文本挖掘案例:基于CSDN博客文章内容的文本挖掘与词云绘制
文章目录
-
-
-
-
- 一.语料准备
-
- 1.获取文章地址
- 2.由地址获取内容
- 二. 文本挖掘
-
- 1.读取文本
- 2.中文分词
- 3.词性标注
- 4.去除停用词
- 5.词性分布分析
- 6.高频词汇分析
- 7.词云绘制
-
-
-
一.语料准备
1.获取文章地址
首先选择需要分析的博主 进入其主页
浏览器上方主页地址:
https://blog.csdn.net/yt266666
需要从主页中获取所有博客详情地址:
- 文章数目较少时,可以手动复制
- 文章数目较多时,解析页面源码
html = requests.get(url="https://blog.csdn.net/yt266666", headers=headers).text
利用该代码获取页面源码或在页面中右键另存为
解析页面源码的方式有很多,包括正则表达式,全文搜索,BeautifulSoup,Xpath等等,
利用Xpath解析后获取如下结果:
1 https://blog.csdn.net/yt266666/article/details/127559647
2 https://blog.csdn.net/yt266666/article/details/127539343
3 https://blog.csdn.net/yt266666/article/details/127511361
4 https://blog.csdn.net/yt266666/article/details/127474784
5 https://blog.csdn.net/yt266666/article/details/127453067
6 https://blog.csdn.net/yt266666/article/details/127452708
7 https://blog.csdn.net/yt266666/article/details/127427285
8 https://blog.csdn.net/yt266666/article/details/127405088
9 https://blog.csdn.net/yt266666/article/details/127401802
10 https://blog.csdn.net/yt266666/article/details/127394061
11 https://blog.csdn.net/yt266666/article/details/127377217
12 https://blog.csdn.net/yt266666/article/details/127344774
13 https://blog.csdn.net/yt266666/article/details/127334902
14 https://blog.csdn.net/yt266666/article/details/127334143
15 https://blog.csdn.net/yt266666/article/details/127306966
16 https://blog.csdn.net/yt266666/article/details/127284543
17 https://blog.csdn.net/yt266666/article/details/127271663
18 https://blog.csdn.net/yt266666/article/details/127269150
19 https://blog.csdn.net/yt266666/article/details/127268544
20 https://blog.csdn.net/yt266666/article/details/127268431
解析页面源码获取地址的主要方法如下:
parser = etree.HTMLParser(encoding="utf-8")
tree = etree.HTML(html, parser=parser) # 加载html文件
blogList = tree.xpath('//div[@class="mainContent"]//a/@href')
2.由地址获取内容
将地址传入 解析页面内博客内容标签中的所有文本:
def getText(blogUrl):
html = getHTMLText(blogUrl)
parser = etree.HTMLParser(encoding="utf-8")
tree = etree.HTML(html, parser=parser) # 加载html文件
html = tree.xpath('//div[@class="blog-content-box"]//text()')
html = "".join(html).replace('\n', '')
html = html.replace(" ", "")
return html
这样的处理方式很粗糙 不过勉强能用。
再将文本存储在本地TXT文件中 便于读取
with open('blogText.txt', 'a', encoding='utf-8') as fd:
fd.write(blogText)
