python数据分析及可视化(六)Pandas的对齐运算、混合运算、统计函数、排序函数、处理缺失值及数据的存储与读取
对齐运算
强调的是对齐和运算。NaN与任何数据进行操作结果都为NaN。
在下图s1+s2的时候,只找两个中相同位置的内容进行运算,没有的自动填充为NaN,a与a的值相加,结果为0;s1中b为1,s2中没有b,默认为NaN,1+NaN结果为NaN;同理e,f,g结果都为NaN。
对Series的操作

直接运算得到的值是不真实的,可以用函数进行运算,在函数中指定参数,把缺失值改为0进行运算。在s1+s2的时候,s1的b为1,s2的b为缺失值,现改为0,就变成了1+0=0。

对DataFrame的操作
把默认填充值设为0之后,还会有NaN值出现。填充为0是指在一个表中存在,另外一个表中不存在的情况;而两个表中都没有的则还是为NaN,如b行D列,因为在两个DataFrame中这个位置都没有值。

可以用add函数,指定填充的值为0

混合运算
| 方法 | 描述 |
|---|---|
| add,radd | 加法(+) |
| sub,rsub | 减法(-) |
| div,rdiv | 除法(/) |
| floordiv,rfloordiv | 整除(//) |
| mul,rmul | 乘法(*) |
| pow,rpow | 幂次方(**) |



统计计算函数
| 方法 | 描述 |
|---|---|
| count | 非NA值的个数 |
| min,max | 最小值,最大值 |
| idxmin,idxmax | 最小值,最大值的标签索引 |
| sum | 求和 |
| mean | 平均值 |
| median | 中位数 |
| var | 方差 |
| std | 标准差 |
| cumsum | 累计值 |
| cummin,cummax | 累计值的最小值或最大值 |
| cumprod | 值的累计积 |
| diff | 计算第一个算术差值(时间序列) |
| pct_change | 百分比 |
| corr | 按索引对其的值的相关性 |
| cov | 协方差 |
在sum函数进行计算的时候,会自动忽略NaN,只选择有值的进行运算,但是inf还是会按照原样计算,结果仍未inf。
cumsum函数是累计求和,比如基金的收益,第二个月月底的收益是第一个月和第二个月收益的累加,第三个月没有投资,也就没有收益,第四个月月底收益是前面四个月收益的总和。
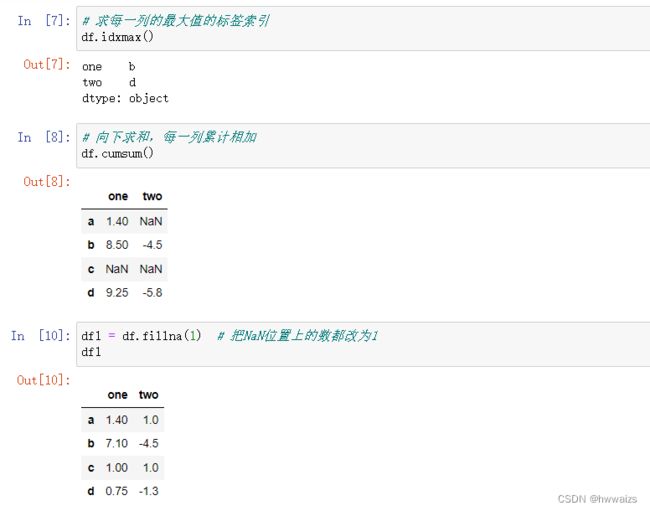
fillna(),括号内是要填充的值,函数的作用是把NaN位置上的数值都改为括号内的数值,后期做数据清洗的时候会经常使用,填充缺失的位置。做做缺失值处理的时候有两种方法,一种是删除,一种是填充。填充的时候要考虑数据场景,考虑数据本身,比如一个人的工资出现问题为NaN,若填充为0,则计算平均薪资的时候,都会被拉低,这个时候就要填入另外几人薪资的平均值或者删掉。
shift(-1),把每一行的数据都往上移动一行,括号内为1就是把数据都往下移动一行。
diff函数的作用是计算第一个算术差值,相当于原函数减去往上移动一行函数的,算式为df-df.shift(1)。
describe,汇总统计,只统计整数,包括个数,平均值,标准差,最大最小值等,可以看出数据的缺失值、平均值、异常值等。
info函数,查看表的基本信息。
apply函数在行或者列方向上应用函数,函数可以是自定义的,沿某一行或者某一列的操作。
applymap函数里没有轴参数,只传入函数,对表里的每一个数据都执行括号内的函数,通常用于对整个表的操作,如保留两位小数。




