基于GAN的火灾图像数据集增强目标检测
1.文章信息
本次介绍的文章是韩国光云大学发表的一篇火灾图像数据集目标检测文章,题目为《Object Detection with Dataset Augmentation for Fire Images Based on GAN》。
2.摘要
目标检测是在图像中发现和分类目标的任务。现在已经提出了许多基于深度学习算法的对象检测模型。深度学习算法需要用丰富的图像和精确的注释来训练模型。然而,在火灾探测的情况下,既没有足够的数据集来训练探测模型,也没有正确和充分的注释。文章提出了一种基于GAN的模型来生成带有边界框的火灾图像,以提高火灾检测模型的性能。通过实验,文章证明了该模型可以将火焰图像注入到指定区域内的干净图像中,并且生成的图像足以扩展火灾检测数据集,从而可以提高模型的目标检测性能。
3.介绍
对象检测是从给定图像中指定对象位置和类别的任务。随着深度学习算法的发展,基于神经网络的目标检测模型受到了关注。由于检测性能高度依赖于图像和注释的数量,因此对象检测模型需要大量的图像和注释,例如边界框和类标签。尽管有许多数据集用于训练对象检测模型,如Open Image Dataset和MS COCO,但它们有一个局限性,即仅包含普通对象类。
Fire是一个没有足够数据集的对象的例子。带有注释以训练目标检测模型的火灾数据集的数量太少,以至于很难实现足够的检测性能。与其他物体不同,出于安全原因,查找或创建新的火灾图像受到限制。火灾数据集的缺乏可能导致目标检测模型的检测性能不佳,并使训练和扩展模型变得困难。例如,FireNet是一种专门用于火灾探测的轻量级模型。尽管FireNet有少量参数,但FireNet中的训练和验证损失之间的泛化差距表明,由于缺乏数据,模型被过度拟合。缓解此问题的最简单方法是使用人力对图像进行注释。尽管这种方法可以生成精确的数据集,但它在时间和成本方面效率低下。图像增强增加了无需人工注释器的输入数据量,数据增强方法主要分为图像处理方法和深度学习方法。图像处理方法通过剪切、擦除和混合来转换图像。
当图像数量较少时,该方法可能会发生过拟合。在这种情况下,可以使用生成建模等深度学习方法。然而,该模型只考虑了特定情况,而不是一般情况。此外,该模型仅对火焰混合的图像块进行图像到图像的转换,因此从块到块附近的背景的过渡是不自然的。
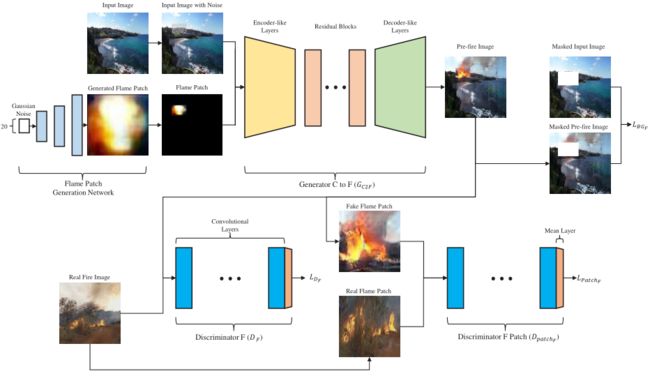
为了解决上述问题,文章提出了基于生成对抗网络(GAN)的模型,该模型在边界框的给定坐标内将无火图像(干净图像)转换为有火图像(火图像)。文章的模型基于GAN模型:火焰斑块生成网络、火灾前图像生成网络和火焰关注网络。火焰面片生成网络接受带有边界框的火焰图像,使用边界框裁剪火焰面片,并经过训练以生成类似的火焰面片。火灾前图像生成网络可以获取干净的图像、火灾图像和边界框。该网络将清洁图像与火焰斑块生成网络生成的火焰斑块混合。该模块的结果是具有退化背景和伪影的预拍摄图像。火焰关注网络获取火灾前图像作为输入,并计算指示火焰的关注度。对于注意力,所提出的模型执行注意力和预激发图像的逐元素乘积;以及反转的注意力和干净的输入图像。然后,所提出的模型将两个结果相加以生成作为模型输出的火灾图像。结果表明,改善了背景质量,从火焰到背景的自然过渡,减少了伪影。在实验中,文章证实了模型可以将火焰图像混合到干净图像的一个块中,该块对应于从模型生成的边界框,并且可以提高对象检测模型的火灾检测性能。
文章的技术贡献点:1.我们提出的模型能够将火焰混合到指定区域的背景图像中,而不会严重恶化背景。2.从所提出的模型合成的图像及其相应的边界框可用于增强现有的火灾数据集,以增强目标检测性能。
4.基于GAN同时生成火灾图像和边界框
A. 拟定火灾图像生成架构
模型包括三个网络:火焰斑块生成网络、火灾前图像生成网络和火焰关注网络。火焰补丁生成网络基于DCGAN,并学习生成火焰图像,该图像将由火灾前生成网络使用。火灾前图像生成网络基于CycleGAN。该网络经过训练,不仅可以将火焰注入干净的图像,还可以从火焰图像中去除火焰。为了鼓励将火焰混合成干净的图像,还将火焰补丁提供给生成器。训练过程之后,将清洁图像映射到火灾图像的生成器将用于生成火灾图像。然而,生成器给出的图像不能用于增强火灾数据集,因为它丢失了干净图像的大部分高频信息,并且存在伪影,尤其是在干净图像中的低频区域。火焰关注网络基于具有关注网络的CycleGAN。注意力网络使用干净的图像和火灾图像,但该网络不使用火灾图像的注释。火焰关注网络接受火前图像并生成指示火焰的关注地图。为了恢复丢失的信息并减轻伪影,该模型执行火灾前图像和注意力图的逐元素乘积,以获得火灾前图像的火焰部分。该模型还执行干净图像和反向注意力图的元素乘积,以获得干净的背景图像。将应用逐元素乘积的清洁图像和火灾前图像相加以生成火灾图像。下图显示了使用示例的整体火灾图像生成过程和架构。

