自学python_19 正则表达式
比较好的博客地址:
https://www.runoob.com/python/python-reg-expressions.html
https://www.cnblogs.com/austinjoe/p/9492790.html
正则表达式:
search 和 match 方法:
import re
msg = "娜扎热巴代斯佟丽娅"
pattern = re.compile("佟丽娅")
res = re.match(pattern,msg)
# match方法没有匹配成功才会返回None。
# 只有把佟丽娅提前才能匹配得到。
print(res)
# None 在这里 娜扎热 和 佟丽娅匹配不上,所以返回None。
res = re.match(pattern,msg)
print(res)
如何寻找那些混在一起的字母和数字,或者是寻找具备其他某种特征的结果该怎么做呢?这就引入了正则表达式。正则表达式不是search中的固定字符串,而是将字符串变成了一种用固定的语言定义特征的字符串。
可以再re.py查看定义的具体规则。
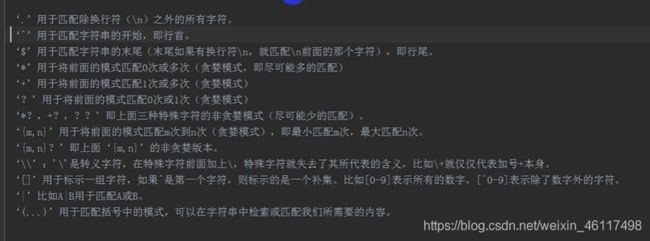
寻找字符串中在[123456]里的字符
import re
s = "哈哈6"
s1 = "哈哈9"
res = re.search("[123456]",s)
# [123456] 相当于 [1-6]
print(res)
# 寻找全部字符串中一个数字加一个字母的组合
import re
s = "d1cc2j3c1b2j1a23aa12313b"
res = re.findall("[a-z][0-9][a-z]",s)
print(res)
# ['d1c', 'c2j', 'c1b', 'j1a']
这里的c2j3c仅仅是把c2j当成结果了,j3c没有,要注意这个机制。
如果把上面的一个换成多个,就要用到 * + ?

import re
s = "d1cc2j3c1b2j1a23aa12313b"
res = re.findall("[a-z][0-9]+[a-z]",s)
print(res)
# ['d1c', 'c2j', 'c1b', 'j1a', 'a12313b']
简单应用:判断QQ号
#qq号验证, 5~11为,开头不能为0
q = "31234123"
q1 = "[12312323]"
res = re.match("^[1-9][0-9]{4,10}$",q)
# {}里面的数字是,必须有这么多位符合要求
# {m,n} 表示次数大于等于m且小于等于n次。
# 也可以用{m,},{,n}表示大于等于,小于等于。
print(res)
# 正则表达式中的预定义字符:

简单应用:检索文件名:
import re
msg = "123.py 123.txt 12323.py"
# 最常规的方法是在字符串前加r。
res = re.findall(r"\w*\.py\b",msg)
# 如果不在字符串前面加r,就要写成\\w,\\b。
print(res)
# ['123.py', '12323.py']
分组操作:
(word1|word2|word3) 只能是word1,2,3。不能有任何改变。
[word1|word2|word3] 与()不同,这里的|没有或的意思,就是一个字符|。
这里把 word1|word2|word3 看成一个整体,只要再这个整体中就符合要求,比如w,o,d。
import re
# 匹配 1 - 100 的数字。
n = "9"
result = re.match(r"[1-9]?\d?$|100$",n)
print(result)
# 验证输入的邮箱 163 126 qq
email = "[email protected]"
result = re.match(r"\w{5,20}@(163|126|qq)\.(com|cn)$",email)
print(result)
结合group:
如果正则表达式中定义了组,就可以在Match对象上用group()方法提取出子串来。
email = "[email protected]"
result = re.match(r"(\w{5,20}@)(163|126|qq)\.(com|cn)$",email)
print(result.group(1))
# 123132@
print(result.group(2))
# qq
print(result.group(3))
# com
注意到group(0)永远是原始字符串,group(1)、group(2)……表示第1、2、……个子串。
用number对group里的内容进行调用。
import re
# 结合number进行使用。
result = re.match(r"<([0-9a-zA-Z]+)>(.+)$",msg)
print(result)
# 也可以对group里的各个分组进行命名。
import re
msg = "abc
"
result = re.match(r"<(?P\w+)><(?P\w+)>(.+)" ,msg)
print(result)
# (?P)可以对分组命名,如果需要调用分组的名称,用(?P=name)不要加空格。
sub:将匹配的数据进行替换:
import re
msg = "abc
"
result = re.sub(r"\d+","90","121231231adasd1231")
print(result)
# 90adasd90
第一个参数是替换的类型,第二个是替换的内容,第三个是原字符串。也可以把第二个参数换成一个函数。
import re
def fun(temp):
num = temp.group()
num1 = int(num) + 1
return str(num1)
msg = "abc
"
result = re.sub(r"\d+",fun,"121231231adasd1231")
print(result)
此时就会将原字符串传递进fun里作为temp进行操作,并且在操作完之后将字符串返回,注意返回值一定要是字符串类型。
贪婪和非贪婪:
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪则相反,总是尝试匹配尽可能少的字符。在"*","?","+","{m,n}"后面加上?,使贪婪变成非贪婪。
贪婪模式下字符串查找会直接走到字符串结尾去匹配,如果不相等就向前寻找,这一过程称为回溯。
import re
str1='贪婪 贪婪 贪婪
贪婪'
str2=re.findall(r'<.*>',str1)
print(str2)
# ['贪婪 贪婪 贪婪
']
非贪婪模式下会自左向右查找,一个一个匹配不会出现回溯的情况。
import re
str1='贪婪 贪婪 贪婪
贪婪'
str2=re.findall(r'<.*?>',str1)
print(str2)
# ['', '', ' ', ' ', '', ' ', '', ' ', '', '
']