幅的权重被正则化的程度小于使用权值衰减时的情况。与SGD相比,当使用L2正则化时,这会导致adam表现不佳。另一方面,重量衰减在SGD和Adam上的表现是一样的。
一个令人震惊的结果是,具有动量的SGD优于Adam等自适应梯度方法,因为常用的深度学习库实现了L2正则化,而不是原始的权值衰减。因此,在使用L2正则化对SGD有益的任务中,Adam的结果要比使用动量的SGD差。
结论
因此,我们得出结论,尽管权重衰减和L2正则化在某些条件下可能达到等价,但仍然是略有不同的概念,应该区别对待,否则会导致无法解释的性能下降或其他实际问题。
作者:Divyanshu Mishra