利用docker部署深度学习的例子
由于工作实际需要,训练了几个语义分割的模型,但是模型的部署落地还是第一次做,前后端分别用的是vue和flask框架,数据库采用mysql。在研究算法的同时,具备一定的部署能力也是必须的。由于单位生产上是涉密环境,环境的问题让人头疼,刚好最近在研究docker,就试着用docker容器技术对REST API模型进行部署,可以很快在涉密环境中部署好我们的深度学习模型。
下面,我利用一个简单的demo来说明问题,包括dockerfile的编写,构建镜像,启动容器,以及遇到的坑。
首先,docker是什么就不详细介绍了,可以自行百度。
简单的Flask后端接口
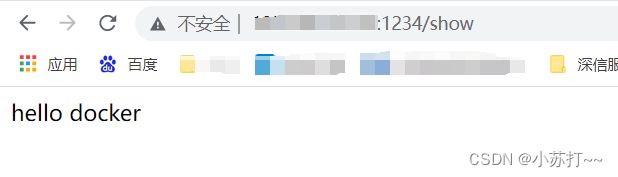
代码很简单,导入深度学习框架TensorFlow,输出hello docker,用于启动REST API的app.py编写如下:
# -*- coding: utf-8 -*-
# @Time : 2022/8/6 16:29
# @Author : xsd
# @FileName: app.py
# @Software: PyCharm
# @Function: app
from flask import Flask
app = Flask(__name__)
import tensorflow as tf
@app.route('/show')
def show_info():
print('hello')
return 'hello docker'
if __name__ == '__main__':
app.run(host='0.0.0.0', port=1234)生成python依赖库requirements文件
这里用到的是pipreqs第三方库,pipreqs可以自动检测当前项目下所有的组件及其版本,并生成requirements.txt文件,极大方便项目的迁移和部署包的管理。
使用步骤:
1.pip install pipreqs
2.在当前目录使用生成
pipreqs ./ --encoding=utf8 --force
--encoding=utf-8:为生成目录下requirements.txt存在时覆盖
--force:强制执行,当生成目录下的requirements.txt存在时覆盖
./表示在哪个文件夹下生成requirements.txt文件
requirements.txt内容如下:
Flask==1.0.2
tensorflow_gpu==1.13.1
Dockerfile编写
接下来就是编写dockerfile,这是实现docker快速部署的关键,dockerfile指令是将python环境,项目所需第三方库、脚本运行等串起来,实现一键操作,由于用到GPU环境,查看宿主机CUDA版本为CUDA10.0+cuDNN(7.6.5),要保持和宿主机版本一致。cudnn文件如下:
下边可以正式编写dockerfile,具体如下:
ARG ubuntu_version=18.04
ARG cuda_version=10.0
#指定Python环境
FROM nvidia/cuda:${cuda_version}-devel-ubuntu${ubuntu_version}
ARG cudnn_version=7.5.0
ARG cudnn_ln_version=7
#这里会配置一些环境变量的过程
#cuda
ENV PATH=/usr/local/cuda/bin:$PATH
ENV LD_LIBRARY_PATH=/usr/local/cuda/lib64
#cudnn
COPY ./cudnn-10.0-linux-x64-v7.5.0.56.tgz /usr/local
#RUN sed -i 's#http://archive.ubuntu.com/#http://mirrors.tuna.tsinghua.edu.cn/#' /etc/apt/sources.list;
#安装CUDA
RUN \
cd /usr/local/ && \
tar -zxvf cudnn-10.0-linux-x64-v7.5.0.56.tgz && \
chmod +x /usr/local/cuda/lib64/libcudnn* && \
chmod +x /usr/local/cuda/include/cudnn* && \
cd /usr/local/cuda/lib64/ && \
ln -snf libcudnn.so.${cudnn_version} libcudnn.so.${cudnn_ln_version} && \
ln -snf libcudnn_adv_train.so.${cudnn_version} libcudnn_adv_train.so.${cudnn_ln_version} && \
ln -snf libcudnn_cnn_train.so.${cudnn_version} libcudnn_cnn_train.so.${cudnn_ln_version} && \
ln -snf libcudnn_ops_train.so.${cudnn_version} libcudnn_ops_train.so.${cudnn_ln_version} && \
ln -snf libcudnn_adv_infer.so.${cudnn_version} libcudnn_adv_infer.so.${cudnn_ln_version} && \
ln -snf libcudnn_cnn_infer.so.${cudnn_version} libcudnn_cnn_infer.so.${cudnn_ln_version} && \
ln -snf libcudnn_ops_infer.so.${cudnn_version} libcudnn_ops_infer.so.${cudnn_ln_version}
#添加清华源
# 添加清华源
RUN \
