爬虫基础:静态加载数据与动态加载数据获取方式
文章目录
-
-
-
-
- 一.静态加载数据
-
- 1.1 观察页面
- 1.2 获取源码
- 1.3 解析源码
- 二.动态加载数据
-
- 2.1 观察页面
- 2.2 获取方式
-
-
-
一.静态加载数据
1.1 观察页面
我们在利用爬虫发起网络请求,获取网页内容的过程中,最常见到的网页数据类型便是静态加载数据。
以搜狗搜索举例: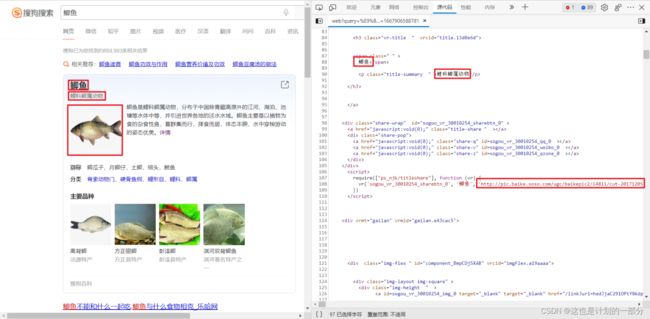
对比后 我们发现
- 网页中的搜索结果与源代码相互匹配 网页内容只是代码面向我们的一种展示方式
- 文字保持不变 音频/图片等资源在代码中以链接 (URL) 的形式存在
我们知道,当我们拥有指定资源的URL,我们就能够将其下载在本地;
这意味着,一旦我们获取到页面源码,就能够获取页面中的全部资源。
1.2 获取源码
利用requests库
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Mobile Safari/537.36 Edg/104.0.1293.54'}
r = requests.get(url=url,headers=headers)
或是手动抓取
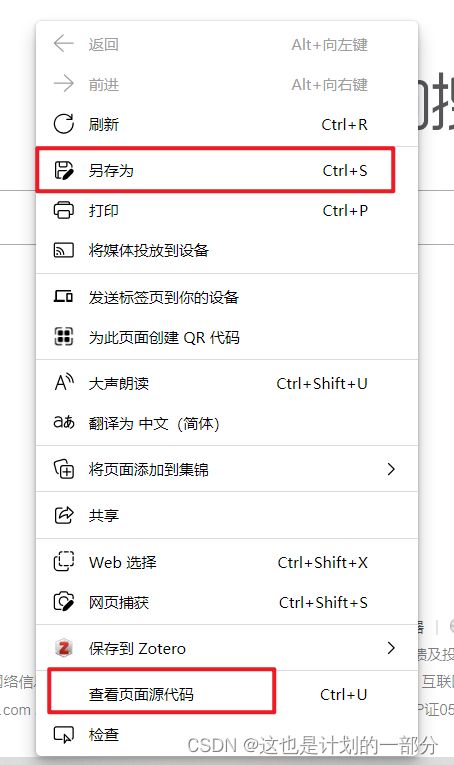
1.3 解析源码
获取到网页源代码后,我们还想得到更具体的信息,如我们获取了微博页面的源代码,我们可能需要的是其评论区信息,或者是最新热点新闻标题等等,总之,我们的需求不会停留在网页源代码(HTML)中。
常用解析网页的方式:
- 字符串检索
- 正则表达式
- XPATH
- BeautifulSoup
本人最推荐XPATH,简单快速上手。
html : 我们获取到的网页源代码
parser = etree.HTMLParser(encoding="utf-8")
tree = etree.HTML(html, parser=parser) # 加载html文件
result = tree.xpath('XPATH语句')
XPATH语句 浏览器已经为我们提供好了
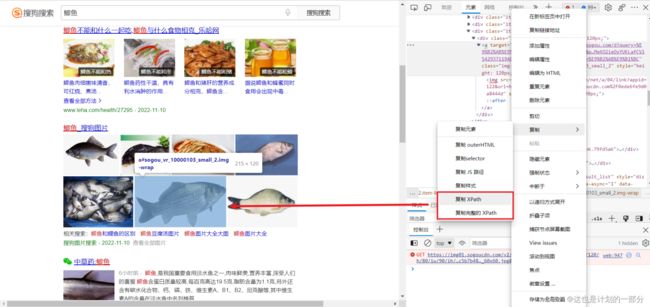
当然还是要稍微懂一些XPATH的语法 才能适用更多场景
二.动态加载数据
2.1 观察页面
动态加载数据,由后台JS或是其他工具刷新出的数据
如搜狗翻译,当我们在搜狗翻译框中不断调整输入,右侧翻译的输出也实时修改。

