这个GAN没见过猪,却能把狗变成猪
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
丰色 发自 凹非寺
转载自:量子位(QbitAI)
不用成千上万张目标图片训练,就能让GAN生成你想要的图片,有可能吗?

还真有可能!
来自特拉维夫大学和英伟达的研究人员成功地盲训出领域自适应的图像生成模型——StyleGAN-NADA。
也就是只需用简单地一个或几个字描述,一张目标领域的图像也不需要,StyleGAN-NADA就能在几分钟内训练出你想要的图片:
比如现在在几张狗狗的基础图片上输入“Sketch”,不到1分钟,一张张草图风格狗的图片就出来了。(视频没有声音可放心“食用”)
再比如在人像上给出文字“Pixar”,就能生成皮克斯风格的图片:

各种人像风格都可以:
甚至把狗变成猪也行:

问题来了,AI不可能生成它完全没有见过的照片,但是又不给它参考照片,那怎么满足要求呢?
基于CLIP
答案就是借助CLIP的语义能力。
CLIP是OpenAI提出的根据文字生成图片的DALL模型的图像分类模块,可以根据文字描述给图片的匹配程度打分。
今年年初,就有人用CLIP做出了一个用“大白话”检索图片的功能,效果还挺惊艳的。
 △输入“The word love written on the wall”的搜索结果
△输入“The word love written on the wall”的搜索结果
总的来说,StyleGAN-NADA的训练机制包含两个紧密相连的生成器Gfrozen和Gtrain,它俩都使用了StyleGAN2的体系结构,并共享同一个映射网络,因此也具有同一个隐空间(latent space)和隐码(latent code),所以它们在最开始生成的图像是一样的。
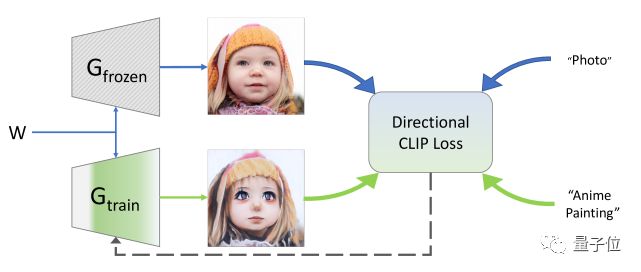
首先使用在单个源域(例如人脸、狗、教堂或汽车数据集)上预训练的模型权重初始化这两个生成器。
由于最终目标是生成一个风格不一样的图像,那就要更改其中一个成对生成器的域,同时保持另一个作为参考域。
具体的话就是Gfrozen的权重保持不变,而Gtrain的权重通过优化和迭代层冻结(iterative layer-freezing)方案进行修改。
而Gtrain的域在通过用户提供的文本方向进行更改(shift)的同时,会保持共享隐空间(latent space)。
具体怎么“更改”呢?
这就用到了一组基于CLIP的损失(loss)和“分层冻结”(layer-freezing)方案。
该方案可以自适应地确定在每次迭代训练中最相关的子层、并“冻结”其余层来提高训练稳定性保证效果。下面就详细介绍一下这两个方法。
基于CLIP的损失(loss)
StyleGAN-NADA依靠预先训练的CLIP作目标域的唯一监督来源。为了有效地从CLIP中提取“知识”,一共用了三种损失算法:
(1)负责确定在每次迭代中训练哪个子集层的全局目标损失 (Global CLIP loss);