apt-get update && apt-get install --assume-yes apt-utils && apt-get upgrade -y && \
echo "deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricted universe multiverse" > /etc/apt/sources.list && \
echo "deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse" >> /etc/apt/sources.list && \
echo "deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse" >> /etc/apt/sources.list && \
echo "deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-security main restricted universe multiverse" >> /etc/apt/sources.list
# 更新源、安装软件
RUN \
apt-get update && apt-get upgrade -y && \
apt-get install gcc automake autoconf libtool make wget openssl libssl-dev software-properties-common vim cmake curl git python3 python3-pip -y && \
python3 -m pip install --upgrade pip && \
pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
#拷贝python依赖库requirements文件到当前目录下
ADD requirements.txt /
#安装依赖库
RUN pip3 install -r /requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
#拷贝所有文件到app目录下
ADD . /app
#指定app为工作目录
WORKDIR /app
#声明端口
EXPOSE 1234
#docker 容器启动
CMD ["python3", "app.py"]
构建镜像
编写完dockerfile文件后,既可以通过docker来构建项目镜像
docker build -t keras_flask_app .根据dockerfile中的17条指令,docker build也会经过17个步骤来生成镜像,这个过程将比较漫长,可以画画标签啥的,哈哈
Sending build context to Docker daemon 432.8MB
Step 1/17 : ARG ubuntu_version=18.04
Step 2/17 : ARG cuda_version=10.0
Step 3/17 : FROM nvidia/cuda:${cuda_version}-devel-ubuntu${ubuntu_version}
---> 52390d68f8ba
Step 4/17 : ARG cudnn_version=7.5.0
---> Using cache
---> 1257cc6216d3
Step 5/17 : ARG cudnn_ln_version=7
---> Using cache
---> a9a52736d18f
Step 6/17 : ENV PATH=/usr/local/cuda/bin:$PATH
---> Using cache
---> 316b0da91ca9
Step 7/17 : ENV LD_LIBRARY_PATH=/usr/local/cuda/lib64
---> Using cache
---> 1eb5ba8e2f96
Step 8/17 : COPY ./cudnn-10.0-linux-x64-v7.5.0.56.tgz /usr/local
---> Using cache
---> 89f0fc974f20
Step 9/17 : RUN cd /usr/local/ && tar -zxvf cudnn-10.0-linux-x64-v7.5.0.56.tgz && chmod +x /usr/local/cuda/lib64/libcudnn* && chmod +x /usr/local/cuda/include/cudnn* && cd /usr/local/cuda/lib64/ && ln -snf libcudnn.so.${cudnn_version} libcudnn.so.${cudnn_ln_version} && ln -snf libcudnn_adv_train.so.${cudnn_version} libcudnn_adv_train.s o.${cudnn_ln_version} && ln -snf libcudnn_cnn_train.so.${cudnn_version} libcudnn_cnn_train.so.${cudnn_ln_version} && ln -snf libcudnn_ops_train.so.${cudnn_version} libcudnn_op s_train.so.${cudnn_ln_version} && ln -snf libcudnn_adv_infer.so.${cudnn_version} libcudnn_adv_infer.so.${cudnn_ln_version} && ln -snf libcudnn_cnn_infer.so.${cudnn_version} li bcudnn_cnn_infer.so.${cudnn_ln_version} && ln -snf libcudnn_ops_infer.so.${cudnn_version} libcudnn_ops_infer.so.${cudnn_ln_version}
