鲍鱼数据集数据分析和可视化,线性回归预测鲍鱼年龄(基于TensorFlow)
一:数据集描述
Name Data Type Meas. Description
---- --------- ----- -----------
Sex nominal M, F, and I (infant)
Length continuous mm Longest shell measurement
Diameter continuous mm perpendicular to length
Height continuous mm with meat in shell
Whole weight continuous grams whole abalone
Shucked weight continuous grams weight of meat
Viscera weight continuous grams gut weight (after bleeding)
Shell weight continuous grams after being dried
Rings integer +1.5 gives the age in years
共9个属性,最后一个属性(Rings)代表鲍鱼的年轮,和树木一样,一年鲍鱼生长一出一个年轮
数据分析:
1.导入相关的第三方库:
我在ipython上进行的,所以添加魔法函数%matplotlib inline让绘图显示
%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns2.读入数据
利用pandas读取数据和分析数据
data = pd.read_csv('dataset.data')使用.info()方法查看数据集的总体信息
data.info()
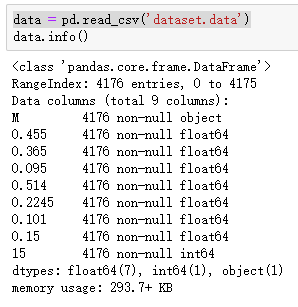
可以看到,共有4176条数据,9个特征,没有缺失值,除了年轮数据为int64,其他均为float64
因为原文件中,没有特征项的名称,我们加上特征名称,方便后续操作
data.columns = ['Sex', 'Length', 'Diameter', 'Height',
'Whole weight', 'Shucked weight', 'Viscera weight',
'Shell weight', 'Rings']下面是添加了列索引后的前五行数据:
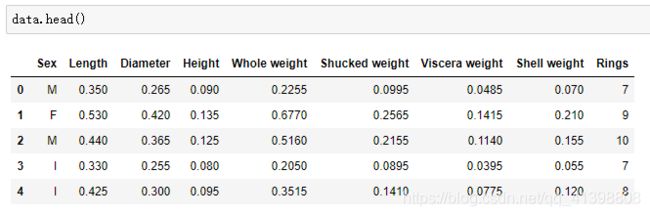
下面看看数据根据性别分类的数据分布:

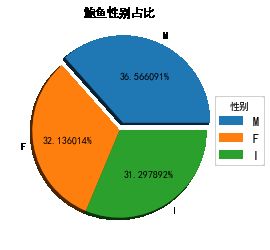
可以看到,鲍鱼性别共有三个分类(M,F,I),分别表示(雄性,雌性,未成年)
不同性别所占的数据为:M:1527,I:1342,F:1307
使用饼图直观的表示,不同性别的分布:
获取类别数:
n = len(data['Sex'].unique())获得类别标签:
labels = [data['Sex'].unique()[i] for i in range(n)]获得每个标签的数据个数:
fraces = [data['Sex'].value_counts()[i] for i in range(n)]绘制饼图:
explode = [0.1, 0, 0]
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title("鲍鱼性别占比")
wedges, texts, autotexts = plt.pie(x=fraces, labels=labels, autopct='%0f%%',
explode=explode,shadow=True)
plt.legend(wedges, labels, fontsize=12, title="性别",
loc="center left", bbox_to_anchor=(0.91, 0, 0.3, 1))
针对其他的离散数据,分别查看他们的概率分布密度图像:
分别使用核密度估计图和小提琴图:
sns.kdeplot(data_length)
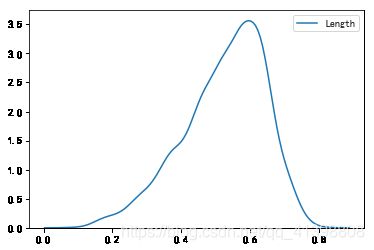
sns.violinplot(data_length)
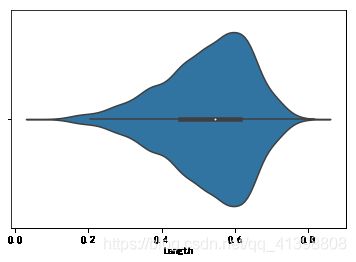
根据性别合并查询,查看不同性别的数据分布:
a = data.drop('Rings', axis=1).groupby('Sex').mean()
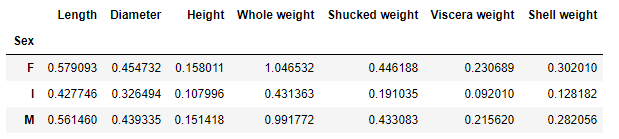
绘制分组条形图:
a.plot(kind='bar', grid=False)
plt.title('不同性别鲍鱼特征均值')