又或者说豆瓣电影排行榜 ,你简单翻翻该页面的源代码 就会发现其中并没有电影数据
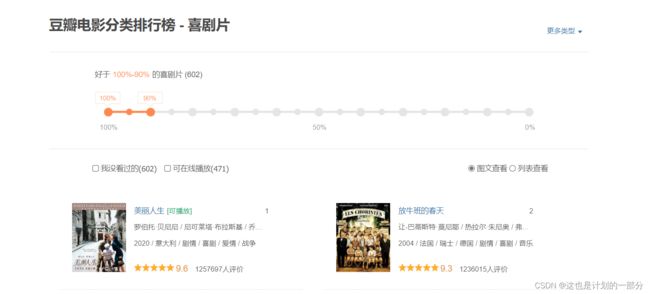
2.2 获取方式
利用浏览器的开发者工具进行抓包 按键盘F12

刷新浏览器
![]()
在开发者工具的网络页面下 能够看见许多请求

选中这些请求看看 ,意外发现在请求的响应数据中,存在着我们需要的电影信息。
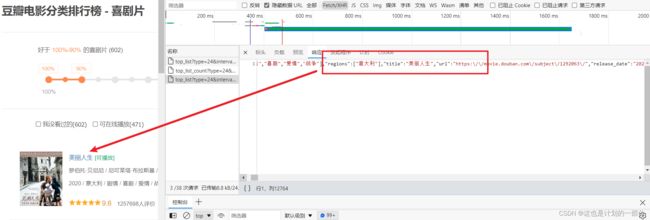
那么 事情就很清晰了~如果不嫌麻烦的话,不断刷新抓包,将JSON数据复制出来即可。
[
{
"rating":[
"9.6",
"50"
],
"rank":1,
"cover_url":"https://img2.doubanio.com\/view\/photo\/s_ratio_poster\/public\/p2578474613.jpg",
"is_playable":true,
"id":"1292063",
"types":[
"剧情",
"喜剧",
"爱情",
"战争"
],
"regions":[
"意大利"
],
"title":"美丽人生",
"url":"https:\/\/movie.douban.com\/subject\/1292063\/",
"release_date":"2020-01-03",
"actor_count":29,
"vote_count":1257698,
"score":"9.6",
"actors":[
"罗伯托·贝尼尼",
"尼可莱塔·布拉斯基",
"乔治·坎塔里尼",
"朱斯蒂诺·杜拉诺",
"赛尔乔·比尼·布斯特里克",
],
"is_watched":false
}
]
当然我们也可以通过实用的requests库 向目标连接发送请求
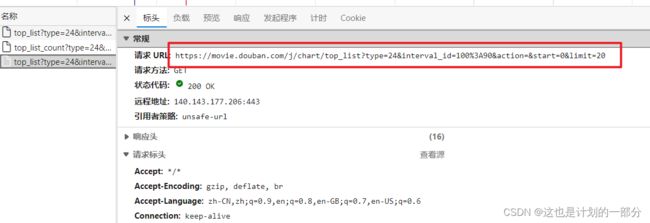
目标URL:
url = 'https://movie.douban.com/j/chart/top_list'
负载参数:
type 电影类型
start-limit 控制抓取的电影数据多少
data = {
'type': '11',
'interval_id': '100:90',
'action': None,
'start': '0',
'limit': '100'
}
UA伪装:
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Mobile Safari/537.36 Edg/104.0.1293.54'}
请求数据:
json = requests.post(url=url, data=data, headers=headers).json()
按照上述方式~就能够得到豆瓣的动态加载数据