---> Using cache
---> da2e9667552d
Step 10/17 : RUN apt-get update && apt-get install --assume-yes apt-utils && apt-get upgrade -y && echo "deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic main restricte d universe multiverse" > /etc/apt/sources.list && echo "deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-updates main restricted universe multiverse" >> /etc/apt/sources.li st && echo "deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ bionic-backports main restricted universe multiverse" >> /etc/apt/sources.list && echo "deb https://mirrors.tuna.t singhua.edu.cn/ubuntu/ bionic-security main restricted universe multiverse" >> /etc/apt/sources.list
---> Using cache
---> 56fb09a4b89d
Step 11/17 : RUN apt-get update && apt-get upgrade -y && apt-get install gcc automake autoconf libtool make wget openssl libssl-dev software-properties-common vim cmake curl g it python3 python3-pip -y && python3 -m pip install --upgrade pip && pip3 config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
---> Using cache
---> 02a7ebe389e9
Step 12/17 : ADD requirements.txt /
---> Using cache
---> 8f14fe0dd741
Step 13/17 : RUN pip3 install -r /requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple/
---> Using cache
---> cc30375227eb
Step 14/17 : ADD . /app
---> Using cache
---> 83da92fecf5d
Step 15/17 : WORKDIR /app
---> Using cache
---> 0f05af6c25c1
Step 16/17 : EXPOSE 1234
---> Using cache
---> 5d1b5b7cfb7f
Step 17/17 : CMD ["python3", "app.py"]
---> Using cache
---> 3d43018803b6
Successfully built 3d43018803b6
Successfully tagged keras_flask_app:latest
生成镜像后开始运行,使用下边的命令
docker run -it --name ai -p 1234:1234 keras_flask_app结果报错了
ImportError: libcuda.so.1: cannot open shared object file: No such file or directory
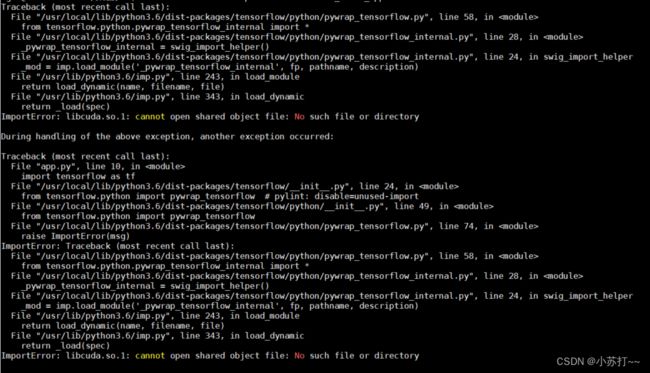
然后,然后就各种百度,查资料,发现是要使用一个可以使用GPU的docker来启动才行,也就是用nvidia-docker来启动才行 ,不得以下边开始安装nvidia-docker
1.配置源
$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
$ curl -s -L https://nvidia.github.io/nvidia-docker/ubuntu18.04/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
$ sudo apt-get update
2.安装nvidia-docker
$ sudo apt-get install nvidia-docker2
$ sudo systemctl restart docker
结果用下边命令测试nvidia-docker是否安装成功,还是报错
sudo docker run --rm --gpus all nvidia/cuda:10.0-base nvidia-smi
这就无奈了,然后又是各种百度,有一个爱心网友说,重启凑效,就赶紧sudo reboot now,重启之后就真的好用了。然后赶紧用nvidia-docker启动容器
1.创建容器
#docker run -idt --name 容器名 --gpus all --shm-size 16G 镜像名:版本号
docker run -idt --name ai -p 1234:1234 --gpus all --shm-size 12G keras_flask_app2.启动容器
sudo nvidia-docker start ai3.访问接口
成功!!!