B.火焰补丁生成网络

如上图所示,火焰补丁生成网络基于简单的DCGAN网络。网络的生成器学习将高斯噪声映射到火焰图像。在训练过程中,网络使用边界框从火焰图像中裁剪火焰补丁,以获得真实的火焰补丁。生成器重复执行上采样和卷积,而不是转置卷积,这可以防止生成的图像出现棋盘状伪影。网络中的鉴别器执行卷积以将图像减少为通知鉴别器评估结果的标量值。
由于真实的火斑不仅包括火焰,还包括建筑物、原木、树木或消防员等火灾情况的背景,因此网络的结果不像真实的火焰,而是接近火焰的纹理。火焰补丁的质量对整个生成过程的影响很小。这是因为下面的火灾前图像生成网络被训练来升级火焰补丁并合并火焰补丁和清洁图像。
C.火灾前图像生成网络
火灾前生成网络的目的是将清洁图像映射到火灾图像。CycleGAN可以稳定地学习该映射。因此,火灾前图像生成网络采用CycleGAN作为其基线结构。下图说明了将清洁图像映射到火灾图像的火灾前图像生成网络的一部分。网络的另一部分具有相同的结构。
CycleGAN网络的组件由两个生成器和两个鉴别器组成:生成器![]() 用于将清洁图像映射到火灾图像,生成器
用于将清洁图像映射到火灾图像,生成器![]() 用于将火灾图像映射到清洁图像,鉴别器
用于将火灾图像映射到清洁图像,鉴别器![]() 用于评估图像是否为清洁图像,以及鉴别器
用于评估图像是否为清洁图像,以及鉴别器![]() 用于确定图像是否来自火灾数据集。
用于确定图像是否来自火灾数据集。![]() 和
和![]() 成为一对,用于将清洁图像映射到火灾图像,
成为一对,用于将清洁图像映射到火灾图像,![]() 成为另一对,以将火灾图像映射到清洁图像。训练以GAN损失
成为另一对,以将火灾图像映射到清洁图像。训练以GAN损失![]() 和
和![]() 、身份损失
、身份损失![]() 和
和![]() 以及循环一致性损失
以及循环一致性损失![]() 和
和![]() 进行。
进行。