(2)旨在保持多样性的局部定向损失 (Directional CLIP loss);
(3)以及防止图像生成不必要的语义伪影的嵌入范数损失 (Embedding-norm Loss)。
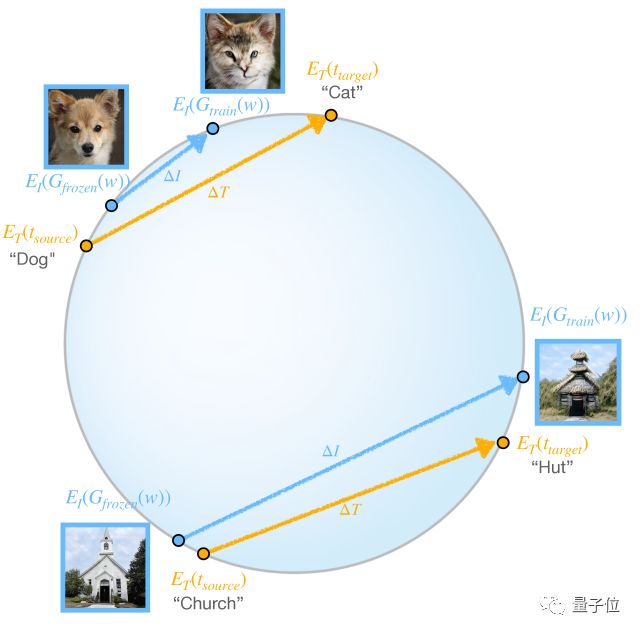
△ 局部定向损失要求源/目标图像/文字的CLIP-space方向一致
“分层冻结”(layer-freezing)
此机制分为两阶段:
(1)选层阶段,保持所有网络权重不变并对一组隐码进行优化,然后选择变化最显著的一层(优化使用目标域文本描述驱动的全局CLIP损失进行);
(2)优化阶段,“解冻”选定层的权重,然后使用定向CLIP损失进行优化和更改。
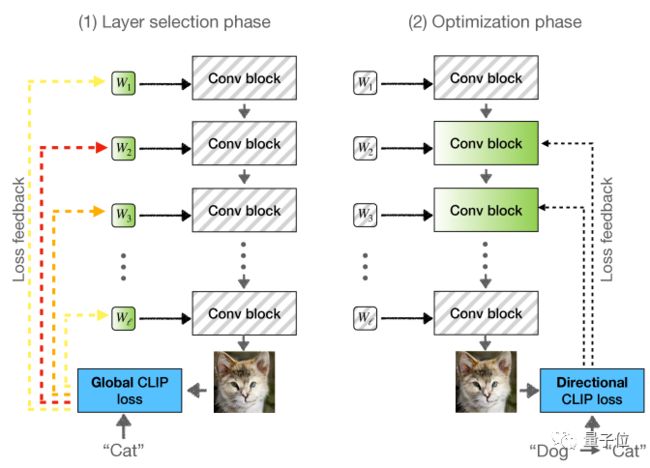
大多数训练只需几分钟就可完成
首先,该模型可以实现范围广泛的域外自适应,从纹理变化到大的形状修改,从现实到魔幻风格……甚至包括一些收集高质量数据成本很高的目标域。
其次,所有的这些图片的生成都只需给一个简单的文字描述,除了极端情况,大多数训练只需几分钟就能完成。
对于基于纹理的修改目标,该模型通常需要300次迭代,batch size为2,在一个NVIDIA V100 GPU上训练大约3分钟。在某些情况下(比如从“照片”到“草图”),训练只需不到一分钟的时间。
然后,所有的实验用的就是这个完整当然模型,没有添加任何latent mapper。研究人员发现,对于纯粹是基于样式的图像生成,模型需要跨所有层进行训练,比如下面这种:

而对于较小的形状修改,则只需训练大约2/3数量的层数就能折中保持训练时间和效果:

最后,将该模型与StyleCLIP(结合了StyleGAN和CLIP的域内图像编辑模型)、以及只用了Gfrozen生成器的模型对比发现,只有StyleGAN-NADA可以实现目标。

再将零样本的StyleGAN-NADA与一些少样本的图像生成模型对比发现,别的都要么过拟合要么崩溃(MineGAN更是只记住了训练集图像),只有StyleGAN-NADA在保持多样性的情况下成功生成(但它也有伪影出现)。
下面是消融实验:
 △ 通过训练latent mapper可以进一步提高生成质量
△ 通过训练latent mapper可以进一步提高生成质量
ps.在论文的最后,研究人员表示:
由于这项技术,也许在不久的将来,这类图像生成的工作将不再受到训练数据的约束,而只取决于我们的创造力。
论文地址:
https://arxiv.org/abs/2108.00946
GitHub地址:
https://github.com/rinongal/StyleGAN-nada
参考链接:
https://stylegan-nada.github.io/
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
重磅!Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看