plt.legend(loc="center left", bbox_to_anchor = (1, 0.5))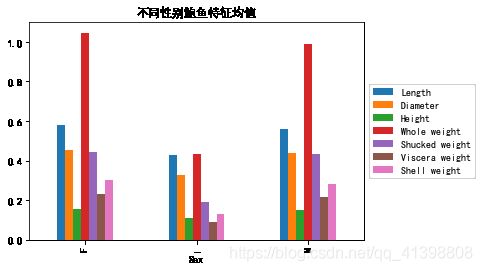
构建回归模型:
导入需要的库:
import tensorflow as tf
import numpy as np
import pandas as pd
from sklearn.utils import shuffle因为性别标签的数据是离散的,所以将离散数据转化为数值型数据:
size_mapping = {
'F': 0.1,
'M': 0.5,
'I': 0.9
}
df['Sex'] = df['Sex'].map(size_mapping)数据归一化:
data = np.array(df.values)
n = len(df.columns)
for i in range(n-1):
data[:,i] = data[:,i]/(data[:,i].max() - data[:,i].min())数据分为x(输入特征),y(预测数据)
x_data = data[:,:n-1]
y_data = data[:,-1]定义特征数据和标签数据的占位符
x = tf.placeholder(tf.float32, [None, n-1], name='x')
y = tf.placeholder(tf.float32, [None, 1], name='y')定义模型结构:
with tf.name_scope("model"):
w = tf.Variable(tf.random_normal([n-1, 1], stddev = 0.01), name = "w")
b = tf.Variable(1.0, name = "b")
def model(x, w, b):
return tf.matmul(x, w) + b
pred = model(x, w, b)超参数:
train_epochs = 50
learning_rate = 0.01定义均方损失函数:
with tf.name_scope("LossFunction"):
loss_function = tf.reduce_mean(tf.pow(y-pred, 2))创建梯度下降优化器:
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss_function)
sess = tf.Session()
init = tf.global_variables_initializer()记录日志文件,方便后续tensorBoard可视化:
logdir = r'C:\Users\yuzhu\Desktop\鲍鱼数据集\log'
sum_loss_op = tf.summary.scalar("loss", loss_function)
merged = tf.summary.merge_all()
sess.run(init)创建摘要文件写入器(FileWriter):
writer = tf.summary.FileWriter(logdir, sess.graph)训练模型:
loss_list = []
loss_list2 = []
for epoch in range(train_epochs):
loss_sum = 0.0
for xs,ys in zip(x_data, y_data):
xs = xs.reshape(1, n-1)
ys = ys.reshape(1, 1)
_, summary_str, loss = sess.run([optimizer, sum_loss_op, loss_function], feed_dict = {x:xs, y:ys})
writer.add_summary(summary_str, epoch)
loss_sum = loss_sum + loss
loss_list2.append(loss)
xvalues, yvalues = shuffle(x_data, y_data)
b0temp = b.eval(session=sess)
w0temp = w.eval(session=sess)
loss_average = loss_sum/len(y_data)
loss_list.append(loss_average)
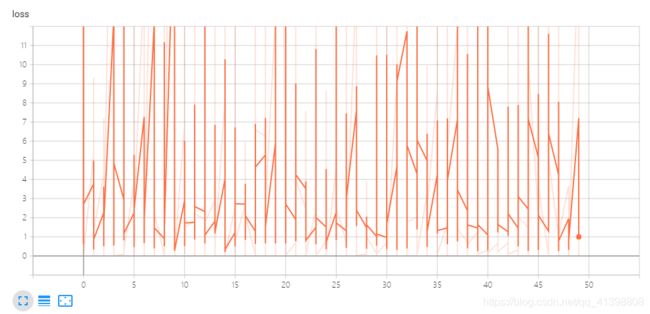
print("epoch=", epoch+1, "loss=", loss_average, "b=", b0temp, "w=", w0temp)绘制损失值的变化情况:
plt.plot(loss_list)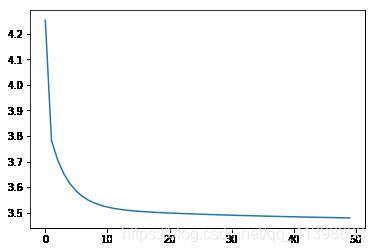
plt.plot(loss_list2)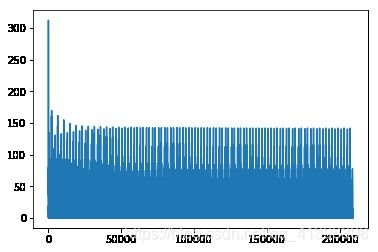
tensorBoard可视化结果(损失值):