【机器学习笔记】SVM进行房价预测
文章目录
- 前言
- 一、源码解析
-
- 1.引入库
- 2.设置属性防止中文乱码
- 3.加载数据
- 4.分割数据
- 5.模型构建(参数类型和SVC基本一样)
- 6.获取最优参数
- 7.画图与图形展示
- 总结
前言
本文将记录机器学习当中关于房价预测实现过程,附源码及介绍。
一、源码解析
1.引入库
代码如下(示例):
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
import warnings
import sklearn
from sklearn.svm import SVR # 对比SVC,是svm的回归形式
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV # 网格搜索交叉验证
2.设置属性防止中文乱码
代码如下(示例):
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
def notEmpty(s):
return s != ''
3.加载数据
names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT']
path = "datas/boston_housing.data"
## 由于数据文件格式不统一,所以读取的时候,先按照一行一个字段属性读取数据,然后再安装每行数据进行处理
fd = pd.read_csv(path, header=None)
data = np.empty((len(fd), 14))
for i, d in enumerate(fd.values):
d = map(float, filter(notEmpty, d[0].split(' ')))
data[i] = list(d)
4.分割数据
x, y = np.split(data, (13,), axis=1)
y = y.ravel() # 转换格式
print ("样本数据量:%d, 特征个数:%d" % x.shape)
print ("target样本数据量:%d" % y.shape[0])
# 数据分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=28)
5.模型构建(参数类型和SVC基本一样)
parameters = {
'kernel': ['linear', 'rbf'],
'C': [0.1, 0.5,0.9,1,5],
'gamma': [0.001,0.01,0.1,1]
}
model = GridSearchCV(SVR(), param_grid=parameters, cv=3) # 3折交叉验证
model.fit(x_train, y_train)
6.获取最优参数
print ("最优参数列表:", model.best_params_)
print ("最优模型:", model.best_estimator_)
print ("最优准确率:", model.best_score_)
"""
最优参数列表: {'C': 5, 'gamma': 0.001, 'kernel': 'linear'}
最优模型: SVR(C=5, cache_size=200, coef0=0.0, degree=3, epsilon=0.1, gamma=0.001,
kernel='linear', max_iter=-1, shrinking=True, tol=0.001, verbose=False)
最优准确率: 0.7372572871508232
"""
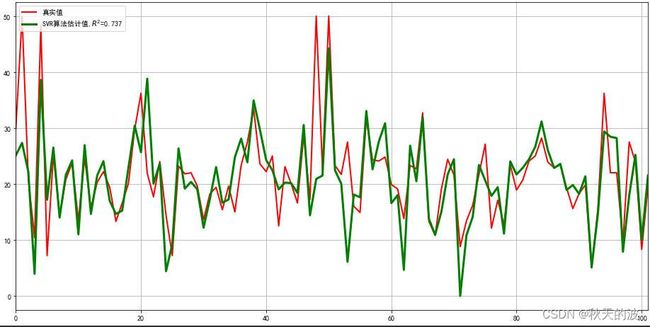
7.画图与图形展示
colors = ['g-', 'b-']
ln_x_test = range(len(x_test))
y_predict = model.predict(x_test)
plt.figure(figsize=(16,8), facecolor='w')
plt.plot(ln_x_test, y_test, 'r-', lw=2, label=u'真实值')
plt.plot(ln_x_test, y_predict, 'g-', lw = 3, label=u'SVR算法估计值,$R^2$=%.3f' % (model.best_score_))
# 图形显示
plt.legend(loc = 'upper left')
plt.grid(True)
plt.title(u"波士顿房屋价格预测(SVM)")
plt.xlim(0, 101)
plt.show()
总结
以上就是今天要讲的内容,本文仅仅简单介绍了SVM进行房价预测,仅供参考学习,如果对您有所帮助,感谢点赞收藏!