从info函数里可以看到,表格有4行数据a-d,有3列数据,以及每一列的数据类型和缺失值,可以用来查看数据的基本问题。


直接使用numpy函数
如果遇到需求,pandas里没有相应的函数,可以去找一下Numpy有没有类似的方法,避免重复造轮子。


排序的函数
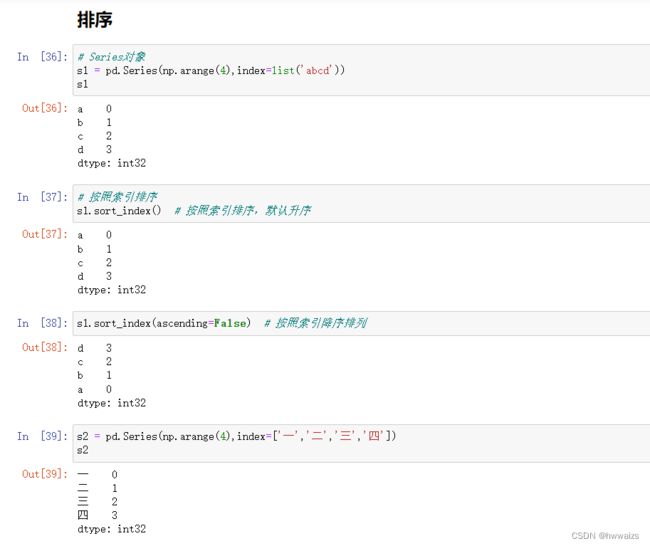
sort_index(),按照索引值排序,默认是升序,修改参数ascending=False,则为降序排列。索引值为整型或者字母可以排序,为字符串则不能排序,注意不是按表中的值排序。
Series对象的排序

DataFrame对象的排序
sort_index(),默认按照行的升序进行排列,可以更改括号内的参数,axis、ascending来实现按列或者降序排列。
sort_values(),内需要增加参数by,指定通过哪一行或者哪一列进行排序,按多个参数进行排列的时候,列或行的先后顺序代表排序的优先级,默认是按行进行排序,by后面也可以是单个的字符串,可以更改axis参数实现对列的排序。



唯一值和成员属性
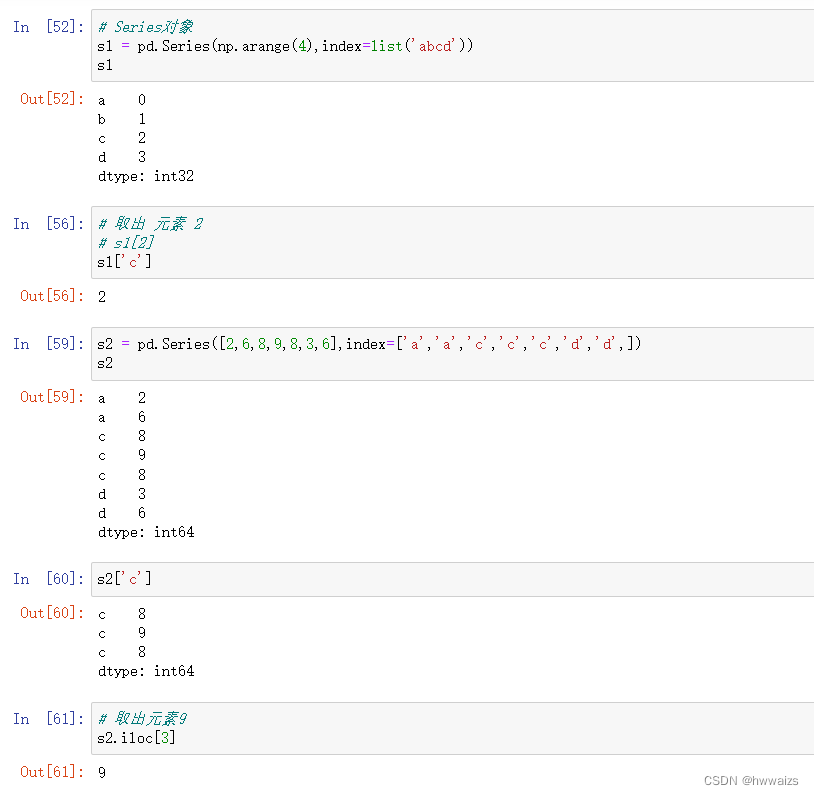
在Series中,标签名(索引名)是可以重复的。
iloc 高级索引取出特定位置的值。
unique,唯一值函数,返回出现过的元素,并不能显示出现过几次
index.is_unique,检查出现的索引名是否有重复
unique,返回出现过的元素
index.is_unique 判断是否有重复索引

数据的个数统计
value_counts(),判断每个元素出现的次数
isin,判断元素是否出现过

处理缺失值
检测缺失值
先进行检测,是否有缺失值
isnull(),检测表格中相应位置是否有缺失值,返回布尔值
isnull().sum(),统计每一列有几个缺失值
notnull(),检测不为缺失值的元素,返回布尔值


删除缺失值
dropna(),把NaN所在的行进行删除,默认的参数axis=0, how=‘any’, thresh=None, subset=None, inplace=False。设置参数axis=1,删除NaN所在的列,how=‘all’,则此行或列全为NaN时,才进行删除。