如上图所示,![]() 和
和![]() 是阻碍图像色调改变的损失。这些损失是通过测量火灾图像与
是阻碍图像色调改变的损失。这些损失是通过测量火灾图像与![]() 应用的相同图像之间的L1距离或清洁图像与
应用的相同图像之间的L1距离或清洁图像与![]() 应用的相同的图像之间的L2距离来计算的。
应用的相同的图像之间的L2距离来计算的。![]() 和
和![]() 是支持生成器学习单个图像的两个域之间的映射的损失,这是通过计算图像和通过网络中的两个生成器恢复的图像之间的L1距离得出的。通过一些实验,文章发现基线CycleGAN无法将火焰插入低频区域。此外,这些损失不足以约束模型学习所需的映射。因此,文章为发生器和鉴别器对添加了辅助鉴别器、输入和操作,以鼓励发生器将火焰图像放入干净的图像中。
是支持生成器学习单个图像的两个域之间的映射的损失,这是通过计算图像和通过网络中的两个生成器恢复的图像之间的L1距离得出的。通过一些实验,文章发现基线CycleGAN无法将火焰插入低频区域。此外,这些损失不足以约束模型学习所需的映射。因此,文章为发生器和鉴别器对添加了辅助鉴别器、输入和操作,以鼓励发生器将火焰图像放入干净的图像中。
为了最大化每个发生器的火焰混合和去除能力,对CycleGAN进行了两项重大修改:输入和模型结构的修改。首先,更改发电机的输入。文章将边界框区域中50%的像素替换为高斯噪声,并将输入图像与拟合到边界框中的噪声和火焰斑块连接起来。
这些串联的6通道图像被给出作为发生器的输入。除此之外,文章添加了补丁鉴别器DpatchF和DpatchC来支持生成器。每个贴片鉴别器决定裁剪的边界框区域是否为火焰图像,以与DF和DC相同的方式产生贴片鉴别器损失LpatchF和LpatchC。通过使用这些方法,模型可以将火焰图像嵌入干净图像的大部分部分。此外,引入了背景损失LBGF和LBGC,以提高生成图像的背景保真度,并松散地限制在指定区域中发生的I2I转换过程。这些损失通过掩蔽输入图像和掩蔽输出图像之间的L1距离来计算。
D.火焰关注网络
尽管火前生成网络有了所有改进,但火前图像的质量不足以表示真实世界的数据,特别是由于其背景受损。
因此,文章使用注意力网络训练CycleGAN,以最小化背景的修改。带有注意力网络模型的基本CycleGAN可以在图像中插入火焰,使背景不受损坏,但注入火焰的位置无法控制。然而,用于将火灾图像映射到清洁图像的注意力网络学习快速突出显示火灾图像中的火焰,以至于只需要几个时期就可以成功指示整个火焰。
因此,文章使用注意力网络从火灾前图像中提取火焰部分,并将其与干净的图像合并。

上图显示,注意力图精确地捕捉了火灾前图像中的火焰。尽管具有注意力网络的CycleGAN比基线CycleGAN更重,但需要不到10个周期的训练才能获得注意力网络。图中的注意力图来自于训练了4个时期的注意力网络。
5.实验结果与分析
A. 实施详细信息
在实验中使用了来自FireNet和Fismo数据集的数据集作为火灾数据集。此外,文章采样并混合了Arnaud Rougetet1的Google Landmark v2数据集和风景图片数据集,以获得干净的数据集。
在火焰斑块生成网络的情况下,文章对20维高斯噪声进行采样并将其放入生成器。由生成器合成的图像的大小设置为128x128。预激发图像生成器网络使用具有11个残差块的生成器,生成器接受6通道输入,而不是3通道输入。在将注意力应用于图像之前,文章将注意力调零为小于0.2,将注意力调高为大于0.7至1.0。此外,文章训练了火焰补丁生成20个周期,50个时期的火灾前图像生成网络和4个时期的火焰关注网络。
B. 带边界框的火灾图像生成
为了检查模型从随机图像和随机边界框位置生成火灾图像的能力,文章随机采样了边界框的坐标。

上图是结果的一部分。火焰在边界框区域内生成,通过注意力的力量,火焰无缝地融合到干净的图像中。
C. 边界框导线测量
即使使用相同的图像作为模型的输入数据,生成结果也会随着给定边界框的移动而改变。下图显示了边界框移动时结果的变化。我们可以看到,无论边界框的位置如何,模型都可以生成火灾图像。
D. 用生成的图像增强数据集
为了检查生成的图像是否可以提高火灾探测性能,准备了两个数据集:第一个数据集由412个火灾图像组成,另一个数据集包含412个火警图像和800个生成的图像。用两个数据集训练了两个YOLOv3模型50个时期,并用90张火灾图像测试了模型。下表显示了火灾探测结果。使用增强数据集训练的模型显示,在所有指标下,检测火力的性能都有所提高。

6.结论
文章提出了一种从干净图像中增强火灾数据集的体系结构。为了提高网络的生成性能,我们引入了火焰补丁生成网络、火灾注意网络以及火灾图像生成网络中的损失和噪声。通过实验,我们证明了所提出的模型可以在不破坏背景的情况下生成火灾图像。此外,我们确认了从所提出的模型生成的图像可以提高火灾检测模型的性能。
Attention
欢迎关注微信公众号《当交通遇上机器学习》!如果你和我一样是轨道交通、道路交通、城市规划相关领域的,也可以加微信:Dr_JinleiZhang,备注“进群”,加入交通大数据交流群!希望我们共同进步!
