实验四 LR(0)分析方法的设计与实现 (8学时)
实验四 LR(0)分析方法的设计与实现(8学时)
一、实验目的
通过LR分析方法的实现,加深对自下而上语法分析方法及语法分析程序自动生成过程的理解。
二、实验要求
输入上下文无关文法,对给定的输入串,给出其LR分析过程及正确与否的判断。
三、实验步骤
1.参考数据结构
typedef struct{/*文法*/
char head;//产生式左部符号
char b[20];//用于存放产生式
int point;
int lg;//产生式的长度
}regular;
typedef struct{
int l; //文法数量
int m; //vn 数量
int n; //vt 数量
regular re[20];
nfinal vn[20];//非终结符
final vt[20];//终结符
}condition;
condition cd[20];//项目
regular first[20];//产生式
- 使用闭包函数(CLOSURE)和转换函数(GO(I,X))构造文法G’的LR(0)的项目集规范族。
计算LR(0)项目集规范族C={I0,I1,…,In}
算法描述如下:
Procedure itemsets(G’);
Begin C = { CLOSURE ({S’ →.S})}
Repeat
For C 中每一项目集I和每一文法符号X
Do if GO(I,X) 非空且不属于C
Then 把 GO(I,X) 放入C中
Until C 不再增大
End;
定义转换函数如下:
GO(I,X)= CLOSURE(J)
其中:I为包含某一项目集的状态,X为一文法符号,J={A→aX.b|A→a.X b∈I}。 - 构造LR(0)分析表
对于LR(0)文法,我们可以直接从它的项目集规范族C和活前缀识别自动机的状态转换函数GO构造出LR分析表。
算法描述如下:
begin
if A→α•aβ Ik and GO(Ik,a) = Ij (aVT) then
置ACTION[k,a] = sj;
If A→α• Ik then
对任意终结符a(包括#)置ACTION[k,a] = rj;
If S’ →S• Ik then
置ACTION[k,#] = acc;
If GO(Ik,A) = Ij (AVN) then
置 GOTO(k,A) = j;
else ERROR //出错 - LR分析算法描述
对给定的输入串,给出其分析过程及正确与否的判断
将S0移进状态栈,#移进符号栈,S为状态栈栈顶状态
begin
a=getsym() //读入第一个符号给a
while(ACTION[S,a]!=acc)
If ACTION[S,a]=si then
PUSH i,a(分别进栈);输出进栈信息
a=getsym();//读入下一个符号给a
else if ACTION[S,a] = rj (第j条产生式为A→β) then
输出归约信息
将状态栈和符号栈分别弹出|β|项; push(A);
将GOTO[S’,A]移进状态栈(S’为当前栈顶状态);
else error;
输出分析结果,接受或出错
End
5、对给定输入串输出其准确与否的分析过程。
四、实验报告要求
1.写出编程思路、源代码(或流程图);
#include2.写出上机调试时发现的问题,以及解决的过程;
问题:定义项目集规范族时进行集合的集合定义,如果要考虑集合的排序规则不能直接定义成unordered_set,须定义成有排序规则的集合,只有这样才能符合C++集合的去重规则。
最后可在数据结构定义相应的去重和排序规则,或者直接定义成set。
问题:在进行分析时符号栈时如何进行转换是矩阵的数字对应
将符号栈定义成整型,自行编写字符串转整型进入符号栈。
3.写出你所使用的测试数据及结果;
测试数据:(注意文件路径)
EAB
abcd
3
E->aA|bB
A->cA|d
B->cB|d
bccd#

结果:

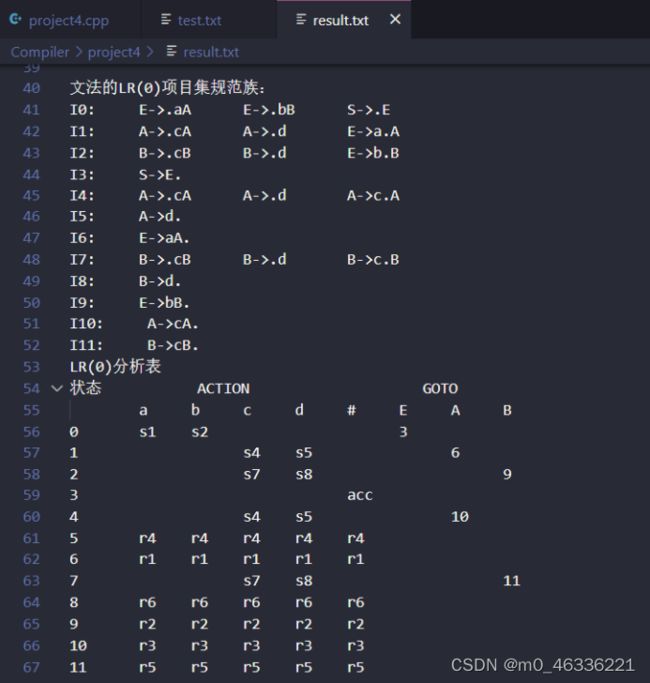

4.谈谈你的体会。
LR(0)文法规范族的每一个项目即不含冲突项目,因此,按上法构造的分析表的每个入口都是唯一的(即不含多重定义)。四种项目的类型:“归约项目”、“移进项目”、“待约项目”和“接受项目”,这几种项目类型不同的冲突会一定程度上使LR(0)失效。(读者也可尝试自己定义set的排序依据,这样效率相对高些)(感兴趣的读者也可自行加错误识别打印出对应分析报告表的位置)
另附YACC自动实现:(感兴趣可自行学习查阅资料)
手把手教程-lex与yacc/flex与bison入门(一)(使用windows环境)
1.写出编程思路、源代码(或流程图);
/test.y/
%{
#include 2.写出上机调试时发现的问题,以及解决的过程;
问题:YACC中bios与flex共同使用时相应的文件如何排版,flex文件不改进行联合编译时会直接报错提示。需要将相应的flex文件删去下面的主函数,只定义规则。
3.写出你所使用的测试数据及结果