填充缺失值
当缺失数据量比较大时,删除会影响整体结果。比如有1万条数据,有10条存在缺失值,数据处理时可以直接进行删除;若有1000条数据,500条有缺失值的话,则需要进行填充,比较科学的方法是在缺失值处填充平均值。
mean(),默认是每一列的平均值
fillna(mean()),把每一列的平均值填充到NaN的位置 ,也可以指定方法进行填充.
method = ‘ffill’,把NaN值上面的数据填充到NaN处,常用于数据中元素差别比较大的情况,如前2人都是5000,第3个人缺失,第4个人5万,这个时候填入平均值意义就不大了。
method = ‘bfill’,把NaN值下面的数据填充到NaN处。

数据的存储与读取
| 函数 | 说明 |
|---|---|
| read_csv | 从文件、URL、文件型对象中加载带分隔符的数据、默认分隔符为逗号 |
| read_table | 从文件、URL、文件型对象中加载带分隔符的数据、默认分隔符为制表符(‘\t’) |
| read_fwf | 读取定宽列格式的数据(没有分隔符) |
| read_clipboard | 读取剪贴板中的数据,可以看作read_table的剪贴板,适用于网页转换为表格 |
| read_excel | 从Excel XLS或XLSX 文件读取表格数据 |
| read_hdf | 读取pandas写的HDF5文件 |
| read_html | 读取HTML文档中所有的表格 |
| read_json | 读取JSON(JavaScript Object Nation)字符串中的数据 |
| read_msgpack | 二进制格式编码的pandas数据 |
| read_pickle | 读取python pickle格式中存储的任意对象 |
| read_sas | 读取存储于SAS系统自定义存储格式的SAS数据集 |
| read_sql | 读取SQL查询结果为pandas的DataFrame |
| read_stata | 读取Stata文件格式的数据集 |
| read_feather | 读取Feather二进制文件格式 |
| 参数 | 说明 |
|---|---|
| path | 表示文件系统位置、URL、文件型对象的字符串 |
| sep或delimiter | 用于对行中各字段进行拆分的字符序列或正则表达式 |
| header | 用作列名的行号。默认为0(第一行),如果没有header行,需设置为None |
| index_col | 用作行索引的列编号或列名。可以是单独名称/数字或由多个名称/数字组成的列表(层次化索引) |
| names | 用于结果的列名列表,结合header=None |
| skiprows | 需要忽略的行数(从文件开始处算起),或需要跳过的行号(从0开始) |
| na_values | 一组用于替换的NA值 |
| comment | 用于将注释信息从行尾拆分出去的字符(一个或多个) |
| parse_dates | 尝试将数据解析为日期,默认为False。若改为True,则尝试解析所有列,也可以指定需要解析的一组列好或列名。如果列表的元素为列表或元组,就会将多个列组合到一起再进行日期解析(如日期/时间分别位于两个列中) |
| keep_data_col | 如果连接多列解析日期,则保持参与连接的列。默认为False |
| converters | 由列号/列名跟函数之间的映射关系组成的字典。例如{‘foo’:f}会对foo列的所有值应用函数f |
| dayfirst | 当解析由歧义的日期时,将其看作国际格式(7/6/2012 -->June 7,2012)。默认为False |
| date_parser | 用于解析日期的函数 |
| nrows | 需要读取的行数(从文件开始处算起) |
| iterator | 返回一个TextParser以便逐块读取文件 |
| chunksize | 文件块的大小(用于迭代) |
| ship_footer | 需要忽略的行数(从文件末尾处算起) |
csv文件的读取和保存
read_csv(),括号内为文件所在的路径,若出现OSError,则是版本过低,要在括号内增加指定python解释器,engine=‘python’,CSV文件看到的是表格,其实是以逗号分隔的数据,所以CSV文件默认分隔是sep=‘,’。读取的时候默认把第一行作为列名称,更改参数header=None,则第一行作为数据,系统自动加上列名称;也可以用指定的names方式增加列名称;也可以用names来指定列名称;也可以指定某一列或者多列作为行索引。




表格数据的保存,建议先放到DataFrame对象里,通过to_csv来保存。直接保存会放到程序所在的同级文件夹下。切记,保存程序运行时,一定要先关闭已经打开的同名文件,更改header和index参数可以设置保存时是否保存行列索引。

excel文件的读取和保存
read_excel(),读取excel文件,header,names,index_col参数的使用跟CSV一样,默认读取的是第一个工作表,从0开始计算。

TXT文件的读取和保存
读取的时候用read_table(),保存的时候用to_csv(),读取和保存的时候要注意txt文件内容以何种符号作为分隔符,判断是空格还是制表符。

特大文件的读取
在对特大文件进行读取的时候,要进行分块读取。当读取文件过大时(读取1个G的CSV文件时),就会大量消耗内存,pandas的读取效率就很低,电脑甚至会蓝屏。分块读取,比如每次读取100条数据,read_csv里的参数chunksize来控制读取块的大小
html文件的读取

从数据库中读取和存储