二. 文本挖掘
1.读取文本
open获得二进制文件流 read读取整个文档为字符串
text=open('blogText.txt', 'r',encoding='utf-8').read()
text=re.sub('[^\u4e00-\u9fa5]+','',text)
read方法:
-
.read() 每次读取整个文件,它通常用于将文件内容放到一个字符串变量中。
-
.readlines() 自动将文件内容分析成一个行的列表,
-
.readline() 每次只读取一行,通常比 .readlines() 慢得多。
-
仅当没有足够内存可以一次读取整个文件时,才应该使用 .readline()。
2.中文分词
采用全模式进行切片 此处需要导入jieba依赖
seg_list = jieba.cut(text, cut_all=True)
print(list(seg_list))
展示分词效果:
'类型', '输入', '二维', '矩阵', '向量', '或', '常数', '它们', '的', '值', '将', '决定', '图像', '的', '绘制', '位置', '如果', '坐标', '为', '常数', '数则', '绘制', '平行', '于', '平面', '的', '二维', '图形', '其他', '两个', '坐标', '同理', '如果', '与', '均', '为', '向量', '向量', '长度', '必须', '与', '内', '的', '矩阵', '相同', '如下', '所示', '旋转', '转角', '角度', '旋转', '观看', '角度', '定义', '观看', '方向', '的', '角度', '横向', '旋转', '图形', '观看', '看表', '表示', '纵向', '旋转', '图形', '观看', '从', '左', '至', '右', '原图', '背景', '方框', '方框框', '框框', '的', '类型', '默认', '只', '绘制', '背景', '面板', '类型', '有', '多种', '如', '图形', '全', '方框', '后面', '面板', '后面', '面板', '网格', '格网', '网格', '后面', '面板', '黑色', '背景', '网格', '黑色', '背景', '用户', '手动', '调整', '无边', '边框', '修改', '颜色', '该', '变量', '设置', '用于', '为', '图像', '添加', '颜色', '如果', '设置', '为', '空值', '将', '不会', '会生', '生成', '图像', '用于', '变量', '如果', '为', '而', '我们', '输入', '了', '参数', '那么', '将',
3.词性标注
依据分词 对词语的词性进行标注
words = pseg.cut(text[:50])
for word, label in words:
print("词语:"+word+"\t\t\t"+"词性:"+label)
词语:背景 词性:n
词语:方框 词性:n
词语:修改 词性:v
词语:颜色 词性:n
词语:设置 词性:vn
词语:图例 词性:n
词语:数值 词性:n
词语:范围 词性:n
4.去除停用词
一些词汇能够出现在任意的文章中 那么他们的出现对于我们的分析是无意义的 我们将其删除。
如我在列表添加的部分停用词:
StopWords = []
StopWords.append('收藏')
StopWords.append('中')
StopWords.append('与')
StopWords.append('我们')
StopWords.append('专栏')
StopWords.append('一个')
StopWords.append('文章')
StopWords.append('方法')
StopWords.append('版权')
StopWords.append('进行')
StopWords.append('使用')
StopWords.append('能够')
StopWords.append('并')
StopWords.append('对')
StopWords.append('可以')

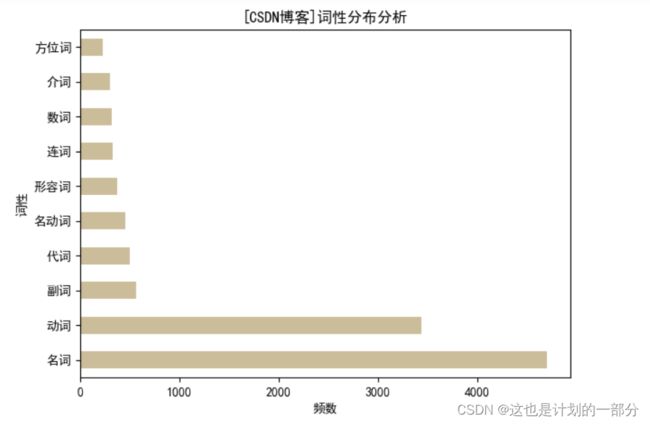
5.词性分布分析
绘制表格如下:
| 词性 | 频数 | 占比 |
|---|---|---|
| 名词 | 4709 | 0.384785 |
| 动词 | 3441 | 0.281588 |
| 副词 | 561 | 0.045908 |
| 代词 | 500 | 0.040917 |
| 名动词 | 451 | 0.036907 |
| 形容词 | 370 | 0.030278 |
| 连词 | 327 | 0.026759 |
| 数词 | 322 | 0.026350 |
| 介词 | 295 | 0.024141 |
| 方位词 | 225 | 0.018412 |
拥有数据后 简单绘制条形图进行展示:
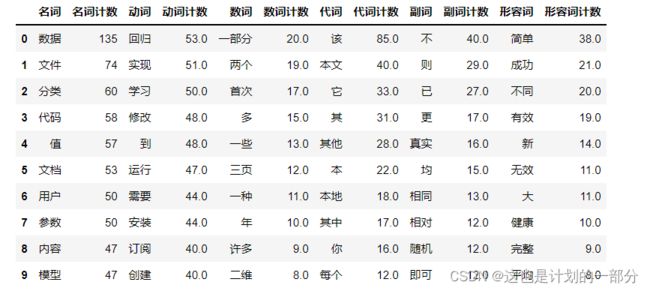
6.高频词汇分析
7.词云绘制
